信息网络安全 ›› 2026, Vol. 26 ›› Issue (4): 503-520.doi: 10.3969/j.issn.1671-1122.2026.04.001
大语言模型推理隐私保护技术综述
崔津华( ), 董亮, 杨新
), 董亮, 杨新
湖南大学半导体学院(集成电路学院) 长沙 410082
-
收稿日期:2025-09-28出版日期:2026-04-10发布日期:2026-04-29 -
通讯作者:崔津华 E-mail:jhcui@hnu.edu.cn -
作者简介:崔津华(1990—),男,甘肃,副教授,博士,CCF会员,主要研究方向为处理器芯片安全、软硬件协同设计与优化|董亮(2003—),男,安徽,硕士研究生,主要研究方向为人工智能硬件安全、软硬件协同设计|杨新(2002—),男,湖北,博士研究生,主要研究方向为人工智能硬件安全、软硬件协同设计 -
基金资助:国家自然科学基金(62402169);湖南省重点研发计划(2024JK2011);湖南省自然科学基金(2026JJ40056);CCF-华为胡杨林基金(CCF-HuaweiTC202402);湖南省教育厅优秀青年项目(23B0036)
A Survey of Privacy-Preserving Techniques for Large Language Model Inference
CUI Jinhua(), DONG Liang, YANG Xin
College of Semiconductors (College of Integrated Circuits) ,Hunan University Changsha 410082, China
-
Received:2025-09-28Online:2026-04-10Published:2026-04-29
摘要:
大语言模型已在医疗、金融、司法等领域得到广泛应用。然而,在推理阶段,大语言模型的隐私风险问题尤为突出。文章首先从隐私风险角度出发,对推理阶段的潜在威胁展开系统性分析,并根据隐私泄露对象进行分类。然后,对现有隐私保护方法进行概述,并根据技术路径将其划分为基于密码学、基于检测以及基于可信执行环境的方法,重点讨论了各类方法的优势与局限。从安全性、效率、可扩展性和部署复杂度4个维度,对不同方法进行深入比较与分析。最后,结合研究现状与挑战,总结出未来在推理阶段提升大语言模型隐私保护的研究方向与潜在解决思路。
中图分类号:
引用本文
崔津华, 董亮, 杨新. 大语言模型推理隐私保护技术综述[J]. 信息网络安全, 2026, 26(4): 503-520.
CUI Jinhua, DONG Liang, YANG Xin. A Survey of Privacy-Preserving Techniques for Large Language Model Inference[J]. Netinfo Security, 2026, 26(4): 503-520.
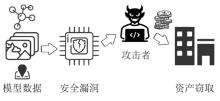
图1
LLM推理阶段的隐私风险成因
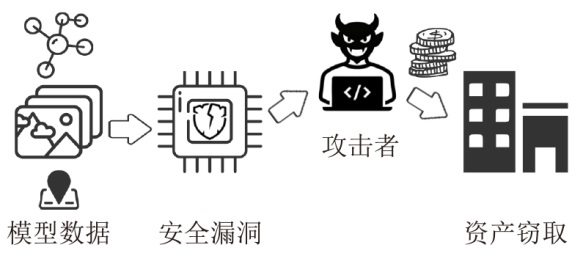
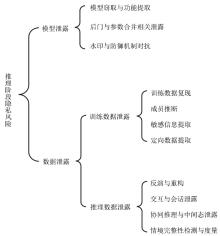
图2
LLM推理阶段的隐私风险分类
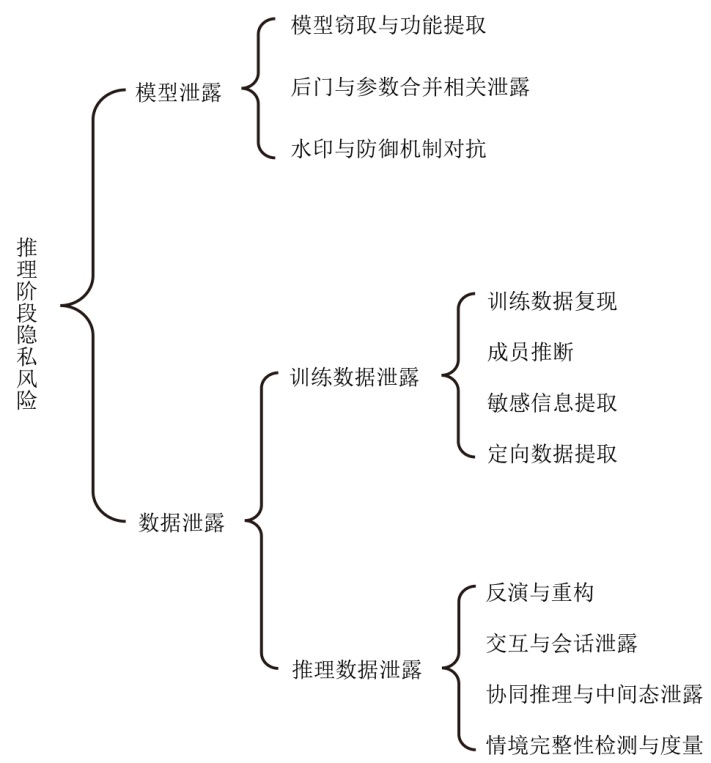
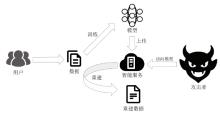
图3
模型反演攻击流程
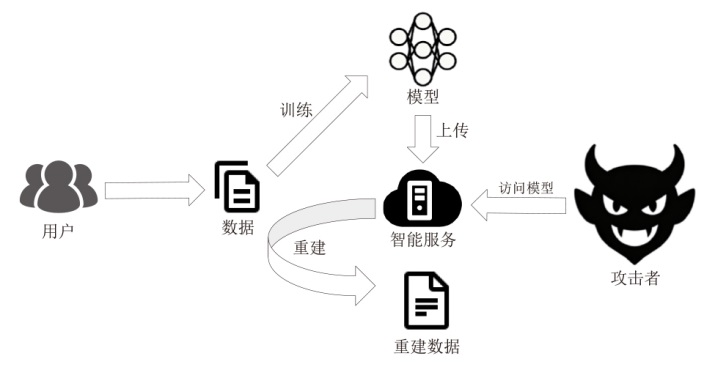
表1
LLM推理阶段的隐私风险分类及攻击技术
| 风险类别 | 攻击方式 | 代表研究 | 说明 | |
|---|---|---|---|---|
| 模型泄露 | 模型窃取与功能提取 | 文献[ | 攻击者复制或推断目标模型的参数,威胁模型机密性与知识产权 | |
| 后门与参数合并相关泄露 | 文献[ 方法 | |||
| 水印与防御机制对抗 | 文献[ | |||
| 数据泄露 | 训练数据泄露 | 训练数据复现 | 文献[ 方法 | 攻击者从模型参数或输出中重建或推断训练样本及敏感信息 |
| 成员推断 | 文献[ | |||
| 敏感信息提取 | 文献[ | |||
| 定向数据提取 | 文献[ | |||
| 推理数据泄露 | 反演与重构 | 文献[ | 攻击者在用户与模型交互中推测或逆推出用户输入与隐私数据 | |
| 交互与会话 泄露 | 文献[ | |||
| 协同推理与 中间态泄露 | 文献[ | |||
| 情境完整性检测与度量 | 文献[ | |||
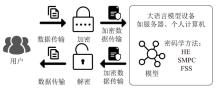
图4
基于密码学的LLM隐私保护推理过程
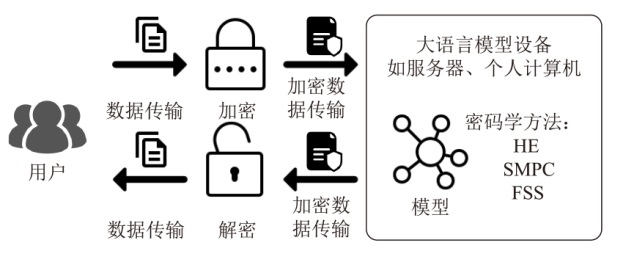
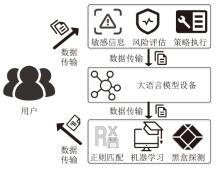
图5
基于检测的LLM隐私保护推理过程
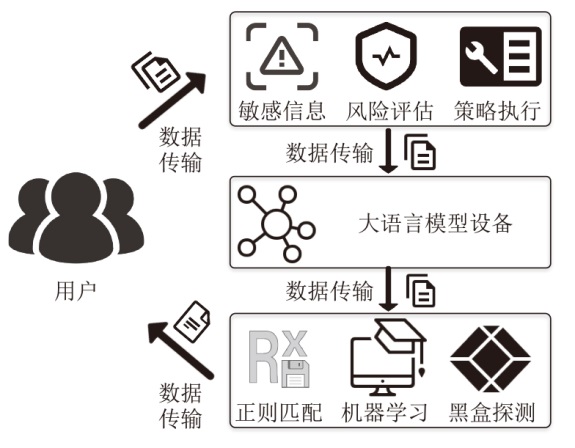
图6
基于TEE的LLM隐私保护推理过程
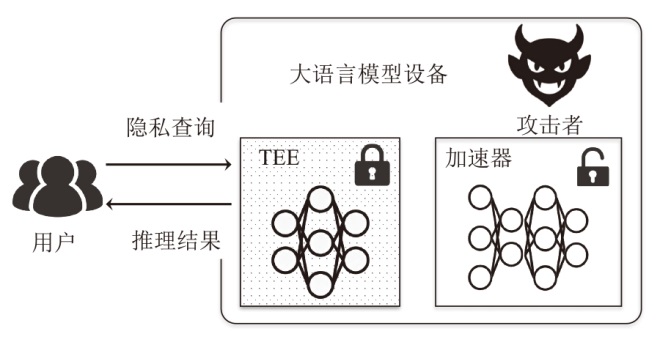
表2
推理阶段常见的隐私保护方法对比
| 方法类别 | 代表研究 | 优点 | 局限性 | 适用场景 |
|---|---|---|---|---|
| 基于密码学的方法 | 文献[ | 理论安全性强,即使通信被窃听,也能保护数据 | 计算和通信开销大,难以扩展至百亿参数模型 | 金融、医疗等对隐私要求较高的领域 |
| 基于检测的方法 | 文献[ | 部署简单,计算开销小,时延低 | 容易被绕过,对抗性提示可规避过滤 | 商业系统中作为补充防护 手段 |
| 基于TEE的方法 | 文献[ | 性能接近明文推理,用户 透明 | 依赖硬件平台,存在侧信道攻击风险 | 云端推理服务、企业内部安全部署 |
表3
各类隐私保护方法的性能与时延对比
| 方法 | 模型 | 环境 | 评估设置 | 性能与 时延 | 主要优化 手段 |
|---|---|---|---|---|---|
| 文献[ 方法 | 端侧模型保护推理 | ARM CCA | 单batch | 端到端时延有显著增加 | 硬件隔离; 可信域划分 |
| 文献[ 方法 | BERT-tiny | CKKS的HE推理 后端 | 单batch | 精度有小幅下降;端到端时延未披露 | 非线性算子近似;蒸馏与两阶段训练 |
| 文献[ 方法 | BERT-base(MNLI) | 多方安全 计算 | 单batch | 在线阶段为小时级时延;离线阶段时延更短;吞吐量随精度配置变化明显 | 比特切片与混合精度;协议流水化 |
