信息网络安全 ›› 2026, Vol. 26 ›› Issue (3): 367-377.doi: 10.3969/j.issn.1671-1122.2026.03.003
深度伪造语音真实性鉴定研究综述
徐衍微1,2( ), 涂敏1,2, 张亮1,2
), 涂敏1,2, 张亮1,2
- 1.江西警察学院网络安全学院,南昌 330100
2.电子数据管控与取证江西省重点实验室,南昌 330100
-
收稿日期:2025-08-10出版日期:2026-03-10发布日期:2026-03-30 -
通讯作者:徐衍微 E-mail:xywlbq@qq.com -
作者简介:徐衍微(1982—),女,江西,讲师,硕士,主要研究方向为网络安全、声纹鉴定|涂敏(1967—),女,江西,教授,本科,主要研究方向为网络安全、计算机取证|张亮(1976—),女,江西,副教授,硕士,主要研究方向为网络安全、声像资料鉴定 -
基金资助:江西省教育厅科学技术研究重点项目(GJJ2202302);江西省教育厅科学技术研究项目(GJJ2402204)
A Review on the Authenticity Verification of Deepfake Speech
XU Yanwei1,2(), TU Min1,2, ZHANG Liang1,2
- 1. School of Cyber Security, Jiangxi Police College, Nanchang 330100, China
2. Jiangxi Provincial Key Laboratory of Electronic Data Control and Forensics, Nanchang 330100, China
-
Received:2025-08-10Online:2026-03-10Published:2026-03-30
摘要:
随着深度伪造语音技术在电信诈骗、网络虚假信息传播中的滥用,高保真合成语音的真实性鉴定面临严峻挑战。文章以面向深度伪造的语音真实性鉴定为研究对象,构建原始性鉴定、完整性鉴定与深度检测相结合的技术框架。在原始性鉴定层面,分析语音设备与系统环境一致性检验、文件属性与元数据逻辑核验的方法及适用边界;在完整性鉴定层面,系统阐述听视觉检验、声谱检验与其他信号分析的技术路径;在深度伪造检测层面,从全局判别与局部定位两个维度,归纳其检测方法、基准数据集与评估指标。研究表明,构建文件属性分析、传统声学检验与深度学习检测的综合技术路径,有助于保障鉴定工作的可解释性、可验证性与司法适用性,为复杂网络环境下的语音真实性鉴定提供理论依据与技术支撑。
中图分类号:
引用本文
徐衍微, 涂敏, 张亮. 深度伪造语音真实性鉴定研究综述[J]. 信息网络安全, 2026, 26(3): 367-377.
XU Yanwei, TU Min, ZHANG Liang. A Review on the Authenticity Verification of Deepfake Speech[J]. Netinfo Security, 2026, 26(3): 367-377.
表1
典型语音伪造技术
| 生成路线 | 代表模型 | 声学特征 | 典型伪造痕迹特征 |
|---|---|---|---|
| TTS- 自回归 | WaveNet[ Tacotron系列[ | 原始波形/ Mel频谱 | 相位连续性异常、基频平滑异常 |
| TTS- 非自回归 | FastSpeech 系列[ | 音素时长、F0 | 时长量化边界、频谱包络过平滑、韵律模式单一 |
| TTS- 端到端/ 大模型 | VALL-E[ VITS[ | 时域波形、 神经音频编码 | 韵律不连贯、噪声底纹不稳定、上下文切换伪影 |
| TTS- 扩散模型 | Grad-TTS[ | 扩散轨迹、 Mel频谱 | 频带能量分布异常、去噪残留伪影 |
