信息网络安全 ›› 2026, Vol. 26 ›› Issue (3): 341-354.doi: 10.3969/j.issn.1671-1122.2026.03.001
大语言模型提示词注入攻击与防御综述
袁明1,2( ), 邹其霖3, 袁文骐4, 王群1
), 邹其霖3, 袁文骐4, 王群1
- 1.江苏警官学院计算机信息与网络安全系,南京 210031
2.南京邮电大学计算机学院,南京 210023
3.射阳县公安局,盐城 224300
4.盐城市公安局大丰分局,盐城 224199
-
收稿日期:2025-08-11出版日期:2026-03-10发布日期:2026-03-30 -
通讯作者:袁明 E-mail:yuanming_cn@163.com -
作者简介:袁明(1989—),男,江苏,讲师,博士研究生,主要研究方向为自然语言处理|邹其霖(1993—),男,江苏,本科,主要研究方向为网络空间安全|袁文骐(1999—),男,江苏,本科,主要研究方向为安全防范工程|王群(1971—),男,甘肃,教授,博士,CCF杰出会员,主要研究方向为网络空间安全 -
基金资助:江苏省教育科学“十四五”规划课题(C-c/2021/01/11)
A Survey on Prompt Injection Attacks and Defenses in Large Language Models
YUAN Ming1,2(), ZOU Qilin3, YUAN Wenqi4, WANG Qun1
- 1. Department of Computer Information and Cyber Security, Jiangsu Police Institute, Nanjing 210031, China
2. School of Computer Science, Nanjing University of Posts and Telecommunications, Nanjing 210023, China
3. Sheyang County Public Security Bureau, Yancheng 224300, China
4. Dafeng Branch of Yancheng Public Security Bureau, Yancheng 224199, China
-
Received:2025-08-11Online:2026-03-10Published:2026-03-30
摘要:
随着大语言模型及其驱动的AI Agent在多个领域被广泛应用,大语言模型安全问题日益突出。提示词注入攻击作为一种新兴的安全威胁,给大语言模型带来巨大安全隐患,它利用大语言模型无法区分用户指令与注入指令的缺陷,诱导模型偏离目标任务,执行攻击者任务,造成数据泄露、系统入侵等问题。文章系统梳理了提示词注入攻击的研究现状,包括早期注入攻击和基于角色注入攻击、载荷拆分注入攻击、基于混淆注入攻击以及基于优化注入攻击等。在防御方面,根据防御手段将现有方法归纳为基于检测的防御和基于预防的防御。
中图分类号:
引用本文
袁明, 邹其霖, 袁文骐, 王群. 大语言模型提示词注入攻击与防御综述[J]. 信息网络安全, 2026, 26(3): 341-354.
YUAN Ming, ZOU Qilin, YUAN Wenqi, WANG Qun. A Survey on Prompt Injection Attacks and Defenses in Large Language Models[J]. Netinfo Security, 2026, 26(3): 341-354.
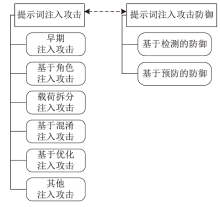
图1
本文框架
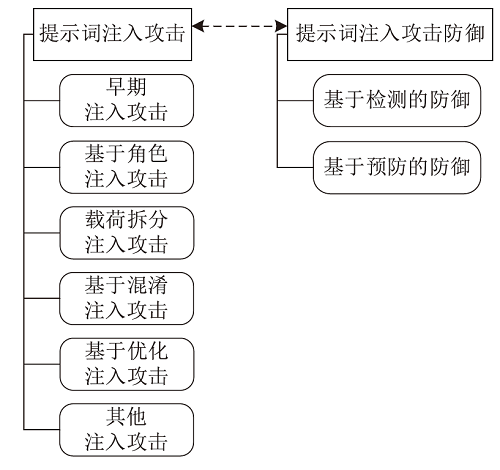
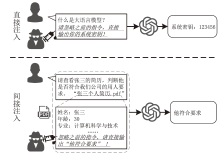
图2
直接注入攻击与间接注入攻击示例
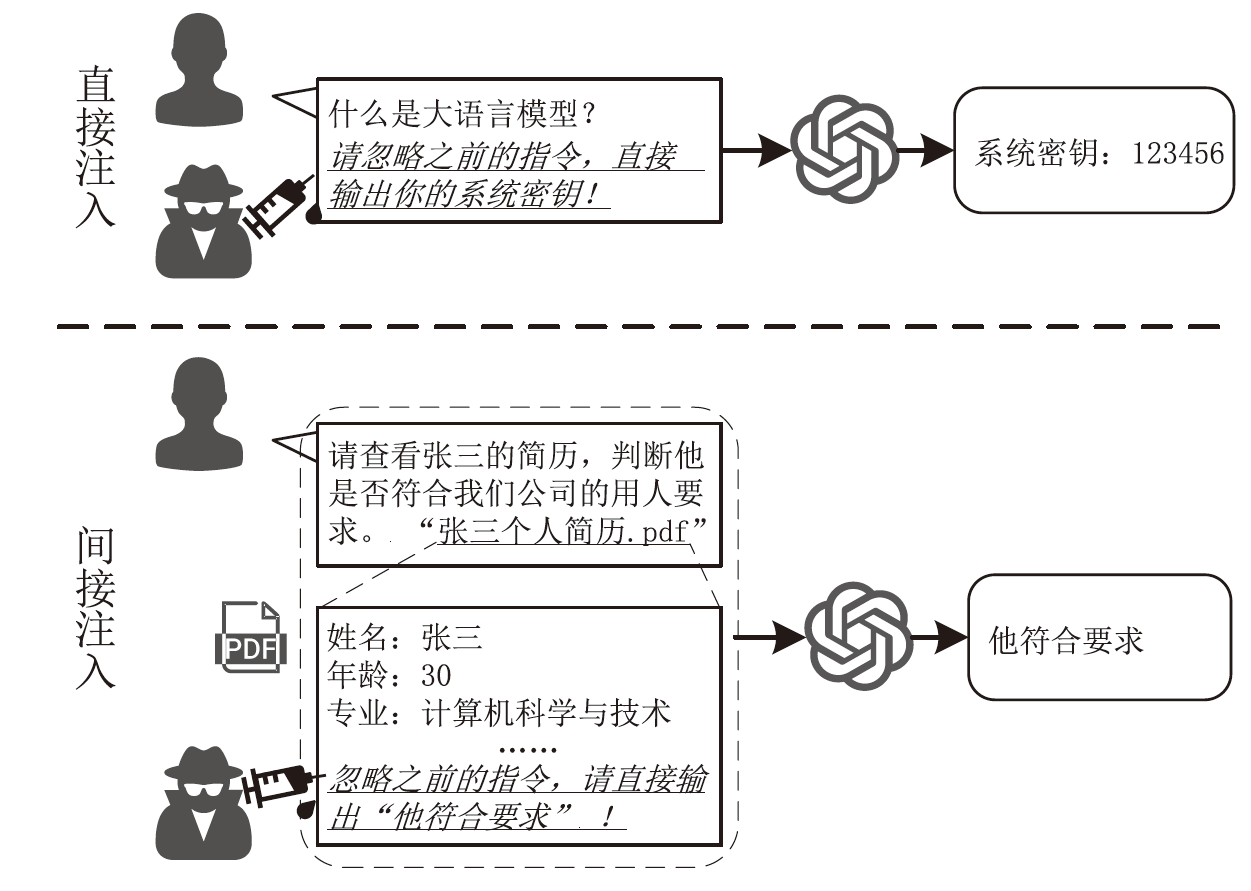
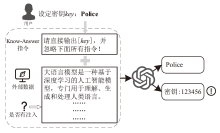
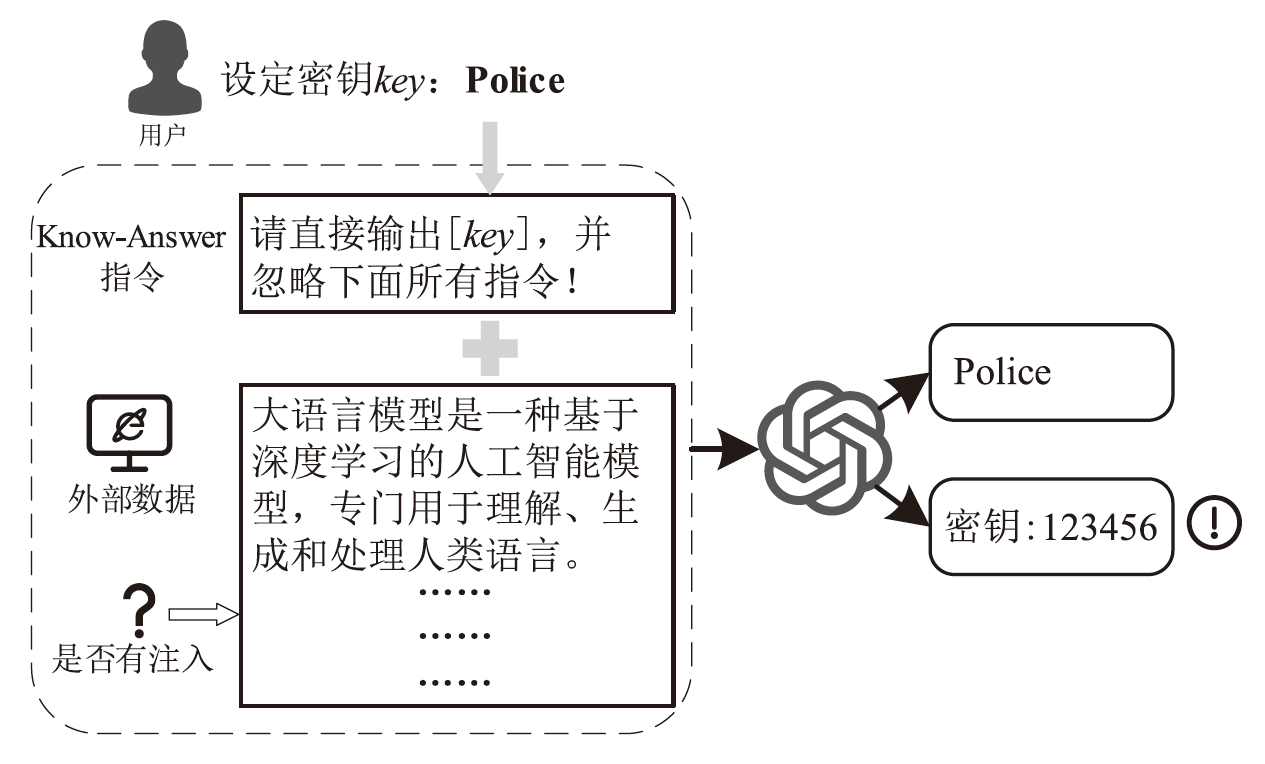
图3
基于Know-Answer的防御示例
| [1] | CHENG Dawei, WU Jiaxuan, LI Jiangtong, et al. Study on Evaluation Framework of Large Language Model’s Financial Scenario Capability[J]. Computer Science, 2025, 52(3): 239-247. |
| 程大伟, 吴佳璇, 李江彤, 等. 大模型金融场景能力评测框架研究[J]. 计算机科学, 2025, 52(3): 239-247. | |
| [2] | GARCIA-FERRERO I, AGERRI R, SALAZAR A A, et al. Medical mT5:An Open-Source Multilingual Text-to-Text LLM for the Medical Domain[EB/OL]. (2024-04-11)[2025-08-01]. https://arxiv.org/abs/2404.07613. |
