信息网络安全 ›› 2026, Vol. 26 ›› Issue (3): 420-431.doi: 10.3969/j.issn.1671-1122.2026.03.008
融合性别与情绪强度提示特征的多层次语音情感识别模型
秦振凯1,2, 罗起宁1, 农熏衣1, 于小川1,2( ), 操晓春3
), 操晓春3
- 1.广西警察学院信息技术学院,南宁 530028
2.广西警察学院网络安全研究中心,南宁 530028
3.中山大学网络空间安全学院,深圳 518107
-
收稿日期:2025-08-10出版日期:2026-03-10发布日期:2026-03-30 -
通讯作者:于小川 E-mail:yxc_gxpc@126.com -
作者简介:秦振凯(1996—),男,广西,高级工程师,硕士,CCF会员,主要研究方向为多模态大模型|罗起宁(2004—),男,广西,本科,CCF学生会员,主要研究方向为深度学习|农熏衣(2004—),女,广西,本科,CCF学生会员,主要研究方向为深度学习|于小川 (1968—),男,广西,教授,主要研究方向为大数据应用|操晓春(1980—),男,安徽,教授,博士,主要研究方向为计算机视觉、网络空间内容安全 -
基金资助:广西重点研发计划(桂科AB22035034)
Multi-Level Speech Emotion Recognition Model Integrating Gender and Emotional Intensity Cue Features
QIN Zhenkai1,2, LUO Qining1, NONG Xunyi1, YU Xiaochuan1,2(), CAO Xiaochun3
- 1. School of Information Technology, Guangxi Police College, Nanning 530028, China
2. Network Security Research Center, Guangxi Police College, Nanning 530028, China
3. School of Cyber Science and Technology, Sun Yat-sen University, Shenzhen 518107, China
-
Received:2025-08-10Online:2026-03-10Published:2026-03-30
摘要:
为解决复杂情境下语音情感识别准确率低的问题,文章基于深度卷积神经网络构建 SACER模型,以提升识别性能。首先,通过梅尔频率倒谱系数(MFCC)提取语音信号的频谱特征,以精确捕捉语音中的关键频率信息;然后,利用动态提示特征嵌入技术,将性别和情绪强度等背景信息进行有机融合,进而提升模型在复杂语境下对个体差异的适应能力;最后,借助深度卷积神经网络,对语音信号的局部和全局特征进行多层次提取与联合建模,从而全面捕捉语音信号中的细微情绪波动及其全局背景特征。在 RAVDESS语音情感数据集上的实验结果表明,该模型在多种情感类别和不同个体差异下的表现均优于基于注意力机制与LSTM的语音情绪识别等主流方法,其准确率达到94.58%,相较于对比方法平均提升约11.73%,这证明了该模型在语音情感识别任务中的高准确性。
中图分类号:
引用本文
秦振凯, 罗起宁, 农熏衣, 于小川, 操晓春. 融合性别与情绪强度提示特征的多层次语音情感识别模型[J]. 信息网络安全, 2026, 26(3): 420-431.
QIN Zhenkai, LUO Qining, NONG Xunyi, YU Xiaochuan, CAO Xiaochun. Multi-Level Speech Emotion Recognition Model Integrating Gender and Emotional Intensity Cue Features[J]. Netinfo Security, 2026, 26(3): 420-431.

