Netinfo Security ›› 2024, Vol. 24 ›› Issue (9): 1409-1421.doi: 10.3969/j.issn.1671-1122.2024.09.009
Previous Articles Next Articles
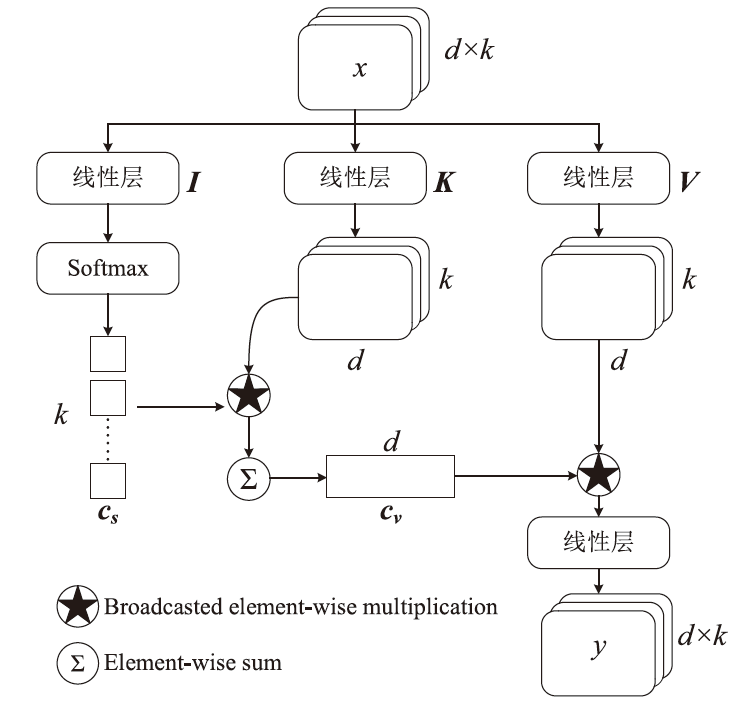
Lightweight Malicious Code Detection Architecture Based on Vision Transformer
HUANG Baohua1( ), YANG Chanjuan1, XIONG Yu2, PANG Si1
), YANG Chanjuan1, XIONG Yu2, PANG Si1
- 1. School of Computer and Electronic Information, Guangxi University, Nanning 530004, China
2. Wuhan Digital Engineer Institute, Wuhan 430070, China
-
Received:2024-06-01Online:2024-09-10Published:2024-09-27
CLC Number:
Cite this article
HUANG Baohua, YANG Chanjuan, XIONG Yu, PANG Si. Lightweight Malicious Code Detection Architecture Based on Vision Transformer[J]. Netinfo Security, 2024, 24(9): 1409-1421.
share this article
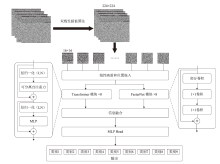
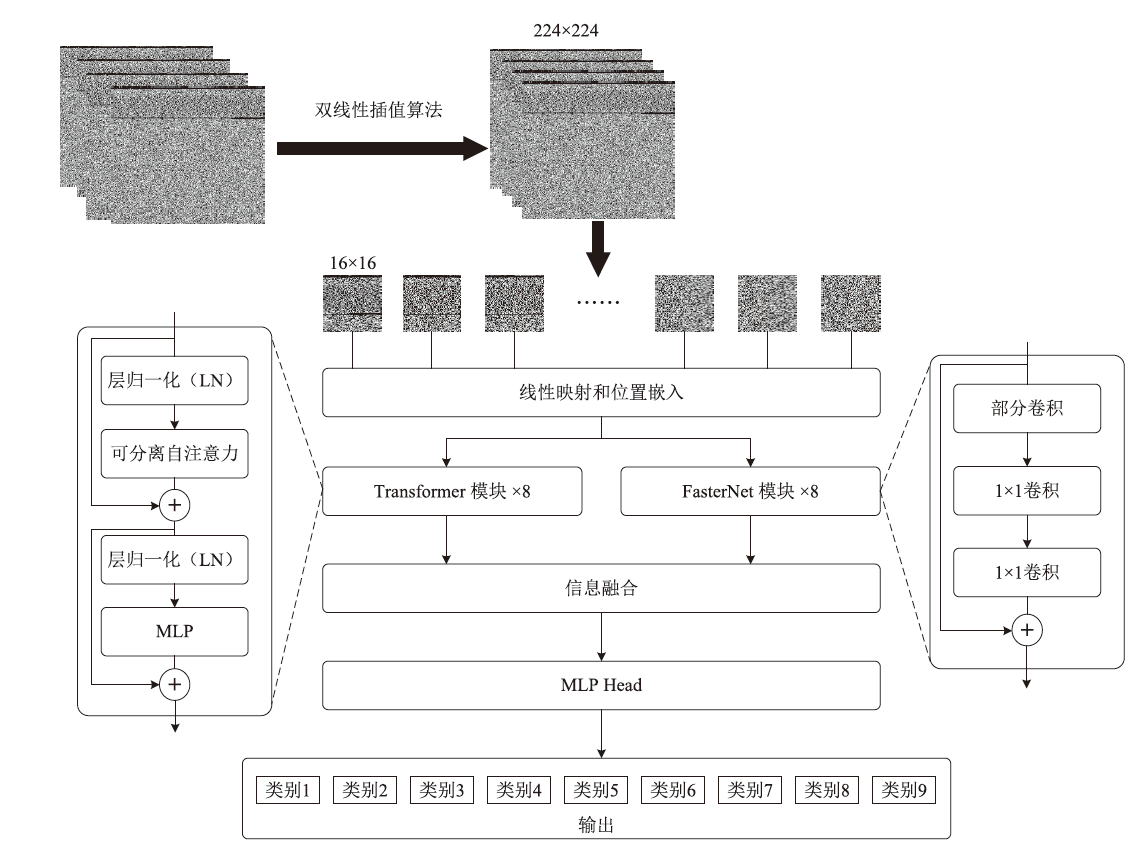

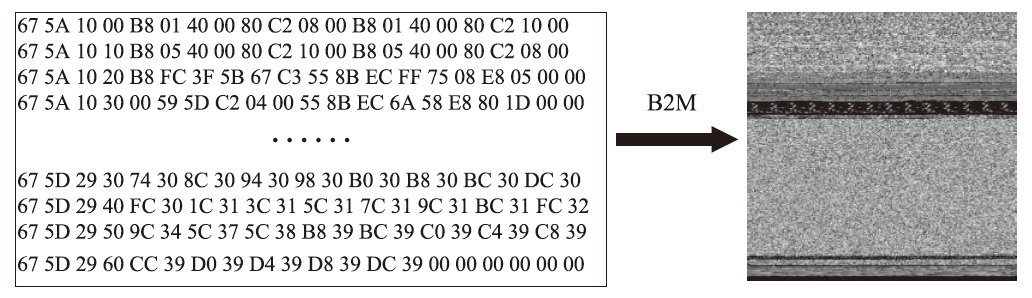
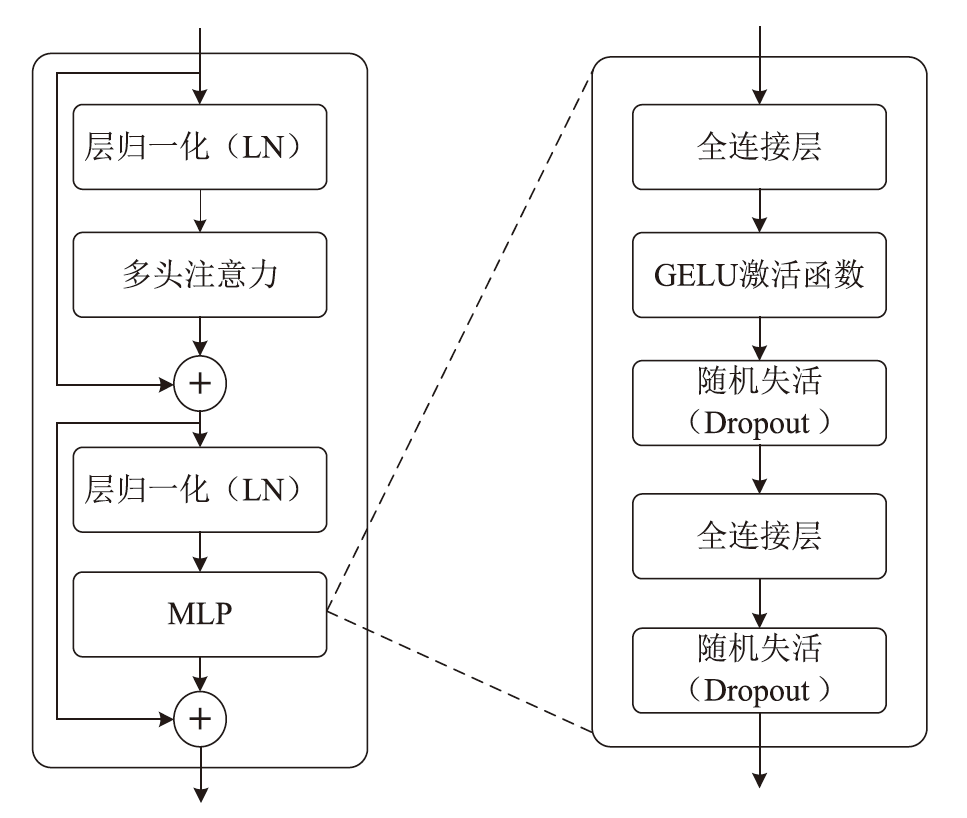
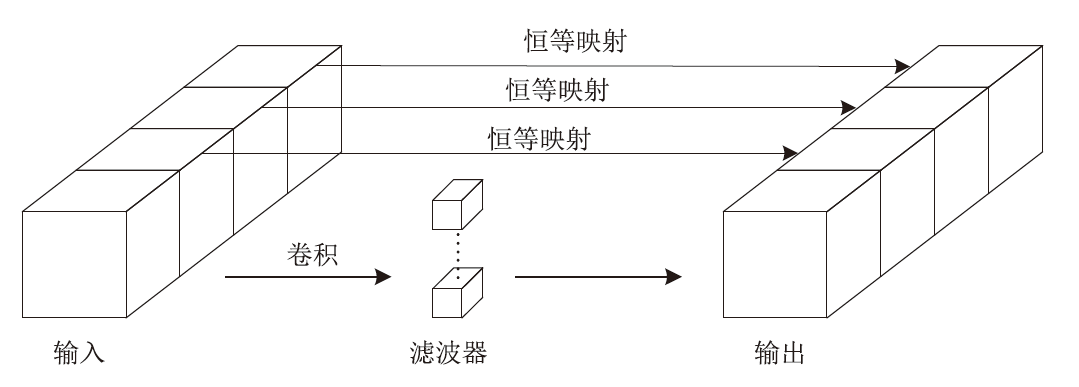
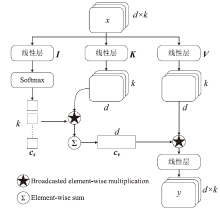
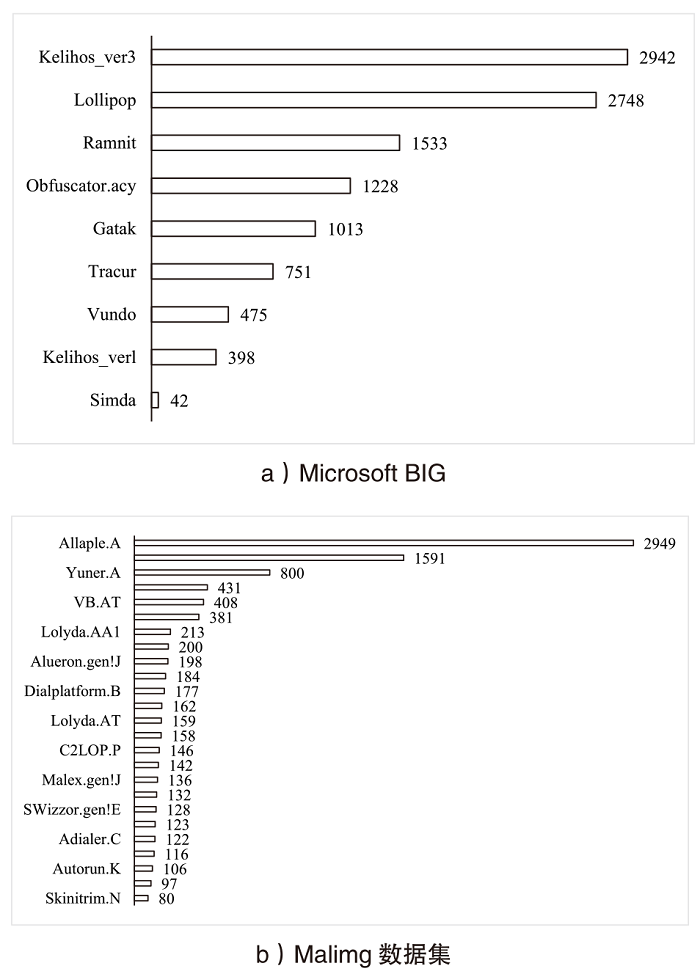
| 尺寸 | Accuracy | Precision | Recall | F1 | MCC |
|---|---|---|---|---|---|
| 64?64 | 91.22% | 92.51% | 91.22% | 0.9150 | 0.8952 |
| 128?128 | 95.03% | 95.41% | 95.02% | 0.9509 | 0.9402 |
| 224?224 | 98.53% | 96.23% | 98.53% | 0.9732 | 0.9699 |
| 256?256 | 96.25% | 96.38% | 96.25% | 0.9625 | 0.9548 |
| 优化器 | Accuracy | Precision | Recall | F1 | MCC |
|---|---|---|---|---|---|
| Adam | 97.11% | 96.18% | 97.11% | 0.9655 | 0.9615 |
| AdamW | 98.53% | 96.23% | 98.53% | 0.9732 | 0.9699 |
| 部分 卷积 | 可分离 自注意力 | Accuracy | Precision | Recall | F1 | MCC | 参数量 |
|---|---|---|---|---|---|---|---|
| — | — | 95.34% | 95.56% | 95.33% | 0.9534 | 0.9437 | 28.79M |
| √ | — | 96.13% | 96.35% | 96.13% | 0.9612 | 0.9534 | 28.87M |