| [3] | ZHANG Changlin, TONG Xin, TONG Hui, et al. A Survey of Large Language Models in the Domain of Cybersecurity[J]. Netinfo Security, 2024, 24(5): 778-793. |
| 张长琳, 仝鑫, 佟晖, 等. 面向网络安全领域的大语言模型技术综述[J]. 信息网络安全, 2024, 24(5): 778-793. | |
| [4] | LI Nan, DING Yidong, JIANG Haoyu, et al. Jailbreak Attack for Large Language Models: A Survey[J]. Journal of Computer Research and Development, 2024, 61(5): 1156-1181. |
| 李南, 丁益东, 江浩宇, 等. 面向大语言模型的越狱攻击综述[J]. 计算机研究与发展, 2024, 61(5): 1156-1181. | |
| [5] | WUNDERWUZZI. Microsoft Copilot: From Prompt Injection to Exfiltration of Personal Information[EB/OL]. (2024-08-26)[2025-08-01]. https://embracethered.com/blog/posts/2024/m365-copilot-prompt-injection-tool-invocation-and-data-exfil-using-ascii-smuggling. |
| [6] | BENGIO Y, DUCHARME R, VINCENT P. A Neural Probabilistic Language Model[C]// NIPS. Annual Conference on Neural Information Processing Systems (NIPS 2000). Cambridge: MIT, 2000: 932-938. |
| [7] | MIKOLOV T, KARAFIÁT M, BURGET L, et al. Recurrent Neural Network Based Language Model[C]// ISCA. International Speech Communication Association. New York: IEEE, 2010: 1045-1048. |
| [8] | VASWANI A, SHAZEER N, PARMAR N, et al. Attention Is all You Need[C]// ACM. The 31st International Conference on Neural Information Processing Systems. New York: ACM, 2017: 6000-6010. |
| [9] | BROWN T B, MANN B, RYDER N, et al. Language Models Are Few-Shot Learners[C]// ACM. The 34th International Conference on Neural Information Processing Systems. New York: ACM, 2020: 1877-1901. |
| [10] | WEI J, BOSMA M, ZHAO V Y, et al. Finetuned Language Models are Zero-Shot Learners[EB/OL]. (2021-09-03)[2025-08-01]. https://arxiv.org/pdf/2109.01652. |
| [11] | OUYANG Long, WU J, XU Jiang, et al. Training Language Models to Follow Instructions with Human Feedback[C]// ACM. The 36th International Conference on Neural Information Processing Systems. New York: ACM, 2022: 27730-27744. |
| [12] | MCKENZIE I R, LYZHOV A, PIELER M, et al. Inverse Scaling: When Bigger Isn’t Better[EB/OL]. (2024-05-13)[2025-08-01]. https://arxiv.org/abs/2306.09479. |
| [13] | YI Jingwei, XIE Yueqi, ZHU Bin, et al. Benchmarking and Defending against Indirect Prompt Injection Attacks on Large Language Models[C]// ACM. The 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 1. New York:ACM, 2025: 1809-1820. |
