信息网络安全 ›› 2020, Vol. 20 ›› Issue (10): 34-40.doi: 10.3969/j.issn.1671-1122.2020.10.005
基于距离与误差平方和的差分隐私K-means聚类算法
黄保华( ), 程琪, 袁鸿, 黄丕荣
), 程琪, 袁鸿, 黄丕荣
- 广西大学计算机与电子信息学院,南宁 530004
-
收稿日期:2020-05-12出版日期:2020-10-10发布日期:2020-11-25 -
通讯作者:黄保华 E-mail:bhhuang66@gxu.edu.cn -
作者简介:黄保华(1973—),男,贵州,副教授,博士,主要研究方向为信息安全|程琪(1994—),男,广西,硕士研究生,主要研究方向为信息安全|袁鸿(1995—),男,湖南,硕士研究生,主要研究方向为信息安全|黄丕荣(1994—),男,广西,硕士研究生,主要研究方向为信息安全 -
基金资助:国家自然科学基金(61962005)
K-means Clustering Algorithm Based on Differential Privacy with Distance and Sum of Square Error
HUANG Baohua(), CHENG Qi, YUAN Hong, HUANG Pirong
- School of Computer, Electronics and Information, Guangxi University, Nanning 530004, China
-
Received:2020-05-12Online:2020-10-10Published:2020-11-25 -
Contact:HUANG Baohua E-mail:bhhuang66@gxu.edu.cn
摘要:
K-means算法具有简单、快速、易于实现等优点,被广泛应用于数据挖掘领域,但在聚类过程中容易造成隐私泄露。差分隐私对隐私保护做了严格定义,且能够对隐私保护量化分析。为解决差分隐私保护中K-means聚类算法在初始中心点选择上具有盲目性而造成聚类可用性低的问题,文章提出一种BDPK-means聚类算法,该算法利用距离与簇内误差平方和的方法选取合理的初始中心点进行聚类。理论分析证明,该算法满足ε-差分隐私。实验证明,相同条件下与现有DPK-means算法相比,BDPK-means算法可提高聚类的可用性。
中图分类号:
引用本文
黄保华, 程琪, 袁鸿, 黄丕荣. 基于距离与误差平方和的差分隐私K-means聚类算法[J]. 信息网络安全, 2020, 20(10): 34-40.
HUANG Baohua, CHENG Qi, YUAN Hong, HUANG Pirong. K-means Clustering Algorithm Based on Differential Privacy with Distance and Sum of Square Error[J]. Netinfo Security, 2020, 20(10): 34-40.
表1
实验数据信息
| 数据集 | 属性类型 | 数据属性数 | 数据样本数 | 数据别名 |
|---|---|---|---|---|
| Banknote Authentication | real | 5 | 1372 | D1 |
| GAGIC Gamma Telescope | real | 11 | 19020 | D2 |
| Wine | real | 13 | 178 | D3 |
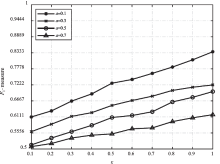
图1
不同a值在D1上的运行结果

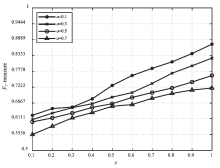
图2
不同a值在D2上的运行结果
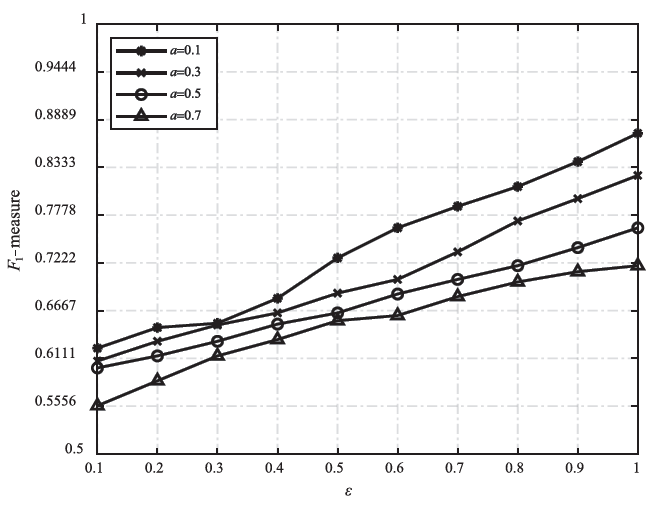

图3
不同a值在D3上的运行结果
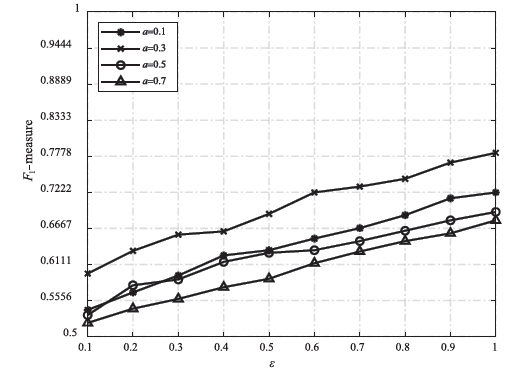

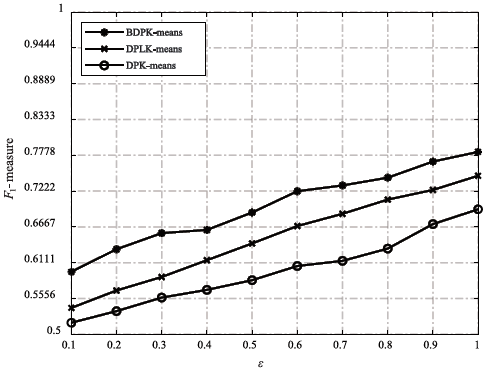
图4
不同算法在D1上的运行结果
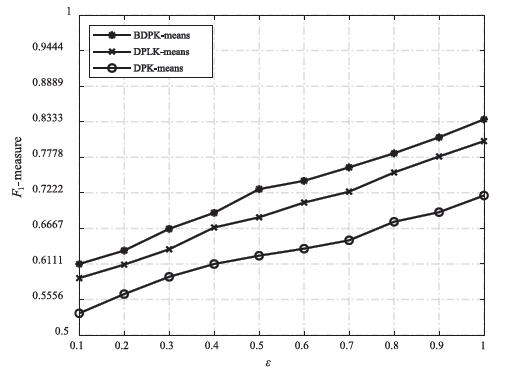

图5
不同算法在D2上的运行结果
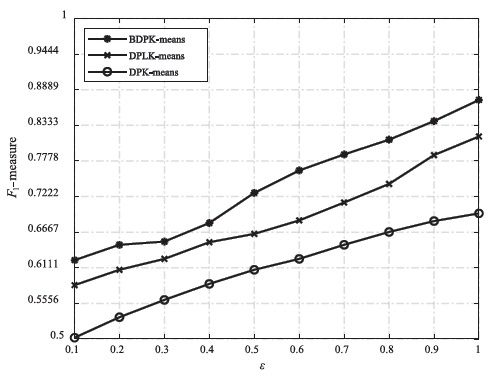

图6
不同算法在D3上的运行结果
