Netinfo Security ›› 2020, Vol. 20 ›› Issue (10): 19-26.doi: 10.3969/j.issn.1671-1122.2020.10.003
Previous Articles Next Articles
Research on k-anonymity Algorithm for Personalized Quasi-identifier Attributes
HE Jingsha, DU Jinhui( ), ZHU Nafei
), ZHU Nafei
- Faculty of Information Technology, Beijing University of Technology, Beijing 100124, China
-
Received:2020-07-03Online:2020-10-10Published:2020-11-25 -
Contact:DU Jinhui E-mail:1290344719@qq.com
CLC Number:
Cite this article
HE Jingsha, DU Jinhui, ZHU Nafei. Research on k-anonymity Algorithm for Personalized Quasi-identifier Attributes[J]. Netinfo Security, 2020, 20(10): 19-26.
share this article
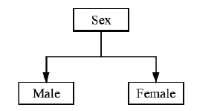




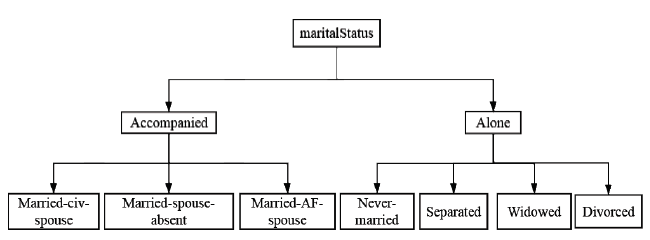
| 属性名称 | 取值个数 | 泛化树深度 | 属性类型 |
|---|---|---|---|
| Sex | 2 | 2 | AQI |
| Country | 40 | 5 | AQI |
| Education | 16 | 3 | AQI |
| Occupation | 14 | 3 | AQI |
| maritalStatus | 7 | 3 | AQI |





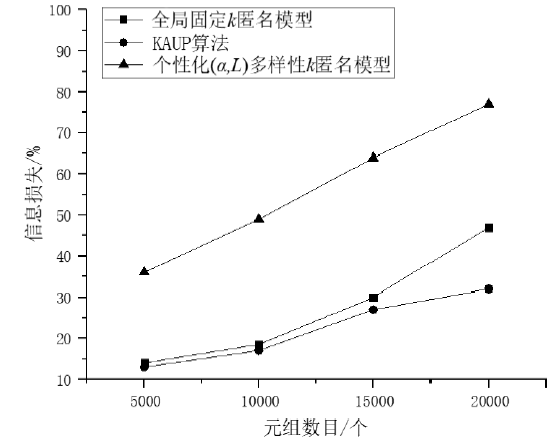
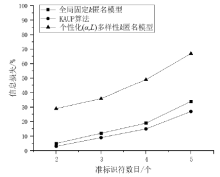

| [1] | LIU Ming, YE Xiaojun. Personalized K-anonymity[J]. Computer Engineering and Design, 2008,29(2):282-286. |
| 刘明, 叶晓俊. 个性化K-匿名模型[J]. 计算机工程与设计, 2008,29(2):282-286. | |
| [2] | YANG Jing, REN Xiangmin, ZHANG Jianpei, et al. Research on Uncertain Data Privacy Protection Based on k-anonymity[J]. International Journal of Advancements in Computing Technology, 2012,4(15):140-149. |
| [3] | NI Sang, XIE Mengbo, QIAN Quan. Clustering-based k-anonymity Algorithm for Privacy Preservation[J]. International Journal of Network Security, 2017,6(19):1062-1071. |
| [4] | FANG Yu, GAO Lei, LIU Zhonghui, et al. Generalized Cost-sensitive Approximate Attribute Reduction Based on Three-way Decisions[J]. Journal of Nanjing University of Science and Technology, 2019,43(4):481-488. |
| 方宇, 高磊, 刘忠慧, 等. 基于三支决策的广义代价敏感属性约简[J]. 南京理工大学学报, 2019,43(4):481-488. | |
| [5] | YE Xiaojun, ZHANG Yawei, LIU Ming. A Personalized (α-k)-anonymity Model [C]// IEEE. The 9th International Conference on Web-Age Information Management, July 20-22, 2008, Zhangjiajie, China. NJ: IEEE, 2008: 341-348. |
| [6] | YIN Yanmin. Research on Privacy Preserving Method of Location Service Trajectory in Fog Computing[J]. Qufu: Qufu Normal University, 2019. |
| 尹彦民. 雾计算中位置服务轨迹隐私保护方法研究[D]. 曲阜:曲阜师范大学, 2019. | |
| [7] | SWEENEY L. k-anonymity: A Model for Protecting Privacy[J]. International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems, 2002,10(5):557-570. |
| [8] | LIU Xiangwen, XIE Qingqing, WANG Liangmin. Personalized Extended (α, k)-anonymity Model for Privacy-preserving Data Publishing[EB/OL]. https://onlinelibrary.wiley.com/doi/epdf/10.1002/cpe.3886, 2016-6-30. |
| [9] | SHEN Yanguang, GUO Gaoshang, WU Di, et al. A Novel Algorithm of Personalized-granular k-anonymity [C]//IEEE. 2013 International Conference on Mechatronic Sciences, Electric Engineering and Computer, December 20-22, 2013, Shenyang, China. NJ: IEEE, 2013: 1860-1866. |
