信息网络安全 ›› 2020, Vol. 20 ›› Issue (10): 19-26.doi: 10.3969/j.issn.1671-1122.2020.10.003
基于k匿名的准标识符属性个性化实现算法研究
何泾沙, 杜晋晖( ), 朱娜斐
), 朱娜斐
- 北京工业大学信息学部,北京 100124
-
收稿日期:2020-07-03出版日期:2020-10-10发布日期:2020-11-25 -
通讯作者:杜晋晖 E-mail:1290344719@qq.com -
作者简介:何泾沙(1961—),男,陕西,教授,博士,主要研究方向为网络安全、测试与分析和云计算|杜晋晖(1994—),男,山西,硕士研究生,主要研究方向为网络安全、隐私保护|朱娜斐(1981—),女,河南,副教授,博士,主要研究方向为网络安全、隐私保护和区块链 -
基金资助:国家自然科学基金(61602456)
Research on k-anonymity Algorithm for Personalized Quasi-identifier Attributes
HE Jingsha, DU Jinhui(), ZHU Nafei
- Faculty of Information Technology, Beijing University of Technology, Beijing 100124, China
-
Received:2020-07-03Online:2020-10-10Published:2020-11-25 -
Contact:DU Jinhui E-mail:1290344719@qq.com
摘要:
k匿名在很大程度上能够解决隐私保护领域中的链路攻击问题,但现有的k匿名模型并不重视个人隐私自治。现有的改进k匿名模型不能满足不同的人对不同类型数据的需求,在进行数据表发布后,整个表仍然只有一个k值,即所有元组都统一泛化,不能反映出用户个性化的隐私要求,产生较大的信息损失。文章在k匿名模型的基础上,结合基于聚类的泛化思想,提出基于k匿名的准标识符属性个性化实现算法(KAUP)。该算法能够有效根据用户的隐私要求,在同一个数据表上呈现不同的k值,从而满足个性化的k匿名。文章使用数据集Adult在运行时间、信息损失和可扩展性方面设计了对比实验。实验表明,在同一个数据表上进行个性化匿名是可行的,且匿名过程中的信息损失较小,利于准标识符属性的个性化匿名研究。
中图分类号:
引用本文
何泾沙, 杜晋晖, 朱娜斐. 基于k匿名的准标识符属性个性化实现算法研究[J]. 信息网络安全, 2020, 20(10): 19-26.
HE Jingsha, DU Jinhui, ZHU Nafei. Research on k-anonymity Algorithm for Personalized Quasi-identifier Attributes[J]. Netinfo Security, 2020, 20(10): 19-26.
使用本文
图1
“Sex”属性泛化树


图2
部分“Country”属性泛化树


图3
“maritalStatus”属性泛化树
表1
数据集属性信息
| 属性名称 | 取值个数 | 泛化树深度 | 属性类型 |
|---|---|---|---|
| Sex | 2 | 2 | AQI |
| Country | 40 | 5 | AQI |
| Education | 16 | 3 | AQI |
| Occupation | 14 | 3 | AQI |
| maritalStatus | 7 | 3 | AQI |

图4
元组数目对运行时间的影响


图5
准标识符数目对运行时间的影响


图6
元组数目对信息损失的影响
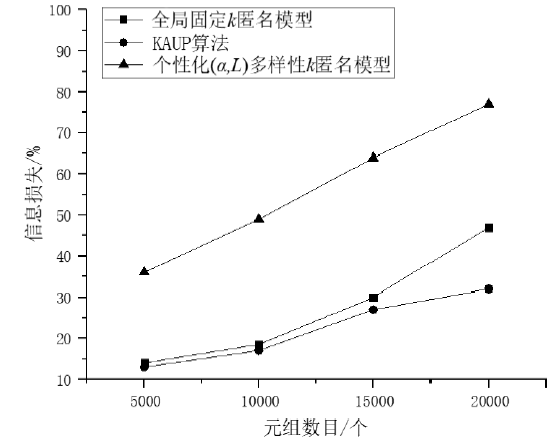
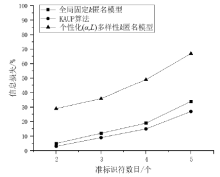
图7
准标识符数目对信息损失的影响