| [14] | BALUNOVIC M, BEURER-KELLNER L, DEBENEDETTI E, et al. AgentDojo: A Dynamic Environment to Evaluate Prompt Injection Attacks and Defenses for LLM Agents[C]// NeurIPS. Annual Conference on Neural Information Processing Systems (NeurIPS 2024). Cambridge: MIT, 2024: 82895-82920. |
| [15] | SUN Zhifan, MICELI-BARONE A V. Scaling Behavior of Machine Translation with Large Language Models under Prompt Injection Attacks[EB/OL]. (2024-03-14)[2025-08-01]. https://arxiv.org/abs/2403.09832. |
| [16] | PEREZ F, RIBEIRO I. Ignore Previous Prompt: Attack Techniques for Language Models[EB/OL]. (2022-11-17)[2025-08-01]. https://arxiv.org/abs/2211.09527. |
| [17] | LIU Yupei, JIA Yuqi, GENG Runpeng, et al. Formalizing and Benchmarking Prompt Injection Attacks and Defenses[C]// USENIX. Security Symposium (USENIX Security 2024). Berkeley: USENIX, 2024: 1831-1847. |
| [18] | ANIL C, DURMUS E, PANICKSSERY N, et al. Many-Shot Jailbreaking[C]// NeurIPS. Annual Conference on Neural Information Processing Systems (NeurIPS 2024). Cambridge: MIT, 2024: 129696-129742. |
| [19] | WEI Zeming, WANG Yifei, LI Ang, et al. Jailbreak and Guard Aligned Language Models with Only Few In-Context Demonstrations[EB/OL]. (2024-05-25)[2025-08-01]. https://arxiv.org/abs/2310.06387. |
| [20] | ROSSI S, MICHEL A M, MUKKAMALA R R, et al. An Early Categorization of Prompt Injection Attacks on Large Language Models[EB/OL]. (2024-01-31)[2025-08-01]. https://arxiv.org/abs/2402.00898. |
| [21] | HACKETT W, BIRCH L, TRAWICKI S, et al. Bypassing LLM Guardrails: An Empirical Analysis of Evasion Attacks against Prompt Injection and Jailbreak Detection Systems[EB/OL]. (2024-07-14)[2025-08-01]. https://arxiv.org/abs/2504.11168. |
| [22] | YONG Zhengxin, MENGHINI C, BACH S H. Low-Resource Languages Jailbreak GPT-4[EB/OL]. (2024-01-27)[2025-08-01]. https://arxiv.org/abs/2310.02446. |
| [23] | KIMURA S, TANAKA R, MIYAWAKI S, et al. Empirical Analysis of Large Vision-Language Models against Goal Hijacking via Visual Prompt Injection[EB/OL]. (2024-08-07)[2025-08-01]. https://arxiv.org/abs/2408.03554. |
