信息网络安全 ›› 2026, Vol. 26 ›› Issue (5): 772-787.doi: 10.3969/j.issn.1671-1122.2026.05.009
基于多视图知识增强的大语言模型事实型幻觉优化方法
胡倾城, 张婉, 袁亚丽, 张静( )
)
东南大学网络空间安全学院 南京 211189
-
收稿日期:2025-12-08出版日期:2026-05-10发布日期:2026-06-03 -
通讯作者:张静 jingz@seu.edu.cn -
作者简介:胡倾城(2001—),女,安徽,硕士研究生,主要研究方向为大模型安全|张婉(2002—),女,安徽,博士研究生,主要研究方向为联邦学习|袁亚丽(1987—),女,河南,副教授,博士,CCF会员,主要研究方向为互联网安全|张静(1981—),男,安徽,教授,博士,CCF会员,主要研究方向为人工智能安全 -
基金资助:国家重点研发计划(2023YFB3106700);江苏省基础研究计划(BK20251747)
A Multi-View Knowledge-Enhanced Approach for Mitigating Factual Hallucinations in Large Language Models
HU Qingcheng, ZHANG Wan, YUAN Yali, ZHANG Jing()
School of Cyber Science and Engineering ,Southeast University Nanjing 211189, China
-
Received:2025-12-08Online:2026-05-10Published:2026-06-03
摘要:
事实型幻觉是指在大语言模型文本生成过程中出现的上下文不一致、与事实相悖的现象。幻觉问题不仅影响大语言模型生成文本的可靠性,还可能导致错误的信息传播,从而对用户决策产生负面影响。为应对这一挑战,文章提出一种新型基于多视图知识图谱(MVKG)和直接偏好优化(DPO)的幻觉缓解方法。该方法引入MVKG,并采用大语言模型更新知识图谱。同时,该方法采用多视图关键词联合检索机制,结合多视图直接偏好优化,以增强大语言模型对查询中多视图实体的提取能力,从而提高整体检索的相关性。实验结果表明,相比现有的检索增强生成方法,该方法在Qwen系列模型和闭源模型上均能显著提升问题回答准确率,有效缓解了大语言模型幻觉问题。
中图分类号:
引用本文
胡倾城, 张婉, 袁亚丽, 张静. 基于多视图知识增强的大语言模型事实型幻觉优化方法[J]. 信息网络安全, 2026, 26(5): 772-787.
HU Qingcheng, ZHANG Wan, YUAN Yali, ZHANG Jing. A Multi-View Knowledge-Enhanced Approach for Mitigating Factual Hallucinations in Large Language Models[J]. Netinfo Security, 2026, 26(5): 772-787.
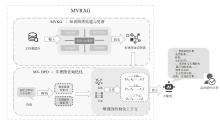
图1
基于知识图谱的LLM事实型幻觉缓解方法的框架
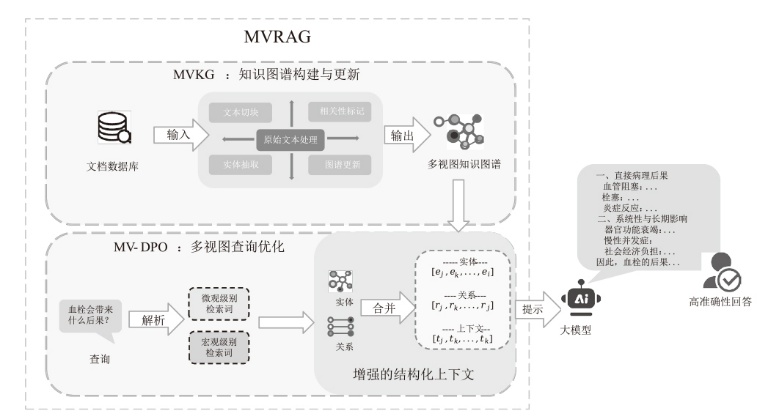
表1
偏好数据集构造类型示例
| 负样本类型 | 查询 | 优选响应 |
|---|---|---|
| 基线模型不准确输出 | What are the common methods for supervised learning | Macro:[learning paradigm, model type] Micro:[support vector machine,decision tree] |
| 逻辑问题: 层次错配 | Explain Newton’s laws of motion | Macro:[physical principles, force interaction] Micro:[inertia, F=ma] |
| 逻辑问题: 属性嫁接 | What are the functions of common cold medicines | Macro:[symptom relief, pathogen inhibition] Micro:[reduce fever,antiviral] |
| 逻辑问题: 概念泛化 | Compare different battery technologies | Macro:[energy density,cycle life] Micro:[lithium-ion,lead-acid] |
| 随机丢弃关键信息 | How does a content-based recommendation system work | Macro:[feature extraction, similarity matching] Micro:[TF-IDF,cosine similarity] |
| 负样本类型 | 劣选响应 | 构造逻辑说明 |