图1
模型架构
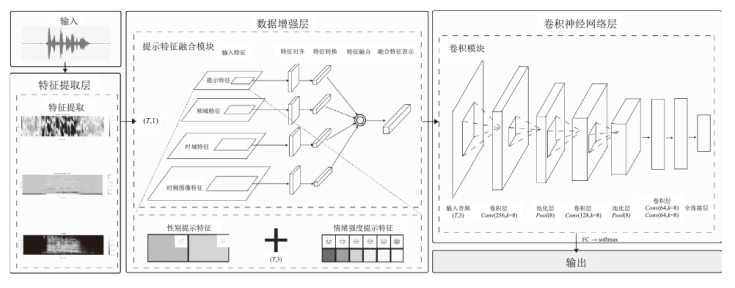
表1
数据集描述性统计
| 类别 | 描述 | 数量 |
|---|---|---|
| 总文件数 | 所有音频和视频文件 | 7356个 |
| 模式分类-语音模式 | — | 1440个 |
| 模式分类-歌唱模式 | — | 1440个 |
| 受试者人数-男性 | 12人,每人604个文件 | 12人 |
| 受试者人数-女性 | 12人,每人604个文件 | 12人 |
| 情感类别-中性 | — | 960个 |
| 情感类别-平静 | — | 960个 |
| 情感类别-快乐 | — | 960个 |
| 情感类别-悲伤 | — | 960个 |
| 情感类别-恐惧 | — | 960个 |
| 情感类别-愤怒 | — | 960个 |
| 情感类别-惊讶 | — | 960个 |
| 情感类别-厌恶 | — | 960个 |
| 强度分类-正常强度 | 平均分布 | — |
| 强度分类-强烈强度 | 平均分布 | — |
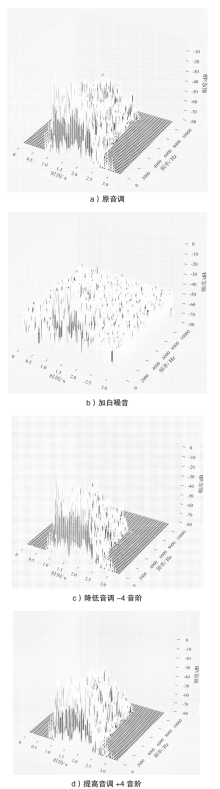
图2
数据预处理可视化

表2
核心指标定义
| 类别 | 预测 | ||
|---|---|---|---|
| 正类样本 | 负类样本 | ||
| 真实 | 正类样本 | 正确分类TP | 错误分类FN |
| 负类样本 | 错误分类FP | 正确分类TN | |
表3
对比实验结果
| 模型 | 准确率 | F1分数 | 单轮训练时间/s | 单样本推理时间/ms |
|---|---|---|---|---|
| LSTM | 50.83% | 51.15% | 0.96 | 0.49 |
| CRNN | 86.66% | 90.52% | 0.79 | 0.36 |
| CNN | 92.08% | 92.19% | 0.43 | 0.19 |
| SE | 91.25% | 91.47% | 0.57 | 0.24 |
| Transformer | 93.42% | 93.61% | 2.87 | 1.94 |
| SACER | 94.58% | 94.67% | 0.62 | 0.26 |
图3
训练和验证损失的变化曲线
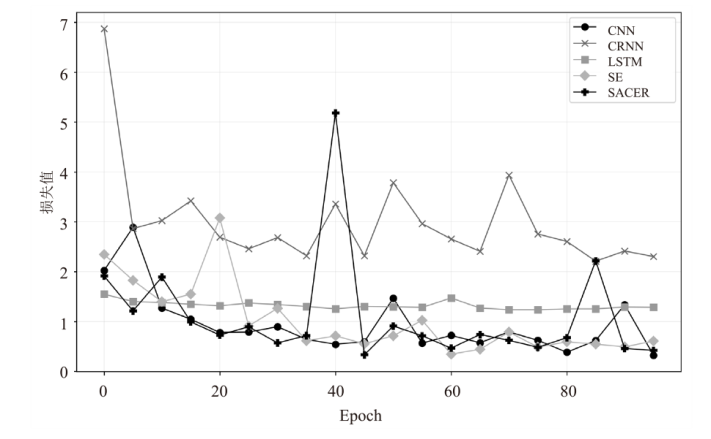
表4
多分类细粒度情绪识别任务实验结果
| 情绪/ 指标 | 精确率 | 召回率 | F1分数 | 测试样本数/个 |
|---|---|---|---|---|
| 愤怒 | 70% | 64% | 62% | 39 |
| 平静 | 88% | 73% | 85% | 38 |
| 厌恶 | 58% | 69% | 69% | 38 |
| 恐惧 | 55% | 52% | 53% | 39 |
| 快乐 | 66% | 61% | 63% | 39 |
| 中性 | 90% | 88% | 69% | 19 |
| 悲伤 | 77% | 65% | 86% | 38 |
| 惊讶 | 62% | 60% | 61% | 38 |
| 宏平均 | 70% | 61% | 61% | 288 |
| 加权平均 | 62% | 61% | 61% | 288 |
表5
消融实验结果
| 模型 | 准确率 | F1分数 |
|---|---|---|
| SACER | 94.58% | 94.67% |
| SACER-Intensity | 50.41% | 45.76% |
| SACER-Gender | 51.66% | 50.51% |
| SACER-Random | 91.66% | 91.73% |
| [1] |
NEAL T M S, SLOBOGIN C, SAKS M J, et al. Psychological Assessments in Legal Contexts: Are Courts Keeping “Junk Science” Out of the Courtroom[J]. Psychological Science in the Public Interest, 2019, 20(3): 135-164.
