信息网络安全 ›› 2026, Vol. 26 ›› Issue (4): 591-604.doi: 10.3969/j.issn.1671-1122.2026.04.007
基于LLM翻译与差分测试的跨语言编译器模糊测试
李岩1, 杨文章2, 薛吟兴2( )
)
- 1
中国科学技术大学软件学院 合肥 230026
2中国科学院工业人工智能研究所 南京 211135
-
收稿日期:2025-12-16出版日期:2026-04-10发布日期:2026-04-29 -
通讯作者:薛吟兴 E-mail:yxxue@iaii.ac.cn -
作者简介:李岩(2000—),男,山东,硕士研究生,CCF会员,主要研究方向为模糊测试|杨文章(1994—),男,浙江,助理研究员,博士,CCF会员,主要研究方向为软件工程、程序设计语言|薛吟兴(1982—),男,江苏,研究员,博士,CCF会员,主要研究方向为软件安全、人工智能安全、网络空间安全 -
基金资助:国家自然科学基金(61972373)
Cross-Language Compiler Fuzzing Based on LLM Translation and Differential Testing
LI Yan1, YANG Wenzhang2, XUE Yinxing2()
- 1
School of Software Engineering ,University of Science and Technology of China Hefei 230026, China
2Institute of AI for Industries ,Chinese Academy of Sciences Nanjing 211135, China
-
Received:2025-12-16Online:2026-04-10Published:2026-04-29
摘要:
随着现代软件系统日益复杂,编译器的正确性与可靠性至关重要。传统编译器模糊测试方法在多语言场景下存在规则维护复杂以及跨语言一致性验证困难等局限。大语言模型在代码翻译与语义推理方面的能力,为解决该问题提供了新思路。文章提出一种基于大语言模型翻译与语义推理的跨语言编译器模糊测试框架Fuzpiler,以挖掘编译器潜在漏洞。Fuzpiler首先利用现有模糊测试工具异步生成测试种子,并通过多目标优化筛选测试样例。随后,借助大语言模型将种子翻译为多种语言的等价程序,构建跨语言“同源”测试种子集。在语义验证方面,该框架利用大语言模型的推理能力对多语言程序进行语义对齐,并通过差分测试检测编译器在不同语言前端或优化阶段的行为不一致性。文章在3种编译器(Clang、Clang++和Rustc)上对Fuzpiler进行实验评估。实验结果表明,与基线工具相比,Fuzpiler在3种编译器上的分支覆盖率分别提升了 5.19%、36.57%和23.91%,验证了大语言模型在跨语言测试生成、语义对齐与一致性验证中的有效性。
中图分类号:
引用本文
李岩, 杨文章, 薛吟兴. 基于LLM翻译与差分测试的跨语言编译器模糊测试[J]. 信息网络安全, 2026, 26(4): 591-604.
LI Yan, YANG Wenzhang, XUE Yinxing. Cross-Language Compiler Fuzzing Based on LLM Translation and Differential Testing[J]. Netinfo Security, 2026, 26(4): 591-604.
