Netinfo Security ›› 2026, Vol. 26 ›› Issue (5): 699-712.doi: 10.3969/j.issn.1671-1122.2026.05.003
Previous Articles Next Articles
Anomaly Data Detection Method Based on Quality Dissimilarity
ZHANG Hongtao1,2, ZHANG Xiao1( ), GUO Yi1,3, ZHANG Liancheng1,3, LI Xuqing1
), GUO Yi1,3, ZHANG Liancheng1,3, LI Xuqing1
- 1
School of Cyber Science and Engineering ,Zhengzhou University Zhengzhou 450002, China
2Network Management Center ,Zhengzhou University Zhengzhou 450001, China
3School of Cyberspace Security ,Cyberspace Force Information Engineering University Zhengzhou 450001, China
-
Received:2025-12-02Online:2026-05-10Published:2026-06-03
CLC Number:
Cite this article
ZHANG Hongtao, ZHANG Xiao, GUO Yi, ZHANG Liancheng, LI Xuqing. Anomaly Data Detection Method Based on Quality Dissimilarity[J]. Netinfo Security, 2026, 26(5): 699-712.
share this article
Add to citation manager EndNote|Ris|BibTeX
URL: http://netinfo-security.org/EN/10.3969/j.issn.1671-1122.2026.05.003
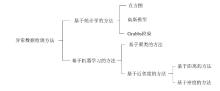
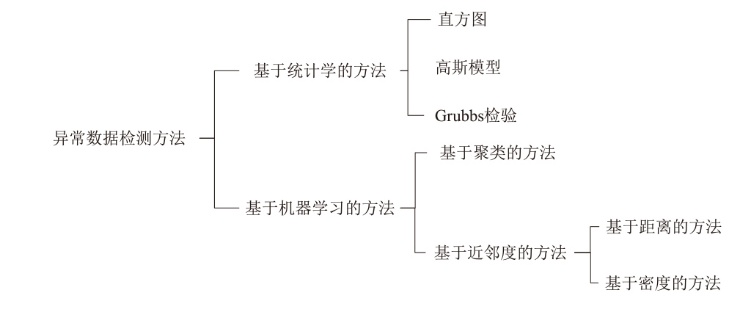
| 方法分类 | 典型方法 | 优点 | 缺点 | ||
|---|---|---|---|---|---|
| 基于统计学的方法 | 无参数: 直方图 有参数: 高斯模型 | 基于数据分布快速且有效、鲁棒性好 | 需要预先假设数据的分布情况,而且不适用于高维数据 | ||
| 基于机器学习的方法 | 基于聚类的方法 | K-means | 实现简单、聚类效果不错,不需要标签和先验知识 | 异常数据检测结果依赖聚类效果 | |
| 基于近邻度的方法 | 基于距离的方法 | KNN | 无数据分布假设、简单方便计算 | 消耗时间长 | |
| 基于密度的方法 | DBSCAN、MBSCAN、DPC、LOF、CFSFDP | 可以根据异常程度给一个定量的值,具有良好的鲁棒性 | 高维数据 计算量大 | ||
| 序号 | 数据集 | 特征数量/个 | 总样本量/条 | 异常样本量/条 |
|---|---|---|---|---|
| DataSet1 | Breast_cancer | 30 | 369 | 12 |
| DataSet2 | Ionosphere | 34 | 251 | 26 |
| DataSet3 | Mushroom | 22 | 897 | 39 |
| DataSet4 | Heart | 13 | 537 | 11 |
| DataSet5 | Abalone | 8 | 4177 | 79 |