doi: 10.1177/1529100619888860 URL |
| [2] |
CHAO Yadong, WANG Huapeng, LIU En, et al. Polygraphing from Speech Stress through Layered Voice Analysis[J]. Forensic Science and Technology, 2020, 45(2): 155-159.
doi: 10.16467/j.1008-3650.2020.02.008 |
|
晁亚东, 王华朋, 刘恩, 等. 基于语音情感分析系统的语音压力测谎[J]. 刑事技术, 2020, 45(2):155-159.
doi: 10.16467/j.1008-3650.2020.02.008 |
|
| [3] | KAPPEN M, VANHOLLEBEKE G, VAN D D J, et al. Acoustic and Prosodic Speech Features Reflect Physiological Stress but Not Isolated Negative Affect: A Multi-Paradigm Study on Psychosocial Stressors[EB/OL]. (2024-03-06)[2025-06-10]. https://doi.org/10.1038/s41598-024-55550-3. |
| [4] |
WANG Shanmin, LIU Chengguang, CHEN Shengyu, et al. A Survey of Multimodal Emotion Recognition from Facial Expressions, Audios, and Language[J]. Journal of Image and Graphics, 2025, 30(6): 2120-2138.
doi: 10.11834/jig.250168 URL |
| 王善敏, 刘成广, 陈胜宇, 等. 面向表情、语音和语言的多模态情感识别综述[J]. 中国图象图形学报, 2025, 30(6):2120-2138. | |
| [5] | SCHEWSKI L, DOSS M M, BELDI G, et al. Measuring Negative Emotions and Stress through Acoustic Correlates in Speech: A Systematic Review[EB/OL]. (2025-07-24)[2025-07-30]. https://doi.org/10.1371/journal.pone.0328833. |
| [6] |
FUKUSHIMA K. Neocognitron: A Self-Organizing Neural Network Model for a Mechanism of Pattern Recognition Unaffected by Shift in Position[J]. Biological Cybernetics, 1980, 36(4): 193-202.
doi: 10.1007/BF00344251 URL |
| [7] |
SCHUSTER M, PALIWAL K K. Bidirectional Recurrent Neural Networks[J]. IEEE Transactions on Signal Processing, 1997, 45(11): 2673-2681.
doi: 10.1109/78.650093 URL |
| [8] | LIU Ying, YUAN Li, ZU Shuodi, et al. Emotion Recognition Based on Multimodal Physiological Data: A Survey[J]. Journal of University of Electronic Science and Technology of China, 2024, 53(5): 720-731. |
| 刘颖, 袁莉, 祖铄迪, 等. 基于多模态生理数据的情感识别综述[J]. 电子科技大学学报, 2024, 53(5):720-731. | |
| [9] | LI Haifeng, CHEN Jing, MA Lin, et al. Dimensional Speech Emotion Recognition Review[J]. Journal of Software, 2020, 31(8): 2465-2491. |
| 李海峰, 陈婧, 马琳, 等. 维度语音情感识别研究综述[J]. 软件学报, 2020, 31(8):2465-2491. | |
| [10] | JORDAN E, TERRISSE R, LUCARINI V, et al. Speech Emotion Recognition in Mental Health: Systematic Review of Voice-Based Applications[EB/OL]. [2025-07-30]. https://pubmed.ncbi.nlm.nih.gov/41027025/. |
| [11] | ZHANG Mengxing. On Application and Legitimacy Review of Demeanor Evidence in the Construction of Intelligent Judicature[J]. Journal of Henan University of Economics and Law, 2023, 38(2): 114-123. |
| 张梦星. 智慧司法建设中情态证据的应用与合法性审查研究[J]. 河南财经政法大学学报, 2023, 38(2):114-123. | |
