信息网络安全 ›› 2021, Vol. 21 ›› Issue (1): 1-9.doi: 10.3969/j.issn.1671-1122.2021.01.001
融合攻击图和博弈模型的网络防御策略生成方法
金志刚1, 王新建1, 李根1( ), 岳顺民2
), 岳顺民2
- 1.天津大学电气自动化与信息工程学院,天津 300072
2.国网天津市电力公司,天津 300010
-
收稿日期:2020-10-09出版日期:2021-01-10发布日期:2021-02-23 -
通讯作者:李根 E-mail:ligen@tju.edu.cn -
作者简介:金志刚(1972—),男,上海,教授,博士,主要研究方向为水下传感器网络、网络安全、智能电网|王新建(1996—),男,天津,硕士研究生,主要研究方向为网络安全、区块链技术、智能电网|李根(1984—),男,天津,工程师,博士,主要研究方向为车联网、网络安全与区块链|岳顺民(1966—),男,天津,高级工程师,博士,主要研究方向为智能电网、电网信息通信。 -
基金资助:国家自然科学基金(61571318);中国博士后科学基金(2016M601265)
The Generation Method of Network Defense Strategy Combining with Attack Graph and Game Model
JIN Zhigang1, WANG Xinjian1, LI Gen1(), YUE Shunmin2
- 1. School of Electronic and Information Engineering, Tianjin University, Tianjin 300072, China
2. State Grid Tianjin Electric Power Company, Tianjin 300010, China
-
Received:2020-10-09Online:2021-01-10Published:2021-02-23 -
Contact:LI Gen E-mail:ligen@tju.edu.cn
摘要:
近些年威胁网络安全的事件日趋频繁,黑客的攻击手段越来越复杂,网络安全防护的难度不断增加。针对实际攻防环境中攻击策略复杂多变和攻击者不理性的问题,文章将攻击图融入攻防博弈模型,并引入强化学习算法,设计了一种网络主动防御策略生成方法。该方法首先基于改进攻击图的网络脆弱性评估模型,成功压缩策略空间并有效降低建模难度,然后对网络攻防进行博弈模型构建,将攻击者和防御者对网络的攻防策略问题设计为一个多阶段的随机博弈模型,引入强化学习Minimax-Q设计了自学习网络防御策略选取算法。防御者在经过对一系列的攻击行为学习之后,求解出针对该攻击者的最优防御策略。最后,本文通过仿真实验验证了该算法的有效性和先进性。
中图分类号:
引用本文
金志刚, 王新建, 李根, 岳顺民. 融合攻击图和博弈模型的网络防御策略生成方法[J]. 信息网络安全, 2021, 21(1): 1-9.
JIN Zhigang, WANG Xinjian, LI Gen, YUE Shunmin. The Generation Method of Network Defense Strategy Combining with Attack Graph and Game Model[J]. Netinfo Security, 2021, 21(1): 1-9.
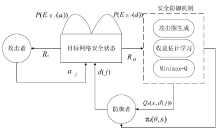
图1
网络安全自防御框架
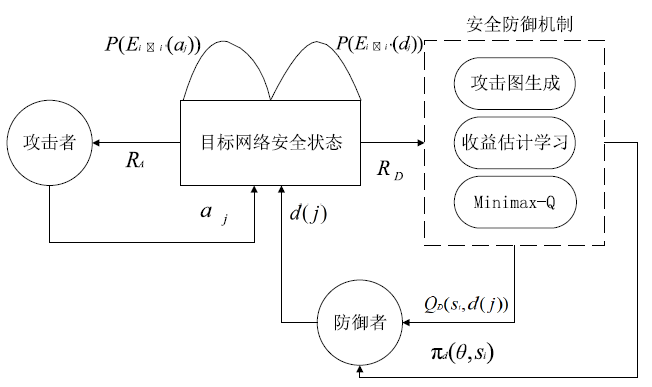
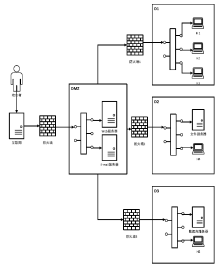
图2
实验场景网络拓扑
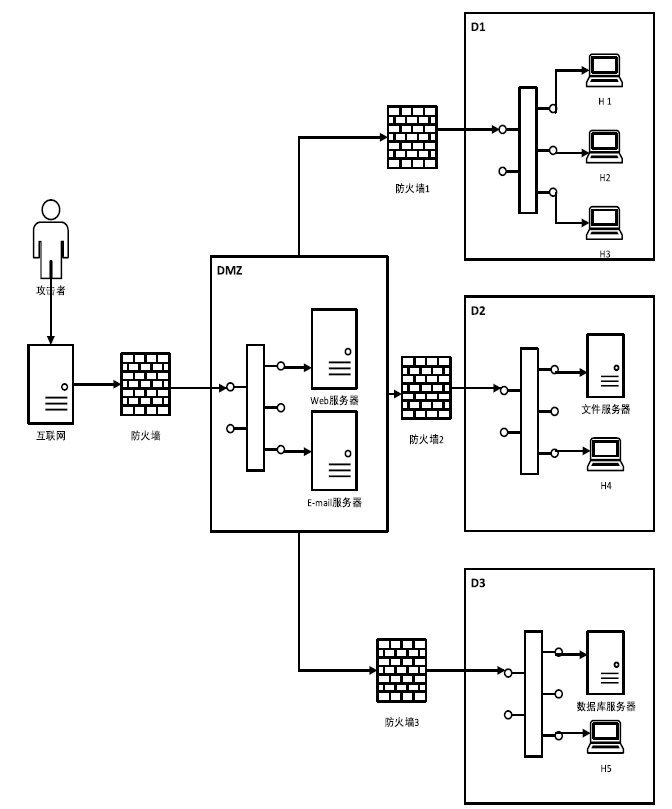
表1
各组件关键漏洞脆弱性信息
| 主机/服务器 | CVE编号 | 漏洞信息 | 利用漏洞的攻击动作编号 |
|---|---|---|---|
| Web服务器 | CVE-2013-2249 | 模块安全漏洞 | a1 |