| 文献[ 方法 | ChatGLM-6B(逐token生成) | 两方私有推理,广域网条件 | 单batch | 逐token生成的时延为秒级 | 随机置换加速非线性;协议与同态混合 优化 |
| 文献[ 方法 | GPT-2 small | GPU加速全同态推理平台与CPU实现对比,包含自举 | 单batch | 相比CPU基线明显加速;自举代价显著;通过批内并行可进一步降低部分层开销 | GPU并行化;近似与查表;密文槽位 并行 |
| 文献[ 方法 | BERT、RoBERTa、GPT-2 | SMPC | 单batch | BERT任务为秒级;更大模型与生成任务耗时明显更高 | Softmax 优化;协议优化与分段近似 |
| 文献[ 方法 | 语言模型 推理 | 多方安全 计算 | 单batch | 端到端指标未披露 | SMPC推理 协议优化 |
| 文献[ 方法 | 安全推理 框架 | 分布式多方计算 | 多并发 | 端到端指标未披露 | 框架级系统优化与协议整合 |
| 文献[ 方法 | 量化BERT | SMPC | 单batch | Softmax与激活函数的安全计算开销显著降低 | 分层量化;低比特全连接;查表协议 |
| 文献[ 方法 | BERT与GPT系列 | FSS | 单batch | 给出端到端时延与通信量对比表;未摘录具体数值 | 将关键算子用FSS形式实现,以降低耗时与通信开销 |
| 文献[ 方法 | 联邦微调与训练 | 混合秘密 共享,联邦 场景 | 多并发 | 以训练与微调效率为主;不提供推理时延指标 | FFT与混合共享以降低训练开销 |
| 文献[ 方法 | 机器学习即服务推理 | Intel SGX | 多并发 | 相对明文推理存在明显额外开销 | 关键组件进入Enclave; 系统级优化 |
| 文献[ 方法 | 云端多租户推理服务 | TEE与HE协同 | 多并发 | 时延增幅较小 | 加密与系统协同;隔离与调度优化 |
| 文献[ 方法 | 运行时证明的推理服务 | 可信计算与证明机制 | 多并发 | 性能开销随证明频率变化;统一数值未披露 | 轻量化attestation 流程 |
| 文献[ 方法 | LoRa多租户适配与推理 | SGX类TEE | 多并发 | 强调兼顾安全与效率;统一指标未 披露 | 隔离与调度;敏感部分进入Enclave |
| 文献[ 方法 | LLM推理 切片 | TEE | 多并发 | 强调降低服务时延;统一指标未披露 | 分片推理;敏感子图 进入TEE |
| 文献[ 方法 | 边缘分布式LLM推理 | 无线边缘分布式部署 | 多并发 | 强调在提升吞吐量的同时降低时延与带宽开销 | 批处理调度;量化;近似 求解 |
| 文献[ 方法 | 对话生成的键值保护 | GPU与TEE协同 | 单batch | 以防护为主;统一性能指标未披露 | 仅关键置换与保护操作进入TEE |
| 文献[ 方法 | Oblivious ML | SGX安全处理器 | 单batch | 以原型可行性为主;统一端到端指标未披露 | 可信执行隔离;访问模式隐藏 |
| 文献[ 方法 | 通用框架 工作负载 | 库操作系统加SGX | 多并发 | 整体性能接近原生 | 轻量化运行;减轻Enclave负担 |
表4
隐私保护方法的安全性与部署复杂度对比
| 方法类别 | 安全性 | 部署复杂度 |
|---|---|---|
| 基于密码学的方法 | 理论最强 | 需改算子、协议 |
| 基于检测的方法 | 易绕过 | 最简单 |
| 基于TEE的方法 | 依赖TEE安全性 | 需硬件生态 |
表5
未来发展方向与潜在解决路径对比
| 挑战 | 典型方案 | 当前进展 | 未来研究方向 |
|---|---|---|---|
| 性能优化与可扩展性 | HE推理框架(如THE-X)、低时延隐私推理系统(如PermLLM) | 时延较高,HE难以扩展 | 结合TEE、HE与GPU加速,算子与协议协同优化 |
| 黑箱模型可解释性 | 模型探测与信息泄露分析工具 | 缺乏系统化 分析工具 | 引入信息流追踪、参数可视化、可解释性评估框架 |
| 多模态隐私保护 | 跨模态安全推理与差分隐私机制 | 研究不足,缺乏协议支持 | 开发跨模态加密、隐私检测与敏感实体识别机制 |
| 个性化与长期交互 | 差分隐私微调、联邦学习式个性化、知识遗忘机制 | 已有初步探索,但规模受限 | 建立动态隔离、个性化差分隐私、缓存清理等综合策略 |
| 全流程隐私保护 | 统一隐私保护框架(如SecureLLM) | 初步提出端到端思路 | 训练微调推理一体化设计、软硬件 结合 |
| 跨学科与产业融合 | 行业标准、TEE与密码学混合部署 | TEE和HE取舍尚未形成 共识 | 法规驱动的产业标准化、跨厂商可信硬件生态 |
| [1] | PARK K. Samsung Bans Use of Generative AI Tools Like ChatGPT after April Internal Data Leak[EB/OL].(2023-05-02)[2025-08-30]. https://techcrunch.com/2023/05/02/samsung-bans-use-of-generative-ai-tools-like-chatgpt-after-april-internal-data-leak/. |
| [2] | OpenAI. March 20 ChatGPT Outage: Here’s What Happened[EB/OL].(2023-03-24)[2025-08-30]. https://openai.com/index/march-20-chatgpt-outage. |
| [3] | CHEN Kang, ZHOU Xiuze, LIN Yuanguo, et al. A Survey on Privacy Risks and Protection in Large Language Models[J].(2025-05-04)[2025-08-30]. https://arxiv.org/abs/2505.01976. |
| [4] | YAN Biwei, LI Kun, XU Minghui, et al. On Protecting the Data Privacy of Large Language Models (LLMs): A Survey[EB/OL].(2024-03-14)[2025-08-30]. https://arxiv.org/abs/2403.05156. |
| [5] | CHEN Congcong, WEI Lifei, XIE Jintao, et al. Privacy-Preserving Machine Learning Based on Cryptography: A Survey[J]. ACM Transactions on Knowledge Discovery from Data, 2025, 19(4): 1-33. |