| [12] | SHI Pengcheng, WANG Hailong, LIU Lin. Emotion Recognition from Physiological Signals: A Review of Cross-Domain Transfer and Multimodal Fusion[EB/OL]. [2025-08-10]. http://fcst.ceaj.org/CN/10.3778/j.issn.1673-9418.2505043. |
| 史鹏程, 王海龙, 柳林. 生理信号情感识别:跨域迁移与多模态融合综述[EB/OL]. [2025-08-10]. http://fcst.ceaj.org/CN/10.3778/j.issn.1673-9418.2505043. | |
| [13] | YANG Jie, LIANG Changwei, WU Xiyu, et al. A Study on Speech Emotion Evaluation Scale Based on Physiology and Acoustics Features[J]. Essays on Linguistics, 2023(4): 3-19. |
| 杨洁, 梁昌维, 吴西愉, 等. 基于生理声学的语音情感评价尺度研究[J]. 语言学论丛, 2023(4):3-19. | |
| [14] | ZHANG Yusha, JIANG Shengyi. Speech Emotion Data Mining Classification and Recognition Method Based on MFCC Feature Extraction and Improved SVM[J]. Computer Applications and Software, 2020, 37(8): 160-165. |
| 张钰莎, 蒋盛益. 基于MFCC特征提取和改进SVM的语音情感数据挖掘分类识别方法研究[J]. 计算机应用与软件, 2020, 37(8):160-165. | |
| [15] | KWAK I Y, KWAG S, LEE J, et al. ResMax: Detecting Voice Spoofing Attacks with Residual Network and Max Feature Map[C]// IEEE. 2020 25th International Conference on Pattern Recognition (ICPR). New York: IEEE, 2021: 4837-4844. |
| [16] | JIANG Nan, PANG Yongheng, GAO Shuang. Speech Recognition Based on Attention Mechanism and Spectrogram Feature Extraction[J]. Journal of Jilin University (Science Edition), 2024, 62(2): 320-330. |
| 姜囡, 庞永恒, 高爽. 基于注意力机制语谱图特征提取的语音识别[J]. 吉林大学学报(理学版), 2024, 62(2):320-330. | |
| [17] | CHEN Qiaohong, YU Zeyuan, SUN Qi, et al. Speech Emotion Recognition Based on Attention Mechanism and LSTM[J]. Journal of Zhejiang Sci-Tech University (Natural Sciences), 2020, 48(6): 815-822. |
| 陈巧红, 于泽源, 孙麒, 等. 基于注意力机制与LSTM的语音情绪识别[J]. 浙江理工大学学报(自然科学版), 2020, 48(6):815-822. | |
| [18] | SANG D V, CUONG L T B. Improving CRNN with EfficientNet-Like Feature Extractor and Multi-Head Attention for Text Recognition[C]// ACM. The Tenth International Symposium on Information and Communication Technology-SoICT 2019. New York: ACM, 2019: 285-290. |
| [19] | HAN Yongming, ZHANG Mingxing, GENG Zhiqiang. Heart Rate Variability Features for Emotion Dimensional Prediction by Using a Principal Component Analysis-Support Vector Regression (PCA-SVR) Model[J]. Journal of Beijing University of Chemical Technology (Natural Science Edition), 2021, 48(5): 102-110. |
|
韩永明, 张明星, 耿志强. 基于心率变异性特征和PCA-SVR的PAD维度情感预测分析[J]. 北京化工大学学报(自然科学版), 2021, 48(5):102-110.
doi: 10.13543/j.bhxbzr.2021.05.013 |
|
| [20] | XIAO Xi, XU Chen. Speech Feature Fusion Algorithm Based on Acoustic State Likelihood and Supervised State Modelling[J]. Journal of Tsinghua University (Science and Technology), 2019, 59(6): 476-481. |
|
肖熙, 徐晨. 基于声学状态似然值得分模型及监督状态模型的语音识别特征融合算法[J]. 清华大学学报(自然科学版), 2019, 59(6):476-481.