| DataSet6 | Chess | 36 | 1685 | 16 |
| DataSet7 | Spambase | 57 | 2788 | 56 |
| 序号 | n_estimators/个 | max_samples/条 | Accuracy | Recall | F1_Score |
|---|---|---|---|---|---|
| 1 | 50 | 64 | 0.9675 | 0.9449 | 0.9567 |
| 2 | 50 | 128 | 0.9658 | 0.9477 | 0.9583 |
| 3 | 50 | 256 | 0.9595 | 0.9531 | 0.9673 |
| 4 | 100 | 64 | 0.9650 | 0.9457 | 0.9576 |
| 5 | 100 | 128 | 0.9706 | 0.9456 | 0.9682 |
| 6 | 100 | 256 | 0.9671 | 0.9457 | 0.9680 |
| 7 | 200 | 64 | 0.9721 | 0.9248 | 0.9588 |
| 8 | 200 | 128 | 0.9677 | 0.9462 | 0.9562 |
| 9 | 200 | 256 | 0.9687 | 0.9661 | 0.9660 |
| 10 | 400 | 64 | 0.9593 | 0.9482 | 0.9580 |
| 11 | 400 | 128 | 0.9681 | 0.9377 | 0.9677 |
| 12 | 400 | 256 | 0.9688 | 0.9563 | 0.9578 |
| 序号 | 异常样本占比 | Accuracy | Recall | F1_Score |
|---|---|---|---|---|
| 1 | 1% | 0.9661 | 0.9451 | 0.9682 |
| 2 | 2% | 0.9683 | 0.9389 | 0.9548 |
| 3 | 5% | 0.9666 | 0.9437 | 0.9677 |
| 4 | 8% | 0.9687 | 0.9450 | 0.9561 |
| 5 | 10% | 0.9658 | 0.9392 | 0.9671 |
| 序号 | Accuracy | Recall | F1_Score |
|---|---|---|---|
| 1 | 0.9851 | 0.9489 | 0.9765 |
| 2 | 0.9899 | 0.9636 | 0.9569 |
| 3 | 0.9770 | 0.9434 | 0.9657 |
| 4 | 0.9716 | 0.9463 | 0.9812 |
| 5 | 0.9751 | 0.9461 | 0.9711 |
| 6 | 0.9708 | 0.9598 | 0.9646 |
| 7 | 0.9706 | 0.9364 | 0.9412 |
| 8 | 0.9740 | 0.9535 | 0.9593 |
| 9 | 0.9902 | 0.9304 | 0.9672 |
| 10 | 0.9656 | 0.9602 | 0.9814 |
| 样本均值 | 0.9770 | 0.9489 | 0.9665 |
| 样本方差 | 0.000066 | 0.000114 | 0.000150 |
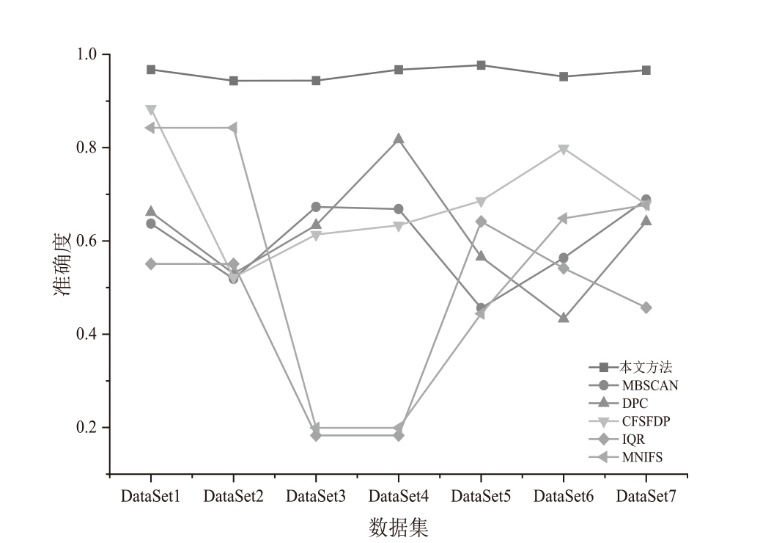

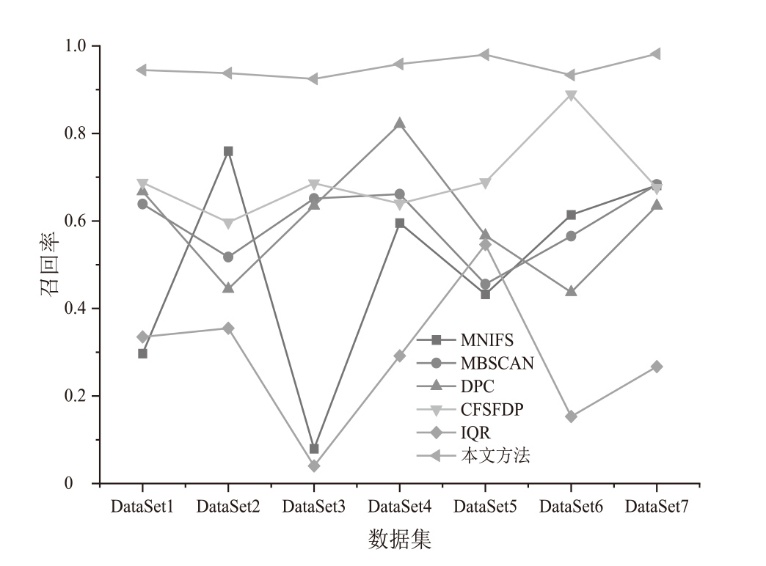
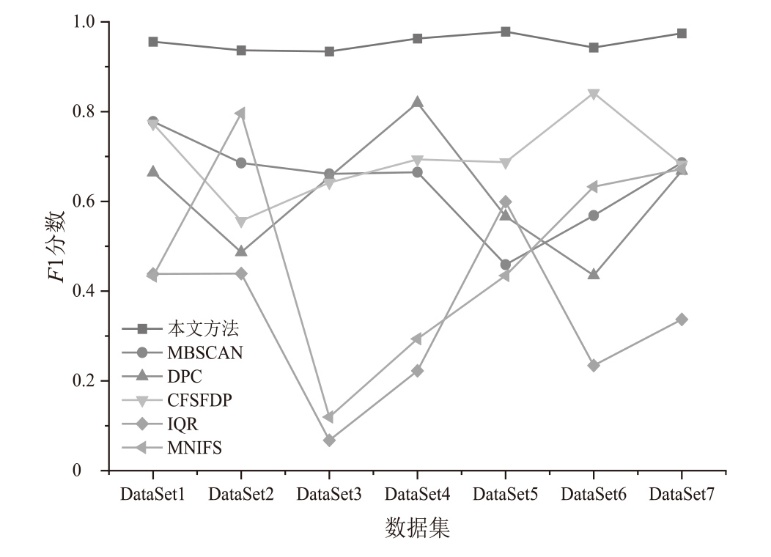
| [1] | SHAIKH F A, JOSEPH D, KANG E. Reassessing Information Security Perceptions Following a Data Breach Announcement: The Role of Post-Breach Management in Firm-Specific Risk[EB/OL]. (2025-11-05)[2025-11-28]. https://doi.org/10.1016/j.cose.2025.104752. |
