信息网络安全 ›› 2020, Vol. 20 ›› Issue (5): 72-82.doi: 10.3969/j.issn.1671-1122.2020.05.009
复杂网络中基于QRD的主动防御决策方法研究
金辉1,2,*( ), 张红旗1,2, 张传富1,2, 胡浩1,2
), 张红旗1,2, 张传富1,2, 胡浩1,2
- 1. 中国人民解放军战略支援部队信息工程大学,郑州 450004
2. 河南省信息安全重点实验室,郑州 450004
-
收稿日期:2020-01-15出版日期:2020-05-10发布日期:2020-06-05 -
通讯作者:金辉 E-mail:695969075@qq.com -
作者简介:金辉(1988—),男,宁夏,硕士研究生,主要研究方向为网络安全建模与仿真;|张红旗(1962—),男,河北,教授,博士,主要研究方向为网络安全、等级保护和信息安全管理等|张传富(1973—),男,山东,副教授,博士,主要研究方向为计算机建模与仿真技术等|胡浩(1989—),男,安徽,讲师,博士,主要研究方向为网络态势感知、网络行为分析和图像秘密共享等 -
基金资助:国家自然科学基金(61902427)
Research on Active Defense Decision-making Method Based on QRD in Complex Network
JIN Hui1,2,*(), ZHANG Hongqi1,2, ZHANG Chuanfu1,2, HU Hao1,2
- 1. PLA SSF Information Engineering University, Zhengzhou 450004, China
2. Henan Province Key Laboratory of Information Security, Zhengzhou 450004, China
-
Received:2020-01-15Online:2020-05-10Published:2020-06-05 -
Contact:Hui JIN E-mail:695969075@qq.com
摘要:
针对未知网络攻防场景下,信息不公开导致最优防御策略难以准确选取的问题。通过对不完全信息下的网络攻防博弈进行分析,文章首先构建具有探索机制的攻防演化博弈模型;然后基于Boltzmann探索的Q-learning复制动态方程构建攻防决策动态演化方程;最后通过求解演化稳定均衡给出最优防御策略选取方法,并刻画攻防策略的演化轨迹。仿真实验结果表明,对于小规模局域网,在探索程度参数取10附近时,生成的最优防御策略具有较好的可解释性和稳定性,能够使得防御主体获取最大防御收益。
中图分类号:
引用本文