doi: 10.16511/j.cnki.qhdxxb.2019.21.011 |
|
| [21] | YUE Liya, HU Pei, ZHU Jiulong. Advanced Differential Evolution for Gender-Aware English Speech Emotion Recognition[EB/OL]. (2024-07-31)[2025-07-10]. https://pmc.ncbi.nlm.nih.gov/articles/PMC11291894/. |
| [22] | JIA Junwei, JIANG Nan. Correlation Analysis of Multimodal Lie Features Based on Speech and Physiological Signals[J]. Electro-Optic Technology Application, 2020, 35(4): 26-30. |
| 贾俊玮, 姜囡. 基于语音和生理信号的多模态谎言特征相关性分析[J]. 光电技术应用, 2020, 35(4):26-30. | |
| [23] |
ABDUL Z K, AL-TALABANI A K. Mel Frequency Cepstral Coefficient and Its Applications: A Review[J]. IEEE Access, 2022, 10: 122136-122158.
doi: 10.1109/ACCESS.2022.3223444 URL |
| [24] |
MATEO C, TALAVERA J A. Bridging the Gap between the Short-Time Fourier Transform (STFT), Wavelets, the Constant-Q Transform and Multi-Resolution STFT[J]. Signal, Image and Video Processing, 2020, 14(8): 1535-1543.
doi: 10.1007/s11760-020-01701-8 |
| [25] | KUMAR Y S, KUMAR R, KUMAR S. 2D-Discrete Cosine Transform Based Dynamically Controllable Image Compression Technique[C]// IEEE. 2020 IEEE 22nd Electronics Packaging Technology Conference (EPTC). New York: IEEE, 2020: 203-206. |
| [26] | ZHAI Yuting, WANG Xin, BAI Lei. Dynamic Task Scheduling for Wireless Sensor Networks Based on an Improved Bat Algorithm[J]. Chinese Journal of Sensors and Actuators, 2024, 37(4): 704-708. |
| 翟羽婷, 王欣, 白蕾. 基于改进蝙蝠算法的无线传感器网络动态任务调度[J]. 传感技术学报, 2024, 37(4):704-708. | |
| [27] |
CHEN Xi, ITA L S, LEVINE M, et al. Acoustic-Prosodic and Lexical Cues to Deception and Trust: Deciphering How People Detect Lies[J]. Transactions of the Association for Computational Linguistics, 2020, 8: 199-214.
doi: 10.1162/tacl_a_00311 URL |
| [28] | ZHAO Li, LIANG Ruiyu, XIE Yue, et al. Progress and Outlook of Lie Detection Technique in Speech[J]. Journal of Data Acquisition and Processing, 2017, 32(2): 246-257. |
| 赵力, 梁瑞宇, 谢跃, 等. 语音测谎技术研究现状与展望[J]. 数据采集与处理, 2017, 32(2):246-257. | |
| [29] |
GENG Lili, NIU Baoning. Convolutional Neural Network Pruning Based on Channel Similarity Entropy[J]. Computer Engineering, 2024, 50(7): 133-143.
doi: 10.19678/j.issn.1000-3428.0068284 |
|
耿丽丽, 牛保宁. 基于通道相似度熵的卷积神经网络裁剪[J]. 计算机工程, 2024, 50(7):133-143.