| VC-非平行 | CycleGAN-VC[ StarGAN-VC[ | Mel频谱 | 说话人特征混叠、共振峰偏移、说话人特征残留 |
| VC-扩散模型 | DDDM-VC[ Diff-VC[ | Mel频谱、 扩散轨迹 | 频带能量衰减不均、共振峰轨迹异常、跨帧相关性异常 |

图1
主流伪造语音生成与鉴定技术框架
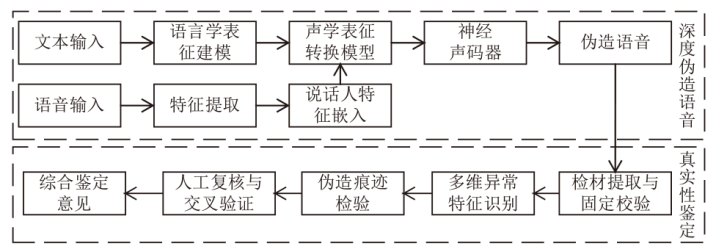

图2
语音真实性鉴定技术框架
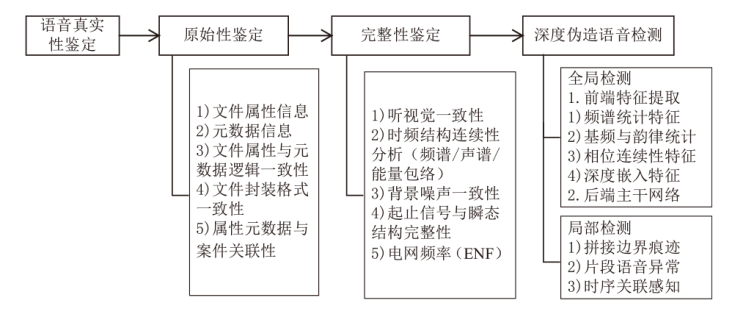
表2
主流数据集
| 数据集 | 伪造类型 | 语言 | 常用评估指标 |
|---|---|---|---|
| ASVspoof 系列[ | TTS、VC(LA)、重放(PA)、 深度伪造(DF) | 英语 | EER、min t-DCF |
| WaveFake[ | TTS | 英语/日语 | EER、AUC |
| ADD LF[ CFAD | TTS、VC | 中文 | EER |
| ITW | TTS | 英语 | EER |
| PartialSpoof[ | 帧级部分伪造 | 英语 | EER |
| ADD PF[ | 局部伪造 | 中文 | EER、F1 |
| HAD[ | 局部拼接/篡改 | 中文 | EER、F1 |
表3
语音真实性鉴定的技术路径
| 鉴定 维度 | 检验思路 | 检验内容 | 关键技术方法 |
|---|---|---|---|
| 文件层 | 文件结构与元数据一致性 | 哈希值校验、容器结构一致性、元数据逻辑核验、系统底层日志分析 | 设备指纹比对、 多源系统交叉核验[ |
| 听觉感知与语义层 | 语音听觉感知特征 | 语义逻辑、 语音自然性 | 听觉感知分析[ |
| 多模态检材一致性 | 音视频时序同步 | 跨模态特征一致性关联[ | |
| 声学特征层 | 声学统计 一致性 | 频谱连续性、噪声平稳性、谐噪统计 一致性 | 波形分析、长时平均功率谱(LTAS)、谐噪比统计与拼接痕迹检测[ |
| 编码与物理信号层 | 编码痕迹与环境信号溯源 | 频谱与噪声稳定性、编码痕迹(MDCT)、ENF轨迹 | 重采样、重压缩、电网频率信号(ENF)分析[ |
| 深度伪造语音检测 | 全局伪造检测 | 前端特征提取 | 传统手工特征(MFCC、LFCC、CQCC)、声源生理特征、F0与复频谱表征、自监督语音表征[ |
| 后端主干网络 | LCNN+最大特征图激活、RawNet2、AASIST+ 图注意力机制[ | ||
| 局部伪造检测 | 帧级/音素级边界、时序建模、 局部频谱伪影 | 片段级伪造定位、帧级定位、音素级一致性验证[ |
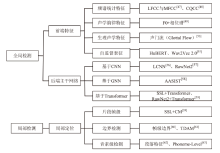
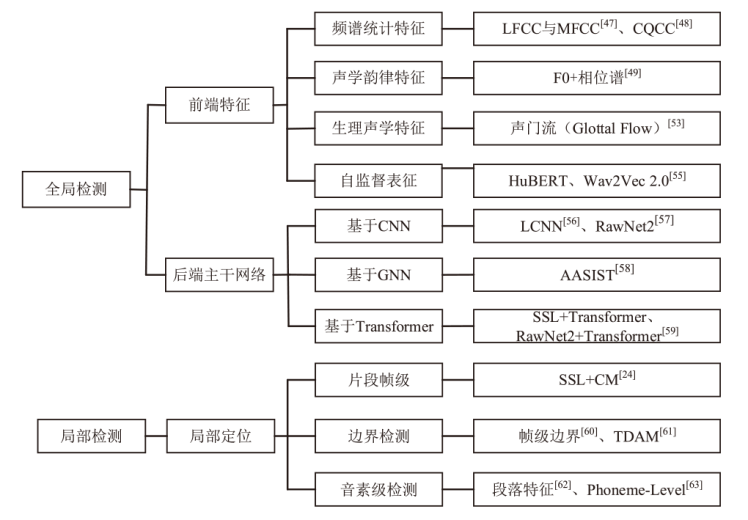
图3
主流深度伪造语音检测技术
| [1] | PHAM L, LAM P, TRAN D, et al. A Comprehensive Survey with Critical Analysis for Deepfake Speech Detection[EB/OL]. (2025-04-16)[2025-08-10]. https://www.skopik.at/ait/2025_csreview.pdf. |
| [2] | LI Menglu, AHMADIADLI Y, ZHANG Xiaoping. A Survey on Speech Deepfake Detection[J]. ACM Computing Surveys, 2025, 57(7): 1-38. |
