信息网络安全 ›› 2023, Vol. 23 ›› Issue (3): 96-102.doi: 10.3969/j.issn.1671-1122.2023.03.010
基于深度学习的教育数据分类方法
谭柳燕1,2, 阮树骅1,2( ), 杨敏1,2, 陈兴蜀1,2
), 杨敏1,2, 陈兴蜀1,2
- 1.四川大学网络空间安全学院,成都 610065
2.四川大学网络空间安全研究院,成都 610065
-
收稿日期:2022-10-19出版日期:2023-03-10发布日期:2023-03-14 -
通讯作者:阮树骅 E-mail:ruanshuhua@scu.edu.cn -
作者简介:谭柳燕(1998—),女,四川,硕士研究生,主要研究方向为数据分类分级|阮树骅(1966—),女,浙江,副教授,硕士,主要研究方向为云计算与大数据安全、区块链安全|杨敏(1994—),女,四川,博士研究生,主要研究方向为数据安全和数据治理|陈兴蜀(1968—),女,贵州,教授,博士,主要研究方向为可信计算、云计算与大数据安全 -
基金资助:国家自然科学基金(U19A2081);四川大学工科特色团队项目(2020SCUNG129)
Educational Data Classification Based on Deep Learning
TAN Liuyan1,2, RUAN Shuhua1,2(), YANG Min1,2, CHEN Xingshu1,2
- 1. School of Cyber Science and Engineering, Sichuan University, Chengdu 610065, China
2. Cyber Science Research Institute, Sichuan University, Chengdu 610065, China
-
Received:2022-10-19Online:2023-03-10Published:2023-03-14 -
Contact:RUAN Shuhua E-mail:ruanshuhua@scu.edu.cn
摘要:
大数据技术的不断发展和数据泄露事件的频繁发生,催生了保护教育行业数据安全的迫切需求。教育行业的个人教育和成长的精准数据具有极高的价值,因此对教育数据实施保护已迫在眉睫。针对这一问题,文章提出了基于深度学习的教育数据分类方法。首先,根据数据管理主体的不同,定义个人数据、机构数据和业务数据3个类别;其次,提出一种基于字词向量结合的Bi-LSTM神经网络模型,实现教育数据分类的自动化、智能化;最后,通过在两所高校数据集上的实验对文章提出的分类方案进行验证。实验表明,相比于基线模型,文章所提方法在实验数据集上训练得到的模型分类准确率可达95%,且在各指标上均达到最优。
中图分类号:
引用本文
谭柳燕, 阮树骅, 杨敏, 陈兴蜀. 基于深度学习的教育数据分类方法[J]. 信息网络安全, 2023, 23(3): 96-102.
TAN Liuyan, RUAN Shuhua, YANG Min, CHEN Xingshu. Educational Data Classification Based on Deep Learning[J]. Netinfo Security, 2023, 23(3): 96-102.
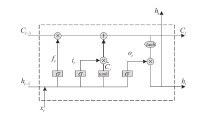
图1
LSTM隐藏单元结构

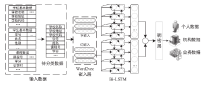
图2
基于深度学习的教育数据分类模型
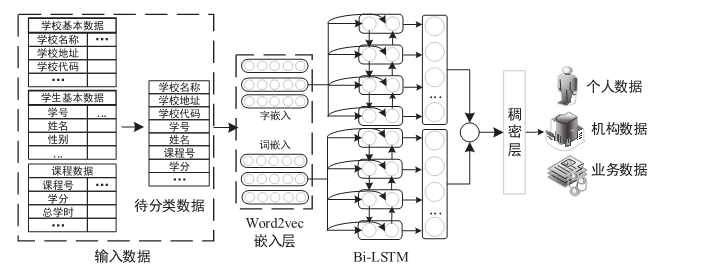
表1
环境配置
| 实验环境 | 具体信息 |
|---|---|
| 操作系统 | Windows 10 |
| CPU | Intel(R) Core(TM) i7-9700 |
| GPU | 无 |
| 内存 | 16 GB |
| 开发语言 | Python 3.7.0 |
| 开发平台 | PyCharm 2021.2.2 |
表2
收集的数据示例
| 编号 | 数据项名 | 中文简称 | 类型 | 长度 | 约束 | 解释/举例 | 引用编号 |
|---|---|---|---|---|---|---|---|
| JCXS010101 | XH | 学号 | C | 20 | M | Complied by the school | JY/T 1002 |
| JCXS020101 | RXNY | 入学年月 | C | 6 | M | YYYYMM | — |
| JCTB010407 | ZY | 专业 | C | 12 | 0 | — | — |
表3
实验数据具体情况
| 数据集 | 阶段 | 个人数据/条 | 机构数据/条 | 业务数据/条 |
|---|---|---|---|---|
| 大学A | 训练 | 231 | 201 | 1558 |
| 测试 | 92 | 68 | 693 | |
| 大学B | 训练 | 210 | 165 | 1107 |
| 测试 | 78 | 74 | 484 |
表4
不同词嵌入的分类性能对比
| 数据集 | 词嵌入 | 精确率 | 召回率 | 准确率 | F1值 |
|---|---|---|---|---|---|
| 大学A | One-hot | 75% | 76% | 88% | 0.76 |
| Word2vec | 88% | 78% | 92% | 0.82 | |
| GloVe | 91% | 55% | 87% | 0.63 | |
| FasText | 82% | 77% | 91% | 0.79 | |
| 大学B | One-hot | 76% | 83% | 87% | 0.79 |
| Word2vec | 84% | 82% | 90% | 0.83 | |
| GloVe | 71% | 50% | 80% | 0.55 | |
| FastText | 82% | 80% | 90% | 0.81 |
表5
与基线模型在教育数据三分类任务中的分类性能对比
| 数据集 | 分类模型 | 精确率 | 召回率 | 准确率 | F1值 |
