Netinfo Security ›› 2015, Vol. 15 ›› Issue (3): 19-22.doi: 10.3969/j.issn.1671-1122.2015.03.004
Previous Articles Next Articles
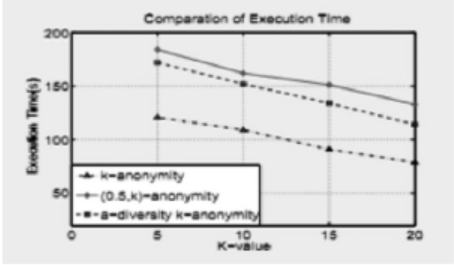
a-diversity and k-anonymity Big Data Privacy Preservation Based On Micro-aggregation
CHENG Liang( ), JIANG Fan
), JIANG Fan
- School of Computer Science and Technology, University of Science and Technology of China, Hefei Anhui 230027, China
-
Received:2015-01-21Online:2015-03-10Published:2015-05-08
CLC Number:
Cite this article
CHENG Liang, JIANG Fan. a-diversity and k-anonymity Big Data Privacy Preservation Based On Micro-aggregation[J]. Netinfo Security, 2015, 15(3): 19-22.
share this article
Add to citation manager EndNote|Ris|BibTeX
URL: http://netinfo-security.org/EN/10.3969/j.issn.1671-1122.2015.03.004

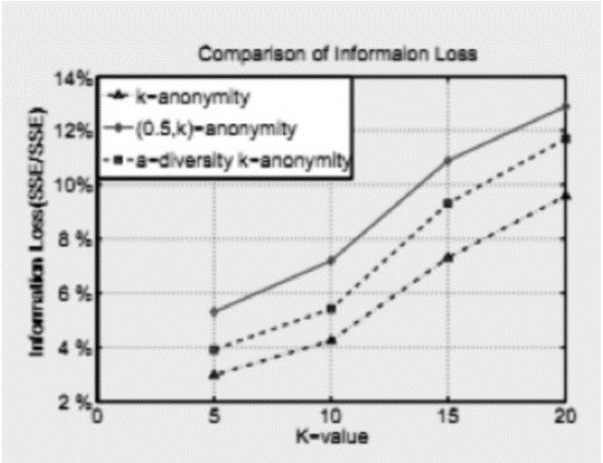
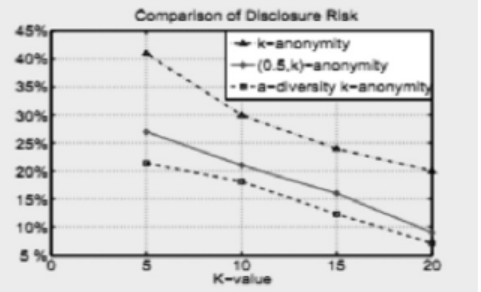
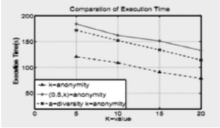
| [1] | Josep Domingo-Ferrer, Antoni Mart´nez-Ballest é,Josep Maria Mateo-Sanz, et al. Efficient multivariate data-oriented microaggregation. The VLDB Journal, 15(4):355-369, 2006. |
| [2] | Josep Domingo-Ferrer and Josep Maria Mateo-Sanz.Practicaldata-oriented microaggrega-tion for statistical disclosure control. Knowledge and Data Engineering, IEEE Transactionson, 14(1):189-201, 2002. |
| [3] | Josep Domingo-Ferrer, Agusti Solanas,Antoni Martinez-Balleste.Privacy in statisticaldatabases: k-anonymity through microaggregation. In GrC, pages 774-777, 2006. |
| [4] | Raymond Chi-Wing Wong, Jiuyong Li, Ada Wai-Chee Fu,Ke Wang.(a,k)-anonymity:an enhanced k-anonymity model for privacy preserving data publishing. In Proceedings of the 12th ACM SIGKDD international conference on Knowledge discovery and data mining,pages 754-759. ACM, 2006. |
| [5] | Bugra Gedik and Ling Liu. Protecting location privacy with personalized k-anonymity:Architecture and algorithms. Mobile Computing, IEEE Transactions on, 7(1):1-18, 2008 . |
| [6] | Yabo Xu, Ke Wang, Benyu Zhang,Zheng Chen.Privacy-enhancing personalized websearch. In Proceedings of the 16th international conference on World Wide Web, pages 591-600. ACM, 2007. |
| [7] | Mingxuan Yuan, Lei Chen,Philip S Yu.Personalized privacy protection in social networks. Proceedings of the VLDB Endowment, 4(2):141-150, 2010. |
| [8] | Ashwin Machanavajjhala, Daniel Kifer, Johannes Gehrke,Muthuramakrishnan Venkita-subramaniam. l-diversity: Privacy beyond k-anonymity. ACM Transactions on KnowledgeDiscovery from Data (TKDD), 1(1):3, 2007. |
| [9] | Jordi Soria-Comas, Josep Domingo-Ferrer, David Sánchez,Sergio Mart´ınez.Enhancing data utility in differential privacy via microaggregation-based k-anonymity. The VLDBJournal, pages 1-24, 2014. |
| [10] | Latanya Sweeney. k-anonymity: A model for protecting privacy.International Journal ofUncertainty, Fuzziness and Knowledge-Based Systems, 10(05):557-570, 2002. |