| [6] | ZHANG Qiao, XIN Chunsheng, WU Hongyi. Privacy-Preserving Deep Learning Based on Multiparty Secure Computation: A Survey[J]. IEEE Internet of Things Journal, 2021, 8: 10412-10429. |
| [7] | YUAN Jiangjun, LIU Weinan, SHI Jiawen, et al. Approximate Homomorphic Encryption Based Privacy-Preserving Machine Learning: A Survey[J]. Artificial Intelligence Review, 2025, 58(3): 82-130. |
| [8] | BARANSKI S. A Survey on Privacy-Preserving Machine Learning Inference[J]. TASK Quarterly, 2024, 28(2): 1-17. |
| [9] | JIANG Yi, YANG Yong, YIN Jiali, et al. Survey on Security and Privacy Risks in Large Language Models[J]. Journal of Computer Research and Development, 2025, 62(8): 1979-2018. |
| 姜毅, 杨勇, 印佳丽, 等. 大语言模型安全与隐私风险综述[J]. 计算机研究与发展, 2025, 62(8): 1979-2018. | |
| [10] | CARLINI N, TRAMER F, WALLACE E, et al. Extracting Training Data from Large Language Models[C]// USENIX. The 30th USENIX Security Symposium (USENIX Security 21). Berkeley: USENIX, 2021: 2633-2650. |
| [11] | GERASIMENKO D V, NAMIOT D. Extracting Training Data: Risks and Solutions in the Context of LLM Security[J]. International Journal of Open Information Technologies, 2024, 12(11): 9-19. |
| [12] | CARLINI N, PALEKA D, DVIJOTHAM K D, et al. Stealing Part of a Production Language Model[EB/OL].(2024-03-11)[2025-08-30]. https://arxiv.org/abs/2403.06634. |
| [13] | FREDRIKSON M, JHA S, RISTENPART T. Model Inversion Attacks that Exploit Confidence Information and Basic Countermeasures[C]// ACM. The 22nd ACM SIGSAC Conference on Computer and Communications Security. New York: ACM, 2015: 1322-1333. |
| [14] | PAN Xudong, ZHANG Mi, JI Shouling, et al. Privacy Risks of General-Purpose Language Models[C]// IEEE. 2020 IEEE Symposium on Security and Privacy (SP). New York: IEEE, 2020: 1314-1331. |
| [15] | ABDOLLAHI S, MAHERI M, SIBY S, et al. An Early Experience with Confidential Computing Architecture for On-Device Model Protection[EB/OL].(2025-04-11)[2025-08-30]. https://arxiv.org/abs/2504.08508. |
| [16] | CHEN Tianyu, BAO Hangbo, HUANG Shaohan, et al. THE-X: Privacy-Preserving Transformer Inference with Homomorphic Encryption[C]// ACL. Findings of the Association for Computational Linguistics (ACL 2022). Stroudsburg: ACL, 2022: 3510-3520. |
| [17] | TRAMER F, ZHANG Fan, JUELS A, et al. Stealing Machine Learning Models via Prediction APIs[C]// USENIX. The 25th USENIX Security Symposium (USENIX Security 2016). Berkeley: USENIX, 2016: 601-618. |
| [18] | LIANG Zi, YE Qingqing, WANG Yanyun, et al. Alignment-Aware Model Extraction Attacks on Large Language Models[EB/OL].(2024-09-04)[2025-08-30]. https://arxiv.org/abs/2409.02718v1. |
| [19] | HE Jiaming, HOU Guanyu, JIA Xinyue, et al. Data Stealing Attacks against Large Language Models via Backdooring[J]. Electronics, 2024, 13(14): 2858-2869. |
| [20] | WANG Liaoyaqi, CHENG Minhao. GuardEmb: Dynamic Watermark for Safeguarding Large Language Model Embedding Service against Model Stealing Attack[C]// ACL. Findings of the Association for Computational Linguistics (EMNLP 2024). Stroudsburg: ACL, 2024: 7518-7534. |
