信息网络安全 ›› 2024, Vol. 24 ›› Issue (7): 1076-1087.doi: 10.3969/j.issn.1671-1122.2024.07.009
基于预训练模型和中英文威胁情报的TTP识别方法研究
任昌禹1, 张玲2, 姬航远1, 杨立群3( )
)
- 1.北京航空航天大学复杂关键软件环境全国重点实验室,北京 100083
2.郑州大学电气与信息工程学院,郑州 450001
3.北京航空航天大学网络空间安全学院,北京 100083
-
收稿日期:2024-04-03出版日期:2024-07-10发布日期:2024-08-02 -
通讯作者:杨立群lqyang@buaa.edu.cn -
作者简介:任昌禹(2000—),男,山西,硕士研究生,主要研究方向为信息抽取、大语言模型|张玲(1976—),女,安徽,副教授,博士,主要研究方向为数据挖掘|姬航远(1996—),男,河南,硕士研究生,主要研究方向为大语言模型、网络信息安全|杨立群(1990—),男,河北,讲师,博士,主要研究方向为网络信息安全、工业互联网、数字孪生和人工智能。 -
基金资助:国家自然科学基金(U2333205);国家自然科学基金(62302025);国家自然科学基金(62276017);2022年度CCF-绿盟科技鲲鹏科研基金及上海可信工控平台开放项目(CCF-NSFOCUS202210)
Research on TTP Extraction Method Based on Pre-Trained Language Model and Chinese-English Threat Intelligence
REN Changyu1, ZHANG Ling2, JI Hangyuan1, YANG Liqun3()
- 1. State Key Laboratory of Complex & Critical Software Environment, Beihang University, Beijing 100083, China
2. School of Electrical Engineering, Zhengzhou University, Zhengzhou 450001, China
3. School of Cyber Science and Technology, Beihang University, Beijing 100083, China
-
Received:2024-04-03Online:2024-07-10Published:2024-08-02
摘要:
TTP情报主要存在于非结构化的威胁报告中,是一种具有重要价值的网络威胁情报。然而,目前开源的TTP分类标签数据集主要集中在英文领域,涵盖的语料来源与TTP种类较为有限,特别是缺乏中文领域的相关数据。针对该情况,文章构建了一个中英文TTP情报数据集BTICD,该数据集包含17700条样本数据与236种对应的TTP。BTICD首次利用了公开的中文威胁报告语料进行TTP标注,且标注了一部分无法映射到任何一种TTP的白样本数据。文章基于预训练模型构建,并在该双语数据集上微调得到双语TTP识别模型SecBiBERT。实验结果表明,SecBiBERT在50种常见TTP分类任务上的Micro F1分数达到86.49%,在全量236类TTP分类任务上Micro F1分数达到73.09%,识别性能表现良好。
中图分类号:
引用本文
任昌禹, 张玲, 姬航远, 杨立群. 基于预训练模型和中英文威胁情报的TTP识别方法研究[J]. 信息网络安全, 2024, 24(7): 1076-1087.
REN Changyu, ZHANG Ling, JI Hangyuan, YANG Liqun. Research on TTP Extraction Method Based on Pre-Trained Language Model and Chinese-English Threat Intelligence[J]. Netinfo Security, 2024, 24(7): 1076-1087.
