信息网络安全 ›› 2016, Vol. 16 ›› Issue (11): 12-18.doi: 10.3969/j.issn.1671-1122.2016.11.003
一种基于改进模糊哈希的文件比较算法研究
邸宏宇1, 张静1, 于毅2, 王连印2( )
)
- 1.北京明朝万达科技股份有限公司,北京 100097
2. 国家质检总局信息中心,北京 100088
-
收稿日期:2016-09-18出版日期:2016-11-20发布日期:2020-05-13 -
作者简介:作者简介:邸宏宇(1980—),男,陕西,博士,主要研究方向为模式识别、信息安全;张静(1980—),男,北京,博士,主要研究方向为大数据应用与发展;于毅(1983—),男,北京,高级工程师,硕士,主要研究方向为信息安全;王连印(1960—),男,北京,研究员,博士,主要研究方向为电子政务、信息化应用、信息安全。
-
基金资助:国家信息安全专项[20131309]
Research on Document Comparison Algorithm Based on Modified Fuzzy Hash
Hongyu DI1, Jing ZHANG1, Yi YU2, Lianyin WANG2()
- 1. Beijing Wondersoft Technology Co., Ltd., Beijing 100097, China
2. Information Center of the General Administration of Quality Supervision Inspection and Quarantine of the People’s Republic of China, Beijing 100088, China;
-
Received:2016-09-18Online:2016-11-20Published:2020-05-13
摘要:
模糊哈希算法广泛应用于同源相似文件的检索、恶意代码检测、电子数据取证等领域。模糊哈希算法首先依据文件长度和文件内容检测对文件进行分片,再对每一个分片进行滚动哈希运算,最后将各分片的哈希值连接在一起,形成文件指纹,实现了具有局部敏感特性的近似最邻近搜索。文章采用了关键词触发的变长分片策略和基于simhash的滚动哈希计算方法对现有的模糊哈希算法进行改进,克服了分片长度依赖于文件长度、触发条件与分片中内容无紧密联系、运算性能受滚动窗口长度制约的缺陷。基于多种语料库的文件比较实验表明,文章提出的改进模糊哈希算法可以有效地实现同源相似文件的发现,且具备支持多级信息粒度比较的能力。
中图分类号:
引用本文
邸宏宇, 张静, 于毅, 王连印. 一种基于改进模糊哈希的文件比较算法研究[J]. 信息网络安全, 2016, 16(11): 12-18.
Hongyu DI, Jing ZHANG, Yi YU, Lianyin WANG. Research on Document Comparison Algorithm Based on Modified Fuzzy Hash[J]. Netinfo Security, 2016, 16(11): 12-18.

图1
模糊哈希算法流程图
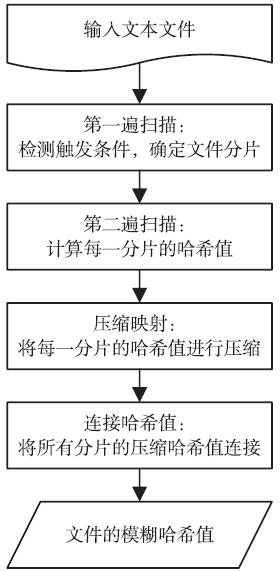

图2
改进的模糊哈希算法流程图


图3
simhash计算流程图
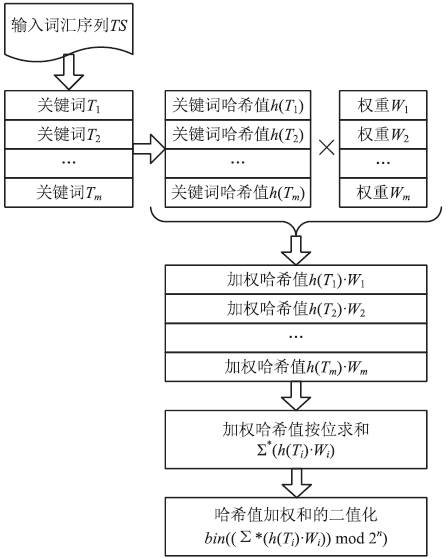
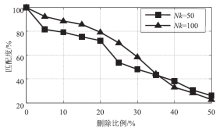
图4
删除处理后平均匹配度的变化情况


