信息网络安全 ›› 2025, Vol. 25 ›› Issue (4): 550-563.doi: 10.3969/j.issn.1671-1122.2025.04.004
基于节点中心性和大模型的漏洞检测数据增强方法
张学旺1( ), 卢荟1, 谢昊飞2
), 卢荟1, 谢昊飞2
- 1.重庆邮电大学软件工程学院,重庆 400065
2.重庆邮电大学自动化学院,重庆 400065
-
收稿日期:2025-02-28出版日期:2025-04-10发布日期:2025-04-25 -
通讯作者:张学旺zhangxw@cqupt.edu.cn -
作者简介:张学旺(1974—),男,湖南,教授,博士,CCF高级会员,主要研究方向为区块链与物联网、数据安全与隐私保护、大数据与智能数据处理|卢荟(2001—),女,浙江,硕士研究生,主要研究方向为互联网软件及安全技术、漏洞检测|谢昊飞(1978—),男,湖南,教授,博士,主要研究方向为网络化控制系统、无线传感网、工业物联网 -
基金资助:国家重点研发计划(2022YFB3204503);重庆市城市管理科研项目(城管科学2023第35号)
A Data Augmentation Method Based on Graph Node Centrality and Large Model for Vulnerability Detection
ZHANG Xuewang1(), LU Hui1, XIE Haofei2
- 1. College of Software Engineering, Chongqing University of Posts and Telecommunications, Chongqing 400065, China
2. College of Automation, Chongqing University of Posts and Telecommunications, Chongqing 400065, China
-
Received:2025-02-28Online:2025-04-10Published:2025-04-25
摘要:
智能系统源代码漏洞是影响其安全的重要因素,基于深度学习的源代码漏洞检测存在因数据集不平衡、规模小、质量低而引发的模型检测能力与泛化能力不足的问题。虽然采样技术和数据增强技术可改善一部分问题,但在真实数据集上效果不佳。为解决这些问题,文章提出基于节点中心性和大模型的漏洞检测数据增强方法DA_GLvul。该方法首先利用代码属性图将源代码抽象为图结构,并借助图节点中心性分析计算代码优先级值,将最大值对应节点的对应代码行作为关键代码语句,以实现在无已知漏洞语句信息的原始数据集的前提下定位关键代码语句。其次定义一个包含全面的变异规则的变异指令模板,填入原始样本与关键代码后输入至不同的大模型中以生成增强后的代码样本,最终使用增强代码样本与原始样本共同训练漏洞检测模型。实验结果表明,该方法生成的数据中有效样本占73.82%,较两个主流的基于图神经网络的漏洞检测模型在各项评估指标上均对原始结果有优化,其中F1值相比无增强方法平均提升168.85%,相比最优基线方法平均提升8.21%。
中图分类号:
引用本文
张学旺, 卢荟, 谢昊飞. 基于节点中心性和大模型的漏洞检测数据增强方法[J]. 信息网络安全, 2025, 25(4): 550-563.
ZHANG Xuewang, LU Hui, XIE Haofei. A Data Augmentation Method Based on Graph Node Centrality and Large Model for Vulnerability Detection[J]. Netinfo Security, 2025, 25(4): 550-563.