| — | √ | 96.75% | 96.80% | 96.75% | 0.9673 | 0.9607 | 28.03M |
| √ | √ | 97.73% | 96.20% | 97.73% | 0.9689 | 0.9651 | 28.25M |
| 损失函数 | Accuracy | Precision | Recall | F1 | MCC |
|---|---|---|---|---|---|
| 多类交叉熵损失函数 | 97.73% | 96.20% | 97.73% | 0.9689 | 0.9651 |
| 类别平衡焦点损失函数 | 98.53% | 96.23% | 98.53% | 0.9732 | 0.9699 |
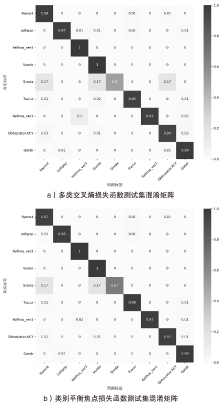
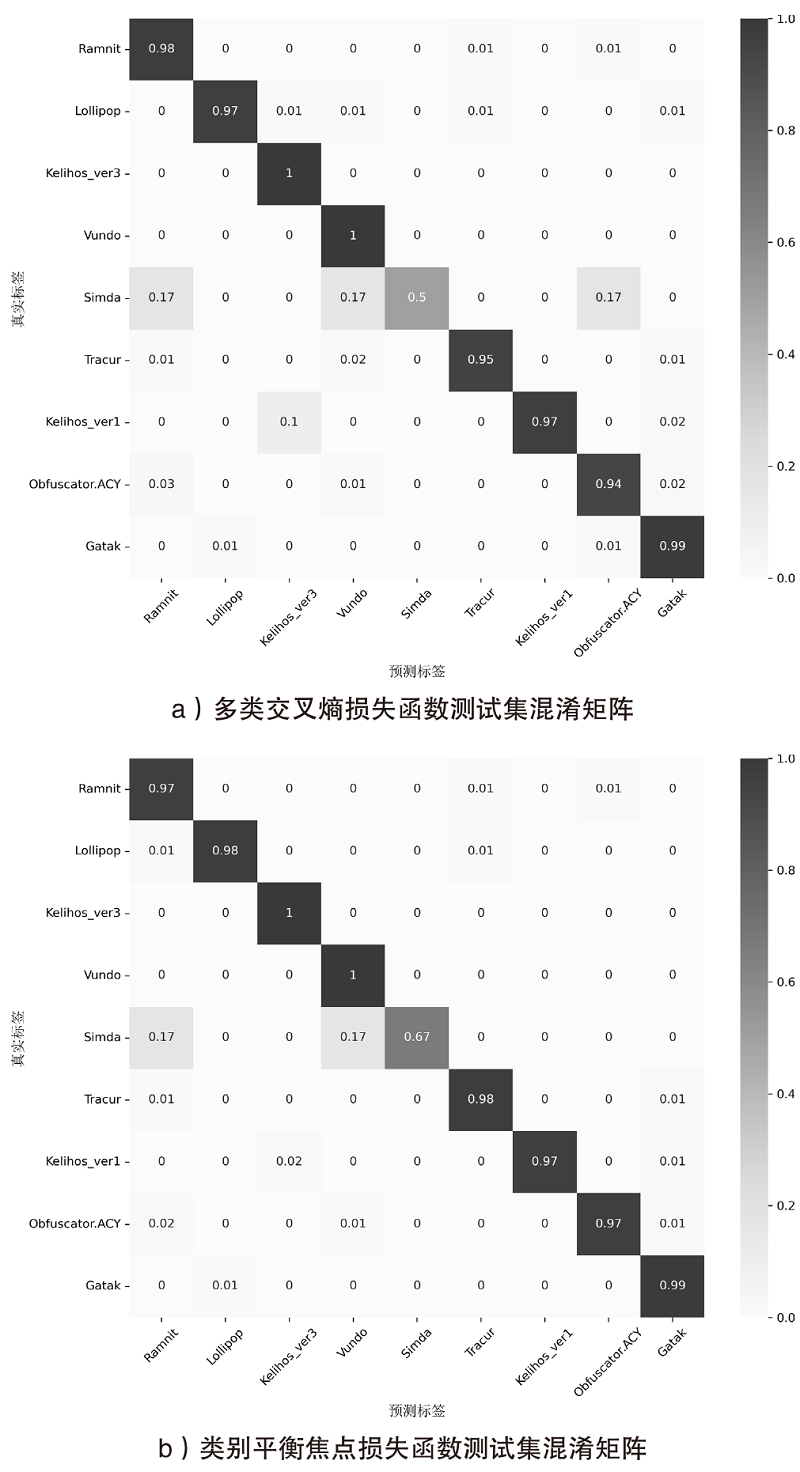
| 恶意代码 检测方法 | 年份 | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|---|
| 文献[ | 2021 | 94.88% | — | 92.47% | 0.8988 |
| 文献[ | 2021 | 98.46% | 98.58% | 97.84% | 0.9821 |
| 文献[ | 2022 | 96.83% | — | — | — |
| DTMIC[ | 2022 | 93.19% | — | — | — |
| IMCBL[ | 2024 | 95.49% | 95.31% | 95.49% | 0.9536 |
| FasterMalViT | 2024 | 98.53% | 96.23% | 98.53% | 0.9732 |
| 恶意代码 检测方法 | 年份 | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|---|
| 文献[ | 2020 | 98.58% | 98.04% | 98.06% | 0.9805 |
| 文献[ | 2021 | 98.23% | 97.78% | 97.92% | 0.9785 |
| 文献[ | 2021 | 98.97% | 99.50% | 97.06% | 0.9697 |
| 文献[ | 2022 | 97.76% | 97.84% | 97.76% | 0.9769 |
| 3D-VGG-16[ | 2024 | 96.14% | 97.00% | 95.00% | 0.9500 |
| FasterMalViT | 2024 | 98.43% | 98.44% | 98.43% | 0.9841 |
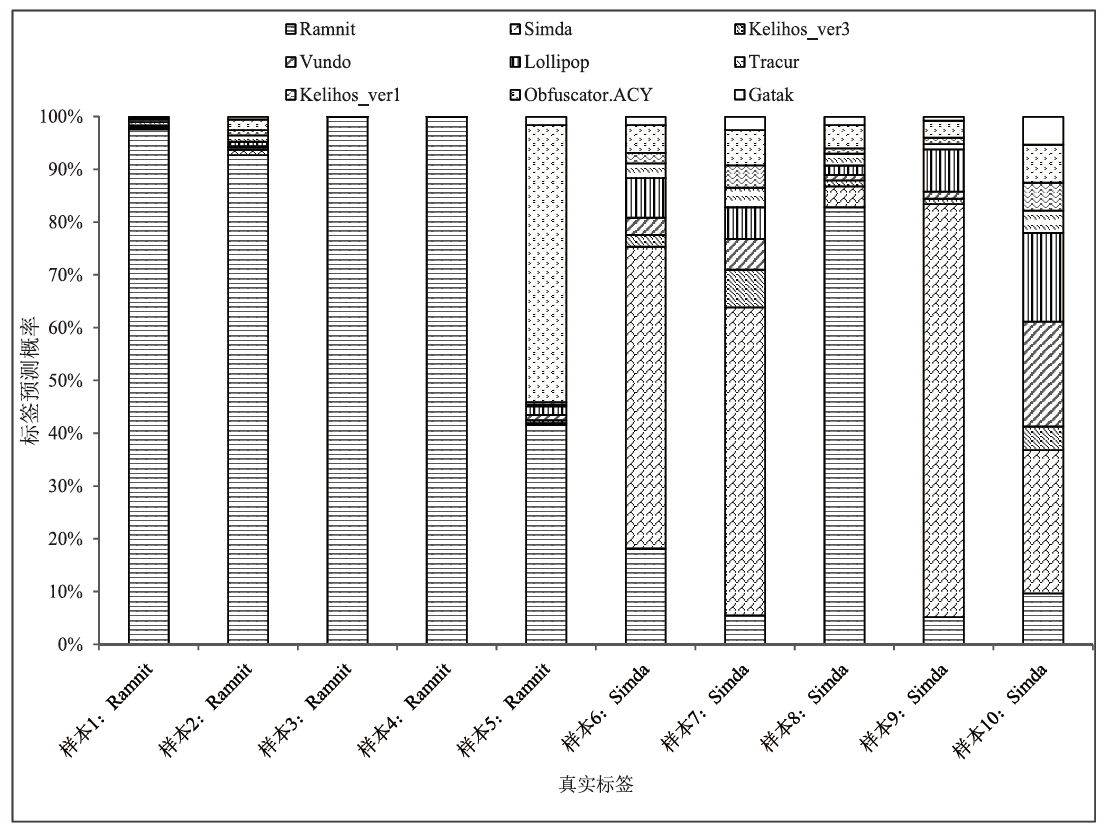
| [1] | ASLAN O, SAMET R. A Comprehensive Review on Malware Detection Approaches[J]. IEEE Access, 2020, 8: 6249-6271. |
| [2] | MANIRIHO P, MAHMOOD A N, CHOWDHURY M J M. A Study on Malicious Software Behaviour Analysis and Detection Techniques: Taxonomy, Current Trends and Challenges[J]. Future Generation Computer Systems, 2022, 130: 1-18. |
| [3] | GOPINATH M, SETHURAMAN S C. A Comprehensive Survey on Deep Learning Based Malware Detection Techniques[EB/OL]. (2023-12-21)[2024-04-30]. https://doi.org/10.1016/j.cosrev.2022.100529. |