| CVE-2020-4362 | 权限提升漏洞 | a10 | |
| CVE-2017-0101 | 整数溢出漏洞 | a6 | |
| H1 | CVE-2019-0708 | 远程桌面远程代码执行漏洞 | a11 |
| CVE-2014-8631 | 安全绕过漏洞 | a5 | |
| CVE-2019-9766 | 缓冲区溢出漏洞 | a9 | |
| H2 | CVE-2011-0638 | USB 数据任意程序执行漏洞 | a2 |
| H3 | CVE-2018-1111 | 远程代码执行漏洞 | a12 |
| CVE-2015-1793 | OpenSSL证书验证安全限制绕过漏洞 | a8 | |
| H4 | CVE-2015-2808 | 弱密码套件漏洞 | a7 |
| 网络文件 服务器 | CVE-2014-7226 | HttpFileServer代码注入漏洞 | a3 |
| 数据库 服务器 | CVE-2016-6617 | SQL注入漏洞 | a4 |
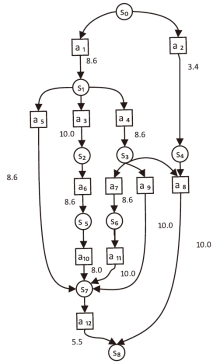
图3
改进攻击图
表2
防御策略描述
| 防御策略 | 描述 |
|---|---|
| DMQ-R | 防御者采取Minimax-Q算法,攻击者采取随机策略,双方进行攻防博弈后,得到的防御策略 |
| DQL-R | 防御者采取Q-learning算法,攻击者采取随机策略,双方进行攻防博弈后,得到的防御策略 |
| DMQ-MQ | 防御者和攻击者都采取Minimax-Q算法,双方进行攻防博弈后,得到的防御策略 |
| DQL-QL | 防御者和攻击者都采取Q-learning算法,双方进行攻防博弈后,得到的防御策略 |
表3
防御胜率
| VS | DMQ-R | DMQ-MQ | DQL-R | DQL-QL |
|---|---|---|---|---|
| 随机攻击策略% | 100 | 100 | 90.9 | 83.6 |
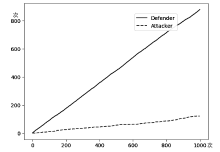
图4
DMQ-R 和 AQL-R攻防博弈结果
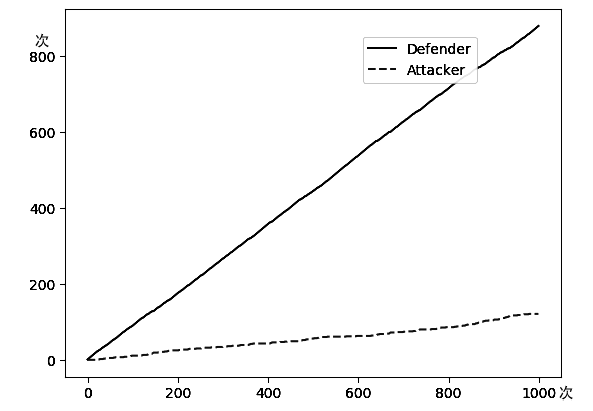
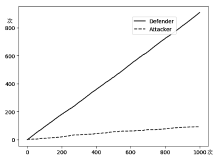
图5
DMQ-MQ 和 AQL-QL攻防博弈结果

| [1] | GB/T 22239-2019 Information Security Technology—Base Line for Classified Protection of Cyber Security[S]. Beijing: Standardization Administration of the People's Republic of China, 2019. |
| GB/T 22239-2019 信息安全技术网络安全等级保护基本要求[S]. 北京:中国国家标准化管理委员会, 2019. | |
| [2] | National Internet Emergency Center. Report on China Internet network security in 2019[M]. Beijing: Posts and Telecommunications Press, 2020. |
| 国家计算机网络应急技术处理协调中心. 2019年中国互联网网络安全报告[M]. 北京: 人民邮电出版社, 2020. | |
| [3] | LYE K W, WING J M. Game strategies in network security[J]. International Journal of Information Security, 2005,4(2):71-86. |
| [4] | WANG Jiaxin, FENG Yi, YOU Rui. Measuring Network Security by Dependency Relationship Graph and Common Vulnerability Scoring System[J]. Journal of Computer Applications, 2019,39(6):1719-1727. |