| [3] | XIE Yuankun, CHENG Haonan, YE Long. A Survey on Deepfake Audio Detection[J]. Journal of Communication University of China (Natural Science Edition), 2024, 31(3): 26-33. |
| 谢元坤, 程皓楠, 叶龙. 深度伪造音频检测综述[J]. 中国传媒大学学报(自然科学版), 2024, 31(3):26-33. | |
| [4] |
XU Yuxiong, LI Bin, TAN Shunquan, et al. Research Progress on Speech Deepfake and Its Detection Techniques[J]. Journal of Image and Graphics, 2024, 29(8): 2236-2268.
doi: 10.11834/jig.230476 URL |
| 许裕雄, 李斌, 谭舜泉, 等. 语音深度伪造及其检测技术研究进展[J]. 中国图象图形学报, 2024, 29(8):2236-2268. | |
| [5] | LI Zeyu, ZHANG Xuhong, PU Yuwen, et al. A Survey of Multimodal Deepfake Generation and Detection Technologies[J]. Journal of Computer Research and Development, 2023, 60(6): 1396-1416. |
| 李泽宇, 张旭鸿, 蒲誉文, 等. 多模态深度伪造及检测技术综述[J]. 计算机研究与发展, 2023, 60(6):1396-1416. | |
| [6] | SHEN J, PANG Ruoming, WEISS R J, et al. Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions[C]// IEEE. The 43rd IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). New York: IEEE, 2018: 4779-4783. |
| [7] | WANG Yuxuan, SKERRY-RYAN R J, STANTON D, et al. Tacotron: A Fully End-to-End Text-to-Speech Synthesis Model[EB/OL]. (2017-03-29)[2025-08-10]. https://arxiv.org/abs/1703.10135. |
| [8] | REN Yi, RUAN Yang jun, TAN Xu, et al. FastSpeech: Fast, Robust and Controllable Text to Speech[J]. Advances in Neural Information Processing Systems, 2019, 32: 1-11. |
| [9] | POPOV V, VOVK I, GOGORYAN V, et al. Grad-TTS: A Diffusion Probabilistic Model for Text-to-Speech[EB/OL]. (2021-05-13)[2025-08-10]. https://arxiv.org/abs/2105.06337. |
| [10] |
CHEN Sanyuan, WANG Chengyi, WU Yu, et al. Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers[J]. IEEE Transactions on Audio, Speech and Language Processing, 2025, 33: 705-718.