金辉, 张红旗, 张传富, 胡浩. 复杂网络中基于QRD的主动防御决策方法研究[J]. 信息网络安全, 2020, 20(5): 72-82.
JIN Hui, ZHANG Hongqi, ZHANG Chuanfu, HU Hao. Research on Active Defense Decision-making Method Based on QRD in Complex Network[J]. Netinfo Security, 2020, 20(5): 72-82.

图1
攻防博弈树
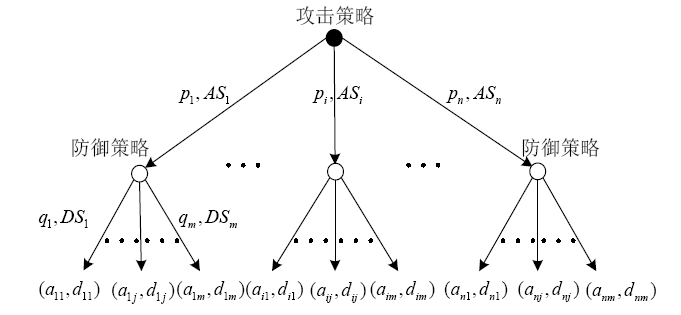
表1
攻击策略及序列原子攻击动作
| 序号 | 原子攻击动作名称 | 攻击策略 | |
|---|---|---|---|
| AS1 | AS2 | ||
| a1 | Port scanning | √ | |
| a2 | Obtain user privileges | √ | |
| a3 | Remote unauthorized access | √ | |
| a4 | Oracle TNS Listener | √ | |
| a5 | Buffer overflow attack | √ | |
表2
防御策略及序列原子防御动作
| 序号 | 原子防御动作名称 | 防御策略 | |
|---|---|---|---|
| DS1 | DS2 | ||
| d1 | Close idle ports | √ | |
| d2 | Modify account password | √ | |
| d3 | User authentication | √ | |
| d4 | Limit packets from ports | √ | |
| d5 | Reinstall Listener program | √ | |
| d6 | Install Oracle patches | √ | |
表3
攻防收益矩阵
| 攻击主体 | 防御主体 | |
|---|---|---|
| DS1 | DS2 | |
| AS1 | (100,-70) | (70,-10) |
| AS2 | (60,-50) | (80,-60) |
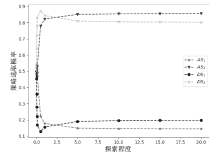
图2
探索因子τ对攻防策略演化的影响
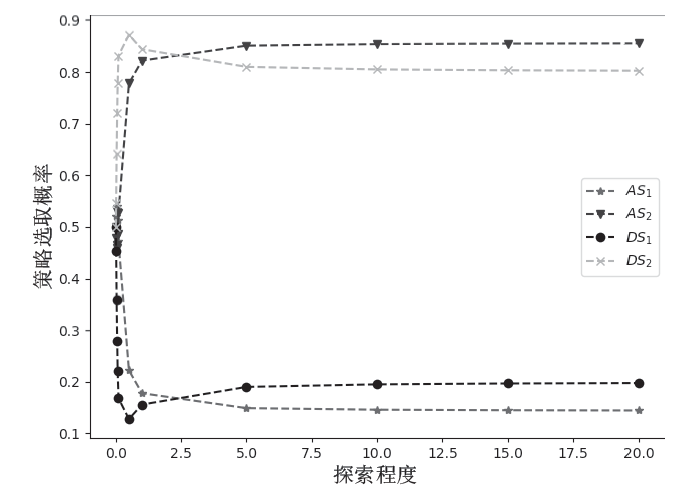
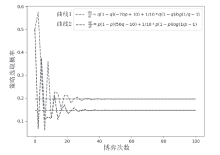
图3
策略AS1和DS1的演化轨迹
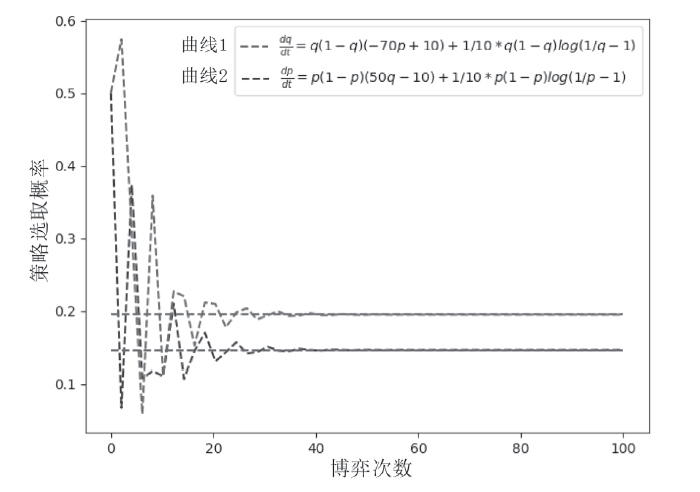