| [2] | HASAN M K, HABIB A A, SHUKUR Z, et al. Review on Cyber-Physical and Cyber-Security System in Smart Grid: Standards, Protocols, Constraints, and Recommendations[EB/OL]. (2022-11-05)[2025-11-28]. https://doi.org/10.1016/j.jnca.2022.103540. |
| [3] | ZHANG Hao, XIE Dazhi, HU Yunsheng, et al. A Review of Network Anomaly Detection Based on Semi-Supervised Learning[J]. Netinfo Security, 2024, 24(4): 491-508. |
| 张浩, 谢大智, 胡云晟, 等. 基于半监督学习的网络异常检测研究综述[J]. 信息网络安全, 2024, 24(4): 491-508. | |
| [4] | WANG Yudi, LIU Xiaojie, WANG Yunpeng. Research on Anomaly Detection Method Based on Improved Negative Selection Algorithm[J]. Netinfo Security, 2020, 20(10): 75-82. |
| 王玉娣, 刘晓洁, 王运鹏. 基于改进否定选择算法的异常检测方法研究[J]. 信息网络安全, 2020, 20(10): 75-82. | |
| [5] | GU Zhaojun, LIU Tingting, GAO Bing, et al. Anomaly Detection of Imbalanced Data in Industrial Control System Based on GAN-Cross[J]. Netinfo Security, 2022, 22(8): 81-89. |
| 顾兆军, 刘婷婷, 高冰, 等. 基于GAN-Cross的工控系统类不平衡数据异常检测[J]. 信息网络安全, 2022, 22(8): 81-89. | |
| [6] | TONG Tiejun, LIN Hongmei, GANG Bowen, et al. ChauBoxplot and AdaptiveBoxplot: Two R Packages for Boxplot-Based Outlier Detection[EB/OL]. [2025-11-28]. https://arxiv.org/abs/2601.13759. |
| [7] |
KAVITHA S S, KAULGUD N. Quantum Machine Learning for Support Vector Machine Classification[J]. Evolutionary Intelligence, 2024, 17(2): 819-828.
doi: 10.1007/s12065-022-00756-5 |
| [8] |
WANG A X, CHUKOVA S S, NGUYEN B P. Ensemble K-Nearest Neighbors Based on Centroid Displacement[J]. Information Sciences, 2023, 629: 313-323.
doi: 10.1016/j.ins.2023.02.004 URL |
| [9] |