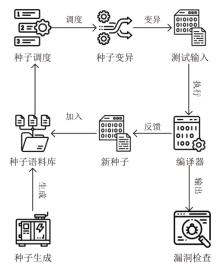
图1
编译器模糊测试基本流程
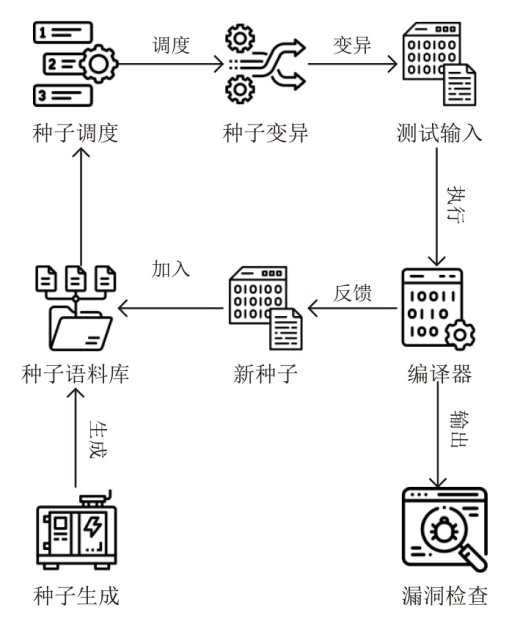
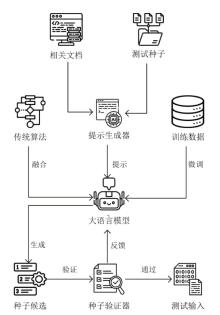
图2
基于LLM的模糊测试输入生成基本流程
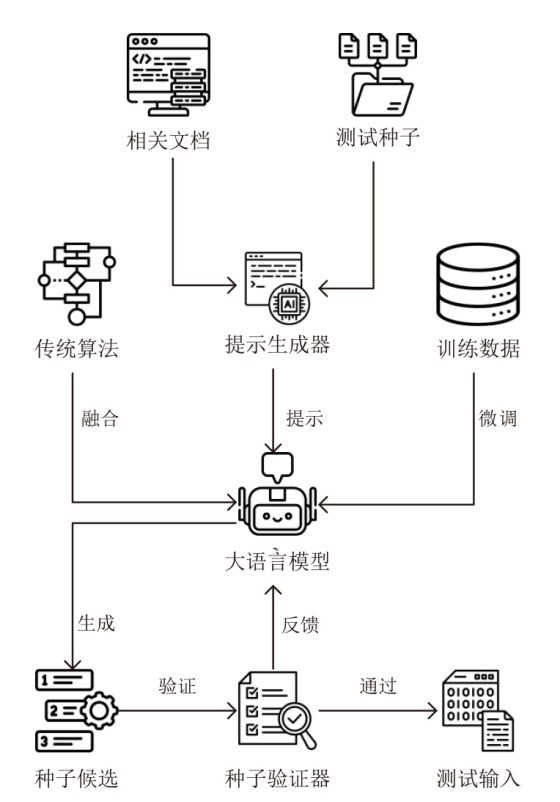
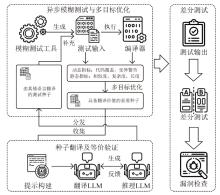
图3
Fuzpiler工作流程
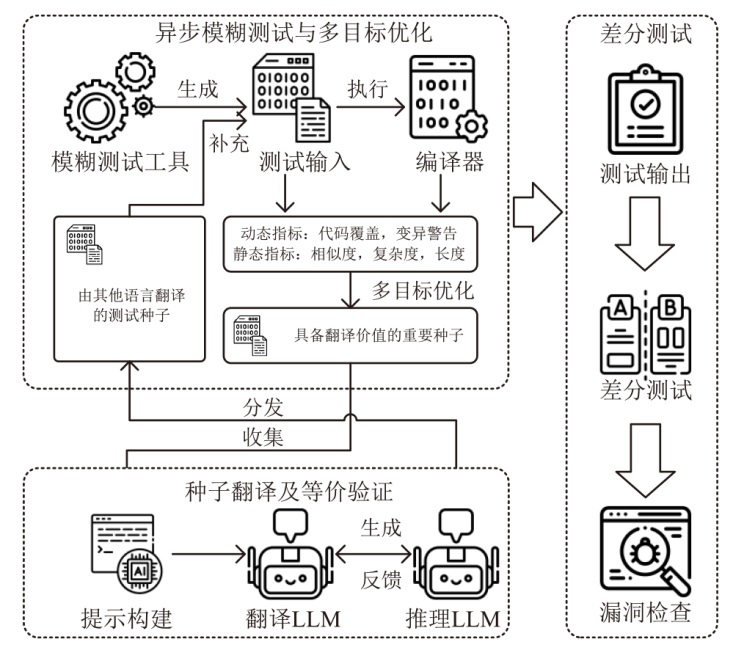

图4
代码翻译与等价验证提示工程模板

表1
差分测试设置
| 差分测试维度 | 差分内容 |
|---|---|
| 跨编译器差分 测试 | 源代码 |
| 翻译代码 | |
| 跨优化等级差分测试 | O0(关闭优化,以最直观方式生成代码) |
| O1(只启用基础优化) | |
| O2(开启更激进的优化,包括循环展开与死代码消除) | |
| O3(面向性能的最高级别优化) | |
| Ofast(包含可能违反语言标准的激进优化) | |
| Os(以减小二进制体积为目标的优化) | |
| Oz(进一步压缩二进制大小) |
表2
被测试编程语言、编译器及其基线工具
| 编程语言 | 编译器 | 基线工具 | 测试版本 | 范式 |
|---|---|---|---|---|
| C | Clang | CSmith[ | 20.1.0 | 命令式 |
| C++ | Clang++ | YarpGen[ | 20.1.0 | 面向对象式、命令式、 泛型编程 |
| Rust | Rustc | RustSmith[ | 1.89.0 | 函数式、命令式、并发式 |
表3
Fuzpiler与基线工具对比结果
| 编译器 (总代码分支) | 测试工具 | 测试种子数/个 | 分支覆盖/千行 | 分支覆盖 对比 | 成本 /美元 |
|---|---|---|---|---|---|
| Clang (2001432) | CSmith | 1145.0 | 451293.0 | — | — |
| Fuzpiler | 1039.0 | 474699.0 | 23406.0 (+ 5.19%) | 2.08 | |
| Clang++ (1777523) | YarpGen | 2143.2 | 151343.0 | — | — |
| Fuzpiler | 928.8 | 206681.6 | 55338.6(+36.57%) | 2.76 | |
| Rustc (619666) | RustSmith | 6889.4 | 135555.0 | — | — |
| Fuzpiler | 1045.4 | 167966.4 | 32411.4(+23.91%) | 2.32 |
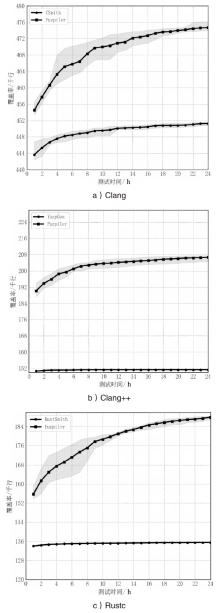
图5
Fuzpiler与基线工具24 h模糊测试增长曲线
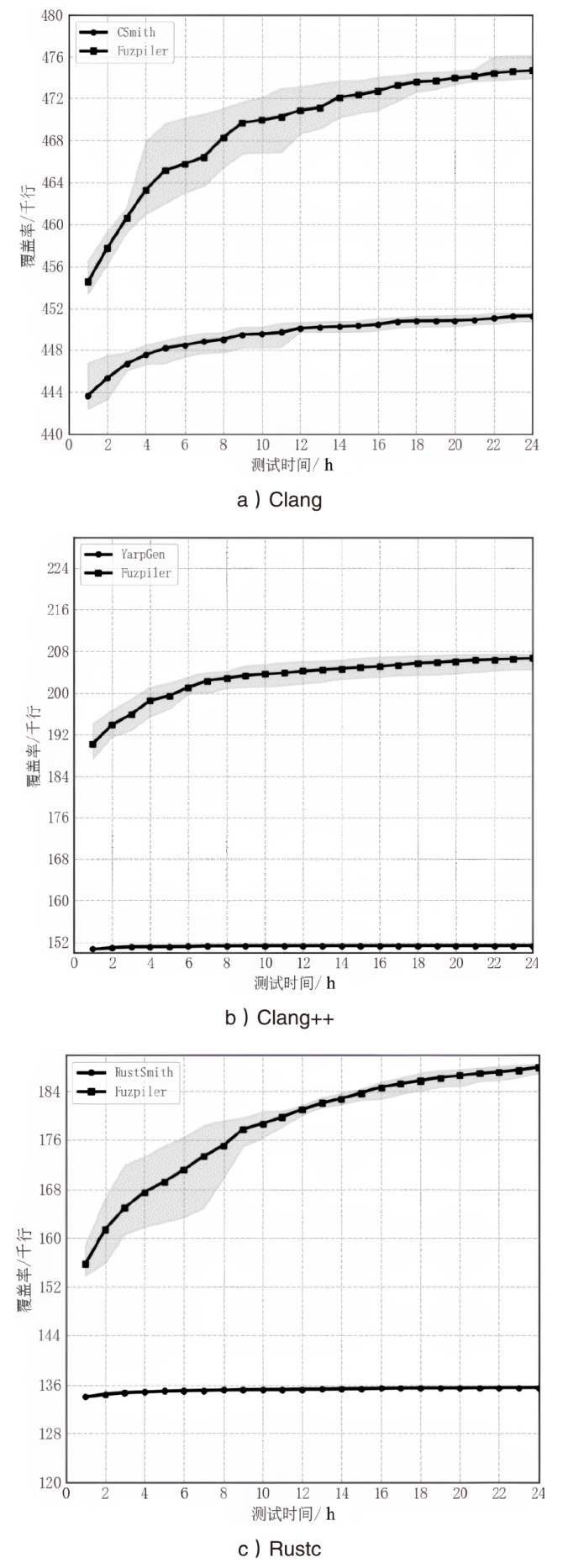
表4
Fuzpiler种子翻译与等价验证结果
| 源语言 | 目标 语言 | 测试种子数 /个 | 有效种子数 /个 | 有效种子 占比 | 等价种子数 /个 | 等价种子 占比 |
|---|---|---|---|---|---|---|
| C | C++ | 464.0 | 358.8 | 77.33% | 354.2 | 98.72% |
| Rust | 524.2 | 325.4 | 62.08% | 288.2 | 88.57% | |
| C++ | C | 520.6 | 396.2 | 76.10% | 332.0 | 83.80% |
| Rust | 521.2 | 236.0 | 45.28% | 225.6 | 95.59% | |
| Rust | C | 518.4 | 425.4 | 82.06% | 188.6 | 44.33% |
| C++ | 464.8 | 300.4 | 64.63% | 191.0 | 63.58% | |