doi: 10.1109/TASLPRO.2025.3530270 URL |
| [11] | GAO Junfeng, CHEN Junguo. Voice Conversion with Non-Parallel Corpus Based on Style-CycleGAN-VC[J]. Computer Applications and Software, 2021, 38(9): 133-139, 159. |
| 高俊峰, 陈俊国. 基于Style-CycleGAN-VC的非平行语料下的语音转换[J]. 计算机应用与软件, 2021, 38(9):133-139,159. | |
| [12] | KAMEOKA H, KANEKO T, TANAKA K, et al. StarGAN-VC: Non-Parallel Many-to-Many Voice Conversion Using Star Generative Adversarial Networks[C]// IEEE. 2018 IEEE Spoken Language Technology Workshop (SLT). New York: IEEE, 2018: 266-273. |
| [13] | CHOI H Y, LEE S H, LEE S W. DDDM-VC: Decoupled Denoising Diffusion Models with Disentangled Representation and Prior Mixup for Verified Robust Voice Conversion[C]// AAAI. The AAAI Conference on Artificial Intelligence. Palo Alto: AAAI, 2024: 17862-17870. |
| [14] | KANEKO T, KAMEOKA H, TANAKA K, et al. Diff-VC: Diffusion-Based Non-Parallel Many-to-Many Voice Conversion[C]// IEEE. 2022 IEEE Spoken Language Technology Workshop (SLT). New York: IEEE, 2022: 730-737. |
| [15] | KIM J, KONG J, SON J. Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech[C]// IMLS. The 38th International Conference on Machine Learning. New York: PMLR, 2021: 5530-5540. |
| [16] | ZHANG Yuxiang, LI Zhuo, LU Jingze, et al. Spoof Speech Detection Based on Speaker Features[J]. Acta Acustica, 2025, 50(1): 201-210. |
| 张宇翔, 李茁, 陆镜泽, 等. 基于声纹特征的伪造语音检测[J]. 声学学报, 2025, 50(1):201-210. | |
| [17] | BAEVSKI A, ZHOU Yuhao, MOHAMED A, et al. wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations[EB/OL]. (2020-12-06)[2025-07-10]. https://arxiv.org/abs/2006.11477. |
| [18] | GAMBIN A F, YAZIDI A, VASILAKOS A, et al. Deepfakes: Current and Future Trends[J]. Artificial Intelligence Review, 2024, 57-64. |
| [19] |
ZENG Chunyan, WANG Zhifeng, WANG Jing, et al. Survey of Passive Detection of Digital Audio Tampering[J]. Computer Engineering and Applications, 2019, 55(2): 1-11, 99.
doi: 10.3778/j.issn.1002-8331.1809-0324 |
|
曾春艳, 王志锋, 王静, 等. 数字音频篡改被动检测研究综述[J]. 计算机工程与应用, 2019, 55(2):1-11,99.
doi: 10.3778/j.issn.1002-8331.1809-0324 |
|
| [20] |
LIU Xuechen, WANG Xin, SAHIDULLAH M, et al. ASVspoof 2021: Towards Spoofed and Deepfake Speech Detection in the Wild[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2023, 31: 2507-2522.
doi: 10.1109/TASLP.2023.3285283 URL |
| [21] | WANG Xin, DELGADO H, SINGH V, et al. ASVspoof 5: Design, Collection and Validation of Resources for Spoofing, Deepfake, and Adversarial Attack Detection Using Crowdsourced Speech[EB/OL]. (2025-02-13)[2025-08-10]. https://doi.org/10.1016/j.csl.2025.101825. |
| [22] | FRANK J, SCHONHERR L. WaveFake: A Dataset to Facilitate Audio Deepfake Detection[C]// NeurIPS. The 35th Conference on Neural Information Processing Systems Datasets and Benchmarks Track. Cambridge: MIT Press, 2021: 1-8. |
| [23] | YI Jiangyan, FU Ruibo, TAO Jianhua, et al. ADD 2022: The First Audio Deep Synthesis Detection Challenge[C]// IEEE. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). New York: IEEE, 2022: 9216-9220. |
| [24] |
ZHANG Lin, WANG Xin, COOPER E, et al. The PartialSpoof Database and Countermeasures for the Detection of Short Fake Speech Segments Embedded in an Utterance[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2023, 31: 813-825.