| [1] | LIU Ming, YE Xiaojun. Personalized K-anonymity[J]. Computer Engineering and Design, 2008,29(2):282-286. |
| 刘明, 叶晓俊. 个性化K-匿名模型[J]. 计算机工程与设计, 2008,29(2):282-286. | |
| [2] | YANG Jing, REN Xiangmin, ZHANG Jianpei, et al. Research on Uncertain Data Privacy Protection Based on k-anonymity[J]. International Journal of Advancements in Computing Technology, 2012,4(15):140-149. |
| [3] | NI Sang, XIE Mengbo, QIAN Quan. Clustering-based k-anonymity Algorithm for Privacy Preservation[J]. International Journal of Network Security, 2017,6(19):1062-1071. |
| [4] | FANG Yu, GAO Lei, LIU Zhonghui, et al. Generalized Cost-sensitive Approximate Attribute Reduction Based on Three-way Decisions[J]. Journal of Nanjing University of Science and Technology, 2019,43(4):481-488. |
| 方宇, 高磊, 刘忠慧, 等. 基于三支决策的广义代价敏感属性约简[J]. 南京理工大学学报, 2019,43(4):481-488. | |
| [5] | YE Xiaojun, ZHANG Yawei, LIU Ming. A Personalized (α-k)-anonymity Model [C]// IEEE. The 9th International Conference on Web-Age Information Management, July 20-22, 2008, Zhangjiajie, China. NJ: IEEE, 2008: 341-348. |
| [6] | YIN Yanmin. Research on Privacy Preserving Method of Location Service Trajectory in Fog Computing[J]. Qufu: Qufu Normal University, 2019. |
| 尹彦民. 雾计算中位置服务轨迹隐私保护方法研究[D]. 曲阜:曲阜师范大学, 2019. | |
| [7] | SWEENEY L. k-anonymity: A Model for Protecting Privacy[J]. International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems, 2002,10(5):557-570. |
| [8] | LIU Xiangwen, XIE Qingqing, WANG Liangmin. Personalized Extended (α, k)-anonymity Model for Privacy-preserving Data Publishing[EB/OL]. https://onlinelibrary.wiley.com/doi/epdf/10.1002/cpe.3886, 2016-6-30. |
| [9] | SHEN Yanguang, GUO Gaoshang, WU Di, et al. A Novel Algorithm of Personalized-granular k-anonymity [C]//IEEE. 2013 International Conference on Mechatronic Sciences, Electric Engineering and Computer, December 20-22, 2013, Shenyang, China. NJ: IEEE, 2013: 1860-1866. |
| [10] | LIU Yinghua, YANG Bingru, LI Guangyuan. A Personalized Privacy Preserving Parallel (alpha, k)-anonymity Model[J]. International Journal of Advanced in Computing Technology, 2012,5(4):165-271. |
| [11] | LIAO Jun, JIANG Chaohui, GUO Chun, et al. Classification Anonymity Algorithm Based on Weight Attributes Entropy[J]. Computer Science, 2017,44(7):42-46. |
| 廖军, 蒋朝惠, 郭春, 等. 一种基于权重属性熵分类的匿名算法[J]. 计算机科学, 2017,44(7):42-46. | |
| [12] | REN Xiangmin, YANG Jing, WEI Fengmei. Research on Diversity of Sensitive Attribute of K-anonymity [C]//IEEE. 2010 2nd International Workshop on Database Technology and Application, November 27-28, 2010, Wuhan, China. NJ: IEEE, 2010: 1-4. |
| [13] | YU Shoujian, NIU in, YANG Yun, et al. Personalized Privacy Protection Based on Diversity against Connection Fingerprint Attact [C]//IEEE. 2019 IEEE International Conference on Power, Intelligent Computing and Systems, July 12-14,2019, Shenyang, China. NJ: IEEE, 2019: 205-211. |
| [14] | TRUTA T M, CAMPAN A, MEYER P. Generating Microdata with p-sensitive k-anonymity Property[M] //Springer. Secure Data Management. Heidelberg: Springer, Berlin, Heidelberg, 2007: 124-141. |
| [15] | JIA Junjie, YAN Guolei. A Personalized (p, k)-Anonymity Privacy Protection Algorithm[J]. Computer Engineering, 2018,44(1):176-181. |