|---|---|---|---|---|---|
| 大学A | DT-SVM | 81% | 80% | 91% | 0.80 |
| LSTM | 88% | 78% | 92% | 0.82 | |
| CNN | 82% | 77% | 90% | 0.80 | |
| Bi-LSTM | 89% | 82% | 93% | 0.85 | |
| 字词向量混合的Bi-LSTM | 89% | 86% | 95% | 0.88 | |
| 大学B | DT-SVM | 80% | 81% | 89% | 0.80 |
| LSTM | 86% | 80% | 91% | 0.82 | |
| CNN | 84% | 79% | 90% | 0.81 | |
| Bi-LSTM | 84% | 82% | 91% | 0.83 | |
| 字词向量混合的Bi-LSTM | 87% | 86% | 92% | 0.86 |
表6
跨数据集交叉验证性能对比
| 测试集 | 训练模型 | 精确率 | 召回率 | 准确率 | F1值 |
|---|---|---|---|---|---|
| 大学A | 模型B | 80% | 86% | 90% | 0.82 |
| 大学B | 模型A | 86% | 77% | 90% | 0.81 |
| [1] | STATISTA. Volume of Data Information Created, Captured, Copied, and Consumed Worldwide from 2010 to 2025[EB/OL]. (2021-06-07)[2022-06-10]. https://www.statista.com/statistics/871513/worldwide-data-created/. |
| [2] | ITRC. ITRC’s 2021 Q3 Data Breach Analysis and Key Takeaways[EB/OL]. (2021-10-06)[2022-06-10]. https://www.idtheftcenter.org/publication/2021-q3-data-breach-analysis/. |
| [3] | HONG Wei, REN Jianhong, XU Lina, et al. Classification of Educational Data Under the Background of Data Security Law[J]. Chinese Journal of ICT in Education, 2022, 28(3): 41-50. |
| 洪伟, 任剑洪, 徐丽娜, 等. 数据安全法实施背景下的教育数据分类分级研究[J]. 中国教育信息化, 2022, 28(3): 41-50. | |
| [4] | WANG Zhen. Research on Data Classification and Grading-Proceed from Article 19 (1) of the Data Security Law of the People’s Republic of China (Draft)[D]. Beijing: Beijing Foreign Studies University, 2021. |
| 王真. 数据分级分类研究——从《中华人民共和国数据安全法(草案)》第19条第1款出发[D]. 北京:北京外国语大学, 2021. | |
| [5] | BI Yunshan. Research of Chinese Text Classification Based on Deep Learning[D]. Hangzhou: Zhejiang University of Science and Technology, 2021. |
| 毕云杉. 基于深度学习的中文文本分类研究[D]. 杭州: 浙江科技学院, 2021. | |
| [6] |
WU Hongping, LIU Yuling, WANG Jingwen. Review of Text Classification Methods on Deep Learning[J]. Computers, Materials and Continua, 2020, 63(3): 1309-1321.
doi: 10.32604/cmc.2020.010172 URL |
| [7] | MIKOLOV T, CHEN K, CORRADO G, et al. Efficient Estimation of Word Representations in Vector Space[J]. Computer Science, 2013, 40(1): 1-10. |
| [8] | PENNINGTON J, SOCHER R, MANNING C. GloVe: Global Vectors for Word Representation[C]// ACL. 2014 Conference on Empirical Methods in Natural Language Processing(EMNLP). New York: The Association for Computational Linguistics, 2014: 1532-1543. |
| [9] | DEVLIN J, CHANG Mingwei, LEE K, et al. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding[C]// ACL. Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. New York: The Association for Computational Linguistics, 2019: 4171-4186. |
| [10] |
HOCHREITER S, SCHMIDHUBER J. Long Short-Term Memory[J]. Neural Computation, 1997, 9(8): 1735-1780.