| [21] | PANG Kaiyi, QI Tao, WU Chuhan, et al. ModelShield: Adaptive and Robust Watermark against Model Extraction Attack[J]. IEEE Transactions on Information Forensics and Security, 2025, 20: 1767-1782. |
| [22] | GUAN Faqian, ZHU Tianqing, CHANG Wenhan, et al. Large Language Models Merging for Enhancing the Link Stealing Attack on Graph Neural Networks[J]. IEEE Transactions on Dependable and Secure Computing, 2025, 22(6): 6809-6825. |
| [23] | GHARAMI K. In the Shadow of Prompts: Adversarial Attacks and Model Cloning in Large Language Models[EB/OL].(2025-07-10)[2025-08-30]. https://commons.erau.edu/edt/909/. |
| [24] | SHEN Yaling, ZHUANG Zhixiong, YUAN Kun, et al. Medical Multimodal Model Stealing Attacks via Adversarial Domain Alignment[J]. The Thirty-Ninth AAAI Conference on Artificial Intelligence, 2025, 39(7): 6842-6850. |
| [25] | SONG Congzheng, RISTENPART T, SHMATIKOV V. Machine Learning Models That Remember Too Much[C]// ACM. The 2017 ACM SIGSAC Conference on Computer and Communications Security. New York: ACM, 2017: 587-601. |
| [26] | SHOKRI R, STRONATI M, SONG Congzheng, et al. Membership Inference Attacks against Machine Learning Models[C]// IEEE. 2017 IEEE Symposium on Security and Privacy (SP). New York: IEEE, 2017: 3-18. |
| [27] | LUKAS N, SALEM A, SIM R, et al. Analyzing Leakage of Personally Identifiable Information in Language Models[C]// IEEE. 2023 IEEE Symposium on Security and Privacy (SP). New York: IEEE, 2023: 346-363. |
| [28] | XU Huan, ZHANG Zhanhao, YU Xiaodong, et al. Targeted Training Data Extraction-Neighborhood Comparison-Based Membership Inference Attacks in Large Language Models[J]. Applied Sciences, 2024, 14(16): 7118-7136. |
| [29] | XIN Yuan, LI Zheng, YU Ning, et al. Inside the Black Box: Detecting Data Leakage in Pre-Trained Language Encoders[EB/OL].(2024-08-20)[2025-08-30]. https://doi.org/10.48550/arXiv.2408.11046. |
| [30] | XU Ruijie, WANG Zengzhi, FAN Runze, et al. Benchmarking Benchmark Leakage in Large Language Models[EB/OL].(2024-05-20)[2025-08-30]. https://github.com/GAIR-NLP/benbench. |
| [31] | LI Qinbin, HONG Junyuan, XIE Chulin, et al. LLM-PBE: Assessing Data Privacy in Large Language Models[EB/OL].(2024-08-23)[2025-08-30]. https://arxiv.org/abs/2408.12787. |
| [32] | DU Yuntao, LI Zitao, LI Ninghui, et al. Beyond Data Privacy: New Privacy Risks for Large Language Models[EB/OL].(2025-08-16)[2025-08-30]. https://arxiv.org/abs/2509.14278. |
| [33] | GALLI F, MELIS L, CUCINOTTA T. Noisy Neighbors: Efficient Membership Inference Attacks against LLMs[EB/OL].(2024-06-24)[2025-08-30]. https://doi.org/10.48550/arXiv.2406.16565. |
| [34] | HE Jiajie, CHEN Minchun, CHEN Xintong, et al. Membership Inference Attacks on LLM-Based Recommender Systems[EB/OL].(2025-08-26)[2025-08-30]. https://arxiv.org/abs/2508.18665. |