| 总计 | — | 3013.2 | 2042.2 | 67.78% | 1579.6 | 77.35% |
表5
Fuzpiler消融实验结果
| 编译器 | 测试 工具 | 测试 种子数 | 有效种子数/个 | 有效种子占比 | 等价种子数/个 | 等价种子 占比 |
|---|---|---|---|---|---|---|
| Clang | Fuzpiler | 1039 | 821.6 | 79.08% | 510.6 | 62.15% |
| w/o OOM | 1104.4 | 814.4 | 73.74% | 467.4 | 57.39% | |
| w/o SEC | 1461.8 | 1073.4 | 73.43% | 544.8 | 50.75% | |
| Clang++ | Fuzpiler | 928.8 | 659.2 | 70.97% | 545.2 | 82.71% |
| w/o OOM | 970.2 | 609.4 | 62.81% | 491.2 | 80.60% | |
| w/o SEC | 1183.4 | 736.2 | 62.21% | 548.2 | 74.46% | |
| Rustc | Fuzpiler | 1045.4 | 561.4 | 53.70% | 543.8 | 96.86% |
| w/o OOM | 1136.0 | 576.8 | 50.77% | 523.8 | 90.81% | |
| w/o SEC | 1452.6 | 723.8 | 49.83% | 539.4 | 74.52% | |
| 编译器 | 测试 工具 | 测试 种子数 | 分支覆盖数/千行 | 分支覆盖对比 | — | — |
| Clang | Fuzpiler | 1039.0 | 474699.0 | — | — | — |
| w/o OOM | 1104.4 | 471431.4 | -3267.6 (-0.69%) | — | — | |
| w/o SEC | 1461.8 | 473025.2 | -1673.8 (-0.35%) | — | — | |
| Clang++ | Fuzpiler | 928.8 | 206681.6 | — | — | — |
| w/o OOM | 970.2 | 199463.0 | -7218.6 (-3.65%) | — | — | |
| w/o SEC | 1183.4 | 203331.0 | -3350.6 (-1.62%) | — | — | |
| Rustc | Fuzpiler | 1045.4 | 167966.4 | — | — | — |
| w/o OOM | 1136.0 | 154930.4 | -13036 (-7.76%) | — | — | |
| w/o SEC | 1452.6 | 159716.0 | -8250.4 (-4.91%) | — | — |
| [1] | RAHMAN A, BOSE D B, BARSHA F L, et al. Defect Categorization in Compilers: A Multi-Vocal Literature Review[J]. ACM Computing Surveys, 2024, 56(4): 1-42. |
| [2] | MANÈS V J M, HAN H, HAN C, et al. The Art, Science, and Engineering of Fuzzing: A Survey[J]. IEEE Transactions on Software Engineering, 2021, 47(11): 2312-2331. |
| [3] | YANG Xuejun, CHEN Yang, EIDE E, et al. Finding and Understanding Bugs in C Compilers[C]// ACM. The 32nd ACM SIGPLAN Conference on Programming Language Design and Implementation. New York: ACM, 2011: 283-294. |