| 基线模型不准确输出 | Macro:[algorithm, method] Micro:[clustering,backpropagation] | 基础模型输出错误:微观词“Clustering”是无监督方法,“Backpropagation”是优化技术,均与“监督学习”查询不匹配 |
| 逻辑问题: 层次错配 | Macro:[Net force,vector superposition method] Micro:[inertia, F=ma] | 正确的微观关键词“矢量叠加”、“合力”被错误地关联到宏观主题之下 |
| 逻辑问题: 属性嫁接 | macro:[symptom relief, pathogen inhibition] Micro:[reduce fever,conductivity] | 将物理属性“conductivity”错误嫁接至药品功能的微观描述中,造成语义混淆 |
| 逻辑问题: 概念泛化 | Macro:[energy density,cycle life] Micro:[battery,technology] | 具体的技术实例被替换为过于空泛的上位词“Battery”和“Technology”,信息量严重不足 |
| 随机丢弃关键信息 | Macro:[feature extraction, similarity matching] Micro:[cosine similarity] | 随机制造信息残缺,此例中缺失了关键的文本相似度度量方法“TF-IDF” |
表2
Ultra Domain领域数据集分类信息
| 信息 | 农业 | 计算机 | 法律 | 混合 |
|---|---|---|---|---|
| 总文档数/个 | 12 | 10 | 94 | 61 |
| 总token数/个 | 2017886 | 2306535 | 5081069 | 619009 |
表3
模型在Ultra Domain问题上的 LLM Score评估
| 模型 | Naive RAG | GraphRAG | MemoRAG | MVRAG w/o MV-DPO | MVRAG with MV-DPO |
|---|---|---|---|---|---|
| Qwen3-8B | 54.0% | 68.7% | 63.7% | 72.9% | 74.6% |
| Qwen3-14B | 60.4% | 76.7% | 80.9% | 81.4% | 83.3% |
| ChatGPT-3.5 | 79.5% | 83.5% | 85.3% | 86.1% | — |
| gemini-2.0 | 80.1% | 88.6% | 89.0% | 89.2% | — |
表4
模型在Ultra-Domain各领域的LLM Score评估
| 模型 | Naive RAG | GraphRAG | ||||||
|---|---|---|---|---|---|---|---|---|
| 农业 | 计算机 | 法律 | 混合 | 农业 | 计算机 | 法律 | 混合 | |
| Qwen3-8B | 55.3% | 57.8% | 51.0% | 57.8% | 68.9% | 63.8% | 72.3% | 63.8% |
| Qwen3-14B | 61.8% | 64.6% | 57.0% | 64.6% | 77.0% | 71.3% | 80.8% | 71.3% |
| ChatGPT-3.5 | 75.3% | 78.1% | 80.9% | 78.4% | 81.7% | 75.8% | 85.5% | 82.1% |
| gemini-2.0 | 77.1% | 75.4% | 79.6% | 82.3% | 82.3% | 81.9% | 91.5% | 86.6% |
| 模型 | MemoRAG | MVRAG w/o MV-DPO | ||||||
| 农业 | 计算机 | 法律 | 混合 | 农业 | 计算机 | 法律 | 混合 | |
| Qwen3-8B | 69.3% | 51.2% | 64.9% | 62.7% | 73.1% | 68.0% | 76.5% | 68.0% |
| Qwen3-14B | 71.1% | 71.5% | 84.2% | 79.3% | 81.7% | 76.0% | 85.5% | 76.0% |
| ChatGPT-3.5 | 82.9% | 80.3% | 87.6% | 83.0% | 86.1% | 80.6% | 90.4% | 80.3% |
| gemini-2.0 | 89.1% | 85.2% | 93.7% | 82.4% | 89.7% | 77.1% | 94.1% | 83.6% |
| 模型 | MVRAG with MV-DPO | — | — | — | — | |||
| 农业 | 计算机 | 法律 | 混合 | — | — | — | — | |
| Qwen3-8B | 74.8% | 69.7% | 78.2% | 69.7% | — | — | — | — |
| Qwen3-14B | 83.6% | 77.9% | 87.4% | 77.9% | — | — | — | — |