| [4] | GABER M G, AHMED M, JANICKE H. Malware Detection with Artificial Intelligence: A Systematic Literature Review[J]. ACM Computing Surveys, 2024, 56(6): 1-33. |
| [5] | ZHANG Jixin, QIN Zheng, YIN Hui, et al. A Feature-Hybrid Malware Variants Detection Using CNN Based Opcode Embedding and BPNN Based API Embedding[J]. Computers & Security, 2019, 84: 376-392. |
| [6] | JEON J, JEONG B, BAEK S, et al. Hybrid Malware Detection Based on Bi-LSTM and SPP-Net for Smart IoT[J]. IEEE Transactions on Industrial Informatics, 2022, 18(7): 4830-4837. |
| [7] | VERMA V, MUTTOO S K, SINGH V B. Multiclass Malware Classification via First- and Second-Order Texture Statistics[EB/OL]. (2020-07-23)[2024-04-30]. https://doi.org/10.1016/j.cose.2020.101895. |
| [8] | SHAUKAT K, LUO Suhai, VARADHARAJAN V. A Novel Deep Learning-Based Approach for Malware Detection[EB/OL]. (2023-03-09)[2024-04-30]. https://doi.org/10.1016/j.engappai.2023.106030. |
| [9] | DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale[C]// ICLR. 9th International Conference on Learning Representations(ICLR 2021). Washington: ICLR, 2021: 1-21. |
| [10] | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is All You Need[C]// ACM. 31st International Conference on Neural Information Processing Systems. New York: ACM, 2017(11): 6000-6010. |
| [11] | CHEN Jierun, KAO S H, HE Hao, et al. Run, Don’t Walk: Chasing Higher FLOPS for Faster Neural Networks[C]// IEEE. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE, 2023: 12021-12031. |
| [12] | MEHTA S, RASTEGARI M. Separable Self-Attention for Mobile Vision Transformers[J]. Transactions on Machine Learning Research, 2023: 1-22. |