COSTA V G, PEDREIRA C E. Recent Advances in Decision Trees: An Updated Survey[J]. Artificial Intelligence Review, 2023, 56(5): 4765-4800.
doi: 10.1007/s10462-022-10275-5 |
| [10] |
BARANWAL M, SALAPAKA S. Clustering and Supervisory Voltage Control in Power Systems[J]. International Journal of Electrical Power & Energy Systems, 2019, 109: 641-651.
doi: 10.1016/j.ijepes.2019.02.025 URL |
| [11] |
POTHULA K R, SMYRNOVA D, SCHRÖDER G F. Clustering Cryo-EM Images of Helical Protein Polymers for Helical Reconstructions[J]. Ultramicroscopy, 2019, 203: 132-138.
doi: S0304-3991(18)30316-4 pmid: 30591222 |
| [12] |
LLOBELL F, VIGNEAU E, QANNARI E M. Clustering Datasets by Means of CLUSTATIS with Identification of Atypical Datasets. Application to Sensometrics[J]. Food Quality and Preference, 2019, 75: 97-104.
doi: 10.1016/j.foodqual.2019.02.017 URL |
| [13] |
WANG Changdong, LAI Jianhuang, ZHU Junyong. Graph-Based Multiprototype Competitive Learning and Its Applications[J]. IEEE Transactions on Systems, Man, and Cybernetics, Part C (Applications and Reviews), 2012, 42(6): 934-946.
doi: 10.1109/TSMCC.2011.2174633 URL |
| [14] |
DENG Tingquan, YE Dongsheng, MA Rong, et al. Low-Rank Local Tangent Space Embedding for Subspace Clustering[J]. Information Sciences, 2020, 508: 1-21.
doi: 10.1016/j.ins.2019.08.060 URL |
| [15] |
YAN Xiaoqiang, YE Yangdong, QIU Xueying, et al. Synergetic Information Bottleneck for Joint Multi-View and Ensemble Clustering[J]. Information Fusion, 2020, 56: 15-27.
doi: 10.1016/j.inffus.2019.10.006 URL |
| [16] |
ISMKHAN H. I-k-Means-+: An Iterative Clustering Algorithm Based on an Enhanced Version of the K-Means[J]. Pattern Recognition, 2018, 79: 402-413.