doi: 10.1109/TASLP.2022.3233236 URL |
| [25] | YI Jiangyan, BAI Ye, TAO Jianhua, et al. Half-Truth: A Partially Fake Audio Detection Dataset[C]// ISCA. International Speech Communication Association Annual Conference. New York: IEEE, 2021: 4321-4325. |
| [26] |
ZHANG Bowen, CUI Hui, NGUYEN V, et al. Audio Deepfake Detection: What Has Been Achieved and What Lies Ahead[J]. Sensors, 2025, 25(7): 1989-2021.
doi: 10.3390/s25071989 URL |
| [27] | KINNUNEN T, LEE K-A, DELGADO H, et al. T-DCF: A Detection Cost Function for the Tandem Assessment of Spoofing Countermeasures and Automatic Speaker Verification[EB/OL]. (2018-04-25)[2025-08-10]. https://arxiv.org/abs/1804.09618. |
| [28] |
LI Xiaolong, YU Nenghai, ZHANG Xinpeng, et al. Overview of Digital Media Forensics Technology[J]. Journal of Image and Graphics, 2021, 26(6): 1216-1226.
doi: 10.11834/jig.210081 URL |
| 李晓龙, 俞能海, 张新鹏, 等. 数字媒体取证技术综述[J]. 中国图象图形学报, 2021, 26(6):1216-1226. | |
| [29] | KOENIG B E, LACEY D S. Forensic Authenticity Analyses of the Header Data in Re-Encoded WMA Files from Small Olympus Audio Recorders[J]. Journal of the Audio Engineering Society, 2012, 60(4): 255-265. |
| [30] | LU Qimeng, SHI Shaopei, BIAN Xinwei, et al. A Method for Identifying Audio File Sources Based on Data Analysis[J]. Chinese Journal of Forensic Sciences, 2016(1): 37-44. |
| 卢启萌, 施少培, 卞新伟, 等. 一种基于数据分析的录音文件来源识别方法[J]. 中国司法鉴定, 2016(1):37-44. | |
| [31] |
ZENG Jinhua, XI Jianhua, SUN Weilong, et al. Authenticity Identification Technology of iPhone Recordings[J]. Chinese Journal of Forensic Sciences, 2020(5): 93-97.
doi: 10.3969/j.issn.1671-2072.2020.05.015 |
|
曾锦华, 奚建华, 孙维龙, 等. 苹果手机录制录音真实性鉴定技术[J]. 中国司法鉴定, 2020(5):93-97.
doi: 10.3969/j.issn.1671-2072.2020.05.015 |
|
| [32] |
LIU Haoyang, GUO Hong. Research on Authenticity Appraisal of Instant Messaging Chat Records[J]. Chinese Journal of Forensic Sciences, 2025(4): 75-82.
doi: 10.3969/j.issn.1671-2072.2025.04.008 |
| 刘浩阳, 郭弘. 即时通讯聊天记录真实性鉴定研究[J]. 中国司法鉴定, 2025(4):75-82. | |
| [33] | KIRCHHUEBEL C, BROWN G. Spoofed Speech from the Perspective of a Forensic Phonetician[C]// IEEE. 2022 Annual Conference of the International Speech Communication Association. New York: IEEE, 2022: 1308-1312. |
| [34] |
ZHAO Hong, MALIK H. Audio Recording Location Identification Using Acoustic Environment Signature[J]. IEEE Transactions on Information Forensics and Security, 2013, 8(11): 1746-1759.