表1
数据集基本参数
| 参数名称 | 参数值 |
|---|---|
| 样本总数 | 17700条 |
| 中文样本数 | 8877条 |
| 英文样本数 | 8823条 |
| 样本平均长度 | 24.14词/条 |
| 样本最大长度 | 142词/条 |
| 样本最小长度 | 4词/条 |
| 单词总数 | 427263个 |
表2
各TTP开源数据集对比
| 数据集 | 语种 | 样本数/条 | TTP类别数/种 |
|---|---|---|---|
| TRAM[ | 英文 | 4070 | 50 |
| 文献[5]数据集 | 英文 | 12945 | 188 |
| TTPHunter[ | 英文 | 8387 | 50 |
| BTICD(本文) | 中文、英文 | 17700(含353条白样本) | 236(含白标签) |

图1
数据集标签分布
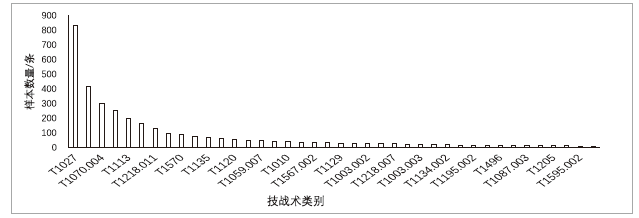
表3
TTP标注示例
| 样本内容 | TTP标注 |
|---|---|
| downpaper使用powershell执行 | T1059.001 |
| 植入ngrok反向代理 | T1090 |
| netboy and revbshell, gather system information | T1082 |
| hawkball 创建了一个 cmd.exe 反向 shell,执行命令并通过命令行上传输出 | T1059.003 |
| apt28 has used compromised email accounts to send credential phishing emails | T1586.002 |
| blacklotus 尝试使用合法文件名隐藏其部署在 esp 上的文件,例如 grubx64.efi(如果在受感染计算机上启用了 uefi 安全启动)或 bootmgfw.efi(如果在受感染计算机上禁用了 uefi 安全启动) | T1036.005 |
| apt32 has used scheduled task raw xml with a backdated timestamp of june 2, 2016. the group has also set the creation time of the files dropped by the second stage of the exploit to match the creation time of kernel32.dll. additionally, apt32 has used a random value to modify the timestamp of the file storing the clientid | T1070.006 |
| 当文件执行时,Windows 不会自动加载此数据,因为它位于 pe 结构之外 | white |
| 15c87b1820b67d4d2b082e81fd7946dd00a1072441b7551e38fccd5575bf18c2 | white |
| In january 2023, there was a significant 41% decrease in ransomware victim posting rates across all groups compared to december 2022, signaling an overall decline in ransomware activities | white |
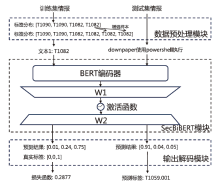
图2
算法框架

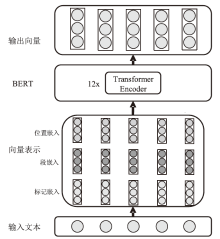
图3