doi: 10.1016/j.patcog.2018.02.015 URL |
| [17] |
ALI KHAN M, IQBAL N, JAMIL H, et al. Enhanced Abnormal Data Detection Hybrid Strategy Based on Heuristic and Stochastic Approaches for Efficient Patients Rehabilitation[J]. Future Generation Computer Systems, 2024, 154: 101-122.
doi: 10.1016/j.future.2023.11.036 URL |
| [18] |
ALI AL-JUMAILI A H, MUNIYANDI R C, HASAN M K, et al. Parallel Power Load Abnormalities Detection Using Fast Density Peak Clustering with a Hybrid Canopy-K-Means Algorithm[J]. Intelligent Data Analysis, 2024, 28(5): 1321-1346.
doi: 10.3233/IDA-230573 URL |
| [19] | LYU Zhuo, DI Li, CHEN Cen, et al. A Fast Density Peak Clustering Method for Power Data Security Detection Based on Local Outlier Factors[EB/OL]. (2023-07-07)[2025-11-28]. https://www.mdpi.com/2227-9717/11/7/2036. |
| [20] |
HOU Jian, GAO Huijun, LI Xuelong. DSets-DBSCAN: A Parameter-Free Clustering Algorithm[J]. IEEE Transactions on Image Processing, 2016, 25(7): 3182-3193.
doi: 10.1109/TIP.2016.2559803 pmid: 28113183 |
| [21] |
BRYANT A, CIOS K. RNN-DBSCAN: A Density-Based Clustering Algorithm Using Reverse Nearest Neighbor Density Estimates[J]. IEEE Transactions on Knowledge and Data Engineering, 2018, 30(6): 1109-1121.
doi: 10.1109/TKDE.2017.2787640 URL |
| [22] | TING Kaiming, ZHU Ye, CARMAN M, et al. Overcoming Key Weaknesses of Distance-Based Neighbourhood Methods Using a Data Dependent Dissimilarity Measure[C]//ACM. The 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2016: 1205-1214. |
| [23] |
RODRIGUEZ A, LAIO A. Clustering by Fast Search and Find of Density Peaks[J]. Science, 2014, 344(6191): 1492-1496.
doi: 10.1126/science.1242072 URL |
| [24] |
LIU Yaohui, MA Zhengming, YU Fang. Adaptive Density Peak Clustering Based on K-Nearest Neighbors with Aggregating Strategy[J]. Knowledge-Based Systems, 2017, 133: 208-220.
doi: 10.1016/j.knosys.2017.07.010 URL |
| [25] |
WANG Guangtao, SONG Qinbao. Automatic Clustering via Outward Statistical Testing on Density Metrics[J]. IEEE Transactions on Knowledge and Data Engineering, 2016, 28(8): 1971-1985.
doi: 10.1109/TKDE.2016.2535209 URL |
| [26] |
MEHMOOD R, ZHANG Guangzhi, BIE Rongfang, et al. Clustering by Fast Search and Find of Density Peaks via Heat Diffusion[J]. Neurocomputing, 2016, 208: 210-217.
doi: 10.1016/j.neucom.2016.01.102 URL |
| [27] |
LIU Ruhui, HUANG Weiping, FEI Zhengshun, et al. Constraint-Based Clustering by Fast Search and Find of Density Peaks[J]. Neurocomputing, 2019, 330: 223-237.
doi: 10.1016/j.neucom.2018.06.058 |
| [28] |
SEYEDI S A, LOTFI A, MORADI P, et al. Dynamic Graph-Based Label Propagation for Density Peaks Clustering[J]. Expert Systems with Applications, 2019, 115: 314-328.
doi: 10.1016/j.eswa.2018.07.075 |
| [29] |
XIE Juanying, GAO Hongchao, XIE Weixin, et al. Robust Clustering by Detecting Density Peaks and Assigning Points Based on Fuzzy Weighted K-Nearest Neighbors[J]. Information Sciences, 2016, 354: 19-40.