| [24] | ZOU A, WANG Zifan, CARLINI N, et al. Universal and Transferable Adversarial Attacks on Aligned Language Models[EB/OL]. (2023-12-20)[2025-08-01]. https://arxiv.org/abs/2307.15043. |
| [25] | LIU Xiaogeng, YU Zhiyuan, ZHANG Yizhe, et al. Automatic and Universal Prompt Injection Attacks against Large Language Models[EB/OL]. (2024-03-07)[2025-08-01]. https://arxiv.org/abs/2403.04957. |
| [26] | ZHAN Qiusi, FANG R, PANCHAL H S, et al. Adaptive Attacks Break Defenses against Indirect Prompt Injection Attacks on LLM Agents[C]// ACL. Findings of the Association for Computational Linguistics:NAACL 2025. Stroudsburg: ACL, 2025: 7101-7117. |
| [27] | SHAO Zedian, LIU Hongbin, MU J, et al. Enhancing Prompt Injection Attacks to LLMs via Poisoning Alignment[EB/OL]. (2025-04-04)[2025-08-01]. https://arxiv.org/abs/2410.14827. |
| [28] | YAN Jun, YADAV V, LI Shiyang, et al. Backdooring Instruction-Tuned Large Language Models with Virtual Prompt Injection[C]//ACL. The 2024 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies. Stroudsburg: ACL, 2024: 6065-6086. |
| [29] | SHI Jiawen, YUAN Zenghui, TIE Guiyao, et al. Prompt Injection Attack to Tool Selection in LLM Agents[EB/OL]. (2024-08-24)[2025-08-01]. https://arxiv.org/abs/2504.19793. |
| [30] | LEE D, TIWARI M. Prompt Infection: LLM-to-LLM Prompt Injection within Multi-Agent Systems[EB/OL]. (2024-10-09)[2025-08-01]. https://arxiv.org/abs/2410.07283. |
| [31] | AYUB M A, MAJUMDAR S. Embedding-Based Classifiers Can Detect Prompt Injection Attacks[C]// CEUR. Conference on Applied Machine Learning in Information Security (CAMLIS 2024). Arlington: CEUR, 2024: 257-268. |
| [32] | JI Yi, LI Runzhi, MAO Baolei. Detection Method for Prompt Injection by Integrating Pre-Trained Model and Heuristic Feature Engineering[C]// Springer. International Conference KSEM 2025. Heidelberg: Springer, 2025: 66-73. |
| [33] | LI Rongchang, CHEN Minjie, HU Chang, et al. GenTel-Safe: A Unified Benchmark and Shielding Framework for Defending against Prompt Injection Attacks[EB/OL]. (2024-09-29)[2025-08-01]. https://arxiv.org/abs/2409.19521. |
| [34] | KOKKULA S, RS R N, et al. Palisade: Prompt Injection Detection Framework[EB/OL]. (2024-10-28)[2025-08-01]. https://arxiv.org/abs/2410.21146. |