| [1] | BLUM A, DWORK C, MCSHERRY F, et al. Practical Privacy: The SulQ Framework [C]//ACM. 24th ACM SIGACT-SIGMOD-SIGART Symposium on Principles of Database Systems, June 13-15, 2005, Baltimore, Maryland, USA. New York: ACM, 2005: 128-138. |
| [2] | DWORK C. A Firm Foundation for Private Data Analysis[J]. Communications of the ACM, 2011,54(1):86-95. |
| [3] | NISSIM K, RASKHODNIKOVA S, SMITH A. Smooth Sensitivity and Sampling in Private Data Analysis [C]//ACM. 39th Annual ACM Symposium on Theory of Computing, June 11-13, 2007 California, San Diego, USA. New York: ACM, 2007: 75-84. |
| [4] | FELDMAN D, FIAT A, KAPLAN H, et al. Private Coresets [C]//ACM. 41st Annual ACM Symposium on Theory of Computing, May 31-June 2, 2009, MD, Bethesda, USA. New York: ACM, 2009: 361-370. |
| [5] | LI Yang, HAO Zhifeng, WEN Wen, et al. Research on Differential Privacy Preserving k-means Clustering[J]. Computer Science, 2013,40(3):287-290. |
| 李杨, 郝志峰, 温雯, 等. 差分隐私保护k-means聚类方法研究[J]. 计算机科学, 2013,40(3):287-290. | |
| [6] | YU Qingying, LUO Yonglong, CHEN Chuanming, et al. Outlier-eliminated k-means Clustering Algorithm Based on Differential Privacy Preservation[J]. Applied Intelligence. 2016,45(4):1179-1191. |
| [7] | XIONG Ping, ZHU Tianqing, WANG Xiaofeng. A Survey on Diffenrential Privacy and Applications[J]. Chinese Journal of Computers, 2014,37(1):101-122. |
| 熊平, 朱天清, 王晓峰. 差分隐私保护及其应用[J]. 计算机学报, 2014,37(1):101-122. | |
| [8] | MOHAN P, THAKURTA A, SHI E, et al. GUPT: Privacy Preserving Data Analysis Made Easy [C]//ACM. 2012 ACM SIGMOD International Conference on Management of Data, May 20-24, 2012, Arizona, Scottsdale, USA. New York: ACM, 2012: 349-360. |
| [9] | REN Jun, XIONG Jinbo, YAO Zhiqiang, et al. DPLK-means: A Novel Differential Privacy K-means Mechanism [C]//IEEE. 2017 IEEE Second International Conference on Data Science in Cyberspace(DSC), June 26-29, 2017, Shenzhen, China. New Jersey: IEEE, 2017: 133-139. |
