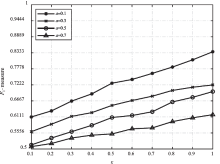
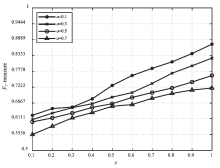
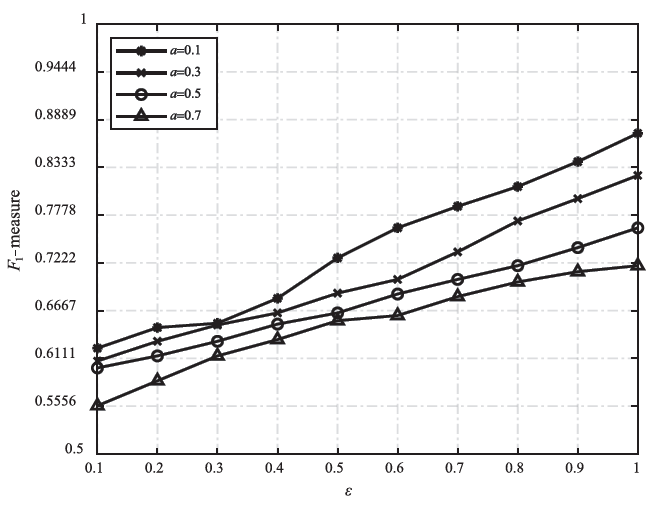
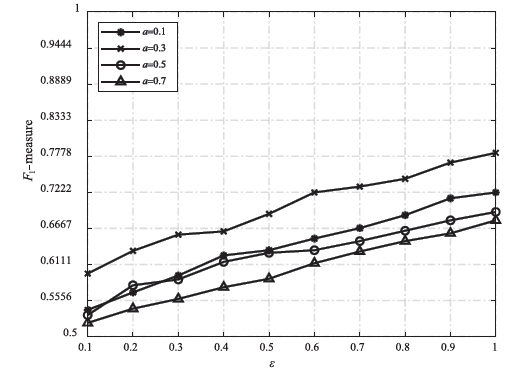
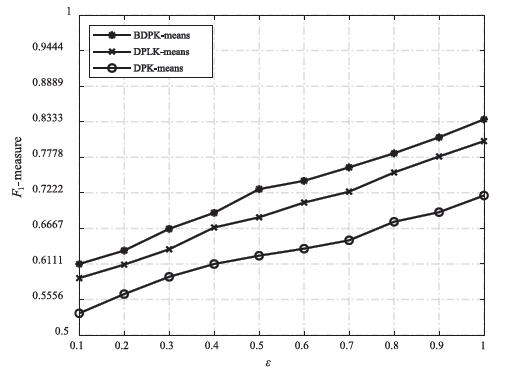
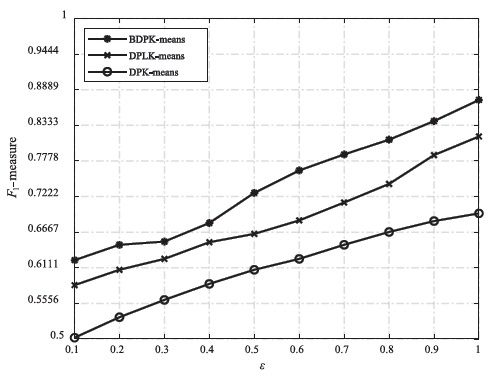
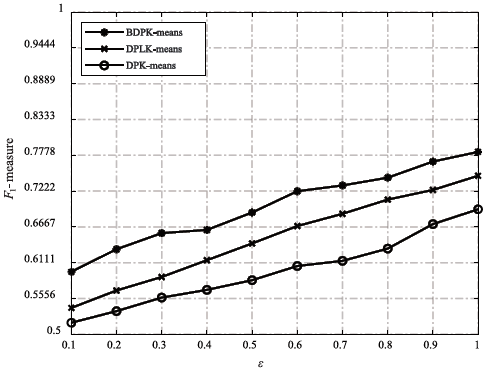
| [1] |
BLUM A, DWORK C, MCSHERRY F, et al. Practical Privacy: The SulQ Framework [C]//ACM. 24th ACM SIGACT-SIGMOD-SIGART Symposium on Principles of Database Systems, June 13-15, 2005, Baltimore, Maryland, USA. New York: ACM, 2005: 128-138.
|
| [2] |
DWORK C. A Firm Foundation for Private Data Analysis[J]. Communications of the ACM, 2011,54(1):86-95.
|
| [3] |
NISSIM K, RASKHODNIKOVA S, SMITH A. Smooth Sensitivity and Sampling in Private Data Analysis [C]//ACM. 39th Annual ACM Symposium on Theory of Computing, June 11-13, 2007 California, San Diego, USA. New York: ACM, 2007: 75-84.
|
| [4] |
FELDMAN D, FIAT A, KAPLAN H, et al. Private Coresets [C]//ACM. 41st Annual ACM Symposium on Theory of Computing, May 31-June 2, 2009, MD, Bethesda, USA. New York: ACM, 2009: 361-370.