| [13] | NATARAJ L, KARTHIKEYAN S, JACOB G, et al. Malware Images: Visualization and Automatic Classification[C]// ACM. Proceedings of the 8th International Symposium on Visualization for Cyber Security. New York: ACM, 2011: 1-7. |
| [14] | ZHU Huijuan, GU Wei, WANG Liangmin, et al. Android Malware Detection Based on Multi-Head Squeeze-and-Excitation Residual Network[EB/OL]. (2023-08-30)[2024-04-30]. https://doi.org/10.1016/j.eswa.2022.118705. |
| [15] | LI Ce, CHENG Zijun, ZHU He, et al. DMalNet: Dynamic Malware Analysis Based on API Feature Engineering and Graph Learning[EB/OL]. (2022-08-08)[2024-04-30]. https://doi.org/10.1016/j.cose.2022.102872. |
| [16] | NGUYEN T N, NGO Q D, NGUYEN H T, et al. An Advanced Computing Approach for IoT-Botnet Detection in Industrial Internet of Things[J]. IEEE Transactions on Industrial Informatics, 2022, 18(11): 8298-8306. |
| [17] | DENG Huaxin, GUO Chun, SHEN Guowei, et al. MCTVD: A Malware Classification Method Based on Three-Channel Visualization and Deep Learning[EB/OL]. (2023-01-04)[2024-04-30]. https://doi.org/10.1016/j.cose.2022.103084. |
| [18] | RADHAKRISHNAN P. Why Transformers are Slowly Replacing CNNs in Computer Vision?[EB/OL]. (2021-09-11)[2024-04-30]. https://becominghuman.ai/transformers-in-vision-e2e87b739feb. |
| [19] | LI M Q, FUNG B C M, CHARLAND P, et al. I-MAD: Interpretable Malware Detector Using Galaxy Transformer[EB/OL]. (2021-06-18)[2024-04-30]. https://doi.org/10.1016/j.cose.2021.102371. |
| [20] | RAHALI A, AKHLOUFI M. MalBERT: Using Transformers for Cybersecurity and Malicious Software Detection[EB/OL]. (2021-03-05)[2024-04-30]. |
| [21] | BU S J, CHO S B. Triplet-Trained Graph Transformer with Control Flow Graph for Few-Shot Malware Classification[EB/OL]. (2023-08-28)[2024-04-30]. https://doi.org/10.1016/j.ins.2023.119598. |