| ChatGPT-3.5 | — | — | — | — | — | — | — | — |
| gemini-2.0 | — | — | — | — | — | — | — | — |

图2
MVRAG优越性具体示例

表5
不同模型在TruthfulQA回答任务上的性能
| 模型 | Naive RAG | GraphRAG | ||||
|---|---|---|---|---|---|---|
| LLM Score | MC1 Score | MC2 Score | LLM Score | MC1 Score | MC2 Score | |
| Qwen3-4B | 56.2% | 18.1% | 23.9% | 58.2% | 28.7% | 26.1% |
| Qwen3-8B | 52.3% | 21.4% | 33.1% | 55.0% | 25.2% | 36.4% |
| Qwen3-14B | 67.7% | 28.5% | 39.2% | 68.5% | 32.1% | 42.8% |
| ChatGPT-3.5 | 64.3% | 33.9% | 46.1% | 66.4% | 38.3% | 48.1% |
| gemini-2.0 | 69.2% | 45.8% | 37.9% | 69.8% | 48.9% | 43.3% |
| 模型 | MemoRAG | MVRAG | ||||
| LLM Score | MC1 Score | MC2 Score | LLM Score | MC1 Score | MC2 Score | |
| Qwen3-4B | 51.9% | 27.2% | 28.3% | 63.7% | 22.9% | 28.8% |
| Qwen3-8B | 56.8% | 29.1% | 37.2% | 58.5% | 28.4% | 39.1% |
| Qwen3-14B | 68.6% | 34.0% | 42.1% | 69.5% | 35.8% | 45.0% |
| ChatGPT-3.5 | 67.4% | 41.9% | 40.3% | 68.1% | 42.2% | 49.3% |
| gemini-2.0 | 68.2% | 50.2% | 44.5% | 73.1% | 49.6% | 45.1% |
表6
不同模型在FACTOR回答任务上的性能
| 模型 | Naive RAG | GraphRAG | ||
|---|---|---|---|---|
| LLM Score | Factor Acc | LLM Score | Factor Acc | |
| Qwen3-4B | 27.7% | 29.1% | 30.6% | 32.0% |
| Qwen3-8B | 37.3% | 31.4% | 43.3% | 35.1% |
| Qwen3-14B | 38.1% | 28.6% | 42.7% | 32.7% |
| ChatGPT-3.5 | 34.4% | 28.6% | 38.1% | 32.5% |
| gemini-2.0 | 45.2% | 36.3% | 41.9% | 40.5% |
| 模型 | MemoRAG | MemoRAG | ||
| LLM Score | Factor Acc | LLM Score | Factor Acc | |
| Qwen3-4B | 31.7% | 30.9% | 32.3% | 35.1% |
| Qwen3-8B | 42.5% | 36.9% | 43.9% | 38.7% |
| Qwen3-14B | 44.6% | 35.8% | 45.2% | 36.3% |
| ChatGPT-3.5 | 40.0% | 34.1% | 42.8% | 35.5% |
| gemini-2.0 | 45.6% | 45.7% | 50.9% | 45.6% |
表7
消融实验结果
| 模型 | MVRAG w/o MV-DPO -Macro | MVRAG w/o MV-DPO -Micro | MVRAG w/o MV-DPO | MVRAG with MV-DPO |
|---|---|---|---|---|
| Qwen3-4B | 52.0% | 62.5% | 63.2% | 64.7% |
| Qwen3-8B | 58.9% | 70.8% | 71.6% | 73.3% |
| Qwen3-14B | 65.9% | 79.1% | 80.0% | 81.9% |
| ChatGPT-3.5 | 69.8% | 83.6% | 84.6% | — |
| gemini-2.0 | 70.8% | 85.3% | 86.4% | — |
| [1] |
ZHANG Qintong, WANG Yuchao, WANG Hexi, et al. Comprehensive Review of Large Language Model Fine-Tuning[J]. Computer Engineering and Applications, 2024, 60(17): 17-33.