| [4] | LIVINSKII V, BABOKIN D, REGEHR J. Random Testing for C and C++ Compilers with YARPGen[J]. Proceedings of the ACM on Programming Languages, 2020, 4: 1-25. |
| [5] | SHARMA M, YU Pingshi, DONALDSON A F. RustSmith: Random Differential Compiler Testing for Rust[C]// ACM. The 32nd ACM SIGSOFT International Symposium on Software Testing and Analysis. New York: ACM, 2023: 1483-1486. |
| [6] | HOLLER C, HERZIG K, ZELLER A. Fuzzing with Code Fragments[C]// USENIX. 21st USENIX Security Symposium. Berkeley: USENIX, 2012: 445-458. |
| [7] | CHALIASOS S, SOTIROPOULOS T, SPINELLIS D, et al. Finding Typing Compiler Bugs[C]// ACM. The 43rd ACM SIGPLAN International Conference on Programming Language Design and Implementation. New York: ACM, 2022: 183-198. |
| [8] | LE V, AFSHARI M, SU Zhendong. Compiler Validation via Equivalence Modulo Inputs[J]. ACM SIGPLAN Notices, 2014, 49(6): 216-226. |
| [9] | LE V, SUN Chengnian, SU Zhendong. Finding Deep Compiler Bugs via Guided Stochastic Program Mutation[J]. ACM SIGPLAN Notices, 2015, 50(10): 386-399. |
| [10] | LIDBURY C, LASCU A, CHONG N, et al. Many-Core Compiler Fuzzing[J]. ACM SIGPLAN Notices, 2015, 50(6): 65-76. |
| [11] | JIANG Bo, WANG Xiaoyan, CHAN W K, et al. CUDAsmith: A Fuzzer for CUDA Compilers[C]// IEEE. 2020 IEEE 44th Annual Computers, Software, and Applications Conference (COMPSAC). New York: IEEE, 2020: 861-871. |
| [12] | XIAO Dongwei, LIU Zhibo, YUAN Yuanyuan, et al. Metamorphic Testing of Deep Learning Compilers[J]. Proceedings of the ACM on Measurement and Analysis of Computing Systems, 2022, 6(1): 1-28. |
| [13] | CUMMINS C, PETOUMENOS P, MURRAY A, et al. Compiler Fuzzing through Deep Learning[C]// ACM. The 27th ACM SIGSOFT International Symposium on Software Testing and Analysis. New York: ACM, 2018: 95-105. |