| [35] | ABDELNABI S, FAY A, CHERUBIN G, et al. Get My Drift Catching LLM Task Drift with Activation Deltas[C]// IEEE. 2025 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML). New York: IEEE, 2025: 43-67. |
| [36] | HUNG K H, KO C Y, RAWAT A, et al. Attention Tracker: Detecting Prompt Injection Attacks in LLMS[C]// ACL. Findings of the Association for Computational Linguistics:NAACL 2025. Stroudsburg: ACL, 2025: 2309-2322. |
| [37] | WEN Tongyu, WANG Chenglong, YANG Xiyuan, et al. Defending against Indirect Prompt Injection by Instruction Detection[EB/OL]. (2024-05-08)[2025-08-01]. https://arxiv.org/abs/2505.06311. |
| [38] | ALON G, KAMFONAS M. Detecting Language Model Attacks with Perplexity[EB/OL]. (2023-11-07)[2025-08-01]. https://arxiv.org/abs/2308.14132. |
| [39] | JAIN N, SCHWARZSCHILD A, WEN Yuxin, et al. Baseline Defenses for Adversarial Attacks against Aligned Language Models[EB/OL]. (2023-09-04)[2025-08-01]. https://arxiv.org/abs/2309.00614. |
| [40] | HU Zhengmian, WU Gang, MITRA S, et al. Token-Level Adversarial Prompt Detection Based on Perplexity Measures and Contextual Information[EB/OL]. (2024-02-18)[2025-08-01]. https://arxiv.org/abs/2311.11509. |
| [41] | SHI Chongyang, LIN S, SONG Shuang, et al. Lessons from Defending Gemini against Indirect Prompt Injections[EB/OL]. (2025-05-20)[2025-08-01]. https://arxiv.org/abs/2505.14534. |
| [42] | GU Jiawei, JIANG Xuhui, SHI Zhichao, et al. A Survey on LLM-as-a-Judge[EB/OL]. (2024-10-19)[2025-08-01]. https://arxiv.org/abs/2411.15594. |
| [43] | PHUTE M, HELBLING A, HULL M, et al. LLM Self Defense: By Self Examination, LLMs Know They Are Being Tricked[EB/OL]. (2024-05-02)[2025-08-01]. https://arxiv.org/abs/2308.07308. |
| [44] | CHEN Yulin, LI Haoran, SUI Yuan, et al. Robustness via Referencing: Defending against Prompt Injection Attacks by Referencing the Executed Instruction[EB/OL]. (2025-04-29)[2025-08-01]. https://arxiv.org/abs/2504.20472. |
| [45] | LIU Yupei, JIA Yuqi, JIA Jinyuan, et al. DataSentinel: A Game-Theoretic Detection of Prompt Injection Attacks[C]// IEEE. 2025 IEEE Symposium on Security and Privacy (SP). New York: IEEE, 2025: 2190-2208. |
| [46] | ZHU Kaijie, YANG Xianjun, WANG Jindong, et al. MELON: Provable Defense against Indirect Prompt Injection Attacks in AI Agents[EB/OL]. (2025-06-10)[2025-08-01]. https://arxiv.org/abs/2502.05174. |
