信息网络安全 ›› 2023, Vol. 23 ›› Issue (7): 74-85.doi: 10.3969/j.issn.1671-1122.2023.07.008
基于稀疏自动编码器的可解释性异常流量检测
刘宇啸, 陈伟( ), 张天月, 吴礼发
), 张天月, 吴礼发
- 南京邮电大学网络空间安全学院,南京 210023
-
收稿日期:2022-12-20出版日期:2023-07-10发布日期:2023-07-14 -
通讯作者:陈伟 chenwei@njupt.edu.cn -
作者简介:刘宇啸(1999—),男,湖南,硕士研究生,CCF会员,主要研究方向为Web安全、异常流量检测|陈伟(1979—),男,江苏,教授,博士,CCF会员,主要研究方向为无线网络安全、移动互联网安全|张天月(1998—),女,江苏,硕士研究生,主要研究方向为机器学习、深度学习、异常流量检测|吴礼发(1968—),男,湖北,教授,博士,主要研究方向为软件安全漏洞挖掘和入侵检测 -
基金资助:国家重点研发计划(2019YFB2101704)
Explainable Anomaly Traffic Detection Based on Sparse Autoencoders
LIU Yuxiao, CHEN Wei(), ZHANG Tianyue, WU Lifa
- School of Computer Science, Nanjing University of Posts and Telecommunications, Nanjing 210023, China
-
Received:2022-12-20Online:2023-07-10Published:2023-07-14
摘要:
目前许多深度学习检测模型在各项指标上达到较好的效果,但是由于安全管理者不理解深度学习模型的决策依据,导致一方面无法信任模型的判别结果,另一方面不能很好地诊断和追踪模型的错误,这极大地限制了深度学习模型在该领域的实际应用。面对这样的问题,文章提出了一个基于稀疏自动编码器的可解释性异常流量检测模型(Sparse Autoencoder Based Anomaly Traffic Detection,SAE-ATD)。该模型利用稀疏自动编码器学习正常流量特征,并在此基础上引入了阈值迭代选取最佳阈值,以提高模型的检测率。模型预测完毕后,将预测结果的异常值送入解释器中,通过解释器对参考值进行迭代更新后,返回每个特征参考值和异常值的差值,并结合原始数据进行可解释性分析。文章在CICIDS2017数据集和CIRA-CIC-DoHBrw-2020数据集上进行实验,实验结果表明SAE-ATD在两个数据集上对大部分攻击检测的精确率和召回率达到99%,且能给模型提供可解释性。
中图分类号:
引用本文
刘宇啸, 陈伟, 张天月, 吴礼发. 基于稀疏自动编码器的可解释性异常流量检测[J]. 信息网络安全, 2023, 23(7): 74-85.
LIU Yuxiao, CHEN Wei, ZHANG Tianyue, WU Lifa. Explainable Anomaly Traffic Detection Based on Sparse Autoencoders[J]. Netinfo Security, 2023, 23(7): 74-85.