| [22] | DENG Xiaoheng, WANG Zhe, PEI Xinjun, et al. TransMalDE: An Effective Transformer Based Hierarchical Framework for IoT Malware Detection[J]. IEEE Transactions on Network Science and Engineering, 2024, 11(1): 140-151. |
| [23] | PARK K W, CHO S B. A Vision Transformer Enhanced with Patch Encoding for Malware Classification[C]// Springer. 23rd International Conference on Intelligent Data Engineering and Automated Learning-IDEAL 2022. Heidelberg: Springer, 2022: 289-299. |
| [24] | DEMIRKIRAN F, ÇAYIR A, ÜNAL U, et al. An Ensemble of Pre-Trained Transformer Models for Imbalanced Multiclass Malware Classification[EB/OL]. (2022-07-27)[2024-04-30]. https://doi.org/10.1016/j.cose.2022.102846. |
| [25] | VASAN D, ALAZAB M, WASSAN S, et al. IMCFN: Image-Based Malware Classification Using Fine-Tuned Convolutional Neural Network Architecture[EB/OL]. (2020-02-16)[2024-04-30]. https://doi.org/10.1016/j.comnet.2020.107138. |
| [26] | RAVI A, CHATURVEDI V, SHAFIQUE M. ViT4Mal: Lightweight Vision Transformer for Malware Detection on Edge Devices[J]. ACM Transactions on Embedded Computing Systems, 2023, 22(5s): 1-26. |
| [27] | BELAL M M, SUNDARAM D M. Global-Local Attention-Based Butterfly Vision Transformer for Visualization-Based Malware Classification[J]. IEEE Access, 2023, 11: 69337-69355. |
| [28] | FREITAS S, DUGGAL R, CHAU D H. MalNet: A Large-Scale Image Database of Malicious Software[C]// ACM. 31st ACM International Conference on Information & Knowledge Management. New York: ACM, 2022: 3948-3952. |
| [29] | SENEVIRATNE S, SHARIFFDEEN R, RASNAYAKA S, et al. Self-Supervised Vision Transformers for Malware Detection[J]. IEEE Access, 2022, 10: 103121-103135. |