doi: 10.3778/j.issn.1002-8331.2312-0035 |
|
张钦彤, 王昱超, 王鹤羲, 等. 大语言模型微调技术的研究综述[J]. 计算机工程与应用, 2024, 60(17): 17-33.
doi: 10.3778/j.issn.1002-8331.2312-0035 |
|
| [2] |
ZHAO Yue, HE Jinwen, ZHU Shenchen, et al. Security of Large Language Models: Current Status and Challenges[J]. Computer Science, 2024, 51(1): 68-71.
doi: 10.11896/jsjkx.231100066 |
|
赵月, 何锦雯, 朱申辰, 等. 大语言模型安全现状与挑战[J]. 计算机科学, 2024, 51(1): 68-71.
doi: 10.11896/jsjkx.231100066 |
|
| [3] | HUANG Lei, YU Weijiang, MA Weitao, et al. A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions[J]. ACM Transactions on Information Systems, 2025, 43(2): 1-55. |
| [4] | ZHANG Wan, ZHANG Jing. Hallucination Mitigation for Retrieval-Augmented Large Language Models: A Review[EB/OL]. (2025-02-04)[2025-10-24]. https://doi.org/10.3390/math13050856. |
| [5] | HU Yuntong, LEI Zhihan, ZHANG Zheng, et al. GRAG: Graph Retrieval-Augmented Generation[C]//ACL. Findings of the Association for Computational Linguistics(NAACL 2025). Stroudsburg: ACL, 2025: 4145-4157. |
| [6] | LI Zijian, GUO Qingyan, SHAO Jiawei, et al. Graph Neural Network Enhanced Retrieval for Question Answering of Large Language Models[C]//ACL. The 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics:Human Language Technologies. Stroudsburg: ACL, 2025: 6612-6633. |
| [7] | LI Yuanzhi, BUBECK S, ELDAN R, et al. Textbooks Are All You Need II:Phi-1.5 Technical Report[EB/OL]. (2023-09-11)[2025-10-24]. https://arxiv.org/abs/2309.05463. |
| [8] | VISWANATH H, ZHANG Tianyi. FairPy: A Toolkit for Evaluation of Prediction Biases and Their Mitigation in Large Language Models[EB/OL]. (2025-04-15)[2025-10-24]. https://arxiv.org/abs/2302.05508. |
| [9] | ZHOU Chunting, NEUBIG G, GU Jiatao, et al. Detecting Hallucinated Content in Conditional Neural Sequence Generation[EB/OL]. ( 2021-06-02)[2025-10-24]. https://arxiv.org/abs/2011.02593. |
| [10] | CHEN Yuyan, FU Qiang, YUAN Yichen, et al.Hallucination Detection: Robustly Discerning Reliable Answers in Large Language Models[C]//ACM. The 32nd ACM International Conference on Information and Knowledge Management. New York: ACM, 2023: 245-255. |
| [11] |
MCINTOSH T R, SUSNJAK T, LIU Tong, et al. The Inadequacy of Reinforcement Learning from Human Feedback—Radicalizing Large Language Models via Semantic Vulnerabilities[J]. IEEE Transactions on Cognitive and Developmental Systems, 2024, 16(4): 1561-1574.