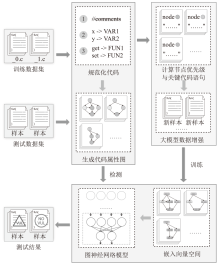
图1
DA_GLvul方法的整体框架
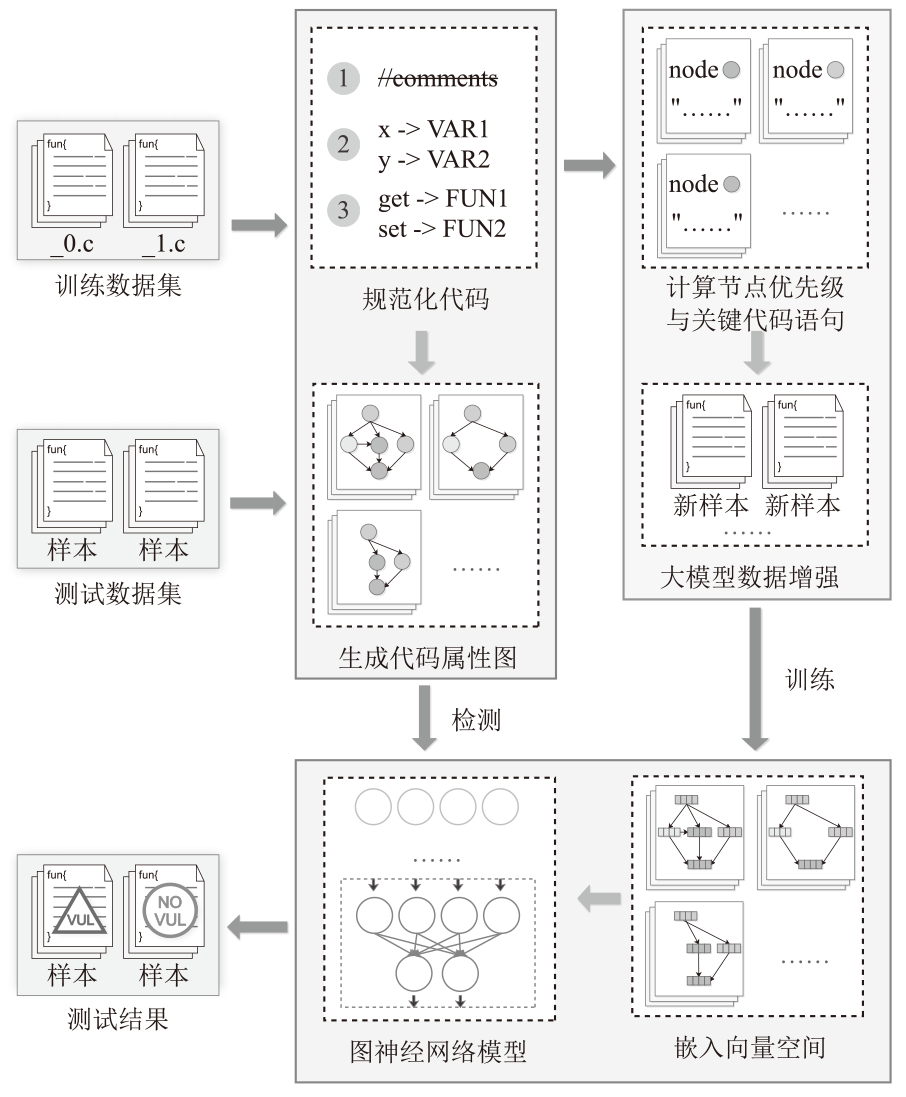
图2
代码规范化过程
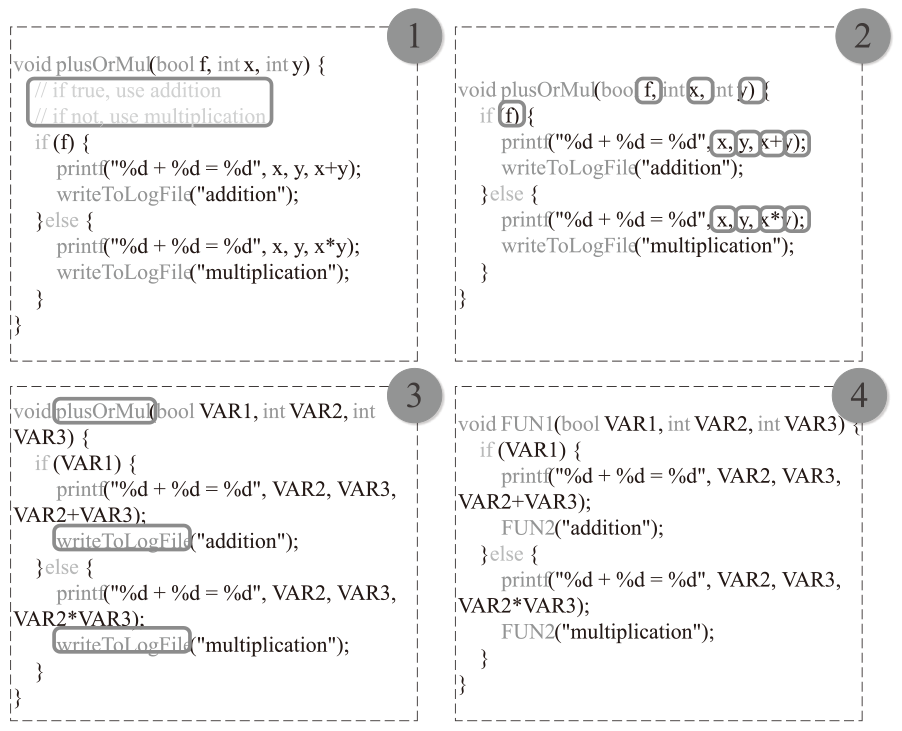
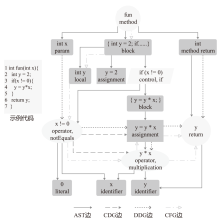
图3
示例代码的CPG


图4
变异指令模板

表1
原始漏洞数据集
| 数据集 | 样本总数/个 | 漏洞样本数/个 | 非漏洞样本数/个 | 比例 |
|---|---|---|---|---|
| Devign | 22792 | 10768 | 12024 | 1:1.1 |
| Reveal | 22734 | 2240 | 20494 | 1:9.1 |
表2
结果值对应符号
| 实际标签 | 预测结果 | |
|---|---|---|
| 1 | 0 | |
| 1 | TP | FN |
| 0 | FP | TN |
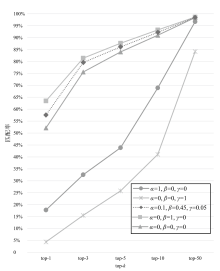
图5
关键代码语句与真实漏洞语句top-k匹配率
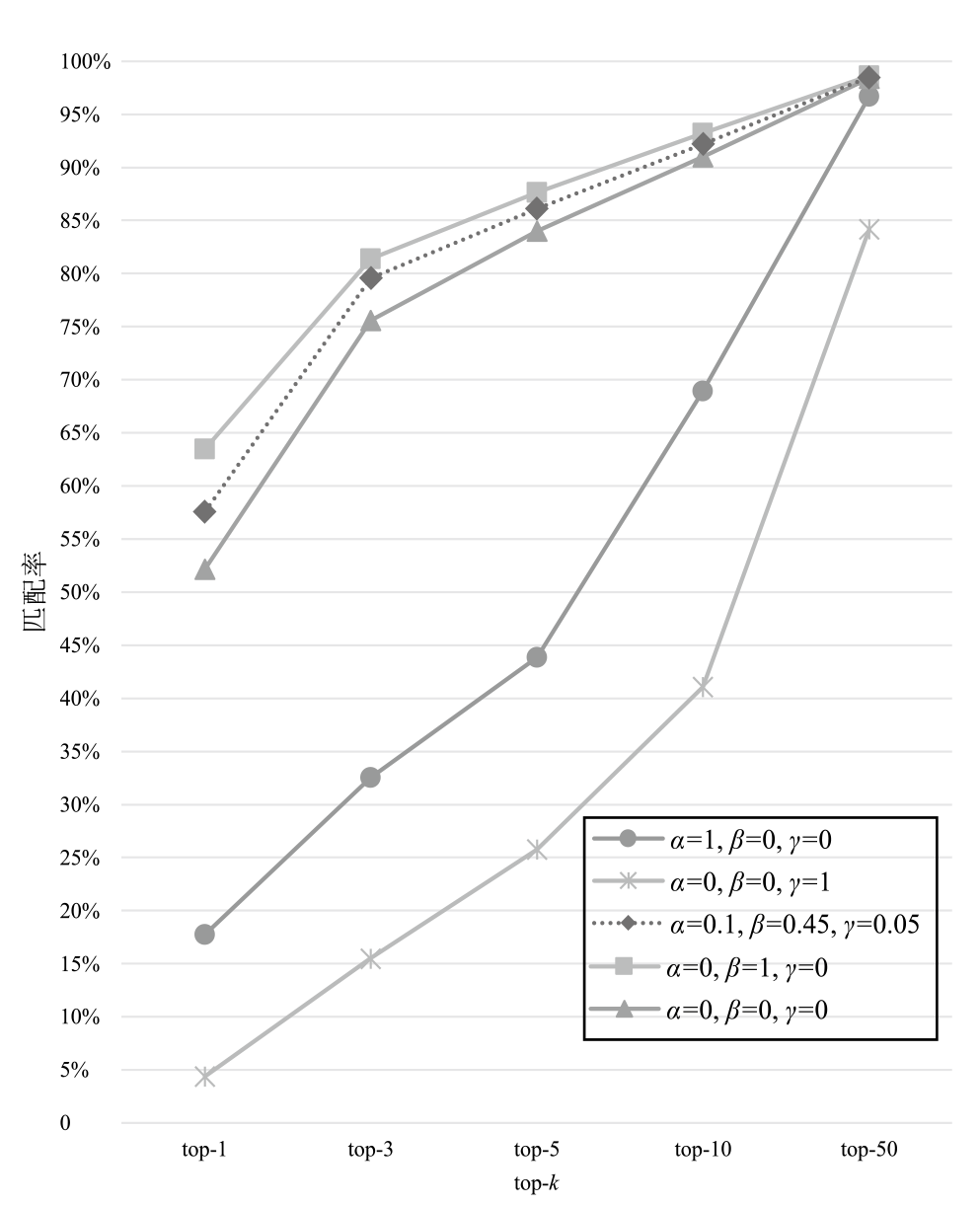

图6
不同大模型生成前后的样本数量
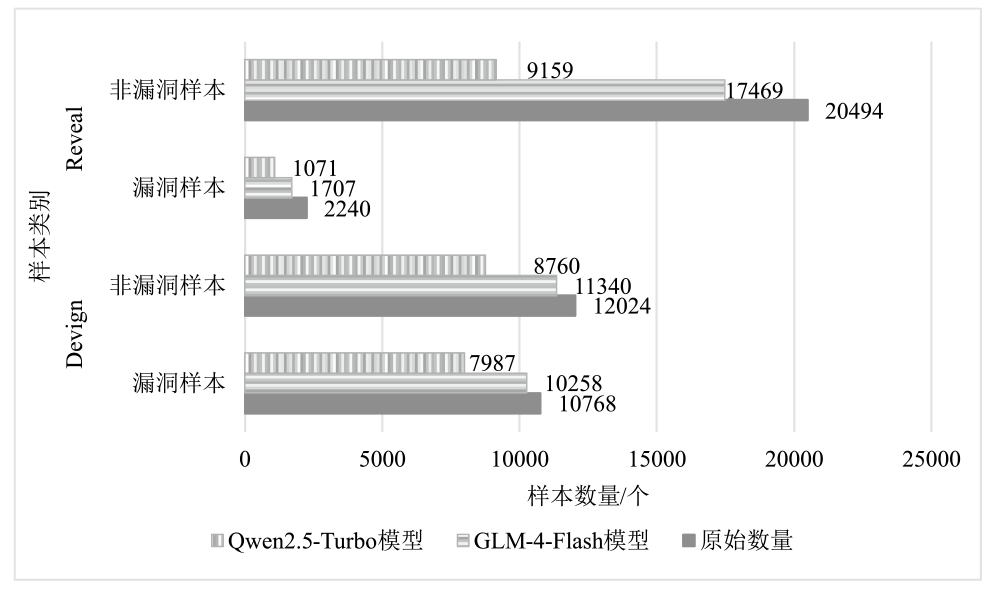
表3
数据集组1实验结果
| 检测 模型 | 增强 方式 | 大模型 | FPR | FNR | A | P | R | F1 |
|---|---|---|---|---|---|---|---|---|
| Devign | — | — | 48.95% | 45.19% | 51.39% | 10.21% | 54.81% | 17.22% |
| OSS | — | 46.92% | 42.49% | 53.09% | 10.31% | 53.11% | 17.27% | |
| SMOTE | — | 48.89% | 43.25% | 51.63% | 10.55% | 56.75% | 17.79% | |
| VGX | VGX | 63.15% | 30.75% | 39.84% | 10.02% | 69.25% | 17.51% | |
| VulScribeR | ChatGPT3.5 | 56.59% | 39.91% | 44.95% | 9.74% | 60.09% | 16.76% | |
| CodeQwen1.5 | 60.15% | 37.73% | 41.92% | 9.51% | 62.27% | 16.51% | ||
| 本文方法 | GLM-4 | 36.45% | 44.19% | 63.84% | 13.46% | 55.81% | 21.69% | |
| Qwen2.5 | 41.55% | 42.14% | 58.40% | 12.39% | 57.86% | 20.41% | ||
| Reveal | — | — | 33.72% | 65.96% | 63.31% | 9.30% | 34.04% | 14.61% |
| VGX | VGX | 58.82% | 43.13% | 42.63% | 8.94% | 56.87% | 15.46% | |
| VulScribeR | ChatGPT3.5 | 54.81% | 51.00% | 45.55% | 8.33% | 49.00% | 14.23% | |
| CodeQwen1.5 | 58.62% | 47.89% | 42.37% | 8.28% | 52.11% | 14.29% | ||
| 本文方法 | GLM-4 | 38.70% | 56.87% | 59.63% | 10.17% | 43.13% | 16.46% | |