| [35] | LI Haoran, GUO Dadi, LI Donghao, et al. Privlm-Bench: A Multi-Level Privacy Evaluation Benchmark for Language Models[EB/OL].(2023-11-07)[2025-08-30]. https://aclanthology.org/2024.acl-long.4/. |
| [36] | DUAN Lin, SUN Jingwei, JIA Jinyuan, et al. Reimagining Mutual Information for Enhanced Defense against Data Leakage in Collaborative Inference[EB/OL].(2024-12-10)[2025-08-30]. https://papers.nips.cc/paper_files/paper/2024/hash/4eb32e1569085c8f8883163665bf3c0a-Abstract-Conference.html. |
| [37] | LI Haoran, FAN Wei, CHEN Yulin, et al. Privacy Checklist: Privacy Violation Detection Grounding on Contextual Integrity Theory[EB/OL].(2024-08-19)[2025-08-30]. https://arxiv.org/abs/2408.10053. |
| [38] | RAEINI M. Privacy-Preserving Large Language Models (PPLLMs)[EB/OL].(2023-08-10)[2025-08-30]. https://www.researchgate.net/publication/372950300_Privacy-Preserving_Large_Language_Models_PPLLMs. |
| [39] | ZHENG Mengxin, LOU Qian, JIANG Lei. Primer: Fast Private Transformer Inference on Encrypted Data[C]// IEEE. 2023 60th ACM/IEEE Design Automation Conference (DAC). New York: IEEE, 2023: 1-6. |
| [40] | ZHENG Fei, CHEN Chaochao, HAN Zhongxuan, et al. PermLLM: Private Inference of Large Language Models within 3 Seconds under WAN[C]// IEEE. IEEE Symposium on Security and Privacy (SP). New York: IEEE, 2024: 1-12. |
| [41] | ROVIDA L, LEPORATI A. Transformer-Based Language Models and Homomorphic Encryption: An Intersection with BERT-Tiny[C]// ACM. The 10th ACM International Workshop on Security and Privacy Analytics. New York: ACM, 2024: 3-13. |
| [42] | CASTRO M, ESCUDERO D, AGRAWAL A, et al. EncryptedLLM: Privacy-Preserving Large Language Model Inference via GPU-Accelerated Fully Homomorphic Encryption[EB/OL].(2025-05-01)[2025-08-30]. https://openreview.net/forum?id=PGNff6H1TV. |
| [43] | ZIMERMAN I, BARUCH M, DRUCKER N, et al. Converting Transformers to Polynomial Form for Secure Inference over Homomorphic Encryption[EB/OL].(2023-11-15)[2025-08-30]. https://arxiv.org/abs/2311.08610. |
| [44] | LUO Jinglong, ZHANG Yehong, ZHANG Zhuo, et al. SecFormer: Fast and Accurate Privacy-Preserving Inference for Transformer Models via SMPC[C]// ACL. Findings of the Association for Computational Linguistics ACL 2024. Stroudsburg:ACL, 2024: 13333-13348. |
| [45] | SONG Chen, HUANG Ruwei, HU Sai. Private-Preserving Language Model Inference Based on Secure Multi-Party Computation[EB/OL].(2024-08-01)[2025-08-30]. https://www.sciencedirect.com/science/article/pii/S0925231224005654. |
| [46] | REDDY B, CHETHAN M, KOLEKAR V K, et al. Tackling Big Data Challenges in Large Language Models with an Emphasis on Sharing, Security, and Scalability[C]// IEEE. 2024 IEEE 4th International Conference on ICT in Business Industry & Government (ICTBIG). New York: IEEE, 2024: 1-6. |
| [47] | ZENG Chenkai, HE Debiao, FENG Qi, et al. SecureGPT: A Framework for Multi-Party Privacy-Preserving Transformer Inference in GPT[J]. IEEE Transactions on Information Forensics and Security, 2024, 19: 9480-9493. |
