信息网络安全 ›› 2025, Vol. 25 ›› Issue (12): 1990-1998.doi: 10.3969/j.issn.1671-1122.2025.12.013
大语言模型驱动的无害化处理识别方法
孟辉1( ), 毛琳琳2, 彭聚智2
), 毛琳琳2, 彭聚智2
- 1.中国刑事警察学院,沈阳 110854
2.南航数智科技(广东)有限公司,广州 510080
-
收稿日期:2025-11-20出版日期:2025-12-10发布日期:2026-01-06 -
通讯作者:孟辉 E-mail:1441209123@qq.com -
作者简介:孟辉(1981—),男,山东,讲师,硕士,主要研究方向为视频侦查、网络与系统安全|毛琳琳(1986—),女,山东,高级工程师,硕士,主要研究方向为国资数智监管、安全管理|彭聚智(1982—),男,河南,高级工程师,本科,主要研究方向为信息安全管理、产品运营管理 -
基金资助:辽宁省自然科学基金(2025-MS-101)
Sanitize Processing and Recognition Method Driven by Large Language Model
MENG Hui1(), MAO Linlin2, PENG Juzhi2
- 1. Criminal Investigation Police University of China, Shenyang 110854, China
2. China Southern Airlines Digital Technology (Guangdong) Co., Ltd., Guangzhou 510080, China
-
Received:2025-11-20Online:2025-12-10Published:2026-01-06 -
Contact:MENG Hui E-mail:1441209123@qq.com
摘要:
静态污点分析在自动发现数据流相关安全漏洞中扮演重要角色,但传统基于规则或符号的方法在工程化场景下常因自定义处理函数、上下文相关的验证/转义逻辑以及动态代码特性而产生高误报或漏报。针对这一痛点,文章提出一种大语言模型驱动的无害化处理识别方法,将代码及其调用上下文通过语义化转换算子映射为模型可理解的描述,采用结构化提示引导大语言模型给出判定并输出可证据化的解释,同时结合置信度阈值、缓存策略与选择性符号执行的回退验证,以提升判定的可靠性与工程可用性。在3个公开Java Web基准数据集上的评估结果表明,文章所提方法在无害化处理识别方面显著优于规则匹配法和AST污点分析法,同时针对不同漏洞场景,识别准确率可达89.4%以上。
中图分类号:
引用本文
孟辉, 毛琳琳, 彭聚智. 大语言模型驱动的无害化处理识别方法[J]. 信息网络安全, 2025, 25(12): 1990-1998.
MENG Hui, MAO Linlin, PENG Juzhi. Sanitize Processing and Recognition Method Driven by Large Language Model[J]. Netinfo Security, 2025, 25(12): 1990-1998.
图1
LLM驱动的无害化处理识别方法总体框架
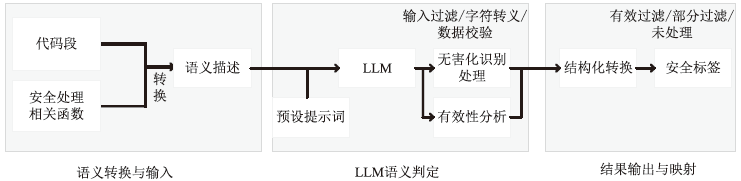
表1
实验用数据集
| 数据集名称 | 来源 | 数据规模 | 涵盖漏洞类型 | 说明 |
|---|---|---|---|---|
| SARD (Software Assurance Reference Dataset) | NIST (National Institute of Standards and Technology) | 约4000个Java Web样本 | XSS、SQL注入、命令注入、路径遍历等 | 包含多语言和多框架样本,适合安全语义验证 |
| OWASP Benchmark Project | OWASP Foundation | 约2500个Java测试用例 | 输入验证、SQL注入、XSS、反序列化漏洞等 | 公开、可复现标准漏洞基准 |
| Juliet Java Test Suite | NIST / DHS | 约10000+代码样本 | 缝隙控制、资源暴露、输入信任等 | 典型静态分析模型对照 数据集 |
表2
无害化处理识别效果对比
| 方法类型 | 准确率 | 召回率 | 误报率 | 平均耗时/ms |
|---|---|---|---|---|
| 规则匹配法 | 78.4% | 70.6% | 14.2% | 420 |
| AST污点分析法 | 84.1% | 77.9% | 11.3% | 680 |
| 本文方法 | 93.8% | 90.5% | 6.1% | 535 |
表3
不同漏洞场景下无害化处理识别效果对比
| 漏洞类型 | 规则匹配法识别率 | AST污点分析法识别率 | 本文方法识别率 |
|---|---|---|---|
| XSS输入过滤 | 80.5% | 87.1% | 95.2% |
| SQL注入校验 | 77.9% | 83.6% | 92.3% |
| 命令注入防护 | 69.8% | 75.4% | 89.4% |
| 路径遍历检测 | 82.1% | 86.8% | 93.1% |