doi: 10.1162/neco.1997.9.8.1735 pmid: 9377276 |
| [11] |
SCHUSTER M, PALIWAL K K. Bidirectional Recurrent Neural Networks[J]. IEEE Transactions on Signal Processing, 1997, 45(11): 2673-2681.
doi: 10.1109/78.650093 URL |
| [12] | GB/T 35273-2020 Information Security Technology-Personal Information Security Specification[S]. Beijing: Standards Press of China, 2020. |
| GB/T 35273-2020 信息安全技术个人信息安全规范[S]. 北京: 中国标准出版社, 2020. | |
| [13] | SUN Junyi. Jieba[EB/OL]. (2020-01-20)[2022-06-10]. https://github.com/fxsjy/jieba. |
| [14] | ZHANG Mohan. CNN-LSTM for Short Text Classification Based on Hybrid Word-Char Embeddings[J]. Information Technology and Informatization, 2019(1): 77-80. |
| 张默涵. 基于字词混合向量的CNN-LSTM短文本分类[J]. 信息技术与信息化, 2019(1): 77-80. | |
| [15] |
YANG Min, CHEN Xingshu, LUO Yonggang, et al. An Android Malware Detection Model Based on DT-SVM[J]. Security and Communication Networks, 2020, 1: 1-11.
doi: 10.1002/(ISSN)1939-0122 URL |
| [16] | YOON K. Convolutional Neural Networks for Sentence Classification[C]// ACL. 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP). New York: The Association for Computational Linguistics, 2014: 1746-1751. |
| [1] | 徐占洋, 程洛飞, 程建春, 许小龙. 一种使用Bi-ADMM优化深度学习模型的方案[J]. 信息网络安全, 2023, 23(2): 54-63. |
| [2] | 陈得鹏, 刘肖, 崔杰, 仲红. 一种基于双阈值函数的成员推理攻击方法[J]. 信息网络安全, 2023, 23(2): 64-75. |
| [3] | 贾凡, 康舒雅, 江为强, 王光涛. 基于NLP及特征融合的漏洞相似性算法评估[J]. 信息网络安全, 2023, 23(1): 18-27. |
| [4] | 高博, 陈琳, 严迎建. 基于CNN-MGU的侧信道攻击研究[J]. 信息网络安全, 2022, 22(8): 55-63. |
| [5] | 郑耀昊, 王利明, 杨婧. 基于网络结构自动搜索的对抗样本防御方法研究[J]. 信息网络安全, 2022, 22(3): 70-77. |
| [6] | 郭森森, 王同力, 慕德俊. 基于生成对抗网络与自编码器的网络流量异常检测模型[J]. 信息网络安全, 2022, 22(12): 7-15. |
| [7] | 张郅, 李欣, 叶乃夫, 胡凯茜. 融合多重风格迁移和对抗样本技术的验证码安全性增强方法[J]. 信息网络安全, 2022, 22(10): 129-135. |
| [8] | 刘烁, 张兴兰. 基于双重注意力的入侵检测系统[J]. 信息网络安全, 2022, 22(1): 80-86. |
| [9] | 朱新同, 唐云祁, 耿鹏志. 基于特征融合的篡改与深度伪造图像检测算法[J]. 信息网络安全, 2021, 21(8): 70-81. |
| [10] | 路宏琳, 王利明. 面向用户的支持用户掉线的联邦学习数据隐私保护方法[J]. 信息网络安全, 2021, 21(3): 64-71. |
| [11] | 马瑞, 蔡满春, 彭舒凡. 一种基于改进的Xception网络的深度伪造视频检测模型[J]. 信息网络安全, 2021, 21(12): 109-117. |
| [12] | 潘孝勤, 杜彦辉. 基于混合特征和多通道GRU的伪造语音鉴别方法[J]. 信息网络安全, 2021, 21(10): 1-7. |
| [13] | 徐国天, 盛振威. 基于融合CNN与LSTM的DGA恶意域名检测方法[J]. 信息网络安全, 2021, 21(10): 41-47. |
| [14] | 吴警, 芦天亮, 杜彦辉. 基于Char-RNN改进模型的恶意域名训练数据生成技术[J]. 信息网络安全, 2020, 20(9): 6-11. |
| [15] | 王文华, 郝新, 刘焱, 王洋. AI系统的安全测评和防御加固方案[J]. 信息网络安全, 2020, 20(9): 87-91. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||