| [14] | LEE S, HAN H S, CHA S K, et al. Montage: A Neural Network Language Model-Guided JavaScript Engine Fuzzer[C]// USENIX. 29th USENIX Security Symposium. Berkeley: USENIX, 2020: 2613-2630. |
| [15] | LIU Xiao, LI Xiaoting, PRAJAPATI R, et al. DeepFuzz: Automatic Generation of Syntax Valid C Programs for Fuzz Testing[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2019, 33(1): 1044-1051. |
| [16] | XU Haoran, WANG Yongjun, FAN Shuhui, et al. DSmith: Compiler Fuzzing through Generative Deep Learning Model with Attention[C]// IEEE. 2020 International Joint Conference on Neural Networks (IJCNN). New York: IEEE, 2020: 1-9. |
| [17] | XIA C S, PALTENGHI M, JIA Letian, et al. Fuzz4All: Universal Fuzzing with Large Language Models[C]// ACM. The IEEE/ACM 46th International Conference on Software Engineering. New York: ACM, 2024: 1-13. |
| [18] | LIU Fang, LIU Yang, SHI Lin, et al. Beyond Functional Correctness: Exploring Hallucinations in LLM-Generated Code[EB/OL].(2024-05-11)[2025-10-25]. https://arxiv.org/abs/2404.00971. |
| [19] | ZHU Xiaogang, ZHOU Wei, HAN Qinglong, et al. When Software Security Meets Large Language Models: A Survey[J]. IEEE/CAA Journal of Automatica Sinica, 2025, 12(2): 317-334. |
| [20] | MIAO Siwei, WANG Juan, ZHANG Chong, et al. Deep Learning in Fuzzing: A Literature Survey[C]// IEEE. 2022 IEEE the 2nd International Conference on Electronic Technology, Communication and Information (ICETCI). New York: IEEE, 2022: 220-223. |
| [21] | ALAGARSAMY S, TANTITHAMTHAVORN C, ALETI A. A3Test:Assertion-Augmented Automated Test Case Generation[EB/OL].(2024-08-30)[2025-10-25]. https://doi.org/10.1016/j.infsof.2024.107565. |
| [22] | DENG Yinlin, XIA C S, YANG Chenyuan, et al. Large Language Models Are Edge-Case Fuzzers: Testing Deep Learning Libraries via FuzzGPT[EB/OL].(2023-04-04)[2025-10-25]. https://arxiv.org/abs/2304.02014. |