| Qwen2.5 | 43.57% | 57.28% | 55.16% | 9.06% | 42.72% | 14.95% |
表4
数据集组2实验结果
| 检测 模型 | 增强 方式 | 大模型 | FPR | FNR | A | P | R | F1 |
|---|---|---|---|---|---|---|---|---|
| Devign | — | — | 2.54% | 97.63% | 52.45% | 52.27% | 3.06% | 5.78% |
| OSS | — | 1.97% | 96.94% | 52.42% | 52.30% | 2.37% | 4.53% | |
| SMOTE | — | 6.36% | 91.76% | 52.92% | 54.14% | 8.24% | 14.30% | |
| VGX | VGX | 27.42% | 72.04% | 51.30% | 48.16% | 27.96% | 35.38% | |
| VulScribeR | ChatGPT3.5 | 26.79% | 73.56% | 50.91% | 47.35% | 26.44% | 33.93% | |
| CodeQwen1.5 | 19.62% | 80.26% | 51.47% | 47.83% | 19.74% | 27.95% | ||
| 本文 方法 | GLM-4 | 34.27% | 62.69% | 52.18% | 49.80% | 37.31% | 42.66% | |
| Qwen2.5 | 18.28% | 80.29% | 52.16% | 49.56% | 19.71% | 28.20% | ||
| Reveal | — | — | 14.35% | 84.57% | 52.17% | 49.48% | 15.43% | 23.53% |
| VGX | VGX | 51.45% | 48.72% | 49.85% | 47.59% | 51.28% | 49.37% | |
| VulScribeR | ChatGPT3.5 | 47.81% | 52.76% | 49.83% | 47.37% | 47.24% | 47.30% | |
| CodeQwen1.5 | 49.10% | 50.50% | 50.23% | 47.88% | 49.50% | 48.67% | ||
| 本文 方法 | GLM-4 | 59.55% | 35.58% | 51.88% | 49.64% | 64.42% | 56.07% | |
| Qwen2.5 | 55.43% | 41.35% | 51.28% | 49.08% | 58.65% | 53.44% |
| [1] | CHEN Yufei, SHEN Chao, WANG Qian, et al. Security and Privacy Risks in Artificial Intelligence Systems[J]. Journal of Computer Research and Development, 2019, 56(10): 2135-2150. |
| 陈宇飞, 沈超, 王骞, 等. 人工智能系统安全与隐私风险[J]. 计算机研究与发展, 2019, 56(10): 2135-2150. | |
| [2] | BLACKDUCK. 2024 Open Source Security and Risk Analysis Report[EB/OL]. (2024-12-05)[2024-12-28]. https://www.blackduck.com/resources/analyst-reports/open-source-security-risk-analysis.html. |