| [1] | WANG Yue, LE H, GOTMARE A D, et al. CodeT5+: Open Code Large Language Models for Code Understanding and Generation[C]// ACL.The 2023 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2023: 1069-1088. |
| [2] | ZENG Shenglai, ZHANG Jiankun, HE Pengfei, et al. The Good and The Bad: Exploring Privacy Issues in Retrieval-Augmented Generation(RAG)[EB/OL]. (2024-02-24)[2025-10-30]. https://aclanthology.org/2024.findings-acl.267.pdf. |
| [3] | ZHAO Shangru, LI Xuejun, FANG Yue, et al. Survey of Automatic Exploitation of Security Vulnerabilities[J]. Journal of Computer Research and Development, 2019, 56(10): 2097-2111. |
| 赵尚儒, 李学俊, 方越, 等. 安全漏洞自动利用综述[J]. 计算机研究与发展, 2019, 56(10):2097-2111. | |
| [4] | ZHANG Jiang, WANG Yingtian, LIU Cong, et al. SANRAZOR: Reducing Redundant Sanitizer Checks in C/C++ Programs[C]// USENIX. The 14th USENIX Symposium on Operating Systems Design and Implementation(OSDI). Berkeley: USENIX, 2021: 685-702. |
| [5] | CHEN Jing. Research on XSS Vulnerability Detection Method Based on Taint Analysis and Fuzz Testing[D]. Nanjing: Nanjing University of Posts and Telecommunications, 2019. |
| 陈晶. 基于污点分析与模糊测试的XSS漏洞检测方法[D]. 南京: 南京邮电大学, 2019. | |
| [6] | YANG Changming. Research on Recurring Vulnerability Detection Guided by Taint Analysis[D]. China Taipei: National Taiwan University, 2023. |
| 杨昌明. 基于污点分析引导的复现漏洞侦测[D]. 中国台北: 国立台湾大学, 2023. | |
| [7] | JING Haotian. Privacy Leakage Detection of Android Applications Based on Taint Analysis[D]. Shanghai: ShanghaiTech University, 2022. |
| 井皓天. 基于污点分析的Android应用隐私泄露检测[D]. 上海: 上海科技大学, 2022. | |
| [8] | DING Yangruibo, FU Yanjun, IBRAHIM O, et al. Vulnerability Detection with Code Language Models: How Far Are We?[EB/OL]. (2024-07-10)[2025-10-30]. https://arxiv.org/abs/2403.18624. |
| [9] | LU Guangzheng, CHEN Hongyu, WANG Jian, et al. GRACE: Empowering LLM-Based Software Vulnerability Detection by Incorporating Graph Structural Information[EB/OL]. (2024-05-04)[2025-10-30]. https://arxiv.org/abs/2405.02534. |
| [10] | ZOU Zhengbin, JIANG Tao, WANG Yizheng, et al. Code Vulnerability Detection Based on Augmented Program Dependency Graph and Optimized CodeBERT[EB/OL]. (2025-11-10)[2025-11-12]. https://www.nature.com/articles/s41598-025-23029-4.pdf. |
| [11] | JIA Wenchao, WANG Yongyi, SHI Fan, et al. DOM XSS Vulnerability Detection Based on Dynamic Taint Propagation Model[J]. Application Research of Computers, 2014, 31(7): 2119-2122. |