doi: 10.1016/j.ins.2016.03.011 URL |
| [30] |
LIU Rui, WANG Hong, YU Xiaomei. Shared-Nearest-Neighbor-Based Clustering by Fast Search and Find of Density Peaks[J]. Information Sciences, 2018, 450: 200-226.
doi: 10.1016/j.ins.2018.03.031 URL |
| [31] |
DU Mingjing, DING Shifei, JIA Hongjie. Study on Density Peaks Clustering Based on K-Nearest Neighbors and Principal Component Analysis[J]. Knowledge-Based Systems, 2016, 99: 135-145.
doi: 10.1016/j.knosys.2016.02.001 URL |
| [32] |
CHEN Yewang, TANG Shengyu, BOUGUILA N, et al. A Fast Clustering Algorithm Based on Pruning Unnecessary Distance Computations in DBSCAN for High-Dimensional Data[J]. Pattern Recognition, 2018, 83: 375-387.
doi: 10.1016/j.patcog.2018.05.030 URL |
| [33] | YANG Siyu, YUAN Zhong, LUO Chuan, et al. Fuzzy Multi-Neighborhood Entropy-Based Interactive Feature Selection for Unsupervised Outlier Detection[EB/OL]. (2024-12-09)[2025-11-28]. https://doi.org/10.1016/j.asoc.2024.112572. |
| [34] |
MAHARANA K, MONDAL S, NEMADE B. A Review: Data Pre-Processing and Data Augmentation Techniques[J]. Global Transitions Proceedings, 2022, 3(1): 91-99.
doi: 10.1016/j.gltp.2022.04.020 URL |
| [35] | SHI Xi, PRINS C, VAN POTTELBERGH G, et al. An Automated Data Cleaning Method for Electronic Health Records by Incorporating Clinical Knowledge[EB/OL]. [2025-11-28]. https://link.springer.com/article/10.1186/s12911-021-01630-7. |
| [36] | JIA Weikuan, SUN Meili, LIAN Jian, et al. Feature Dimensionality Reduction: A Review[J]. Complex & Intelligent Systems, 2022, 8(3): 2663-2693. |
| [37] |
BONETTI P, METELLI A M, RESTELLI M. Interpretable Linear Dimensionality Reduction Based on Bias-Variance Analysis[J]. Data Mining and Knowledge Discovery, 2024, 38(4): 1713-1781.
doi: 10.1007/s10618-024-01015-0 |
| [38] | XU Yichen, LI E. Robust Locally Nonlinear Embedding (RLNE) for Dimensionality Reduction of High-Dimensional Data with Noise[EB/OL]. (2024-05-25)[2025-11-28]. https://doi.org/10.1016/j.neucom.2024.127900. |
| [39] | JAIN M, SAIHJPAL V, SINGH N, et al. An Overview of Variants and Advancements of PSO Algorithm[EB/OL]. (2022-08-23)[2025-11-28]. https://www.mdpi.com/2076-3417/12/17/8392. |
| [40] | DAVIRAN M, MAGHSOUDI A, GHEZELBASH R. Optimized AI-MPM: Application of PSO for Tuning the Hyperparameters of SVM and RF Algorithms[EB/OL]. (2024-11-20)[2025-11-28]. https://doi.org/10.1016/j.cageo.2024.105785. |
| [41] |
XIA Zhixin, HE Siyuan, LIU Changwei, et al. PSO-GA Hyperparameter Optimized ResNet-BiGRU-Based Intrusion Detection Method[J]. IEEE Access, 2024, 12: 135535-135550.
doi: 10.1109/ACCESS.2024.3464529 URL |
| [42] | ZHANG Wei, ZHANG Gongxuan, CHEN Xiaohui, et al. DHC: A Distributed Hierarchical Clustering Algorithm for Large Datasets[EB/OL]. [2025-11-28]. https://doi.org/10.1142/S0218126619500658. |
| [43] |
LI Teng, REZAEIPANAH A, TAG EL DIN E M. An Ensemble Agglomerative Hierarchical Clustering Algorithm Based on Clusters Clustering Technique and the Novel Similarity Measurement[J]. Journal of King Saud University-Computer and Information Sciences, 2022, 34(6): 3828-3842.