| [10] | LIU Yinghua, YANG Bingru, LI Guangyuan. A Personalized Privacy Preserving Parallel (alpha, k)-anonymity Model[J]. International Journal of Advanced in Computing Technology, 2012,5(4):165-271. |
| [11] | LIAO Jun, JIANG Chaohui, GUO Chun, et al. Classification Anonymity Algorithm Based on Weight Attributes Entropy[J]. Computer Science, 2017,44(7):42-46. |
| 廖军, 蒋朝惠, 郭春, 等. 一种基于权重属性熵分类的匿名算法[J]. 计算机科学, 2017,44(7):42-46. | |
| [12] | REN Xiangmin, YANG Jing, WEI Fengmei. Research on Diversity of Sensitive Attribute of K-anonymity [C]//IEEE. 2010 2nd International Workshop on Database Technology and Application, November 27-28, 2010, Wuhan, China. NJ: IEEE, 2010: 1-4. |
| [13] | YU Shoujian, NIU in, YANG Yun, et al. Personalized Privacy Protection Based on Diversity against Connection Fingerprint Attact [C]//IEEE. 2019 IEEE International Conference on Power, Intelligent Computing and Systems, July 12-14,2019, Shenyang, China. NJ: IEEE, 2019: 205-211. |
| [14] | TRUTA T M, CAMPAN A, MEYER P. Generating Microdata with p-sensitive k-anonymity Property[M] //Springer. Secure Data Management. Heidelberg: Springer, Berlin, Heidelberg, 2007: 124-141. |
| [15] | JIA Junjie, YAN Guolei. A Personalized (p, k)-Anonymity Privacy Protection Algorithm[J]. Computer Engineering, 2018,44(1):176-181. |
| 贾俊杰, 闫国蕾. 一种个性化(p,k)匿名隐私保护算法[J]. 计算机工程, 2018,44(1):176-181. | |
| [16] | ZHAO Yan, WANG Jian, LUO Yongcheng, et al. (α, β, k)-anonymity: An Effective Privacy Preserving Model for Databases [C]//IEEE. 2009 International Conference on Test and Measurement. December 5-6, 2009, Hong Kong, China. NJ: IEEE, 2009: 412-415. |
| [17] | RAO U P, MEHTA B B, KUMAR N. Scalable L-diversity: An Extension to Scalable k-anonymity for Privacy Preserving Big Data Publishing[J]. International Journal of Information Technology and Web Engineering, 2019, 14(2): 27-40. |
| [18] | LIAO Jun. Research on Data Privacy Protection Method Based on Classified Mining[D]. Guiyang: Guizhou University, 2017. |
| [19] | TELL R. Property Testing Lower Bounds Via a Generalization of Randomized Parity Decision Trees[J]. Theory of Computing Systems, 2019,63(15):418-449. |
| [20] | ZENG Kai. Privacy Protection Model Research[D]. Chongqing: Chongqing University, 2012. |
| [21] | YU Juan. Research on Anonymity Model and Algorithm of Privacy Protection in Data Publishing[D]. Jinhua: Zhenjiang Normal University, 2010. |
| 于娟. 数据发布中隐私保护的匿名模型及算法研究[D]. 金华:浙江师范大学,2010. | |
| [22] | ZENG Mengjia, CHENG Zhaolin, HUANG Xu, et al. Spatial Crowdsourcing Quality Control Model Based on K-Anonymity Location Privacy Protection and ELM Spammer Detection[J]. Mobile Information Systems, 2019,4(10):1-10. |
| [23] | SONG Jinling, LIU Guohua, HUANG Liming, et al. k-Anonymous Privacy Protection Model K-Value Optimal Selection Algorithms[J]. Minicomputer System, 2011,32(10):1987-1993. |