| [48] | LU Tianpei, ZHANG Bingsheng, PENG Lekun, et al. Privacy-Preserving Inference for Quantized BERT Models[EB/OL].(2025-08-03)[2025-08-30]. https://arxiv.org/abs/2508.01636. |
| [49] | GUPTA K, JAWALKAR N, MUKHERJEE A, et al. SIGMA: Secure GPT Inference with Function Secret Sharing[J]. Proceedings on Privacy Enhancing Technologies, 2024(4): 61-79. |
| [50] | YOU Zhichao, DONG Xuewen, CHENG Ke, et al. PriFFT: Privacy-Preserving Federated Fine-Tuning of Large Language Models via Hybrid Secret Sharing[EB/OL].(2025-03-05)[2025-08-30]. https://arxiv.org/abs/2503.03146. |
| [51] | SU Tan, ZHANG Bingbing, ZHANG Chi, et al. Privacy Leak Detection in LLM Interactions with a User-Centric Approach[C]// IEEE. 2024 IEEE 23rd International Conference on Trust, Security and Privacy in Computing and Communications (TrustCom). New York: IEEE, 2024: 1647-1652. |
| [52] | KIM S, YUN S, LEE H, et al. ProPILE: Probing Privacy Leakage in Large Language Models[J]. Neural Information Processing Systems, 2023, 36: 20750-20762. |
| [53] | STAAB R, VERO M, BALUNOVIC M, et al. Beyond Memorization: Violating Privacy via Inference with Large Language Models[EB/OL].(2023-10-11)[2025-08-30]. https://arxiv.org/abs/2310.07298. |
| [54] | LI Haoran, FAN Wei, CHEN Yulin, et al. Privacy Checklist: Privacy Violation Detection Grounding on Contextual Integrity Theory[C]// ACL. The 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics:Human Language Technologies. Stroudsburg: ACL, 2025: 1748-1766. |
| [55] | HE Jinwen, LU Yiyang, LIN Zijin, et al. PrivacyXray: Detecting Privacy Breaches in LLMs through Semantic Consistency and Probability Certainty[EB/OL].(2025-06-24)[2025-08-30]. https://arxiv.org/abs/2506.19563. |
| [56] | ZENG Hang, LIU Xiangyu, HU Yong, et al. Automated Privacy Information Annotation in Large Language Model Interactions[EB/OL].(2025-08-08)[2025-08-30]. https://doi.org/10.48550/arXiv.2505.20910. |
| [57] | BONFANTI S. LeakSealer: A Unified Framework for Detecting Toxic Content and Privacy Leakage in LLM[EB/OL].(2024-12-11)[2025-08-30]. https://www.politesi.polimi.it/handle/10589/231164. |
| [58] | MIRESHGHALLAH N, KIM H, ZHOU Xuhui, et al. Can LLMs Keep a Secret? Testing Privacy Implications of Language Models via Contextual Integrity Theory[EB/OL].(2023-10-27)[2025-08-30]. https://arxiv.org/abs/2310.17884. |
| [59] | SHEN Xinyue, CHEN Zeyuan, BACKES M, et al. “Do Anything Now”: Characterizing and Evaluating in-the-Wild Jailbreak Prompts on Large Language Models[C]// ACM. The 2024 on ACM SIGSAC Conference on Computer and Communications Security. New York: ACM, 2024: 1671-1685. |
| [60] | YU Jiahao, LIN Xingwei, YU Zheng, et al. LLM-Fuzzer: Scaling Assessment of Large Language Model Jailbreaks[C]// USENIX. The 33rd USENIX Security Symposium (USENIX Security 24). Berkeley: USENIX, 2024: 4657-4674. |
| [61] | ELESEDY H, ESPERANCA P M, OPREA S V, et al. LoRA-Guard: Parameter-Efficient Guardrail Adaptation for Content Moderation of Large Language Models[EB/OL].(2024-07-03)[2025-08-30]. https://arxiv.org/abs/2407.02987. |