| [11] | Ninghui Li, Tiancheng Li,Suresh Venkatasubramanian. t-closeness: Privacy beyondk-anonymity and l-diversity. In ICDE, volume 7, pages 106-115, 2007. |
| [1] | HUANG Wangwang, ZHOU Hua, WANG Daiqiang, ZHAO Qi. Design of Reconfigurable Key Security Authentication Protocol for IoT Based on National Cryptography SM9 [J]. Netinfo Security, 2024, 24(7): 1006-1014. |
| [2] | ZHANG Xiaojun, ZHANG Nan, HAO Yunpu, WANG Zhouyang, XUE Jingting. Three-Factor Authentication and Key Agreement Protocol Based on Chaotic Map for Industrial Internet of Things Systems [J]. Netinfo Security, 2024, 24(7): 1015-1026. |
| [3] | ZHANG Jiwei, WANG Wenjun, NIU Shaozhang, GUO Xiangkuo. Blockchain Scaling Solutions: ZK-Rollup Review [J]. Netinfo Security, 2024, 24(7): 1027-1037. |
| [4] | ZHANG Liqiang, LU Mengjun, YAN Fei. A Cross-Contract Fuzzing Scheme Based on Function Dependencies [J]. Netinfo Security, 2024, 24(7): 1038-1049. |
| [5] | DONG Yunyun, ZHU Yuling, YAO Shaowen. High-Quality Full-Size Image Steganography Method Based on Improved U-Net and Hybrid Attention Mechanism [J]. Netinfo Security, 2024, 24(7): 1050-1061. |
| [6] | ZHOU Shucheng, LI Yang, LI Chuanrong, GUO Lulu, JIA Xinhong, YANG Xinghua. Context-Based Abnormal Root Cause Algorithm [J]. Netinfo Security, 2024, 24(7): 1062-1075. |
| [7] | REN Changyu, ZHANG Ling, JI Hangyuan, YANG Liqun. Research on TTP Extraction Method Based on Pre-Trained Language Model and Chinese-English Threat Intelligence [J]. Netinfo Security, 2024, 24(7): 1076-1087. |
| [8] | CAI Manchun, XI Rongkang, ZHU Yi, ZHAO Zhongbin. A Fingerprint Identification Method of Multi-Page and Multi-Tag Targeting Tor Website [J]. Netinfo Security, 2024, 24(7): 1088-1097. |
| [9] | XIANG Hui, XUE Yunhao, HAO Lingxin. Large Language Model-Generated Text Detection Based on Linguistic Feature Ensemble Learning [J]. Netinfo Security, 2024, 24(7): 1098-1109. |
| [10] | SHEN Xiuyu, JI Weifeng. Optimization of Cost of Edge-Cloud Collaborative Computing Offloading Considering Security [J]. Netinfo Security, 2024, 24(7): 1110-1121. |
| [11] | ZHAO Xinqiang, FAN Bo, ZHANG Dongju. Research on APT Attack Defense System Based on Threat Discovery [J]. Netinfo Security, 2024, 24(7): 1122-1128. |
| [12] | WEN Wen, LIU Qinju, KUANG Lin, REN Xuejing. Research and Scheme Design of Cyber Threat Intelligence Sharing under Privacy Protection System [J]. Netinfo Security, 2024, 24(7): 1129-1137. |
| [13] | LIU Yidan, MA Yongliu, DU Yibin, CHENG Qingfeng. A Certificateless Anonymous Authentication Key Agreement Protocol for VANET [J]. Netinfo Security, 2024, 24(7): 983-992. |
| [14] | LUO Ming, ZHAN Qibang, QIU Minrong. A Heterogeneous Cross-Domain Conditional Privacy Protection Ring Signcryption Scheme for V2I Communication [J]. Netinfo Security, 2024, 24(7): 993-1005. |
| [15] | LI Zengpeng, WANG Siyang, WANG Mei. Research of Privacy-Preserving Proximity Test [J]. Netinfo Security, 2024, 24(6): 817-830. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||