| [24] | CAO Minzi, ZHANG Linlin, BI Xuehua, et al. Personalized (alpha, l)- Diversity K-Anonymous Privacy Protection Model[J]. Computer Science, 2018,45(11):180-186. |
| [1] | LI Ningbo, ZHOU Haonan, CHE Xiaoliang, YANG Xiaoyuan. Design of Directional Decryption Protocol Based on Multi-key Fully Homomorphic Encryption in Cloud Environment [J]. Netinfo Security, 2020, 20(6): 10-16. |
| [2] | HUANG Baohua, CHENG Qi, YUAN Hong, HUANG Pirong. K-means Clustering Algorithm Based on Differential Privacy with Distance and Sum of Square Error [J]. Netinfo Security, 2020, 20(10): 34-40. |
| [3] | Wenjiang HAO, Yun LIN. Research on Social Responsibility of Internet Enterprises and Its Enlightenment [J]. Netinfo Security, 2019, 19(9): 130-133. |
| [4] | Quan ZHOU, Shumei XU, Ningbin YANG. A Privacy Protection Scheme for Smart Grid Based on Attribute-based Group Signature [J]. Netinfo Security, 2019, 19(7): 25-30. |
| [5] | Yanming FU, Zhenduo LI. Research on k-means++ Clustering Algorithm Based on Laplace Mechanism for Differential Privacy Protection [J]. Netinfo Security, 2019, 19(2): 43-52. |
| [6] | Ronglei HU, Yanqiong HE, Ping ZENG, Xiaohong FAN. Design and Implementation of Medical Privacy Protection Scheme in Big Data Environment [J]. Netinfo Security, 2018, 18(9): 48-54. |
| [7] | Peili LI, Haixia XU, Tianjun MA, Yongheng MU. The Application of Blockchain Technology in Network Mutual Aid and User Privacy Protection [J]. Netinfo Security, 2018, 18(9): 60-65. |
| [8] | Rong MA, Xiuhua CHEN, Hui LIU, Jinbo XIONG. Research on User Privacy Measurement and Privacy Protection in Mobile Crowdsensing [J]. Netinfo Security, 2018, 18(8): 64-72. |
| [9] | Le WANG, Zherong YANG, Rongjing LIU, Xiang WANG. A CP-ABE Privacy Preserving Method for Wearable Devices [J]. Netinfo Security, 2018, 18(6): 77-84. |
| [10] | Lei ZHANG, Bin WANG, Lili YU. A Markov Prediction-based Algorithm for Continuous Query Privacy Protection [J]. Netinfo Security, 2018, 18(5): 12-12. |
| [11] | Lei ZHANG, Bin WANG, Lili YU. A Hash Function-based Attribute Generalization Privacy Protection Scheme [J]. Netinfo Security, 2018, 18(3): 14-25. |
| [12] | Liang LI, Yinghui ZHANG, Kaixin DENG, Tiantian ZHANG. Privacy-aware Power Injection in 5G Smart Grid [J]. Netinfo Security, 2018, 18(12): 87-92. |
| [13] | Na ZHAO, Hui LONG, Jinshu SU. A Scheme for Anonymous Authentication and Privacy Protection in the Internet of Things Environment [J]. Netinfo Security, 2018, 18(11): 1-7. |
| [14] | Chunming TANG, Weiming WEI. Regression Algorithm with Privacy Based on Secure Two-party Computation [J]. Netinfo Security, 2018, 18(10): 10-16. |
| [15] | Kuo ZHAO, Yongheng XING. Security Survey of Internet of Things Driven by Block Chain Technology [J]. Netinfo Security, 2017, 17(5): 1-6. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||