doi: 10.1109/TCDS.2024.3377445 URL |
| [12] | WEI J, HUANG Da, LU Yifeng, et al. Simple Synthetic Data Reduces Sycophancy in Large Language Models[EB/OL]. (2024-02-15)[2025-10-24]. https://arxiv.org/abs/2308.03958. |
| [13] | BIAN Ce, CHEN Boyuan, DAI J, et al.BeaverTails: Towards Improved Safety Alignment of LLM via a Human-Preference Dataset[C]//NeurIPS. Neural Information Processing Systems Foundation. New York: NeurIPS, 2023: 24678-24704. |
| [14] | SUN Zhiqing, SHEN Sheng, CAO Shengcao, et al.Aligning Large Multimodal Models with Factually Augmented RLHF[C]//ACL. Findings of the Association for Computational Linguistics (ACL 2024). Stroudsburg: ACL, 2024: 13088-13110. |
| [15] | CHUANG Y S, XIE Yujia, LUO Hongyin, et al. DoLa: Decoding by Contrasting Layers Improves Factuality in Large Language Models[EB/OL]. [2025-10-24]. https://arxiv.org/pdf/2309.03883. |
| [16] | LI Junyi, NG H T. Reasoning Models Hallucinate More: Factuality-Aware Reinforcement Learning for Large Reasoning Models[EB/OL]. (2025-05-30)[2025-10-24]. https://arxiv.org/abs/2505.24630. |
| [17] | LI K, PATEL O, VIÉGAS F, et al. Inference-Time Intervention: Eliciting Truthful Answers from a Language Model[EB/OL]. (2024-06-26)[2025-10-24]. https://arxiv.org/abs/2306.03341. |
| [18] | CUI Jiaxi, NING Munan, LI Zongjian, et al. Chatlaw: A Multi-Agent Collaborative Legal Assistant with Knowledge Graph Enhanced Mixture-of-Experts Large Language Model[EB/OL]. (2024-05-30)[2025-10-24].https://arxiv.org/abs/2306.16092. |
| [19] | LIU Hualing, ZHANG Zilong, PENG Hongshuai. Review of Enhancement Research for Closed-Source Large Language Model[J]. Journal of Frontiers of Computer Science and Technology, 2025, 19(5): 1141-1156. |
|
刘华玲, 张子龙, 彭宏帅. 面向闭源大语言模型的增强研究综述[J]. 计算机科学与探索, 2025, 19(5): 1141-1156.
doi: 10.3778/j.issn.1673-9418.2407021 |
|
| [20] | BOSMA M, CHI E, ICHTER B, et al. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models[C]//NeurIPS. Neural Information Processing Systems Foundation, New York: NeurIPS, 2022: 24824-24837. |
| [21] | ASAI A, WU Zeqiu, WANG Yizhong, et al. Self-RAG: Learning to Retrieve, Generate, and Critique Through Self-Reflection[EB/OL]. [2025-10-24]. https://arxiv.org/pdf/2310.11511v1. |
| [22] | TRIVEDI H, BALASUBRAMANIAN N, KHOT T, et al. Interleaving Retrieval with Chain-of-Thought Reasoning for Knowledge-Intensive Multi-Step Questions[C]//ACL. The 61st Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2023: 10014-10037. |
| [23] | KONG Lingfei, WANG Gang, LIU Naiwei, et al. A Retrieval-Augmented Generation Method Based on Intent Analysis and Ranking Fusion[C]//IEEE. 2024 7th International Conference on Data Science and Information Technology (DSIT). New York: IEEE, 2024: 1-8. |
| [24] | WU Wenlong, WANG Haofen, LI Bohan, et al. MultiRAG: A Knowledge-Guided Framework for Mitigating Hallucination in Multi-Source Retrieval Augmented Generation[C]//IEEE. 2025 IEEE 41st International Conference on Data Engineering (ICDE). New York: IEEE, 2025: 3070-3083. |
| [25] | ZHENG Qiang, XU Zhenbin. LLM-KG Bidirectional Inference Optimization and Hallucination Suppression for Special Equipment[J]. Journal of Data Acquisition and Processing, 2025, 40(3): 647-658. |
| 郑强, 许振彬. 面向特种设备的大语言模型-知识图谱双向推理优化与幻觉抑制方法[J]. 数据采集与处理, 2025, 40(3): 647-658. | |