| [3] | Google. Rough-Auditing-Tool-for-Security[EB/OL]. (2014-01-01)[2024-12-28]. https://code.google.com/archive/p/rough-auditing-tool-for-security/. |
| [4] | CHECKMARX. Checkmarx[EB/OL]. (2024-12-12)[2024-12-28]. https://checkmarx.com/. |
| [5] | DWHEELER. Flawfinder[EB/OL]. (2005-03-01)[2024-12-28]. https://dwheeler.com/flawfinder/. |
| [6] | DUAN Xu, WU Jingzheng, LUO Tianyue, et al. Vulnerability Mining Method Based on Code Property Graph and Attention BiLSTM[J]. Journal of Software, 2020, 31(11): 3404-3420. |
| 段旭, 吴敬征, 罗天悦, 等. 基于代码属性图及注意力双向LSTM的漏洞挖掘方法[J]. 软件学报, 2020, 31(11): 3404-3420. | |
| [7] | WU Yueming, ZOU Deqing, DOU Shihan, et al. VulCNN: An Image-Inspired Scalable Vulnerability Detection System[C]// IEEE. 2022 IEEE/ACM 44th International Conference on Software Engineering (ICSE). New York: IEEE, 2022: 2365-2376. |
| [8] | LI Zhen, ZOU Deqing, XU Shouhuai, et al. VulDeePecker: A Deep Learning-Based System for Vulnerability Detection[EB/OL]. (2018-01-05)[2024-12-28]. https://export.arxiv.org/abs/1801.01681. |
| [9] | ZOU Deqing, WANG Sujuan, XU Shouhuai, et al. μVulDeePecker: A Deep Learning-Based System for Multiclass Vulnerability Detection[J]. IEEE Transactions on Dependable and Secure Computing, 2021, 18(5): 2224-2236. |
| [10] | LI Zhen, ZOU Deqing, XU Shouhuai, et al. SySeVR: A Framework for Using Deep Learning to Detect Software Vulnerabilities[J]. IEEE Transactions on Dependable and Secure Computing, 2022, 19(4): 2244-2258. |
| [11] | ZHOU Yaqin, LIU Shangqing, SIOW J K, et al. Devign: Effective Vulnerability Identification by Learning Comprehensive Program Semantics via Graph Neural Networks[EB/OL]. (2019-12-08)[2024-12-28]. https://www.zhangqiaokeyan.com/academic-conference-foreign_meeting-290335_thesis/0705018328210.html. |