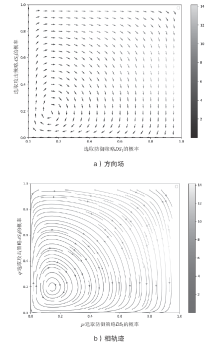
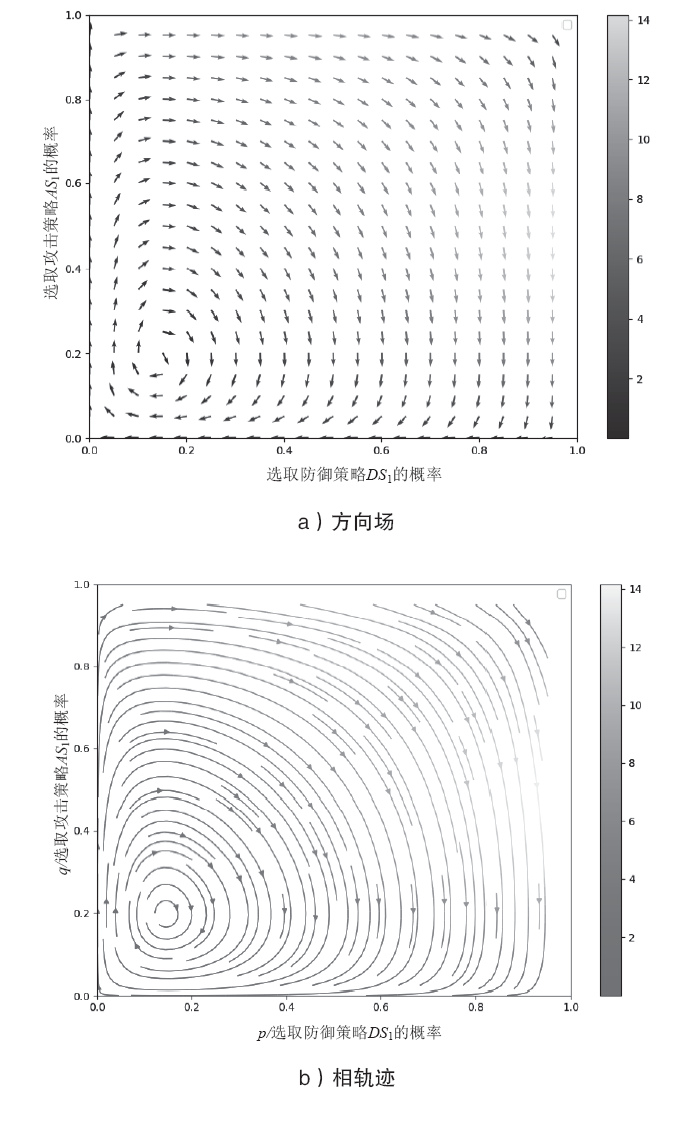
图4
攻防策略的方向场和相轨迹
| [1] | JIANG wei . Research on Key Technologies of Active Defense Based on game model of attack and defense[D]. Harbin: Harbin Institute of Technology, 2011. |
| 姜伟 . 基于攻防博弈模型的主动防御关键技术研究[D]. 哈尔滨:哈尔滨工业大学, 2010. | |
| [2] | IQBAL A, GUO M, GUNN L , et al. Game Theoretical Modelling of Network/Cyber Security[J]. IEEE Access, 2019,19(7):154167-154179. |
| [3] | ZHANG Hengwei, YU Dingkun, HAN Jihong , et al. Selection of Defense Strategy Based on Offensive and Defensive Signal Game Model[J]. Journal of Communications, 2016,37(5):51-61. |
| 张恒巍, 余定坤, 韩继红 , 等. 基于攻防信号博弈模型的防御策略选取方法[J]. 通信学报, 2016,37(5):51-61. | |
| [4] | LIU Jiang, ZHANG Hongqi, LIU Yi . Research on Optimal Selection of Dynamic Target Defense Based on Dynamic Games with Incomplete Information[J]. Chinese Journal of Electronics, 2018,46(1):82-89. |
| 刘江, 张红旗, 刘艺 . 基于不完全信息动态博弈的动态目标防御最优策略选取研究[J]. 电子学报, 2018,46(1):82-89. | |
| [5] |
LA Q D, QUEK T Q S, LEE J , et al. Deceptive Attack and Defense Game in Honeypot-Enabled Networks for the Internet of Things[J]. IEEE Internet of Things Journal, 2016,3(6):1025-1035.