doi: 10.1016/j.jksuci.2022.04.010 URL |
| [1] | FENG Wei, XIAO Wenming, TIAN Zheng, LIANG Zhongjun, JIANG Bin. Research on Semantic Intelligent Recognition Algorithms for Meteorological Data Based on Large Language Models [J]. Netinfo Security, 2025, 25(7): 1163-1171. |
| [2] | PANG Shuchao, LI Zhengxiao, QU Junyi, MA Ruhao, CHEN Hechang, DU Anan. Detecting Poisoned Samples for Untargeted Backdoor Attacks [J]. Netinfo Security, 2025, 25(12): 1878-1888. |
| [3] | LI Zhihua, CHEN Liang, LU Xulin, FANG Zhaohui, QIAN Junhao. Lightweight Detection Method for IoT Mirai Botnet [J]. Netinfo Security, 2024, 24(5): 667-681. |
| [4] | XU Zirong, GUO Yanping, YAN Qiao. Malicious Software Adversarial Defense Model Based on Feature Severity Ranking [J]. Netinfo Security, 2024, 24(4): 640-649. |
| [5] | ZHONG Jing, FANG Bing, ZHU Jiang. Recent Research of Feature Selection Algorithms Based on Sparse Matrix Structure [J]. Netinfo Security, 2024, 24(3): 352-362. |
| [6] | WANG Yaxin, ZHANG Jian. Fingerprint Feature Extraction of Electronic Medical Records Based on Few-Shot Named Entity Recognition Technology [J]. Netinfo Security, 2024, 24(10): 1537-1543. |
| [7] | MA Min, FU Yu, HUANG Kai. A Principal Component Analysis Scheme for Security Outsourcing in Cloud Environment Based on Secret Sharing [J]. Netinfo Security, 2023, 23(4): 61-71. |
| [8] | XU Shengwei, DENG Ye, LIU Changhe, TAN Li. A Selective Encryption Scheme for Audio and Video Based on the National Cryptographic Algorithm [J]. Netinfo Security, 2023, 23(11): 48-57. |
| [9] | LIU Xiangyu, LU Tianliang, DU Yanhui, WANG Jingxiang. Lightweight IoT Intrusion Detection Method Based on Feature Selection [J]. Netinfo Security, 2023, 23(1): 66-72. |
| [10] | YU Chengli, ZHANG Yang, JIA Shijie. Research on Data Security Threats and Protection of Key Technologies in Cloud Environment [J]. Netinfo Security, 2022, 22(7): 55-63. |
| [11] | JIN Bo, TANG Qianjin, TANG Qianlin. Interpretation of the Top 10 Development Trends of Network Security in 2022 by CCF Computer Security Professional Committee [J]. Netinfo Security, 2022, 22(4): 1-6. |
| [12] | XIAO Xiaolei, ZHAO Xuelian. Overview of the Research on Governance of Cross-Border Data Flow in China [J]. Netinfo Security, 2022, 22(10): 45-51. |
| [13] | YANG Xiaoqi, BAI Lifang, TANG Gang. Research and Design of Data Security Evaluation Model Based on DSMM Model [J]. Netinfo Security, 2021, 21(9): 90-95. |
| [14] | XU Guotian*, SHEN Yaotong. Multiple Classification Detection Method for Malware Based on XGBoost and Stacking Fusion Model [J]. Netinfo Security, 2021, 21(6): 52-62. |
| [15] | ZHU Yanhua, LIAO Fangyu, HU Lianglin, WANG Zhiqiang. Research on Key Problems of Scientific Data Security Standard [J]. Netinfo Security, 2021, 21(11): 1-8. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||