图1
SAE-ATD整体框架

图2
数据预处理流程

表1
由信息增益率产生的特征排名
| 编号 | 特征名字 | 信息增益率 |
|---|---|---|
| 1 | min_seg_size_forward | 41.9% |
| 2 | Init_Win_bytes_backward | 41.2% |
| 3 | Init_Win_bytes_forward | 41.1% |
| 4 | Bwd Packet Length Min | 40.4% |
| 5 | Total Length of Bwd Packets | 40.4% |
| 6 | Subflow Bwd Bytes | 39.9% |
| 7 | Bwd Header Length | 39.5% |
| 8 | Fwd Header Length | 39.2% |
| 9 | Fwd Header Length.1 | 38.2% |
| 10 | Fwd PSH Flags | 35.6% |
| 11 | SYN Flag Count | 35.6% |
| 12 | Max Packet Length | 34.8% |
| 13 | Bwd Packet Length Mean | 34.6% |
| 14 | Avg Bwd Segment Size | 34.4% |
| 15 | Bwd Packet Length Max | 33.8% |
| 16 | FIN Flag Count | 33.5% |
| 17 | Total Backward Packets | 32.0% |
| 18 | Subflow Bwd Packets | 32.0% |
| 19 | ACK Flag Count | 31.7% |
| 20 | Destination Port | 29.9% |
| 21 | Total Fwd Packets | 29.7% |
| 22 | Subflow Fwd Packets | 29.1% |
| 23 | act_data_pkt_fwd | 25.4% |
| 24 | Min Packet Length | 25.4% |
| 25 | Fwd Packet Length Min | 25.2% |
| 26 | Fwd Packet Length Max | 25.1% |
| 27 | Total Length of Fwd Packets | 24.7% |
| 28 | Subflow Fwd Bytes | 23.4% |
| 29 | PSH Flag Count | 23.3% |
| 30 | Down/Up Ratio | 23.1% |
| 31 | Bwd Packet Length Std | 21.9% |
| 32 | Average Packet Size | 21.8% |
| 33 | Packet Length Mean | 21.5% |
| 34 | Packet Length Std | 21.4% |

图3
训练模型框架

表2
常用符号
| 符号 | 描述 |
|---|---|
| 解释出异常的数据点 | |
| 用于解释的参考数据点 | |
| 特征的维度 | |
| 目标函数 | |
| 用于初始化表格解释器的邻域规模 |
表3
CICIDS2017时间顺序分布
| 星期 | 描述 | 大小/GB |
|---|---|---|
| Monday | Normal Activity | 11.0 |
| Tuesday | attacks+Normal Activity | 11 |
| Wednesday | attacks+Normal Activity | 13 |
| Thursday | attacks+Normal Activity | 7.8 |
| Friday | attacks+Normal Activity | 8.3 |
表4
本文使用的部分CICIDS2017数据分布
| 流量类型 | 大小/B |
|---|---|
| Benign | 755173 |
| DDoS | 128027 |
| Port Scan | 158930 |
表5
本文使用的部分CIRA-CIC-DoHBrw-2020数据分布
| 数据集 | 良性样本大小/B | 恶意样本大小/B |
|---|---|---|
| CIRA-CIC-DoHBrw-2020 Benign-DoH | 541930 | 0 |
| CIRA-CIC-DoHBrw-2020 Dns2tcp | 31 | 167486 |
| CIRA-CIC-DoHBrw-2020 DNSCat2 | 84 | 35770 |
表6