| [12] | CHENG Xiao, WANG Haoyu, HUA Jiayi, et al. DeepWukong[J]. ACM Transactions on Software Engineering and Methodology, 2021, 30(3): 1-33. |
| [13] | CHAKRABORTY S, KRISHNA R, DING Yangruibo, et al. Deep Learning Based Vulnerability Detection: Are We There Yet?[J]. IEEE Transactions on Software Engineering, 2022, 48(9): 3280-3296. |
| [14] | SU Xiaohong, ZHENG Weining, JIANG Yuan, et al. Research and Progress on Learning-Based Source Code Vulnerability Detection[J]. Chinese Journal of Computers, 2024, 47(2): 337-374. |
| 苏小红, 郑伟宁, 蒋远, 等. 基于学习的源代码漏洞检测研究与进展[J]. 计算机学报, 2024, 47(2): 337-374. | |
| [15] | YANG Xu, WANG Shaowei, LI Yi, et al. Does Data Sampling Improve Deep Learning-Based Vulnerability Detection?Yeas! and Nays![C]// IEEE. 2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE). New York: IEEE, 2023: 2287-2298. |
| [16] | LU Guilong, JU Xiaolin, CHEN Xiang, et al. GRACE: Empowering LLM-Based Software Vulnerability Detection with Graph Structure and In-Context Learning[EB/OL]. (2024-03-21)[2024-12-28]. https://doi.org/10.1016/j.jss.2024.112031. |
| [17] | ZHANG Chenyuan, LIU Hao, ZENG Jiutian, et al. Prompt-Enhanced Software Vulnerability Detection Using ChatGPT[C]// IEEE. 2024 IEEE/ACM 46th International Conference on Software Engineering:Companion Proceedings (ICSE-Companion). New York: IEEE, 2024: 276-277. |
| [18] | ZHOU Xin, ZHANG Ting, LO D. Large Language Model for Vulnerability Detection: Emerging Results and Future Directions[C]// ACM. Proceedings of the 2024 ACM/IEEE 44th International Conference on Software Engineering:New Ideas and Emerging Results. New York: ACM, 2024: 47-51. |