| [62] | ZHENG Lianmin, CHIANG W L, SHENG Ying, et al. Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena[J]. Neural Information Processing Systems, 2023, 36: 46595-46623. |
| [63] | CHEN Hongyu, GOLDFARB-TARRANT S. Safer or Luckier LLMs as Safety Evaluators are Not Robust to Artifacts[EB/OL].(2025-05-12)[2025-08-30]. https://doi.org/10.48550/arXiv.2503.09347. |
| [64] | WU Hengyu, CAO Yang. Membership Inference Attacks on Large-Scale Models: A Survey[EB/OL].(2025-03-25)[2025-08-30]. https://arxiv.org/abs/2503.19338. |
| [65] | POPA R A. Confidential Computing or Cryptographic Computing[J]. ACM Queue, 2025, 23(1): 45-57. |
| [66] | QU Guanqiao, CHEN Qiyuan, WEI Wei, et al. Mobile Edge Intelligence for Large Language Models: A Contemporary Survey[J]. IEEE Communications Surveys & Tutorials, 2025, 27(6): 3820-3860. |
| [67] | MA N U B, KOMPALLY V S. A Review of Large Language Models in Edge Computing: Applications, Challenges, Benefits, and Deployment Strategies[J]. International Journal of Data Science and Machine Learning, 2025, 5(1): 300-322. |
| [68] | ZHOU Zhanke, ZHU Jianing, YU Fengfei, et al. Model Inversion Attacks: A Survey of Approaches and Countermeasures[EB/OL].(2024-11-15)[2025-08-30]. https://arxiv.org/abs/2411.10023. |
| [69] | HUNT T, SONG Congzheng, SHOKRI R, et al. Chiron: Privacy-Preserving Machine Learning as a Service via Secure Enclaves[C]// USENIX. 2018 USENIX Symposium on Networked Systems Design and Implementation (NSDI 18). Berkeley: USENIX, 2018: 283-298. |
| [70] | HOU Jiahui, LIU Huiqi, LIU Yunxin, et al. Model Protection: Real-Time Privacy-Preserving Inference Service for Model Privacy at the Edge[J]. IEEE Transactions on Dependable and Secure Computing, 2022, 19(6): 4270-4284. |
| [71] | ADEPU P K. Confidential AI-as-a-Service with Homomorphic Encryption for LLM Inference in Multi-Tenant Clouds[EB/OL].(2025-03-10)[2025-08-30]. https://www.researchgate.net/publication/399104668. |
| [72] | SU Jianchang, ZHANG Wei. Runtime Attestation for Secure LLM Serving in Cloud-Native Trusted Execution Environments[EB/OL].(2025-06-07)[2025-08-30]. https://www.researchgate.net/publication/395337639_Runtime_Attestation_for_Secure_LLM_Serving_in_Cloud-Native_Trusted_Execution_Environments. |
| [73] | LIN Zechao, ZHANG Sisi, WANG Xingbin, et al. LoRATEE: A Secure and Efficient Inference Framework for Multi-Tenant LoRA LLMS Based on TEE[C]// IEEE. ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). New York: IEEE, 2025: 1-5. |
| [74] | LI Ding, ZHANG Ziqi, YAO Mengyu, et al. TEESlice: Protecting Sensitive Neural Network Models in Trusted Execution Environments When Attackers Have Pre-Trained Models[J]. ACM Transactions on Software Engineering and Methodology, 2025, 34(6): 1-49. |
| [75] | ZHANG Xinyuan, NIE Jiangtian, HUANG Yudong, et al. Beyond the Cloud: Edge Inference for Generative Large Language Models in Wireless Networks[J]. IEEE Transactions on Wireless Communications, 2025, 24(1): 643-658. |