Friday-WorkingHours-Afternoon-PortScan数据集几种异常检测方法对比
| 指标 | DAGMM | Oneclass-SVM | AE-IDS | 本文方法 |
|---|---|---|---|---|
| AC | 59.3% | 83.9% | 77.4% | 99.0% |
| P | 57.7% | 87.5% | 97.7% | 99.9% |
| R | 100% | 83.9% | 78.8% | 98.4% |
| F | 73.2% | 84.5% | 87.2% | 99.1% |
| AUC | 84.8% | 88.3% | 89.8% | 93.2% |
表7
Friday-WorkingHours-Afternoon-DDoS数据集几种异常检测方法对比
| 指标 | DAGMM | Oneclass-SVM | AE-IDS | 本文方法 |
|---|---|---|---|---|
| AC | 81.6% | 83.9% | 57.3% | 84.0% |
| P | 75.6% | 65.6% | 88.5% | 78.0% |
| R | 99.9% | 92.5% | 60.5% | 100% |
| F | 86.1% | 76.8% | 71.9% | 87.6% |
| AUC | 89.9% | 87.4% | 82.5% | 92.5% |
表8
CIRA-CIC-DoHBrw-2020数据集实验结果
| 数据集 | AC | P | R | F | AUC |
|---|---|---|---|---|---|
| Dns2tcp | 99.9% | 99.9% | 100% | 99.9% | 93.4% |
| DNSCat2 | 99.7% | 99.7% | 100% | 99.8% | 90.2% |
表9
参数对比
| 编码层(两层) | L1正则值 | 各层dropout比率 | AC | P | R |
|---|---|---|---|---|---|
| [35,34] | [0.005,0] | [0.1,0.3] | 97.5% | 95.8% | 99.9% |
| [40,38] | [0.005,0] | [0.01,0.03] | 70.1% | 65.0% | 100% |
| [40,30] | [0.005,0] | [0.1,0.3] | 99.0% | 98.4% | 99.9% |
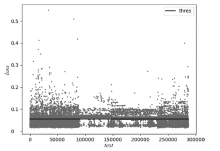
图4
端口扫描测试数据产生误差和阈值分布

表10
端口扫描恶意流量的解释器运行结果
| 特征描述 | 异常值 | 比较 | 参考值 |
|---|---|---|---|
| Destination Port | 0.765 | > | 0.12 |
| Packet Length Mean | 0.1 | < | 0.614 |
| Protocol_6 | 1.0 | > | 0.2 |
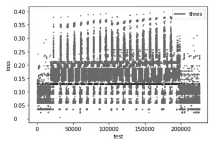
图5
DDoS测试数据产生误差和阈值分布
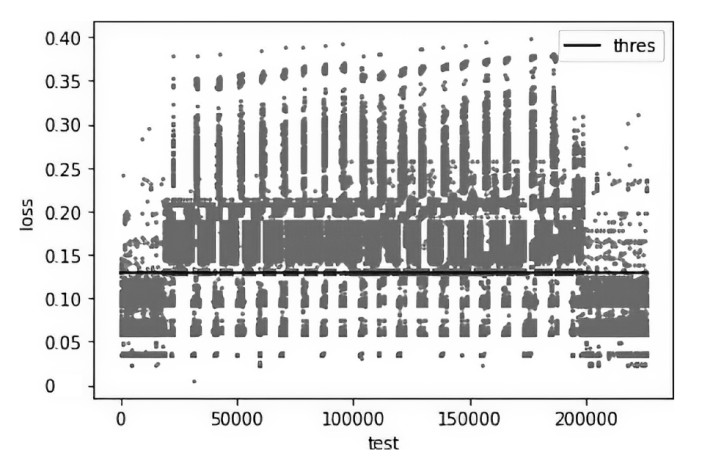
表11
DDoS恶意流量的解释器运行结果
| 特征描述 | 异常值 | 比较 | 参考值 |
|---|---|---|---|
| PSH Flag Count | 1.0 | > | 0.2 |
| Packet Length Std | 0.560 | > | 0.1 |
| Destination Port | 0.769 | > | 0.0 |
| ACK Flag Count | 1.0 | > | 0.2 |
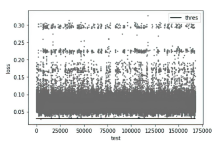
图6
dns2tcp流量测试数据产生误差和阈值分布
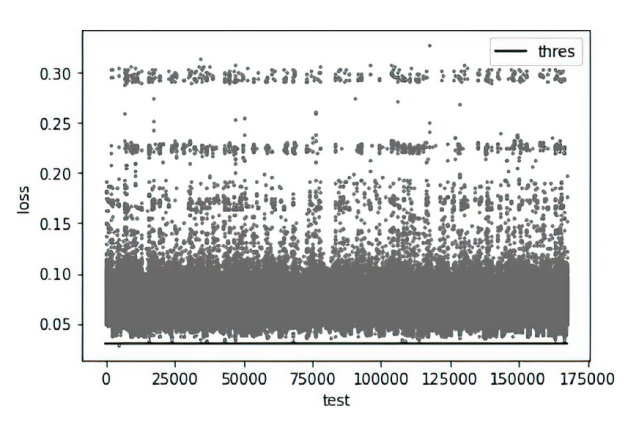
表12
dns2tcp恶意流量的解释器运行结果
| 特征描述 | 异常值 | 比较 | 参考值 |
|---|---|---|---|
| ResponseTimeTimeSkewFromMedian | 0.621 | > | 0.1 |
| PacketTimeCoefficientofVariation | 0.446 | > | 0.2 |
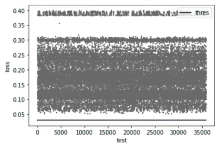
图7
DNSCat2流量测试数据产生误差和阈值分布
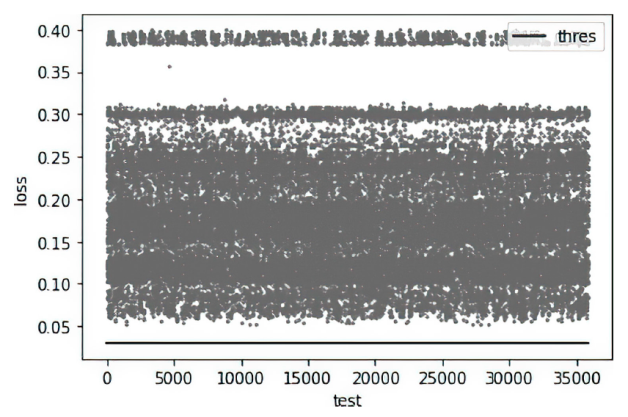
表13
DNSCat2恶意流量的解释器运行结果
| 特征描述 | 异常值 | 比较 | 参考值 |
|---|---|---|---|