| 贾文超, 汪永益, 施凡, 等. 基于动态污点传播模型的DOM XSS漏洞检测[J]. 计算机应用研究, 2014, 31(7):2119-2122. | |
| [12] | WANG Quansheng, WANG Tiantian, MA Rui, et al. Privacy Leakage Detection of Android Applications Based on Dynamic Program Slicing and Taint Analysis[J]. Journal of Chinese Computer Systems, 2025, 46(3): 704-712. |
| 汪全盛, 王田田, 马锐, 等. 基于动态程序切片和污点分析的安卓应用隐私泄露检测[J]. 小型微型计算机系统, 2025, 46(3):704-712. | |
| [13] | ZHANG Jie, TIAN Cong, DUAN Zhenhua. Taint Analysis Tool for Android Applications Based on Contaminated Variable Relationship Graph[J]. Journal of Software, 2021, 32(6): 1701-1716. |
| 张捷, 田聪, 段振华. 基于污染变量关系图的Android应用污点分析工具[J]. 软件学报, 2021, 32(6):1701-1716. | |
| [14] | ZHUGE Jianwei, CHEN Libo, TIAN Fan, et al. Type-Based Dynamic Taint Analysis Technology[J]. Journal of Tsinghua University(Science and Technology), 2012, 52(10): 1320-1328. |
| 诸葛建伟, 陈力波, 田繁, 等. 基于类型的动态污点分析技术[J]. 清华大学学报(自然科学版), 2012, 52(10):1320-1328. | |
| [15] | WU Yanyan. Detection Optimization of Context-Sensitive XSS Vulnerabilities[D]. Chongqing: Southwest University, 2020. |
| 吴延妍. 上下文敏感XSS漏洞的检测优化[D]. 重庆: 西南大学, 2020. |
| [1] | 胡雨翠, 高浩天, 张杰, 于航, 杨斌, 范雪俭. 车联网安全自动化漏洞利用方法研究[J]. 信息网络安全, 2025, 25(9): 1348-1356. |
| [2] | 刘会, 朱正道, 王淞鹤, 武永成, 黄林荃. 基于深度语义挖掘的大语言模型越狱检测方法研究[J]. 信息网络安全, 2025, 25(9): 1377-1384. |
| [3] | 王磊, 陈炯峄, 王剑, 冯袁. 基于污点分析与文本语义的固件程序交互关系智能逆向分析方法[J]. 信息网络安全, 2025, 25(9): 1385-1396. |
| [4] | 张燕怡, 阮树骅, 郑涛. REST API设计安全性检测研究[J]. 信息网络安全, 2025, 25(8): 1313-1325. |
| [5] | 陈平, 骆明宇. 云边端内核竞态漏洞大模型分析方法研究[J]. 信息网络安全, 2025, 25(7): 1007-1020. |
| [6] | 酆薇, 肖文名, 田征, 梁中军, 姜滨. 基于大语言模型的气象数据语义智能识别算法研究[J]. 信息网络安全, 2025, 25(7): 1163-1171. |
| [7] | 张学旺, 卢荟, 谢昊飞. 基于节点中心性和大模型的漏洞检测数据增强方法[J]. 信息网络安全, 2025, 25(4): 550-563. |
| [8] | 顾欢欢, 李千目, 刘臻, 王方圆, 姜宇. 基于虚假演示的隐藏后门提示攻击方法研究[J]. 信息网络安全, 2025, 25(4): 619-629. |
| [9] | 解梦飞, 傅建明, 姚人懿. 基于LLM的多媒体原生库模糊测试研究[J]. 信息网络安全, 2025, 25(3): 403-414. |
| [10] | 秦中元, 王田田, 刘伟强, 张群芳. 大语言模型水印技术研究进展[J]. 信息网络安全, 2025, 25(2): 177-193. |
| [11] | 杨立群, 李镇, 韦超仁, 闫治敏, 仇勇鑫. 大语言模型引导的协议模糊测试技术研究[J]. 信息网络安全, 2025, 25(12): 1847-1862. |
| [12] | 胡斌, 黑一鸣, 吴铁军, 郑开发, 刘文忠. 大模型安全检测评估技术综述[J]. 信息网络安全, 2025, 25(10): 1477-1492. |
| [13] | 胡隆辉, 宋虹, 王伟平, 易佳, 张智雄. 大语言模型在安全托管服务误报处理中的应用研究[J]. 信息网络安全, 2025, 25(10): 1570-1578. |
| [14] | 焦诗琴, 张贵杨, 李国旗. 一种聚焦于提示的大语言模型隐私评估和混淆方法[J]. 信息网络安全, 2024, 24(9): 1396-1408. |
| [15] | 陈昊然, 刘宇, 陈平. 基于大语言模型的内生安全异构体生成方法[J]. 信息网络安全, 2024, 24(8): 1231-1240. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||