| [76] | YANG Huan, ZHANG Deyu, ZHAO Yudong, et al. A First Look at Efficient and Secure on-Device LLM Inference against KV Leakage[C]// ACM. The Workshop on Mobility in the Evolving Internet Architecture. New York: ACM, 2024: 13-18. |
| [77] | OHRIMENKO O, SCHUSTER F, FOURNET C, et al. Oblivious Multi-Party Machine Learning on Trusted Processors[C]// USENIX. The 25th USENIX Security Symposium (USENIX Security 16). Berkeley: USENIX, 2016: 619-636. |
| [78] | VOLOS H, PORTOKALIDIS G, BOS H. Gramine/Graphene-SGX: A Library OS for Unmodified Applications on SGX[C]// USENIX. The 2018 USENIX Annual Technical Conference (ATC 18). Berkeley: USENIX, 2018: 461-473. |
| [79] | KALODANIS K, PAPADOPOULOS S, FERETZAKIS G, et al. SecureLLM: A Unified Framework for Privacy-Focused Large Language Models[J]. Applied Sciences, 2025, 15(8): 4180-4207. |
| [80] | SIVASHANMUGAM S P. Model Inversion Attacks on Llama 3:Extracting PII from Large Language Models[EB/OL].(2025-07-06)[2025-08-30]. https://arxiv.org/abs/2507.04478. |
| [81] | MIRIYALA N S, MACHA K B, METHA S, et al. Comparative Review of AWS and Azure Confidential Computing Systems[J]. Journal of Information Systems Engineering and Management, 2025, 10(12s): 257-268. |
| [82] | ZHANG Rongting, BERTRAN M, ROTH A. Order of Magnitude Speedups for LLM Membership Inference[EB/OL].(2024-09-22)[2025-08-30]. https://arxiv.org/abs/2409.14513. |
| [83] | LI Yang, ZHOU Xinyu, WANG Yitong, et al. Private Transformer Inference in MLaaS: A Survey[EB/OL].(2025-05-15)[2025-08-30]. https://arxiv.org/abs/2505.10315. |
| [1] | 易文哲, 徐枭洋, 石磊, 庄泳, 王鹃. 基于知识迁移和冻结的模型反演防御方法[J]. 信息网络安全, 2026, 26(4): 566-578. |
| [2] | 李岩, 杨文章, 薛吟兴. 基于LLM翻译与差分测试的跨语言编译器模糊测试[J]. 信息网络安全, 2026, 26(4): 591-604. |
| [3] | 胡勉宁, 李欣, 李明锋, 袁得嵛. 基于大语言模型的多策略增强中文网络威胁情报实体抽取研究[J]. 信息网络安全, 2026, 26(4): 615-625. |
| [4] | 袁明, 邹其霖, 袁文骐, 王群. 大语言模型提示词注入攻击与防御综述[J]. 信息网络安全, 2026, 26(3): 341-354. |
| [5] | 林甜甜, 王奕天, 王小航, 竺婷, 任奎. CCASim:Arm机密计算架构性能仿真器研究[J]. 信息网络安全, 2026, 26(2): 189-210. |
| [6] | 顾兆军, 李丽, 隋翯. 基于大语言模型的SQL注入漏洞检测载荷生成方法[J]. 信息网络安全, 2026, 26(2): 274-290. |
| [7] | 赵佳, 王妍淳, 马洪亮, 李琪. 基于可信执行环境的层次角色基分级加密方案[J]. 信息网络安全, 2026, 26(2): 315-324. |
| [8] | 郭毅, 李旭青, 张子蛟, 张宏涛, 张连成, 张香丽. 基于区块链的数据安全共享研究[J]. 信息网络安全, 2026, 26(1): 1-23. |
| [9] | 仝鑫, 焦强, 王靖亚, 袁得嵛, 金波. 公共安全领域大语言模型的可信性研究综述:风险、对策与挑战[J]. 信息网络安全, 2026, 26(1): 24-37. |
| [10] | 胡雨翠, 高浩天, 张杰, 于航, 杨斌, 范雪俭. 车联网安全自动化漏洞利用方法研究[J]. 信息网络安全, 2025, 25(9): 1348-1356. |
| [11] | 刘会, 朱正道, 王淞鹤, 武永成, 黄林荃. 基于深度语义挖掘的大语言模型越狱检测方法研究[J]. 信息网络安全, 2025, 25(9): 1377-1384. |
| [12] | 王磊, 陈炯峄, 王剑, 冯袁. 基于污点分析与文本语义的固件程序交互关系智能逆向分析方法[J]. 信息网络安全, 2025, 25(9): 1385-1396. |
| [13] | 拾以娟, 周丹平, 范磊, 刘茵. 基于可信执行环境的安全多方计算协议[J]. 信息网络安全, 2025, 25(9): 1439-1446. |
| [14] | 张燕怡, 阮树骅, 郑涛. REST API设计安全性检测研究[J]. 信息网络安全, 2025, 25(8): 1313-1325. |
| [15] | 陈平, 骆明宇. 云边端内核竞态漏洞大模型分析方法研究[J]. 信息网络安全, 2025, 25(7): 1007-1020. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||