图5
匹配度阈值变化对算法性能的影响
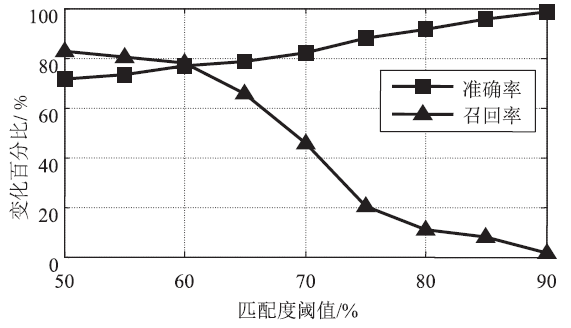
| [1] | 胡雪,封化民,李明伟,等. 数据挖掘中一种增强的Apriori算法分析[J]. 信息网络安全,2015(11):77-83. |
| [2] | ZAMORA J, MENDOZA M, ALLENDE H.Hashing-based Clustering in High Dimensional Data[J]. Expert Systems with Applications, 2016, 62(15): 202-211. |
| [3] | KHAN S, GANI A, WAHAB A W A, et al. Network Forensics: Review,Taxonomy,Open Challenges[EB/OL]., 2016-3-20. |
| [4] | 李亚萌,何泾沙. 基于Hash的YAFFS2文件各版本恢复算法研究[J]. 信息网络安全,2016(5):51-57. |
| [5] | CHRISTIAN W, MARKUS S, YORK Y.F2S2: Fast Forensic Similarity Search through Indexing Piecewise Hash Signatures[J]. Digital Investigation, 2013, 10(4): 361-371. |
| [6] | 王建峰. 基于哈希的最近邻查找[D]. 合肥:中国科学技术大学,2015. |
| [7] | INDYK P, MOTWANI R.Approximate Nearest Neighbors: Towards Removing the Curse of Dimensionality[C]//ACM. 30th Annual ACM Symposium on Theory of Computing, May 24-26, 1998, Dallas, Texas, USA. New York: ACM, 1998: 604-613. |
| [8] | BREITINGER F, BAIER H.Performance Issues about Context-triggered Piecewise Hashing[C]//EAI. Third International ICST Conference, October 26-28, 2011, Dublin, Ireland. Heidelberg: Springer, 2011: 141-155. |
| [9] | CHARIKAR M S.Similarity Estimation Techniques from Rounding Algorithms[C]//ACM. 34th Annual ACM Symposium on Theory of Computing, May 19-21, 2002, Montreal, Quebec, Canada. New York: ACM, 2002: 380-388. |
| [10] | 刘禹. 中文新闻分类语料库[EB/OL]. , 2016-6-20. |
| [11] | 尚海,罗森林,韩磊,等. 基于句义成分的短文本表示方法研究[J]. 信息网络安全,2016(5):64-70. |
| [12] | 李荣陆. 文本分类语料库(复旦)[EB/OL]. , 2016-6-21. |
| [13] | BREITINGER F, STIVAKTAKIS G, BAIER H.FRASH: A Framework to Test Algorithms of Similarity Hashing[J]. Digital Investigation, 2013, 10(10): 1066-1069. |
| [14] | National Institute of Standards and Technology. National Software Reference Library[EB/OL]. , 2016-6-21. |
| [15] | PAULEVE L, JEGOU H, AMSALEG L.Locality Sensitive Hashing: A Comparison of Hash Function Types and Querying Mechanisms[J]. Pattern Recognition Letters, 2010, 31(11): 1348-1358. |
| [16] | KORNBLUM J.Identifying Almost Identical Files Using Context Triggered Piecewise Hashing[J]. Digital Investigation the International Journal of Digital Forensics & Incident Response, 2006, 3(3): 91-97. |
| [17] | 史记,曾昭龙,杨从保,等. Fuzzing测试技术综述[J]. 信息网络安全,2014(3):87-91. |
| [1] | 赵志岩, 纪小默. 智能化网络安全威胁感知融合模型研究[J]. 信息网络安全, 2020, 20(4): 87-93. |
| [2] | 刘敏, 陈曙晖. 基于关联融合的VoLTE流量分析研究[J]. 信息网络安全, 2020, 20(4): 81-86. |
| [3] | 边玲玉, 张琳琳, 赵楷, 石飞. 基于LightGBM的以太坊恶意账户检测方法[J]. 信息网络安全, 2020, 20(4): 73-80. |
| [4] | 杜义峰, 郭渊博. 一种基于信任值的雾计算动态访问控制方法[J]. 信息网络安全, 2020, 20(4): 65-72. |
| [5] | 傅智宙, 王利明, 唐鼎, 张曙光. 基于同态加密的HBase二级密文索引方法研究[J]. 信息网络安全, 2020, 20(4): 55-64. |
| [6] | 王蓉, 马春光, 武朋. 基于联邦学习和卷积神经网络的入侵检测方法[J]. 信息网络安全, 2020, 20(4): 47-54. |
| [7] | 董晓丽, 商帅, 陈杰. 分组密码9轮Rijndael-192的不可能差分攻击[J]. 信息网络安全, 2020, 20(4): 40-46. |
| [8] | 郭春, 陈长青, 申国伟, 蒋朝惠. 一种基于可视化的勒索软件分类方法[J]. 信息网络安全, 2020, 20(4): 31-39. |
| [9] | 陈璐, 孙亚杰, 张立强, 陈云. 物联网环境下基于DICE的设备度量方案[J]. 信息网络安全, 2020, 20(4): 21-30. |
| [10] | 江金芳, 韩光洁. 无线传感器网络中信任管理机制研究综述[J]. 信息网络安全, 2020, 20(4): 12-20. |
| [11] | 刘建伟, 韩祎然, 刘斌, 余北缘. 5G网络切片安全模型研究[J]. 信息网络安全, 2020, 20(4): 1-11. |
| [12] | 刘鹏, 何倩, 刘汪洋, 程序. 支持撤销属性和外包解密的CP-ABE方案[J]. 信息网络安全, 2020, 20(3): 90-97. |
| [13] | 宋宇波, 樊明, 杨俊杰, 胡爱群. 一种基于拓扑分析的网络攻击流量分流和阻断方法[J]. 信息网络安全, 2020, 20(3): 9-17. |
| [14] | 王腾飞, 蔡满春, 芦天亮, 岳婷. 基于iTrace_v6的IPv6网络攻击溯源研究[J]. 信息网络安全, 2020, 20(3): 83-89. |
| [15] | 张艺, 刘红燕, 咸鹤群, 田呈亮. 基于授权记录的云存储加密数据去重方法[J]. 信息网络安全, 2020, 20(3): 75-82. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||