| [19] | YAMAGUCHI F, GOLDE N, ARP D, et al. Modeling and Discovering Vulnerabilities with Code Property Graphs[C]// IEEE. 2014 IEEE Symposium on Security and Privacy. New York: IEEE, 2014: 590-604. |
| [20] | LI Yun, HUANG Chenlin, WANG Zhongfeng, et al. Survey of Software Vulnerability Mining Methods Based on Machine Learning[J]. Journal of Software, 2020, 31(7): 2040-2061. |
| 李韵, 黄辰林, 王中锋, 等. 基于机器学习的软件漏洞挖掘方法综述[J]. 软件学报, 2020, 31(7): 2040-2061. | |
| [21] | The MITRE Corporation. CVE[EB/OL]. (2024-08-03)[2024-12-28]. https://cve.mitre.org/. |
| [22] | National Institute of Standards and Technology. NVD[EB/OL]. (2024-08-27)[2024-12-28]. https://nvd.nist.gov/. |
| [23] | China Information Technology Security Evaluation Center. China National Vulnerability Database of Information Security[EB/OL]. (2024-12-24)[2024-12-28]. https://www.cnnvd.org.cn. |
| 中国信息安全测评中心. 国家信息安全漏洞库[EB/OL]. (2024-12-24)[2024-12-28]. https://www.cnnvd.org.cn. | |
| [24] | GITHUB. GitHub[EB/OL]. (2024-12-28)[2024-12-28]. https://github.com/. |
| [25] | National Institute of Standards and Technology. NIST Software Assurance Reference Dataset[EB/OL]. (2024-12-28)[2024-12-28]. https://samate.nist.gov/SARD. |
| [26] | KUBÁT M, MATWIN S. Addressing the Curse of Imbalanced Training Sets: One-Sided Selection[EB/OL]. [2024-12-28]. https://www.researchgate.net/publication/2624358_Addressing_the_Curse_of_Imbalanced_Training_Sets_One-Sided_Selection. |
| [27] | CHAWLA N V, BOWYER K W, HALL L O, et al. SMOTE: Synthetic Minority Over-Sampling Technique[J]. Journal of Artificial Intelligence Research, 2002, 16: 321-357. |