| FlowBytesReceived | 0.46 | > | 0.1 |
| PacketTimeSkewFromMode | 0.774 | > | 0.2 |

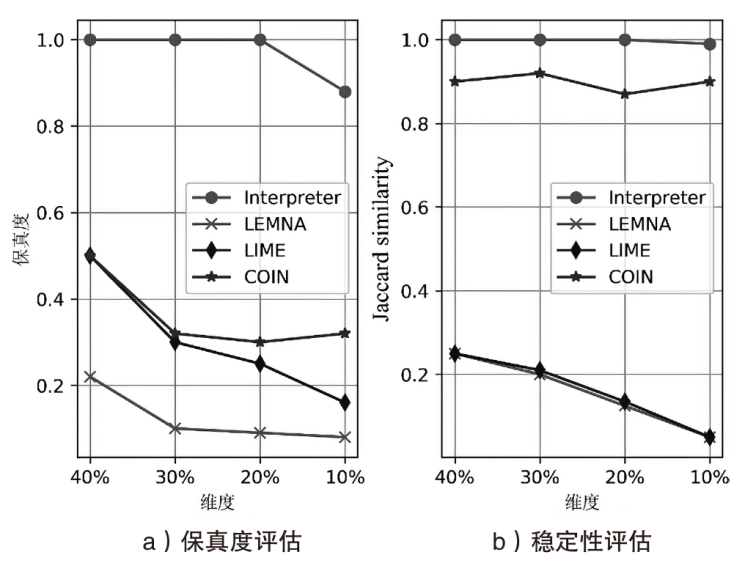
图8
可解释性模型性能对比
| [1] | MIRSKY Y, DOITSHMAM T, ELOVICI Y, et al. Kitsune: An Ensemble of Autoencoders for Online Network Intrusion Detection[J]. Machine Learning, 2018, 5: 2-8. |
| [2] | DU Min, LI Feifei, ZHENG Guineng, et al. Deeplog: Anomaly Detection and Diagnosis from System Logs Through Deep Learning[C]// ACM. Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security. New York: ACM, 2017: 1285-1298. |
| [3] | BOWMAN B, LAPRADE C, JI Yuede, et al. Detecting Lateral Movement in Enterprise Computer Networks with Unsupervised Graph[C]// RAID. 23rd International Symposium on Research in Attacks, Intrusions and Defenses(RAID 2020). New York: ACM, 2020: 257-268. |
| [4] | SIDI L, MIRSKY Y, NADLER A, et al. Helix: DGA Domain Embeddings for Tracking and Exploring Botnets[C]// ACM. Proceedings of the 29th ACM International Conference on Information& Knowledge Management. New York: ACM, 2020: 2741-2748. |
| [5] | LIU Ninghao, SHIN D, HU Xia. Contextual Outlier Interpretation[C]// IJCAI. Proceedings of the 27th International Joint Conference on Artificial Intelligence. New York: ACM, 2018: 2461-2467. |
| [6] | GUO Wenbo, MU Dongliang, XU Jun, et al. Lemna: Explaining Deep Learning Based Security Applications[C]// ACM. Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security. New York: ACM, 2018: 364-379. |
| [7] | RIBEIRO M T, SINGH S, GUESTRIN C. “ Why Should I Trust You?” Explaining the Predictions of Any Classifier[C]// ACM. Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2016: 1135-1144. |
| [8] | YANG Limin, GUO Wenbo, HAO Qingying, et al. {CADE}: Detecting and Explaining Concept Drift Samples for Security Applications[C]// USENIX. 30th USENIX Security Symposium(USENIX Security 21). New York: ACM, 2021: 2327-2344. |
| [9] | ANTWARG L, MILLER R M, SHAPIRA B, et al. Explaining Anomalies Detected by Autoencoders Using SHAP[EB/OL]. [2022-06-17]. https://arxiv.org/pdf/1903.02407.pdf. |