| [10] | SU Dong, CAO Jianneng, LI Ninghui, et al. Differentially Private k-means Clustering [C]//ACM. 6th ACM Conference on Data and Application Security and Privacy, March 9-11, 2016, Louisiana, New Orleans, USA. Ner York: ACM, 2016: 26-37. |
| [11] | GAO Zhiqiang, SUN Yixiao, CUI Xiaolong, et al. Privacy-preserving Hybrid K-means[J]. International Journal of Data Warehousing and Mining(IJDWM), 2018,14(2):1-17. |
| [12] | ZHANG Yaling, LIU Na, WANG Shangping. A Differential Privacy Protecting K-means Clustering Algorithm Based on Contour Coefficients[EB/OL]. https://www.onacademic.com/detail/journal_1000041661939199_f8d7.html, 2018-11-21. |
| [13] | HU Chuang, YANG Geng, BAI Yunlu. Clustering Algorithm in Differential Privacy Preserving[J]. Computer Science, 2019,46(2):129-135. |
| 胡闯, 杨庚, 白云璐. 面向差分隐私保护的聚类算法[J]. 计算机科学, 2019,46(2):129-135. | |
| [14] | MO Ran, LIU Jianfeng, YU Wentao, et al. A Differential Privacy-based Protecting Data Preprocessing Method for Big Data Mining [C]//IEEE. 2019 18th IEEE International Conference on Trust, Security and Privacy In Computing and Communications, August 5-8, 2019, Rotorua, New Zealand. New Jersey: IEEE, 2019: 693-699. |
| [15] | DWORK C. Differential Privacy [C]//Springer. 33rd International Conference on Automata, Languages and Programming-volume Part II, July 10-14, 2006, Venice, Italy. Heidelberg: Springer, 2006: 1-19. |
| [16] | DWORK C. Differential Privacy: A Survey of Results [C]//Springer. International Conference on Theory and Applications of Models of Computation, April 25-29, 2008, Xi’an, China. Heidelberg: Springer, 2008: 1-19. |
| [17] | DWORK C. The Differential Privacy Frontier [C]//Springer. 6th Theory of Cryptography Conference, March 15-17, 2009, San Francisco, CA, USA. Heidelberg: Springer, 2009: 496-502. |