doi: 10.1109/JIOT.2016.2547994 URL |
| [6] | GE X, ZHOU T, ZANG Y . Defense Strategy Selection Method for Stackelberg Security Game Based on Incomplete Information[EB/OL].https://www.researchgate.net/publication/335779277_Defense_Strategy_Selection_Method_for_Stackelberg_Security_Game_Based_on_Incomplete_Information, 2019-10-15. |
| [7] | ZHU Jianming, SONG Biao, HUANG Qiqi . An Evolutionary Game Model of Network Security Attack and Defense Based on System dynamics[J]. Journal of Communications, 2014,14(1):58-65. |
| 朱建明, 宋彪, 黄启发 . 基于系统动力学的网络安全攻防演化博弈模型[J]. 通信学报, 2014,14(1):58-65. | |
| [8] | HUANG Jianming, ZHANG Hengwei, WANG Jindong , et al. Selection of Defense Strategy Based on Offensive and Defensive Evolutionary Game Model[J]. Journal of Communications, 2017,38(1):168-176. |
| 黄健明, 张恒巍, 王晋东 , 等. 基于攻防演化博弈模型的防御策略选取方法[J]. 通信学报, 2017,38(1):168-176. | |
| [9] | DU J, JIANG C, CHEN K C , et al. Community-Structured Evolutionary Game for Privacy Protection in Social Networks[J]. IEEE Transactions on Information Forensics and Security, 2017,13(3):574-589. |
| [10] | ABASS A AA, XIAO L, MANDAYAM N B , et al. Evolutionary Game Theoretic Analysis of Advanced Persistent Threats Against Cloud Storage[J]. IEEE Access, 2017,17(5):8482-8491. |
| [11] | YANG Y, CHE B, ZENG Y , et al. MAIAD: A Multistage Asymmetric Information Attack and Defense Model Based on Evolutionary Game Theory[J]. Symmetry, 2019,11(2):215. |
| [12] | TAYLOR P D, JONKER L B . Evolutionary Stable Strategies and Game Dynamics[J]. Mathematical biosciences, 1978,40(1-2):145-156. |
| [13] | ZEEMAN E C . Dynamics of the Evolution of Animal Conflicts[J]. Journal of theoretical Biology, 1981,89(2):249-270. |
| [14] | TUYLS K, VERBEECK K, LENAERTS T . A Selection-Mutation Model for Q-learning in Multi-agent Systems[EB/OL]. https://www.researchgate.net/publication/221454784_A_selection-mutation_model_for_q-learning_in_multi-agent_systems, 2019-10-15. |
| [15] | PENG Wei, LIU Xiaoming, PENG Hui , et al. Research on the Network Attack Behavior under Finite Repeated Games[J]. Journal of Command and Control, 2015,1(4):118-121. |
| 彭伟, 刘晓明, 彭辉 , 等. 有限次重复博弈下的网络攻击行为研究[J]. 指挥与控制学报, 2015,1(4):118-121. | |
| [16] | JIANG Wei, FANG Binxing, TIAN Zhihong , et al. Network Security Evaluation and Optimal Active Defense Based on Attack and Defense Game Model[J]. Chinese Journal of Computers, 2009,32(4):229-239. |
| 姜伟, 方滨兴, 田志宏 , 等. 基于攻防博弈模型的网络安全测评和最优主动防御[J]. 计算机学报, 2009,32(4):229-239. | |
| [17] | HIRSHLEIFER J . Evolutionary Models in Economics and Law: Cooperation Versus Conflict Strategies[EB/OL]. , 2019-10-15. |
| [18] |
FRIEDMAN D . On Economic Applications of Evolutionary Game Theory[J]. Journal of Evolutionary Economics, 1998,8(1):15-43.
doi: 10.1007/s001910050054 URL |
| [19] | ZHANG weiying . Game Theory and Information Economics[M]. Shanghai: Truth&Wisdom Press, 2004. |
| 张维迎 . 博弈论与信息经济学[M]. 上海: 格致出版社, 2004. | |
| [20] | GORDON L, LOEB M, LUCYSHYN W , et al. 2015 CSI/FBI Computer Crime and Security Survey[EB/OL]. ttps://www.researchgate.net/publication/243784811_CSIFBI_Computer_Crime_and_Security_Survey. 2019-10-15. |
| [21] | CNNVD. China National Vulnerability Database of Information Security[EB/OL]. , 2019-10-15. |
| [1] | 饶绪黎, 徐彭娜, 陈志德, 许力. 基于不完全信息的深度学习网络入侵检测[J]. 信息网络安全, 2019, 19(6): 53-60. |
| [2] | 吕欣, 郭艳卿, 杨月圆. 重要信息系统信息安全保障能力评价研究[J]. 信息网络安全, 2014, 14(9): 22-25. |
| [3] | 贾非. 数据中心网络安全攻防[J]. , 2011, 11(7): 0-0. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||