| [10] | HAN Dongqi, WANG Zhiliang, CHEN Wenqi, et al. DeepAID: Interpreting and Improving Deep Learning-Based Anomaly Detection in Security Applications[C]// ACM. Proceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security. New York: ACM, 2021: 3197-3217. |
| [11] | LI Xukui, CHEN Wei, ZHANG Qianru, et al. Building Auto-Encoder Intrusion Detection System Based on Random Forest Feature Selection[J]. Computers& Security, 2020, 95: 851-859. |
| [12] | ZONG Bo, SONG Qi, MIN Martin, et al. Deep Autoencoding Gaussian Mixture Model for Unsupervised Anomaly Detection[EB/OL]. [2022-11-22]. https://openreview.net/forum?id=BJJLHbb0-. |
| [13] |
BINBUSAYYIS A, VAIYAPURI T. Unsupervised Deep Learning Approach for Network Intrusion Detection Combining Convolutional Autoencoder and One-Class SVM[J]. Applied Intelligence, 2021, 51(10): 7094-7108.
doi: 10.1007/s10489-021-02205-9 |
| [14] | JAFAR M T, AL-FAWA'REH M, AL-HRAHSHEH Z, et al. Analysis and Investigation of Malicious DNS Queries Using CIRA-CIC-DoHBrw-2020 Dataset[EB/OL]. [2022-11-17]. https://mjaias.co.uk/mj-en/article/view/24. |
| [15] | SAMMOUR M, HUSSIN B, OTHMAN F I. Comparative Analysis for Detecting DNS Tunneling Using Machine Learning Techniques[J]. International Journal of Applied Engineering Research, 2017, 12(22): 12762-12766. |
| [16] | AIELLO M, MONGELLI M, PAPALEO G. Basic Classifiers for DNS Tunneling Detection[C]// IEEE. 2013 IEEE Symposium on Computers and Communications(ISCC). New York: IEEE, 2013: 880-885. |
| [17] | ZHAO Hong, CHANG Zhaobin, BAO Guangbin, et al. Malicious Domain Names Detection Algorithm Based on N-gram[EB/OL]. [2022-11-17]. https://www.hindawi.com/journals/jcnc/2019/4612474/. |
| [18] | ALLARD F, DUBOIS R, GOMPEL P, et al. Tunneling Activities Detection Using Machine Learning Techniques[J]. Journal of Telecommunications and Information Technology, 2011: 37-42. |
| [19] |
BANADAKI Y M. Detecting Malicious DNS over Https Traffic in Domain Name System Using Machine Learning Classifiers[J]. Journal of Computer Sciences and Applications, 2020, 8(2): 46-55.