doi: 10.19678/j.issn.1000-3428.0068284 |
|
| [30] | WANG Di, XU Yong, LI Hongliang, et al. Kernel Normalization[J]. Computer Technology and Development, 2019, 29(12): 27-32. |
| 王迪, 许勇, 李宏亮, 等. 卷积核归一化[J]. 计算机技术与发展, 2019, 29(12):27-32. | |
| [31] | SHATRAVIN V, SHASHEV D, SHIDLOVSKIY S. Implementation of the SoftMax Activation for Reconfigurable Neural Network Hardware Accelerators[EB/OL]. (2023-11-28)[2025-07-10]. https://www.mdpi.com/2076-3417/13/23/12784. |
| [32] | MAO Anqi, MOHRI M, ZHONG Yutao. Cross-Entropy Loss Functions: Theoretical Analysis and Applications[C]// ACM. The 40th International Conference on Machine Learning (ICML’23). New York: ACM, 2023: 23803-23828. |
| [33] | GUPTA M V, VAIKOLE S, OZA A D, et al. Audio-Visual Stress Classification Using Cascaded RNN-LSTM Networks[EB/OL]. (2022-09-27)[2025-07-10]. https://pmc.ncbi.nlm.nih.gov/articles/PMC9598122/. |
| [34] | QIN Libo, LI Zhouyang, CHE Wanxiang, et al. Co-GAT: A Co-Interactive Graph Attention Network for Joint Dialog Act Recognition and Sentiment Classification[C]// AAAI. The AAAI Conference on Artificial Intelligence. Palo Alto: AAAI, 2021: 13709-13717. |
| [35] | SUN Chao, ZHANG Min, WU Ruijuan, et al. A Convolutional Recurrent Neural Network with Attention Framework for Speech Separation in Monaural Recordings[EB/OL]. (2021-01-14)[2025-07-30]. https://pmc.ncbi.nlm.nih.gov/articles/PMC7809293/. |
| [36] | HU Jie, SHEN Li, SUN Gang. Squeeze-and-Excitation Networks[C]// IEEE. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2018: 7132-7141. |
| [37] | VASWANI A, SHAZEER N, PARMAR N, et al. Attention Is All You Need[EB/OL]. (2023-08-02)[2025-07-30]. https://doi.org/10.48550/arXiv.1706.03762. |
| [1] | 徐衍微, 涂敏, 张亮. 深度伪造语音真实性鉴定研究综述[J]. 信息网络安全, 2026, 26(3): 367-377. |
| [2] | 徐茹枝, 武晓欣, 吕畅冉. 基于Transformer的超分辨率网络对抗样本防御方法研究[J]. 信息网络安全, 2025, 25(9): 1367-1376. |
| [3] | 陈咏豪, 蔡满春, 张溢文, 彭舒凡, 姚利峰, 朱懿. 多尺度多层次特征融合的深度伪造人脸检测方法[J]. 信息网络安全, 2025, 25(9): 1456-1464. |
| [4] | 王新猛, 陈俊雹, 杨一涛, 李文瑾, 顾杜娟. 贝叶斯优化的DAE-MLP恶意流量识别模型[J]. 信息网络安全, 2025, 25(9): 1465-1472. |
| [5] | 金志刚, 李紫梦, 陈旭阳, 刘泽培. 面向数据不平衡的网络入侵检测系统研究综述[J]. 信息网络安全, 2025, 25(8): 1240-1253. |
| [6] | 王钢, 高雲鹏, 杨松儒, 孙立涛, 刘乃维. 基于深度学习的加密恶意流量检测方法研究综述[J]. 信息网络安全, 2025, 25(8): 1276-1301. |
| [7] | 张兴兰, 陶科锦. 基于高阶特征与重要通道的通用性扰动生成方法[J]. 信息网络安全, 2025, 25(5): 767-777. |
| [8] | 金增旺, 江令洋, 丁俊怡, 张慧翔, 赵波, 方鹏飞. 工业控制系统安全研究综述[J]. 信息网络安全, 2025, 25(3): 341-363. |
| [9] | 陈红松, 刘新蕊, 陶子美, 王志恒. 基于深度学习的时序数据异常检测研究综述[J]. 信息网络安全, 2025, 25(3): 364-391. |
| [10] | 李海龙, 崔治安, 沈燮阳. 网络流量特征的异常分析与检测方法综述[J]. 信息网络安全, 2025, 25(2): 194-214. |
| [11] | 武浩莹, 陈杰, 刘君. 改进Simon32/64和Simeck32/64神经网络差分区分器[J]. 信息网络安全, 2025, 25(2): 249-259. |
| [12] | 金地, 任昊, 唐瑞, 陈兴蜀, 王海舟. 基于情感辅助多任务学习的社交网络攻击性言论检测技术研究[J]. 信息网络安全, 2025, 25(2): 281-294. |
| [13] | 逄淑超, 李政骁, 曲俊怡, 马儒昊, 陈贺昌, 杜安安. 面向无目标后门攻击的投毒样本检测方法[J]. 信息网络安全, 2025, 25(12): 1878-1888. |
| [14] | 李古月, 张子豪, 毛承海, 吕锐. 基于累积量与深度学习融合的水下调制识别模型[J]. 信息网络安全, 2025, 25(10): 1554-1569. |
| [15] | 梁凤梅, 潘正豪, 刘阿建. 基于共性伪造线索感知的物理和数字人脸攻击联合检测方法[J]. 信息网络安全, 2025, 25(10): 1604-1614. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||