| 贾俊杰, 闫国蕾. 一种个性化(p,k)匿名隐私保护算法[J]. 计算机工程, 2018,44(1):176-181. | |
| [16] | ZHAO Yan, WANG Jian, LUO Yongcheng, et al. (α, β, k)-anonymity: An Effective Privacy Preserving Model for Databases [C]//IEEE. 2009 International Conference on Test and Measurement. December 5-6, 2009, Hong Kong, China. NJ: IEEE, 2009: 412-415. |
| [17] | RAO U P, MEHTA B B, KUMAR N. Scalable L-diversity: An Extension to Scalable k-anonymity for Privacy Preserving Big Data Publishing[J]. International Journal of Information Technology and Web Engineering, 2019, 14(2): 27-40. |
| [18] | LIAO Jun. Research on Data Privacy Protection Method Based on Classified Mining[D]. Guiyang: Guizhou University, 2017. |
| [19] | TELL R. Property Testing Lower Bounds Via a Generalization of Randomized Parity Decision Trees[J]. Theory of Computing Systems, 2019,63(15):418-449. |
| [20] | ZENG Kai. Privacy Protection Model Research[D]. Chongqing: Chongqing University, 2012. |
| [21] | YU Juan. Research on Anonymity Model and Algorithm of Privacy Protection in Data Publishing[D]. Jinhua: Zhenjiang Normal University, 2010. |
| 于娟. 数据发布中隐私保护的匿名模型及算法研究[D]. 金华:浙江师范大学,2010. | |
| [22] | ZENG Mengjia, CHENG Zhaolin, HUANG Xu, et al. Spatial Crowdsourcing Quality Control Model Based on K-Anonymity Location Privacy Protection and ELM Spammer Detection[J]. Mobile Information Systems, 2019,4(10):1-10. |
| [23] | SONG Jinling, LIU Guohua, HUANG Liming, et al. k-Anonymous Privacy Protection Model K-Value Optimal Selection Algorithms[J]. Minicomputer System, 2011,32(10):1987-1993. |
| [24] | CAO Minzi, ZHANG Linlin, BI Xuehua, et al. Personalized (alpha, l)- Diversity K-Anonymous Privacy Protection Model[J]. Computer Science, 2018,45(11):180-186. |
| [1] | 汪金苗, 谢永恒, 王国威, 李易庭. 基于属性基加密的区块链隐私保护与访问控制方法[J]. 信息网络安全, 2020, 20(9): 47-51. |
| [2] | 李宁波, 周昊楠, 车小亮, 杨晓元. 云环境下基于多密钥全同态加密的定向解密协议设计[J]. 信息网络安全, 2020, 20(6): 10-16. |
| [3] | 张佳程, 彭佳, 王雷. 大数据环境下的本地差分隐私图信息收集方法[J]. 信息网络安全, 2020, 20(6): 44-56. |
| [4] | 黄保华, 程琪, 袁鸿, 黄丕荣. 基于距离与误差平方和的差分隐私K-means聚类算法[J]. 信息网络安全, 2020, 20(10): 34-40. |
| [5] | 唐春明, 林旭慧. 隐私保护集合交集计算协议[J]. 信息网络安全, 2020, 20(1): 9-15. |
| [6] | 汪金苗, 王国威, 王梅, 朱瑞瑾. 面向雾计算的隐私保护与访问控制方法[J]. 信息网络安全, 2019, 19(9): 41-45. |
| [7] | 郝文江, 林云. 互联网企业社会责任现状与启示研究[J]. 信息网络安全, 2019, 19(9): 130-133. |
| [8] | 周权, 许舒美, 杨宁滨. 一种基于ABGS的智能电网隐私保护方案[J]. 信息网络安全, 2019, 19(7): 25-30. |
| [9] | 李怡霖, 闫峥, 谢皓萌. 车载自组织网络的隐私保护综述[J]. 信息网络安全, 2019, 19(4): 63-72. |
| [10] | 傅彦铭, 李振铎. 基于拉普拉斯机制的差分隐私保护k-means++聚类算法研究[J]. 信息网络安全, 2019, 19(2): 43-52. |
| [11] | 赵志岩, 吴剑, 康凯. 一种兼顾业务数据安全的隐私保护世系发布方法[J]. 信息网络安全, 2019, 19(12): 29-37. |
| [12] | 胡荣磊, 何艳琼, 曾萍, 范晓红. 一种大数据环境下医疗隐私保护方案设计与实现[J]. 信息网络安全, 2018, 18(9): 48-54. |
| [13] | 李佩丽, 徐海霞, 马添军, 穆永恒. 区块链技术在网络互助中的应用及用户隐私保护[J]. 信息网络安全, 2018, 18(9): 60-65. |
| [14] | 马蓉, 陈秀华, 刘慧, 熊金波. 移动群智感知中用户隐私度量与隐私保护研究[J]. 信息网络安全, 2018, 18(8): 64-72. |
| [15] | 赖成喆, 王文娟. 面向车队的安全且具备隐私保护的移动性管理框架[J]. 信息网络安全, 2018, 18(7): 36-46. |
| 阅读次数 | ||||||||||||||||||||||||||||||||||||||||||||||||||
|
全文 143
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||
|
摘要 477
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||