doi: 10.12691/jcsa-8-2-2 URL |
| [20] | IMAN S, ARASH H, ALI A. CIRA-CIC-DoHBrw-2020[EB/OL]. [2022-11-29]. https://www.unb.ca/cic/datasets/dohbrw-2020.html |
| [21] | IMAN SHARAFALDIN, ARASH Habibi Lashkari, ALI A. Ghorba-ni, Intrusion Detection Evaluation Dataset(CICIDS2017)[EB/OL]. [2022-11-29]. http://www.unb.ca/cic/datasets/ids2017.html. |
| [22] | ZHAO Ruijie, HUANG Yiteng, DENG Xianwen, et al. A Novel Traffic Classifier with Attention Mechanism for Industrial Internet of Things[J]. IEEE Transactions on Industrial Informatics, 2023: 1-12. |
| [23] | DU Min, CHEN Zhi, LIU Chang, et al. Lifelong Anomaly Detection through Unlearning[C]// ACM. Proceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security. New York: ACM, 2019: 1283-1297. |
| [24] | YAN Yu, QI Lin, WANG Jie, et al. A Network Intrusion Detection Method Based on Stacked Autoencoder and LSTM[C]// IEEE.ICC 2020-2020 IEEE International Conference on Communications(ICC). New York: IEEE, 2020: 1-6. |
| [25] | KINGMA D P, BA J. Adam: A Method for Stochastic Optimization[EB/OL]. [2022-12-17]. https://arxiv.org/pdf/1412.6980.pdf. |
| [26] | ZENATI H, ROMAIN M, FOO C S, et al. Adversarially Learned Anomaly Detection[C]// IEEE. 2018 IEEE International Conference on Data Mining(ICDM). New York: IEEE, 2018: 727-736. |
| [27] | XU Haowen, CHEN Wenxiao, ZHAO Nengwen, et al. Unsupervised Anomaly Detection via Variational Auto-Encoder for Seasonal KPIS in Web Applications[C]// IEEE. Proceedings of the 2018 World Wide Web Conference. New York: IEEE, 2018: 187-196. |
| [28] | BACH S, BINDER A, MONTAVON G, et al. On Pixel-Wise Explanations for Non-Linear Classifier Decisions by Layer-Wise Relevance Propagation[J]. PLOS ONE, 2015, 10(7): 1-46. |
| [1] | 蒋英肇, 陈雷, 闫巧. 基于双通道特征融合的分布式拒绝服务攻击检测算法[J]. 信息网络安全, 2023, 23(7): 86-97. |
| [2] | 赵小林, 王琪瑶, 赵斌, 薛静锋. 基于机器学习的匿名流量分类方法研究[J]. 信息网络安全, 2023, 23(5): 1-10. |
| [3] | 赵彩丹, 陈璟乾, 吴志强. 基于多通道联合学习的自动调制识别网络[J]. 信息网络安全, 2023, 23(4): 20-29. |
| [4] | 谭柳燕, 阮树骅, 杨敏, 陈兴蜀. 基于深度学习的教育数据分类方法[J]. 信息网络安全, 2023, 23(3): 96-102. |
| [5] | 徐占洋, 程洛飞, 程建春, 许小龙. 一种使用Bi-ADMM优化深度学习模型的方案[J]. 信息网络安全, 2023, 23(2): 54-63. |
| [6] | 陈得鹏, 刘肖, 崔杰, 仲红. 一种基于双阈值函数的成员推理攻击方法[J]. 信息网络安全, 2023, 23(2): 64-75. |
| [7] | 贾凡, 康舒雅, 江为强, 王光涛. 基于NLP及特征融合的漏洞相似性算法评估[J]. 信息网络安全, 2023, 23(1): 18-27. |
| [8] | 高博, 陈琳, 严迎建. 基于CNN-MGU的侧信道攻击研究[J]. 信息网络安全, 2022, 22(8): 55-63. |
| [9] | 郑耀昊, 王利明, 杨婧. 基于网络结构自动搜索的对抗样本防御方法研究[J]. 信息网络安全, 2022, 22(3): 70-77. |
| [10] | 郭森森, 王同力, 慕德俊. 基于生成对抗网络与自编码器的网络流量异常检测模型[J]. 信息网络安全, 2022, 22(12): 7-15. |
| [11] | 张郅, 李欣, 叶乃夫, 胡凯茜. 融合多重风格迁移和对抗样本技术的验证码安全性增强方法[J]. 信息网络安全, 2022, 22(10): 129-135. |
| [12] | 刘烁, 张兴兰. 基于双重注意力的入侵检测系统[J]. 信息网络安全, 2022, 22(1): 80-86. |
| [13] | 朱新同, 唐云祁, 耿鹏志. 基于特征融合的篡改与深度伪造图像检测算法[J]. 信息网络安全, 2021, 21(8): 70-81. |
| [14] | 任涛, 金若辰, 罗咏梅. 融合区块链与联邦学习的网络入侵检测算法[J]. 信息网络安全, 2021, 21(7): 27-34. |
| [15] | 路宏琳, 王利明. 面向用户的支持用户掉线的联邦学习数据隐私保护方法[J]. 信息网络安全, 2021, 21(3): 64-71. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||