| [30] | ZHANG Jinnian, PENG Houwen, WU Kan, et al. MiniViT: Compressing Vision Transformers with Weight Multiplexing[C]// IEEE. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2022: 12145-12154. |
| [31] | KHAN A, RAUF Z, SOHAIL A, et al. A Survey of the Vision Transformers and Their CNN-Transformer Based Variants[J]. Artificial Intelligence Review, 2023, 56(3): 2917-2970. |
| [32] | LOSHCHILOV I, HUTTER F. Decoupled Weight Decay Regularization[C]// ICLR. 7th International Conference on Learning Representations (ICLR 2019). Washington: ICLR, 2019(6): 4061-4078. |
| [33] | LOSHCHILOV I, HUTTER F. SGDR: Stochastic Gradient Descent with Warm Restarts[C]// ICLR. 5th International Conference on Learning Representations (ICLR 2017). Washington: ICLR, 2017(3): 1769-1784. |
| [34] | LIN T Y, GOYAL P, GIRSHICK R, et al. Focal Loss for Dense Object Detection[C]// IEEE. 2017 IEEE International Conference on Computer Vision (ICCV). New York: IEEE, 2017: 2999-3007. |
| [35] | CUI Yin, JIA Menglin, LIN T Y, et al. Class-Balanced Loss Based on Effective Number of Samples[C]// IEEE. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE, 2019: 9268-9277. |
| [36] | RONEN R, RADU M, FEUERSTEIN C, et al. Microsoft Malware Classification Challenge[EB/OL]. (2018-02-22)[2024-04-30]. https://arxiv.org/abs/1802.10135. |
| [37] | CAO Chang, CHICCO D, HOFFMAN M M. The MCC-F 1 Curve: A Performance Evaluation Technique for Binary Classification[EB/OL]. (2020-06-17)[2024-08-13]. https://arxiv.org/abs/2006.11278v1. |
| [38] | ASLAN Ö, YILMAZ A. A New Malware Classification Framework Based on Deep Learning Algorithms[J]. IEEE Access, 2021, 9: 87936-87951. |
| [39] | HEMALATHA J, ROSELINE S A, GEETHA S, et al. An Efficient DenseNet-Based Deep Learning Model for Malware Detection[EB/OL]. (2021-03-15)[2024-04-30]. https://doi.org/10.3390/e23030344. |