| [28] | GANZ T, IMGRUND E, HÄRTERICH M, et al. CodeGraphSMOTE-Data Augmentation for Vulnerability Discovery[C]// Springer. IFIP Annual Conference on Data and Applications Security and Privacy. Heidelberg: Springer, 2023: 282-301. |
| [29] | NONG Yu, OU Yuzhe, PRADEL M, et al. VULGEN: Realistic Vulnerability Generation via Pattern Mining and Deep Learning[C]// IEEE. 2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE). New York: IEEE, 2023: 2527-2539. |
| [30] | NONG Yu, FANG R, YI Guangbei, et al. VGX: Large-Scale Sample Generation for Boosting Learning-Based Software Vulnerability Analyses[C]// ACM. Proceedings of the IEEE/ACM 46th International Conference on Software Engineering. New York: ACM, 2024: 1-13. |
| [31] | DANESHVAR S S, NONG Yu, YANG Xu, et al. Exploring RAG-Based Vulnerability Augmentation with LLMS[EB/OL]. (2024-12-05)[2024-12-28]. https://arxiv.org/abs/2408.04125. |
| [32] | JOERN. Joern[EB/OL]. (2024-12-28)[2024-12-28]. https://joern.io/. |
| [33] | FREEMAN L C. Centrality in Social Networks Conceptual Clarification[J]. Social Networks, 1979, 1(3): 215-239. |
| [34] | BRANDES U. A Faster Algorithm for Betweenness Centrality[J]. The Journal of Mathematical Sociology, 2001, 25(2): 163-177. |
| [35] | KATZ L. A New Status Index Derived from Sociometric Analysis[J]. Psychometrika, 1953, 18(1): 39-43. |
| [36] | YU Shiwen, WANG Ting, WANG Ji. Data Augmentation by Program Transformation[EB/OL]. (2022-03-26)[2024-12-28]. https://doi.org/10.1016/j.jss.2022.111304. |
| [37] | MIKOLOV T, CHEN Kai, CORRADO G, et al. Efficient Estimation of Word Representations in Vector Space[EB/OL]. (2013-09-07)[2024-12-28]. https://arxiv.org/abs/1301.3781v3. |
| [38] | THUDM. GLM-4[EB/OL]. (2024-12-28)[2024-12-28]. https://github.com/THUDM/GLM-4. |