|
| [5] |
LI Yang, HAO Zhifeng, WEN Wen, et al. Research on Differential Privacy Preserving k-means Clustering[J]. Computer Science, 2013,40(3):287-290.
|
|
李杨, 郝志峰, 温雯, 等. 差分隐私保护k-means聚类方法研究[J]. 计算机科学, 2013,40(3):287-290.
|
| [6] |
YU Qingying, LUO Yonglong, CHEN Chuanming, et al. Outlier-eliminated k-means Clustering Algorithm Based on Differential Privacy Preservation[J]. Applied Intelligence. 2016,45(4):1179-1191.
|
| [7] |
XIONG Ping, ZHU Tianqing, WANG Xiaofeng. A Survey on Diffenrential Privacy and Applications[J]. Chinese Journal of Computers, 2014,37(1):101-122.
|
|
熊平, 朱天清, 王晓峰. 差分隐私保护及其应用[J]. 计算机学报, 2014,37(1):101-122.
|
| [8] |
MOHAN P, THAKURTA A, SHI E, et al. GUPT: Privacy Preserving Data Analysis Made Easy [C]//ACM. 2012 ACM SIGMOD International Conference on Management of Data, May 20-24, 2012, Arizona, Scottsdale, USA. New York: ACM, 2012: 349-360.
|
| [9] |
REN Jun, XIONG Jinbo, YAO Zhiqiang, et al. DPLK-means: A Novel Differential Privacy K-means Mechanism [C]//IEEE. 2017 IEEE Second International Conference on Data Science in Cyberspace(DSC), June 26-29, 2017, Shenzhen, China. New Jersey: IEEE, 2017: 133-139.
|
| [10] |
SU Dong, CAO Jianneng, LI Ninghui, et al. Differentially Private k-means Clustering [C]//ACM. 6th ACM Conference on Data and Application Security and Privacy, March 9-11, 2016, Louisiana, New Orleans, USA. Ner York: ACM, 2016: 26-37.
|
| [11] |
GAO Zhiqiang, SUN Yixiao, CUI Xiaolong, et al. Privacy-preserving Hybrid K-means[J]. International Journal of Data Warehousing and Mining(IJDWM), 2018,14(2):1-17.
|
| [12] |
ZHANG Yaling, LIU Na, WANG Shangping. A Differential Privacy Protecting K-means Clustering Algorithm Based on Contour Coefficients[EB/OL]. https://www.onacademic.com/detail/journal_1000041661939199_f8d7.html, 2018-11-21.
|
| [13] |
HU Chuang, YANG Geng, BAI Yunlu. Clustering Algorithm in Differential Privacy Preserving[J]. Computer Science, 2019,46(2):129-135.
|
|
胡闯, 杨庚, 白云璐. 面向差分隐私保护的聚类算法[J]. 计算机科学, 2019,46(2):129-135.
|
| [14] |
MO Ran, LIU Jianfeng, YU Wentao, et al. A Differential Privacy-based Protecting Data Preprocessing Method for Big Data Mining [C]//IEEE. 2019 18th IEEE International Conference on Trust, Security and Privacy In Computing and Communications, August 5-8, 2019, Rotorua, New Zealand. New Jersey: IEEE, 2019: 693-699.
|
| [15] |
DWORK C. Differential Privacy [C]//Springer. 33rd International Conference on Automata, Languages and Programming-volume Part II, July 10-14, 2006, Venice, Italy. Heidelberg: Springer, 2006: 1-19.
|
| [16] |
DWORK C. Differential Privacy: A Survey of Results [C]//Springer. International Conference on Theory and Applications of Models of Computation, April 25-29, 2008, Xi’an, China. Heidelberg: Springer, 2008: 1-19.
|
| [17] |
DWORK C. The Differential Privacy Frontier [C]//Springer. 6th Theory of Cryptography Conference, March 15-17, 2009, San Francisco, CA, USA. Heidelberg: Springer, 2009: 496-502.
|
| [18] |
DWORK C. Differential Privacy in New Settings [C]//ACM. 21st Annual ACM-SIAM Symposium on Discrete Algorithms, January 17-19, 2010, Austin, Texas, USA. New York: Society for Industrial and Applied Mathematics, 2010: 174-183.
|
| [19] |
DALENIUS T. Towards a Methodology for Statistical Disclosure Control[J]. Statistik Tidskrift, 1977,15(2):429-444.
|
| [20] |
VISWANATH P. Histogranm-based Estimation Techniques in Databases[D]. Madison: University of Wisconsirr-Madison, 1997.
|
| [21] |
McSherry F D. Privacy Integrated Queries: An Extensible Platform for Privacy-preserving Data Analysis [C]//ACM. 2009 ACM SIGMOD International Conference on Management of data, June 29-July 2, 2009, Providence Rhode Island, USA. New York: Association for Computing Machinery, 2009: 19-30.
|
 ), CHENG Qi, YUAN Hong, HUANG Pirong
), CHENG Qi, YUAN Hong, HUANG Pirong