| [23] | ZHANG Hongxiang, RONG Yuyang, HE Yifeng, et al. LLAMAFUZZ: Large Language Model Enhanced Greybox Fuzzing[EB/OL].(2025-10-03)[2025-10-25]. https://arxiv.org/abs/2406.07714. |
| [24] | DENG Yinlin, XIA C S, PENG Haoran, et al. Large Language Models Are Zero-Shot Fuzzers: Fuzzing Deep-Learning Libraries via Large Language Models[C]// ACM. The 32nd ACM SIGSOFT International Symposium on Software Testing and Analysis. New York: ACM, 2023: 423-435. |
| [25] | NASHID N, SINTAHA M, MESBAH A. Retrieval-Based Prompt Selection for Code-Related Few-Shot Learning[C]// IEEE. 2023 IEEE/ACM the 45th International Conference on Software Engineering (ICSE). New York: IEEE, 2023: 2450-2462. |
| [26] | VIKRAM V, LEMIEUX C, SUNSHINE J, et al. Can Large Language Models Write Good Property-Based Tests[EB/OL].(2024-07-22)[2025-10-25]. https://arxiv.org/abs/2307.04346. |
| [27] | CHEN Yinghao, HU Zehao, ZHI Chen, et al. ChatUniTest: A Framework for LLM-Based Test Generation[C]// ACM. The 32nd ACM International Conference on the Foundations of Software Engineering. New York: ACM, 2024: 572-576. |
| [28] | MAHBUB P, RAHMAN M M, SHUVO O, et al. Bugsplainer: Leveraging Code Structures to Explain Software Bugs with Neural Machine Translation[C]// IEEE. 2023 IEEE International Conference on Software Maintenance and Evolution (ICSME). New York: IEEE, 2023: 530-535. |
| [29] | YUAN Zhiqiang, LIU Mingwei, DING Shiji, et al. Evaluating and Improving ChatGPT for Unit Test Generation[J]. Proceedings of the ACM on Software Engineering, 2024, 1: 1703-1726. |
| [30] | SHOU Chaofan, LIU Jing, LU Doudou, et al. LLM4Fuzz:Guided Fuzzing of Smart Contracts with Large Language Models[EB/OL].(2024-01-20)[2025-10-25]. https://arxiv.org/abs/2401.11108. |