| [18] | DWORK C. Differential Privacy in New Settings [C]//ACM. 21st Annual ACM-SIAM Symposium on Discrete Algorithms, January 17-19, 2010, Austin, Texas, USA. New York: Society for Industrial and Applied Mathematics, 2010: 174-183. |
| [19] | DALENIUS T. Towards a Methodology for Statistical Disclosure Control[J]. Statistik Tidskrift, 1977,15(2):429-444. |
| [20] | VISWANATH P. Histogranm-based Estimation Techniques in Databases[D]. Madison: University of Wisconsirr-Madison, 1997. |
| [21] | McSherry F D. Privacy Integrated Queries: An Extensible Platform for Privacy-preserving Data Analysis [C]//ACM. 2009 ACM SIGMOD International Conference on Management of data, June 29-July 2, 2009, Providence Rhode Island, USA. New York: Association for Computing Machinery, 2009: 19-30. |
| [1] | 李桥, 龙春, 魏金侠, 赵静. 一种基于LMDR和CNN的混合入侵检测模型[J]. 信息网络安全, 2020, 20(9): 117-121. |
| [2] | 汪金苗, 谢永恒, 王国威, 李易庭. 基于属性基加密的区块链隐私保护与访问控制方法[J]. 信息网络安全, 2020, 20(9): 47-51. |
| [3] | 李宁波, 周昊楠, 车小亮, 杨晓元. 云环境下基于多密钥全同态加密的定向解密协议设计[J]. 信息网络安全, 2020, 20(6): 10-16. |
| [4] | 张佳程, 彭佳, 王雷. 大数据环境下的本地差分隐私图信息收集方法[J]. 信息网络安全, 2020, 20(6): 44-56. |
| [5] | 彭长根, 赵园园, 樊玫玫. 基于最大信息系数的主成分分析差分隐私数据发布算法[J]. 信息网络安全, 2020, 20(2): 37-48. |
| [6] | 何泾沙, 杜晋晖, 朱娜斐. 基于k匿名的准标识符属性个性化实现算法研究[J]. 信息网络安全, 2020, 20(10): 19-26. |
| [7] | 唐春明, 林旭慧. 隐私保护集合交集计算协议[J]. 信息网络安全, 2020, 20(1): 9-15. |
| [8] | 汪金苗, 王国威, 王梅, 朱瑞瑾. 面向雾计算的隐私保护与访问控制方法[J]. 信息网络安全, 2019, 19(9): 41-45. |
| [9] | 郝文江, 林云. 互联网企业社会责任现状与启示研究[J]. 信息网络安全, 2019, 19(9): 130-133. |
| [10] | 周权, 许舒美, 杨宁滨. 一种基于ABGS的智能电网隐私保护方案[J]. 信息网络安全, 2019, 19(7): 25-30. |
| [11] | 李怡霖, 闫峥, 谢皓萌. 车载自组织网络的隐私保护综述[J]. 信息网络安全, 2019, 19(4): 63-72. |
| [12] | 蒋辰, 杨庚, 白云璐, 马君梅. 面向隐私保护的频繁项集挖掘算法[J]. 信息网络安全, 2019, 19(4): 73-81. |
| [13] | 张蕾华, 牛红太, 王仲妮, 刘雪红. 基于大数据的前科人员犯罪预警模型构建研究[J]. 信息网络安全, 2019, 19(4): 82-89. |
| [14] | 傅彦铭, 李振铎. 基于拉普拉斯机制的差分隐私保护k-means++聚类算法研究[J]. 信息网络安全, 2019, 19(2): 43-52. |
| [15] | 赵志岩, 吴剑, 康凯. 一种兼顾业务数据安全的隐私保护世系发布方法[J]. 信息网络安全, 2019, 19(12): 29-37. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||