doi: 10.1109/TIFS.2013.2278843 URL |
| [35] | HU Jiansong, YIN Qixin, CHEN Dingwen. A Systematic Forensic Study on the Authenticity (Integrity) of Voice Data[J]. Journal of Yunnan Police College, 2019(1): 56-70. |
| 胡健松, 殷启新, 陈丁文. 语音资料真实性(完整性)的系统鉴定研究[J]. 云南警官学院学报, 2019(1):56-70. | |
| [36] | CHENG Hao, GUO Yangyang, WANG Tianyi, et al. Voice-Face Homogeneity Tells Deepfake[J]. ACM Transactions on Multimedia Computing, Communications, and Applications, 2024, 20(3): 1-21. |
| [37] | LIU Weifeng, SHE Tianyi, LIU Jiawei, et al. Lips Are Lying: Spotting the Temporal Inconsistency between Audio and Visual in Lip-Syncing DeepFakes[EB/OL]. (2024-01-28)[2025-08-10]. https://arxiv.org/abs/2401.15668. |
| [38] |
ZAKARIAH M, KHAN M K, MALIK H. Digital Multimedia Audio Forensics: Past, Present and Future[J]. Multimedia Tools and Applications, 2018, 77: 1009-1040.
doi: 10.1007/s11042-016-4277-2 URL |
| [39] | OZGEN E, ALTAY S Y. Detecting Audio Copy-Move Forgeries on Mel Spectrograms via Hybrid Keypoint Features[EB/OL]. [2025-08-10]. https://www.mdpi.com/2076-3417/15/21/11845. |
| [40] | NI Lingge, WANG Huapeng, LIU Yuanzhou, et al. The Research on the Impact of Replay Attack on Speech Authenticity Verification[J]. Journal of People’s Public Security University of China (Natural Science Edition), 2020, 26(4): 8-14. |
| 倪令格, 王华朋, 刘元周, 等. 翻录对语音真实性检验的影响研究[J]. 中国人民公安大学学报(自然科学版), 2020, 26(4):8-14. | |
| [41] | RAN Qibin, HUANG Wei. Acoustic Comparison of Voice Quality between Synthetic and Natural Speech: Taking 18 Languages as an Example[J]. Journal of Tianjin Foreign Studies University, 2024, 31(5): 73-87, 112-113. |
| 冉启斌, 黄玮. 合成语音与自然语音嗓音的声学对比分析——以18种语言为例[J]. 天津外国语大学学报, 2024, 31(5):73-87,112-113. | |
| [42] | ZHOU Xinyu, ZHANG Yujin, WANG Yongqi, et al. Pyramid Feature Attention Network for Speech Resampling Detection[EB/OL]. (2024-06-01)[2025-08-10]. https://www.mdpi.com/2076-3417/14/11/4803. |
| [43] |
JIN Chao, WANG Rangding, YAN Diqun, et al. An Efficient Algorithm for Double Compressed AAC Audio Detection[J]. Multimedia Tools and Applications, 2016, 75(8): 1-18.
doi: 10.1007/s11042-014-2221-x URL |
| [44] |
GRIGORAS C. Digital Audio Recording Analysis: The Electric Network Frequency Criterion[J]. International Journal of Speech Language and the Law, 2005, 12(1): 63-76.
doi: 10.1558/sll.2005.12.1.63 URL |
| [45] |
CHUANG Weihong, GARG R, WU Min. Anti-Forensics and Countermeasures of Electrical Network Frequency Analysis[J]. IEEE Transactions on Information Forensics and Security, 2013, 8(12): 2073-2088.