| [31] | LI Yuekang, XUE Yinxing, CHEN Hongxu, et al. Cerebro: Context-Aware Adaptive Fuzzing for Effective Vulnerability Detection[C]// ACM. The 2019 27th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering. New York: ACM, 2019: 533-544. |
| [32] | GALLEY M, GAO Jianfeng, HE Pengcheng, et al. Guiding Large Language Models via Directional Stimulus Prompting[J]. Advances in Neural Information Processing Systems, 2023, 36: 62630-62656. |
| [1] | 崔津华, 董亮, 杨新. 大语言模型推理隐私保护技术综述[J]. 信息网络安全, 2026, 26(4): 503-520. |
| [2] | 胡勉宁, 李欣, 李明锋, 袁得嵛. 基于大语言模型的多策略增强中文网络威胁情报实体抽取研究[J]. 信息网络安全, 2026, 26(4): 615-625. |
| [3] | 袁明, 邹其霖, 袁文骐, 王群. 大语言模型提示词注入攻击与防御综述[J]. 信息网络安全, 2026, 26(3): 341-354. |
| [4] | 顾兆军, 李丽, 隋翯. 基于大语言模型的SQL注入漏洞检测载荷生成方法[J]. 信息网络安全, 2026, 26(2): 274-290. |
| [5] | 仝鑫, 焦强, 王靖亚, 袁得嵛, 金波. 公共安全领域大语言模型的可信性研究综述:风险、对策与挑战[J]. 信息网络安全, 2026, 26(1): 24-37. |
| [6] | 胡雨翠, 高浩天, 张杰, 于航, 杨斌, 范雪俭. 车联网安全自动化漏洞利用方法研究[J]. 信息网络安全, 2025, 25(9): 1348-1356. |
| [7] | 刘会, 朱正道, 王淞鹤, 武永成, 黄林荃. 基于深度语义挖掘的大语言模型越狱检测方法研究[J]. 信息网络安全, 2025, 25(9): 1377-1384. |
| [8] | 王磊, 陈炯峄, 王剑, 冯袁. 基于污点分析与文本语义的固件程序交互关系智能逆向分析方法[J]. 信息网络安全, 2025, 25(9): 1385-1396. |
| [9] | 张燕怡, 阮树骅, 郑涛. REST API设计安全性检测研究[J]. 信息网络安全, 2025, 25(8): 1313-1325. |
| [10] | 陈平, 骆明宇. 云边端内核竞态漏洞大模型分析方法研究[J]. 信息网络安全, 2025, 25(7): 1007-1020. |
| [11] | 酆薇, 肖文名, 田征, 梁中军, 姜滨. 基于大语言模型的气象数据语义智能识别算法研究[J]. 信息网络安全, 2025, 25(7): 1163-1171. |
| [12] | 张学旺, 卢荟, 谢昊飞. 基于节点中心性和大模型的漏洞检测数据增强方法[J]. 信息网络安全, 2025, 25(4): 550-563. |
| [13] | 顾欢欢, 李千目, 刘臻, 王方圆, 姜宇. 基于虚假演示的隐藏后门提示攻击方法研究[J]. 信息网络安全, 2025, 25(4): 619-629. |
| [14] | 解梦飞, 傅建明, 姚人懿. 基于LLM的多媒体原生库模糊测试研究[J]. 信息网络安全, 2025, 25(3): 403-414. |
| [15] | 秦中元, 王田田, 刘伟强, 张群芳. 大语言模型水印技术研究进展[J]. 信息网络安全, 2025, 25(2): 177-193. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||