| 王佳欣, 冯毅, 由睿. 基于依赖关系图和通用漏洞评分系统的网络安全度量[J]. 计算机应用, 2019,39(6):1719-1727. | |
| [5] | HU Hao, LIU Yuling, ZHANG Yuchen, et al. Survey of Attack Graph Based Network Security Metric[J]. Chinese Journal of Network and Information Security, 2018,4(9):5-20. |
| 胡浩, 刘玉岭, 张玉臣, 等. 基于攻击图的网络安全度量研究综述[J]. 网络与信息安全学报, 2018,4(9):5-20. | |
| [6] | CONITZER V, SANDHOLM T. Computing the Optimal Strategy to Commit to [C] // ACM. The 7th ACM Conference on Electronic Commerce, June 11-15, 2006, New York, NY, USA. Ann Arbor: Association for Computing Machinery, 2006: 82-90. |
| [7] | LIU Jingwei, LIU Jingju, LU Yuliang, et al. Application of Game Theory in Network Security Situation Awareness[J]. Journal of Computer Applications, 2017,37(S2):48-51, 64. |
| 刘景玮, 刘京菊, 陆余良, 等. 博弈论在网络安全态势感知中的应用[J]. 计算机应用, 2017,37(S2):48-51,64. | |
| [8] | CAI Xingpu, Wang Qi, TAI Wei, et al. A Multi-stage Game Based Defense Method against False Data Injection Attack on Cyber Physical Power System[J]. Electric Power Construction, 2019,40(5):48-54. |
| 蔡星浦, 王琦, 邰伟, 等. 基于多阶段博弈的电力CPS虚假数据注入攻击防御方法[J]. 电力建设, 2019,40(5):48-54. | |
| [9] | SHELAR D, AMIN S. Security Assessment of Electricity Distribution Networks under DER Node Compromises[J]. IEEE Transactions on Control of Network Systems, 2017,4(1):23-36. |
| [10] | ZHANG Hongqi, YANG Junnan, ZHANG Chuanfu. Defense Decision-making Method Based on Incomplete Information Stochastic Game and Q-learning[J]. Journal on Communications, 2018,39(8):56-68. |
| 张红旗, 杨峻楠, 张传富. 基于不完全信息随机博弈与Q-learning的防御决策方法[J]. 通信学报, 2018,39(8):56-68. | |
| [11] | WANG Zengguang, LU Yu, LI Xi. Active Defense Strategy Selection of Military Information Network Based on Incomplete Information Game[J]. Acta Armamentarii, 2020,41(3):608-617. |