| [40] | KUMAR S, JANET B. DTMIC: Deep Transfer Learning for Malware Image Classification[EB/OL]. (2021-12-01)[2024-04-30]. https://doi.org/10.1016/j.jisa.2021.103063. |
| [41] | VASAN D, HAMMOUDEH M, ALAZAB M. Broad Learning: A GPU-Free Image-Based Malware Classification[EB/OL]. (2024-02-15)[2024-04-30]. https://doi.org/10.1016/j.asoc.2024.111401. |
| [42] | WONG W K, JUWONO F H, APRIONO C. Vision-Based Malware Detection: A Transfer Learning Approach Using Optimal ECOC-SVM Configuration[J]. IEEE Access, 2021, 9: 159262-159270. |
| [43] | BARROS P H, CHAGAS E T C, OLIVEIRA L B, et al. Malware-SMELL: A Zero-Shot Learning Strategy for Detecting Zero-Day Vulnerabilities[EB/OL]. (2022-06-03)[2024-04-30]. https://doi.org/10.1016/j.cose.2022.102785. |
| [44] | AL-KHATER W, AL-MADEED S. Using 3D-VGG-16 and 3D-Resnet-18 Deep Learning Models and FABEMD Techniques in the Detection of Malware[J]. Alexandria Engineering Journal, 2024, 89: 39-52. |
| [1] | LIU Jun, WU Zhichao, WU Jian, TAN Zhenhua. A Malicious Code Recognition Model Fusing Image Spatial Feature Attention Mechanism [J]. Netinfo Security, 2023, 23(12): 29-37. |
| [2] | LI Sicong, WANG Jian, SONG Yafei, HUANG Wei. Malicious Code Classification Method Based on BiTCN-DLP [J]. Netinfo Security, 2023, 23(11): 104-117. |
| [3] | FU Zhibin, QI Shuren, ZHANG Yushu, XUE Mingfu. Localization Network of Deep Inpainting Based on Dense Connectivity [J]. Netinfo Security, 2022, 22(7): 84-93. |
| [4] | LI Pengchao, LIU Yanfei. Research on Forensics Technology of Malicious Code Based on Deleted PE File Header [J]. Netinfo Security, 2021, 21(12): 38-43. |
| [5] | LIU Hong, ZHANG Yuejin, ZHAO Wenxia, YANG Mu. A Security Management Framework for Data Sensitivity and Multidimensional Classification [J]. Netinfo Security, 2021, 21(10): 48-53. |