| [39] | QwenLM. Qwen2.5[EB/OL]. (2024-12-24)[2024-12-28]. https://github.com/QwenLM/Qwen2.5. |
| [40] | FAN Jiahao, LI Yi, WANG Shaohua, et al. A C/C++ Code Vulnerability Dataset with Code Changes and CVE Summaries[C]// IEEE. 2020 IEEE/ACM 17th International Conference on Mining Software Repositories (MSR). New York: IEEE, 2020: 508-512. |
| [1] | 顾欢欢, 李千目, 刘臻, 王方圆, 姜宇. 基于虚假演示的隐藏后门提示攻击方法研究[J]. 信息网络安全, 2025, 25(4): 619-629. |
| [2] | 张雨轩, 黄诚, 柳蓉, 冷涛. 结合提示词微调的智能合约漏洞检测方法[J]. 信息网络安全, 2025, 25(4): 664-673. |
| [3] | 解梦飞, 傅建明, 姚人懿. 基于LLM的多媒体原生库模糊测试研究[J]. 信息网络安全, 2025, 25(3): 403-414. |
| [4] | 秦中元, 王田田, 刘伟强, 张群芳. 大语言模型水印技术研究进展[J]. 信息网络安全, 2025, 25(2): 177-193. |
| [5] | 焦诗琴, 张贵杨, 李国旗. 一种聚焦于提示的大语言模型隐私评估和混淆方法[J]. 信息网络安全, 2024, 24(9): 1396-1408. |
| [6] | 陈昊然, 刘宇, 陈平. 基于大语言模型的内生安全异构体生成方法[J]. 信息网络安全, 2024, 24(8): 1231-1240. |
| [7] | 项慧, 薛鋆豪, 郝玲昕. 基于语言特征集成学习的大语言模型生成文本检测[J]. 信息网络安全, 2024, 24(7): 1098-1109. |
| [8] | 郭祥鑫, 林璟锵, 贾世杰, 李光正. 针对大语言模型生成的密码应用代码安全性分析[J]. 信息网络安全, 2024, 24(6): 917-925. |
| [9] | 张长琳, 仝鑫, 佟晖, 杨莹. 面向网络安全领域的大语言模型技术综述[J]. 信息网络安全, 2024, 24(5): 778-793. |
| [10] | 李鹏超, 张全涛, 胡源. 基于双注意力机制图神经网络的智能合约漏洞检测方法[J]. 信息网络安全, 2024, 24(11): 1624-1631. |
| [11] | 秦振凯, 徐铭朝, 蒋萍. 基于提示学习的案件知识图谱构建方法及应用研究[J]. 信息网络安全, 2024, 24(11): 1773-1782. |
| [12] | 李娇, 张玉清, 吴亚飚. 面向网络安全关系抽取的大语言模型数据增强方法[J]. 信息网络安全, 2024, 24(10): 1477-1483. |
| [13] | 黄恺杰, 王剑, 陈炯峄. 一种基于大语言模型的SQL注入攻击检测方法[J]. 信息网络安全, 2023, 23(11): 84-93. |
| [14] | 张光华, 刘永升, 王鹤, 于乃文. 基于BiLSTM和注意力机制的智能合约漏洞检测方案[J]. 信息网络安全, 2022, 22(9): 46-54. |
| [15] | 彭舒凡, 蔡满春, 刘晓文, 马瑞. 基于图像细粒度特征的深度伪造检测算法[J]. 信息网络安全, 2022, 22(11): 77-84. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||