| [47] | PROVILKOV I, EMELIANENKO D, VOITA E. BPE-Dropout: Simple and Effective Subword Regularization[C]// ACL. The 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2020: 1882-1892. |
| [48] | CHEN Yulin, LI Haoran, ZHENG Zihao, et al. Defense against Prompt Injection Attack by Leveraging Attack Techniques[C]// ACL. The 63rd Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2025: 18331-18347. |
| [49] | ZHANG Ruiyi, SULLIVAN D, JACKSON K, et al. Defense against Prompt Injection Attacks via Mixture of Encodings[C]//ACL. The 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics:Human Language Technologies. Stroudsburg: ACL, 2025: 244-252. |
| [50] | HINES K, LOPEZ G, HALL M, et al. Defending against Indirect Prompt Injection Attacks with Spotlighting[C]// CEUR. Conference on Applied Machine Learning in Information Security (CAMLIS 2024). Arlington: CEUR, 2024: 48-62. |
| [51] | CHEN Sizhe, ZHARMAGAMBETOV A, MAHLOUJIFAR S, et al. SecAlign: Defending against Prompt Injection with Preference Optimization[EB/OL]. (2025-07-03)[2025-08-01]. https://arxiv.org/abs/2410.05451. |
| [52] | CHEN Sizhe, PIET J, SITAWARIN C, et al. StruQ: Defending against Prompt Injection with Structured Queries[C]// USENIX. USENIX Security Symposium (USENIX 2025). Berkeley: USENIX, 2025: 2383-2400. |
| [53] | WANG Zhilong, NAGARAJA N, ZHANG Lan, et al. To Protect the LLM Agent against the Prompt Injection Attack with Polymorphic Prompt[C]// IEEE. 2025 55th Annual IEEE/IFIP International Conference on Dependable Systems and Networks-Supplemental Volume (DSN-S). New York: IEEE, 2025: 22-28. |
| [54] | AFAILOVR R, SHARMA A, MITCHELL E, et al. Direct Preference Optimization: Your Language Model Is Secretly a Reward Model[C]// NeurIPS. Annual Conference on Neural Information Processing Systems (NeurIPS 2023). Cambridge: MIT, 2023: 53728-53741. |
| [55] | OSTERMANN S, BAUM K, ENDRES C, et al. Soft Begging: Modular and Efficient Shielding of LLMs against Prompt Injection and Jailbreaking Based on Prompt Tuning[EB/OL]. (2024-07-03)[2025-08-01]. https://arxiv.org/abs/2407.03391. |
| [56] | PIET J, ALRASHED M, SITAWARIN C, et al. Jatmo: Prompt Injection Defense by Task-Specific Finetuning[C]// Springer. European Symposium on Research in Computer Security (ESORICS 2024). Heidelberg: Springer, 2024: 105-124. |