doi: 10.1109/TIFS.2013.2285515 URL |
| [46] | LIN Xiaodan, KANG Xiangui. Supervised Audio Tampering Detection Using an Autoregressive Model[C]// IEEE. IEEE International Conference on Acoustics, Speech and Signal Processing. New York: IEEE, 2017: 2142-2146. |
| [47] | WU Zhizheng, KINNUNEN T, EVANS N, et al. ASVspoof 2015: The First Automatic Speaker Verification Spoofing and Countermeasures Challenge[C]// ISCA. The 16th Annual Conference of the International Speech Communication Association. New York: IEEE, 2015: 2037-2041. |
| [48] | TODISCO M, DELGADO H, EVANS N. Constant Q Cepstral Coefficients: A Spoofing Countermeasure for Automatic Speaker Verification[J]. Computer Speech & Language, 2017, 45: 516-535. |
| [49] | XUE Jun, FAN Cunhang, LYU Zhao, et al. Audio Deepfake Detection Based on a Combination of F0 Information and Real Plus Imaginary Spectrogram Features[C]// ACM. The 1st International Workshop on Deepfake Detection for Audio Multimedia. New York: ACM, 2022: 19-26. |
| [50] | TAHAOGLU G, BARACCHI D, SHULLANI D, et al. Deepfake Audio Detection with Spectral Features and ResNeXt-Based Architecture[EB/OL]. (2025-07-01)[2025-08-10]. https://flore.unifi.it/retrieve/b86b60b7-d663-4a1e-b421-ede9dd11d1eb/1-s2.0-S0950705125007725-main.pdf. |
| [51] | DESPLANQUES B, THIENPONDT J, DEMUYNCK K, et al. ECAPA-TDNN:Emphasized Channel Attention, Propagation and Aggregation in TDNN Based Speaker Verification[C]// ISCA. Interspeech 2020. New York: IEEE, 2020: 3830-3834. |
| [52] | JUNG J, KIM Y, HEO H, et al. Pushing the Limits of Raw Waveform Speaker Recognition[C]// ISCA. The 23rd International Conference on Speech Communication (Interspeech 2022). New York: IEEE, 2022: 2228-2232. |
| [53] | LU Jingze, ZHANG Yuxiang, SHANG Zengqiang, et al. Spoofed Speech Detection Based on Glottal Flow and Voiceprint Features[J]. Acta Acustica, 2025, 50(6): 1679-1689. |
| 陆镜泽, 张宇翔, 尚增强, 等. 结合声门流和声纹特征的伪造语音检测[J]. 声学学报, 2025, 50(6):1679-1689. | |
| [54] | LIU Xiaolong, YU Yang, LI Xiaolong, et al. Magnifying Multimodal Forgery Clues for Deepfake Detection[EB/OL]. (2023-07-07)[2025-08-10]. https://doi.org/10.1016/j.image.2023.117010. |
| [55] | TAK H, TODISCO M, WANG Xin, et al. Automatic Speaker Verification Spoofing and Deepfake Detection Using Wav2vec 2.0 and Data Augmentation[C]// ISCA. Odyssey 2022:The Speaker and Language Recognition Workshop. New York: IEEE, 2022: 100-106. |
| [56] | LAVRENTYEVA G, NOVOSELOV S, TSEREN A, et al. STC Anti-Spoofing Systems for the ASVspoof 2019 Challenge[C]// ISCA. The 20th Annual Conference of the International Speech Communication Association. New York: IEEE, 2019: 1033-1037. |
| [57] | TAK H, PATINO J, TODISCO M, et al. End-to-End Anti-Spoofing with RawNet2[C]// IEEE. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). New York: IEEE, 2021: 6369-6373. |
| [58] | JUNG J W, HEO H S, TAK H, et al. AASIST: Audio Anti-Spoofing Using Integrated Spectro-Temporal Graph Attention Networks[C]// IEEE. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). New York: IEEE, 2022: 6367-6371. |
| [59] | LIU Xiaohui, CHEN Xiaopeng, GAO Tianxiang, et al. Leveraging Positional-Related Local-Global Dependency for Synthetic Speech Detection[C]// IEEE. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). New York: IEEE, 2023: 1-5. |
| [60] | CAI Zexin, LI Ming. Integrating Frame-Level Boundary Detection and Deepfake Detection for Locating Manipulated Regions in Partially Spoofed Audio Forgery Attacks[J]. Computer Speech & Language, 2024, 85: 97-106. |
| [61] |
LI Menglu, ZHANG Xiaoping, ZHAO Lian. Frame-Level Temporal Difference Learning for Partial Deepfake Speech Detection[J]. IEEE Signal Processing Letters, 2025, 32: 3052-3056.