| [6] | ZHU Chaoyang, ZHOU Liang, ZHU Yayun, LIN Qingwen. Malicious Code Visual Classification Algorithm Based on Behavior Knowledge Graph Sieve [J]. Netinfo Security, 2021, 21(10): 54-62. |
| [7] | WEN Weiping, CHEN Xiarun, YANG Fachang. Malicious Code Forensics Method Based on Hidden Behavior Characteristics of Rootkit on Linux [J]. Netinfo Security, 2020, 20(11): 32-42. |
| [8] | Man ZHAN, Hequn XIAN, Shuguang ZHANG. Research on Identity Authentication Technology Based on Gravity Sensor [J]. Netinfo Security, 2017, 17(9): 58-62. |
| [9] | Zhenfei ZHOU, Binxing FANG, Xiang CUI, Qixu LIU. A Method of Malicious Code Detection in WordPress Theme Based on Similarity Analysis [J]. Netinfo Security, 2017, 17(12): 47-53. |
| [10] | Jiawang ZHANG, Yanwei LI. Research and Design on Malware Detection System Based on N-gram Algorithm [J]. Netinfo Security, 2016, 16(8): 74-80. |
| [11] | Hong LIANG, Hui-yun ZHANG, Xin-guang XIAO. Analysis of E-mail Sample Correlation Based on Social Engineering [J]. Netinfo Security, 2015, 15(9): 180-185. |
| [12] | ZHANG Jun-hao, GU Yi-jun, ZHANG Shi-hao. The Microblogging User Influence Assessment Based on PageRank and User Behavior [J]. Netinfo Security, 2015, 15(6): 73-78. |
| [13] | ZHANG Fu-xia JIANG Chao-hui. Research on LBS(P,L,K) Model and Its Anonymous Algorithms [J]. Netinfo Security, 2015, 15(11): 66-70. |
| [14] | LI Jian, GUAN Wei-li, LIU Ji-qiang, WU Xing. The Model of Network Access Based on Trust Evaluation [J]. Netinfo Security, 2015, 15(10): 14-23. |
| [15] | CHEN Yi-fu, LIU Ji-qiang. Research of Signature Extraction Algorithms for Mobile Applications [J]. Netinfo Security, 2015, 15(1): 45-50. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||