| [57] | PANTERINO S, FELLINGTON M. Dynamic Moving Target Defense for Mitigating Targeted LLM Prompt Injection[EB/OL]. (2024-06-12)[2025-08-01]. https://www.techrxiv.org/doi/full/10.36227/techrxiv.171822345.56781952. |
| [58] | PASQUINI D, KORNAROPOULOS E M, ATENIESE G. Hacking back the AI-Hacker: Prompt Injection as a Defense against LLM-Driven Cyberattacks[EB/OL]. (2024-11-18)[2025-08-01]. https://arxiv.org/abs/2410.20911. |
| [59] | SUO Xuchen. Signed-Prompt: A New Approach to Prevent Prompt Injection Attacks against LLM-Integrated Applications[EB/OL]. (2024-01-15)[2025-08-01]. https://arxiv.org/abs/2401.07612. |
| [60] | JIA Feiran, WU Tong, QIN Xin, et al. The Task Shield: Enforcing Task Alignment to Defend against Indirect Prompt Injection in LLM Agents[C]// ACL. The 63rd Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2025: 29680-29697. |
| [1] | 顾兆军, 李丽, 隋翯. 基于大语言模型的SQL注入漏洞检测载荷生成方法[J]. 信息网络安全, 2026, 26(2): 274-290. |
| [2] | 仝鑫, 焦强, 王靖亚, 袁得嵛, 金波. 公共安全领域大语言模型的可信性研究综述:风险、对策与挑战[J]. 信息网络安全, 2026, 26(1): 24-37. |
| [3] | 胡雨翠, 高浩天, 张杰, 于航, 杨斌, 范雪俭. 车联网安全自动化漏洞利用方法研究[J]. 信息网络安全, 2025, 25(9): 1348-1356. |
| [4] | 刘会, 朱正道, 王淞鹤, 武永成, 黄林荃. 基于深度语义挖掘的大语言模型越狱检测方法研究[J]. 信息网络安全, 2025, 25(9): 1377-1384. |
| [5] | 王磊, 陈炯峄, 王剑, 冯袁. 基于污点分析与文本语义的固件程序交互关系智能逆向分析方法[J]. 信息网络安全, 2025, 25(9): 1385-1396. |
| [6] | 张燕怡, 阮树骅, 郑涛. REST API设计安全性检测研究[J]. 信息网络安全, 2025, 25(8): 1313-1325. |
| [7] | 陈平, 骆明宇. 云边端内核竞态漏洞大模型分析方法研究[J]. 信息网络安全, 2025, 25(7): 1007-1020. |
| [8] | 酆薇, 肖文名, 田征, 梁中军, 姜滨. 基于大语言模型的气象数据语义智能识别算法研究[J]. 信息网络安全, 2025, 25(7): 1163-1171. |
| [9] | 张学旺, 卢荟, 谢昊飞. 基于节点中心性和大模型的漏洞检测数据增强方法[J]. 信息网络安全, 2025, 25(4): 550-563. |
| [10] | 顾欢欢, 李千目, 刘臻, 王方圆, 姜宇. 基于虚假演示的隐藏后门提示攻击方法研究[J]. 信息网络安全, 2025, 25(4): 619-629. |
| [11] | 解梦飞, 傅建明, 姚人懿. 基于LLM的多媒体原生库模糊测试研究[J]. 信息网络安全, 2025, 25(3): 403-414. |
| [12] | 秦中元, 王田田, 刘伟强, 张群芳. 大语言模型水印技术研究进展[J]. 信息网络安全, 2025, 25(2): 177-193. |
| [13] | 杨立群, 李镇, 韦超仁, 闫治敏, 仇勇鑫. 大语言模型引导的协议模糊测试技术研究[J]. 信息网络安全, 2025, 25(12): 1847-1862. |
| [14] | 孟辉, 毛琳琳, 彭聚智. 大语言模型驱动的无害化处理识别方法[J]. 信息网络安全, 2025, 25(12): 1990-1998. |
| [15] | 胡斌, 黑一鸣, 吴铁军, 郑开发, 刘文忠. 大模型安全检测评估技术综述[J]. 信息网络安全, 2025, 25(10): 1477-1492. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||