doi: 10.1109/LSP.2025.3592111 URL |
| [62] | YANG Tianle, SUN Chengzhe, LYU Siwei, et al. Forensic Deepfake Audio Detection Using Segmental Speech Features[EB/OL]. (2025-05-20)[2025-08-10]. https://doi.org/10.1016/j.forsciint.2025.112768. |
| [63] | ZHANG Kuiyuan, HUA Zhongyun, LAN Rushi, et al. Phoneme-Level Feature Discrepancies: A Key to Detecting Sophisticated Speech Deepfakes[C]// AAAI. AAAI Conference on Artificial Intelligence. Palo Alto: AAAI, 2025: 1066-1074. |
| [1] | 秦振凯, 罗起宁, 农熏衣, 于小川, 操晓春. 融合性别与情绪强度提示特征的多层次语音情感识别模型[J]. 信息网络安全, 2026, 26(3): 420-431. |
| [2] | 徐茹枝, 武晓欣, 吕畅冉. 基于Transformer的超分辨率网络对抗样本防御方法研究[J]. 信息网络安全, 2025, 25(9): 1367-1376. |
| [3] | 陈咏豪, 蔡满春, 张溢文, 彭舒凡, 姚利峰, 朱懿. 多尺度多层次特征融合的深度伪造人脸检测方法[J]. 信息网络安全, 2025, 25(9): 1456-1464. |
| [4] | 王新猛, 陈俊雹, 杨一涛, 李文瑾, 顾杜娟. 贝叶斯优化的DAE-MLP恶意流量识别模型[J]. 信息网络安全, 2025, 25(9): 1465-1472. |
| [5] | 金志刚, 李紫梦, 陈旭阳, 刘泽培. 面向数据不平衡的网络入侵检测系统研究综述[J]. 信息网络安全, 2025, 25(8): 1240-1253. |
| [6] | 王钢, 高雲鹏, 杨松儒, 孙立涛, 刘乃维. 基于深度学习的加密恶意流量检测方法研究综述[J]. 信息网络安全, 2025, 25(8): 1276-1301. |
| [7] | 张兴兰, 陶科锦. 基于高阶特征与重要通道的通用性扰动生成方法[J]. 信息网络安全, 2025, 25(5): 767-777. |
| [8] | 金增旺, 江令洋, 丁俊怡, 张慧翔, 赵波, 方鹏飞. 工业控制系统安全研究综述[J]. 信息网络安全, 2025, 25(3): 341-363. |
| [9] | 陈红松, 刘新蕊, 陶子美, 王志恒. 基于深度学习的时序数据异常检测研究综述[J]. 信息网络安全, 2025, 25(3): 364-391. |
| [10] | 李海龙, 崔治安, 沈燮阳. 网络流量特征的异常分析与检测方法综述[J]. 信息网络安全, 2025, 25(2): 194-214. |
| [11] | 武浩莹, 陈杰, 刘君. 改进Simon32/64和Simeck32/64神经网络差分区分器[J]. 信息网络安全, 2025, 25(2): 249-259. |
| [12] | 金地, 任昊, 唐瑞, 陈兴蜀, 王海舟. 基于情感辅助多任务学习的社交网络攻击性言论检测技术研究[J]. 信息网络安全, 2025, 25(2): 281-294. |
| [13] | 逄淑超, 李政骁, 曲俊怡, 马儒昊, 陈贺昌, 杜安安. 面向无目标后门攻击的投毒样本检测方法[J]. 信息网络安全, 2025, 25(12): 1878-1888. |
| [14] | 李古月, 张子豪, 毛承海, 吕锐. 基于累积量与深度学习融合的水下调制识别模型[J]. 信息网络安全, 2025, 25(10): 1554-1569. |
| [15] | 梁凤梅, 潘正豪, 刘阿建. 基于共性伪造线索感知的物理和数字人脸攻击联合检测方法[J]. 信息网络安全, 2025, 25(10): 1604-1614. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||