| [26] | ABDEL HAMID M R, EL-REGAILY S A, AREF M M. Can Large Language Models Perform Retrieval-Augmented Generation as Multi-Hop Reasoning over Knowledge Graphs[C]//IEEE. 2025 International Mobile, Intelligent, and Ubiquitous Computing Conference (MIUCC). New York: IEEE, 2025: 360-365. |
| [27] | LIU Lihui, HILL B, DU Boxin, et al.Conversational Question Answering with Language Models Generated Reformulations over Knowledge Graph[C]//ACL. Findings of the Association for Computational Linguistics (ACL 2024). Stroudsburg: ACL, 2024: 839-850. |
| [28] | GUO Zirui, XIA Lianghao, YU Yanhua, et al. LightRAG: Simple and Fast Retrieval-Augmented Generation[EB/OL]. (2025-04-28)[2025-10-24]. https://arxiv.org/abs/2410.05779. |
| [29] | EDGE D, TRINH H, CHENG N, et al. From Local to Global: A Graph RAG Approach to Query-Focused Summarization[EB/OL]. (2025-02-19)[2025-10-24]. https://arxiv.org/abs/2404.16130. |
| [30] | QIAN Hongjin, LIU Zheng, ZHANG Peitian, et al. MemoRAG: Boosting Long Context Processing with Global Memory-Enhanced Retrieval Augmentation[C]//ACM. The ACM on Web Conference 2025. New York:ACM, 2025: 2366-2377. |
| [31] | ERMON S, FINN C, MANNING C D, et al. Direct Preference Optimization: Your Language Model is Secretly a Reward Model[C]//NeurIPS. Neural Information Processing Systems Foundation. New York: NeurIPS, 2023: 53728-53741. |
| [32] | VRANDEČIĆ D, KRÖTZSCH M. Wikidata: A Free Collaborative Knowledgebase[J]. Communications of the ACM, 2014, 57(10): 78-85. |
| [33] | YANG Yi, YIH W T, MEEK C. WikiQA: A Challenge Dataset for Open-Domain Question Answering[C]//ACL. The 2015 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2015: 2013-2018. |
| [34] | LIN S, HILTON J, EVANS O. TruthfulQA: Measuring how Models Mimic Human Falsehoods[C]//ACL. The 60th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2022: 3214-3252. |
| [35] | MUHLGAY D, RAM O, MAGAR I, et al. Generating Benchmarks for Factuality Evaluation of Language Models[C]//ACL. The 18th Conference of the European Chapter of the Association for Computational Linguistics. Stroudsburg: ACL, 2024: 49-66. |
| [36] | KWON W, LI Zhuohan, ZHUANG Siyuan, et al. Efficient Memory Management for Large Language Model Serving with PagedAttention[EB/OL]. (2023-09-12)[2025-10-24]. https://arxiv.org/abs/2309.06180. |
| [37] | ZHENG Yaowei, ZHANG Richong, ZHANG Junhao, et al. LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models[C]//ACL. The 62nd Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2024: 400-410. |
| [38] | YANG An, LI Anfeng, YANG Baosong, et al. Qwen3 Technical Report[EB/OL]. (2025-05-14)[2025-10-24]. https://arxiv.org/abs/2505.09388. |
| [39] | XU Can, SUN Qingfeng, ZHENG Kai, et al. WizardLM: Empowering Large Pre-Trained Language Models to Follow Complex Instructions[EB/OL]. (2025-05-27)[2025-10-24]. https://arxiv.org/abs/2304.12244. |
| [1] | 许智双, 张昆, 范俊超, 常晓林. 基于本体的网络安全知识图谱构建方法[J]. 信息网络安全, 2025, 25(3): 451-466. |
| [2] | 秦振凯, 徐铭朝, 蒋萍. 基于提示学习的案件知识图谱构建方法及应用研究[J]. 信息网络安全, 2024, 24(11): 1773-1782. |
| [3] | 浦珺妍, 李亚辉, 周纯杰. 基于概率攻击图的工控系统跨域动态安全风险分析方法[J]. 信息网络安全, 2023, 23(9): 85-94. |
| [4] | 王晓狄, 黄诚, 刘嘉勇. 面向网络安全开源情报的知识图谱研究综述[J]. 信息网络安全, 2023, 23(6): 11-21. |
| [5] | 朱朝阳, 周亮, 朱亚运, 林晴雯. 基于行为图谱筛的恶意代码可视化分类算法[J]. 信息网络安全, 2021, 21(10): 54-62. |
| [6] | 刘红, 谢永恒, 王国威, 蒋帅. 基于跨领域本体的信息安全分析[J]. 信息网络安全, 2020, 20(9): 82-86. |
| [7] | 陶源, 黄涛, 李末岩, 胡巍. 基于知识图谱驱动的网络安全等级保护日志审计分析模型研究[J]. 信息网络安全, 2020, 20(1): 46-51. |
| [8] | 高孟茹, 谢方军, 董红琴, 林祥. 面向关键信息基础设施的网络安全评价体系研究[J]. 信息网络安全, 2019, 19(9): 111-114. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||