| 王增光, 卢昱, 李玺. 基于不完全信息博弈的军事信息网络主动防御策略选取[J]. 兵工学报, 2020,41(3):608-617. | |
| [12] | LITTMAN, MICHAEL L. Markov Games as a Framework for Multi-agent Reinforcement Learning[C] //Machine Learning Proceedings. Proceedings of the Eleventh International Conference on Machine Learning (ML-94), June 27-July 2, 1994, Rutgers University, New Brunswick, NJ. San Mateo: Morgan Kauffman Publishers, 1994: 157-153. |
| [13] |
BIANCHI Reinaldo A C, MARTINS Murilo F, RIBEIRO Carlos H C, et al. Heuristically-accelerated Multiagent Reinforcement Learning[J]. IEEE Transactions on Cybernetics, 2014,44(2):252-265.
URL pmid: 23757547 |
| [1] | 王鹃, 杨泓远, 樊成阳. 一种基于多阶段攻击响应的SDN动态蜜罐[J]. 信息网络安全, 2021, 21(1): 27-40. |
| [2] | 刘大恒, 李红灵. QR码网络钓鱼检测研究[J]. 信息网络安全, 2020, 20(9): 42-46. |
| [3] | 李世斌, 李婧, 唐刚, 李艺. 基于HMM的工业控制系统网络安全状态预测与风险评估方法[J]. 信息网络安全, 2020, 20(9): 57-61. |
| [4] | 毕亲波, 赵呈东. 基于STRIDE-LM的5G网络安全威胁建模研究与应用[J]. 信息网络安全, 2020, 20(9): 72-76. |
| [5] | 来疆亮, 侯一凡, 卢旭明. 基于信息度量和损耗的网络安全系统综合效能分析研究[J]. 信息网络安全, 2020, 20(8): 81-88. |
| [6] | 冉金鹏, 王翔, 赵尚弘, 高航航. 基于果蝇优化的虚拟SDN网络映射算法[J]. 信息网络安全, 2020, 20(6): 65-74. |
| [7] | 孟相如, 徐江, 康巧燕, 韩晓阳. 基于熵权VIKOR的安全虚拟网络映射算法[J]. 信息网络安全, 2020, 20(5): 21-28. |
| [8] | 金辉, 张红旗, 张传富, 胡浩. 复杂网络中基于QRD的主动防御决策方法研究[J]. 信息网络安全, 2020, 20(5): 72-82. |
| [9] | 刘建伟, 韩祎然, 刘斌, 余北缘. 5G网络切片安全模型研究[J]. 信息网络安全, 2020, 20(4): 1-11. |
| [10] | 赵志岩, 纪小默. 智能化网络安全威胁感知融合模型研究[J]. 信息网络安全, 2020, 20(4): 87-93. |
| [11] | 黎水林, 祝国邦, 范春玲, 陈广勇. 一种新的等级测评综合得分算法研究[J]. 信息网络安全, 2020, 20(2): 1-6. |
| [12] | 郭启全, 张海霞. 关键信息基础设施安全保护技术体系[J]. 信息网络安全, 2020, 20(11): 1-9. |
| [13] | 顾兆军, 郝锦涛, 周景贤. 基于改进双线性卷积神经网络的恶意网络流量分类算法[J]. 信息网络安全, 2020, 20(10): 67-74. |
| [14] | 荆涛, 万巍. 面向属性迁移状态的P2P网络行为分析方法研究[J]. 信息网络安全, 2020, 20(1): 16-25. |
| [15] | 裘玥. 大型体育赛事网络安全风险分析与评估[J]. 信息网络安全, 2019, 19(9): 61-65. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||