BERT模型结构
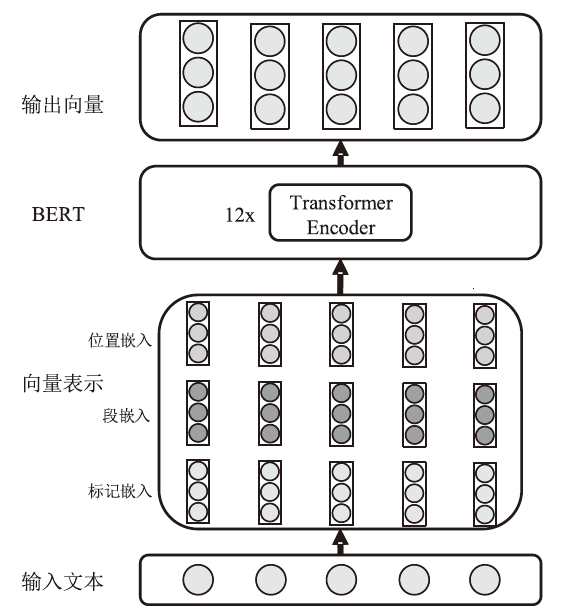
表4
数据集描述
| 划分 | 中文样本数/条 | 英文样本数/条 | 样本总数/条 | TTP类别数/种 |
|---|---|---|---|---|
| 训练集 | 7028 | 7037 | 14065 | 236 |
| 测试集 | 1849 | 1786 | 3635 | 236 |
表5
超参数设置
| 参数名称 | 参数值 |
|---|---|
| 文本特征向量维度 | 768 |
| 优化器 | Adam |
| 学习率 | 5e-5 |
| 损失函数 | Focal loss |
| 批次大小(条/批次) | 12 |
表6
不同分类模型在本文中英TTP数据集上的性能
| 模型 | Acc | Macro P | Macro R | Macro F1 |
|---|---|---|---|---|
| BERT-base | 66.80% | 56.32% | 56.25% | 53.90% |
| BERT-base-chinese | 71.06% | 62.95% | 60.10% | 59.28% |
| SecBERT | 66.80% | 56.32% | 56.25% | 53.90% |
| SecBERT-Plus | 63.66% | 55.89% | 52.67% | 51.37% |
| SciBERT | 66.80% | 54.96% | 52.00% | 51.09% |
| SecBiBERT(本文) | 73.09% | 65.90% | 62.85% | 61.85% |
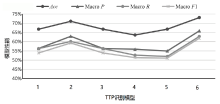
图4
不同分类模型在本文中英TTP数据集结果情况
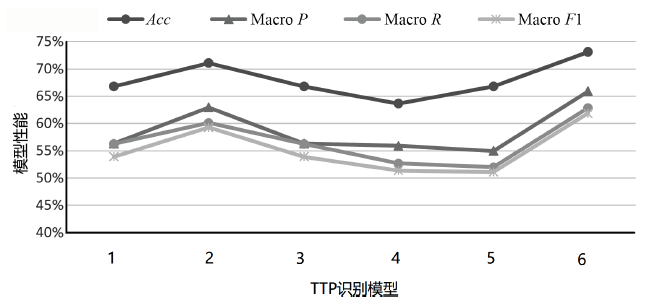
表7
不同分类模型在不同TTP类别数下的性能
| 模型 | K /种 | Micro F1 | Macro P | Macro R | Macro F1 |
|---|---|---|---|---|---|
| TCENet[ | 6 | 94.10% | 97.00% | 97.30% | 97.10% |
| SciBERT[ | 50 | 88.20% | 83.80% | 80.60% | 81.40% |
| SecBiBERT | 50 | 86.49% | 86.79% | 86.57% | 86.41% |
| SecBiBERT | 100 | 81.00% | 79.87% | 77.76% | 77.99% |
| SecBiBERT | 120 | 80.14% | 77.87% | 75.58% | 75.33% |
| SecBiBERT | 150 | 74.92% | 73.25% | 72.49% | 70.85% |
| SecureBERT[ | 188 | 72.50% | — | — | — |
| SecBiBERT | 200 | 71.99% | 65.33% | 64.34% | 62.81% |
| rcATT[ | 215 | 21.14%* | 81.73% | 8.21% | 14.92%* |
| SecBiBERT | 236 | 73.09% | 65.90% | 62.85% | 61.85% |
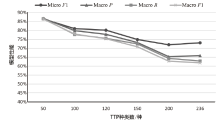
图5
本文模型在不同TTP类别数下的性能
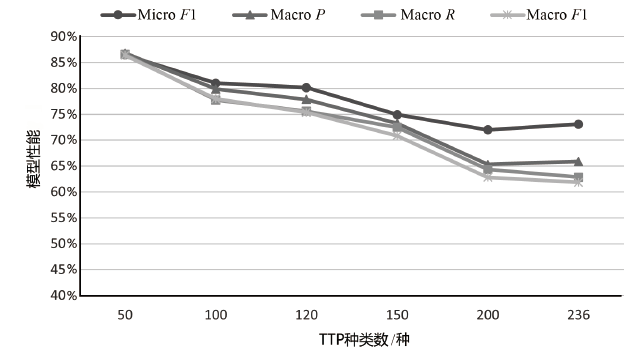
表8
不同语言资源下SecBiBERT的性能
| 序号 | 训练集 语种 | 测试集 语种 | Acc | Macro P | Macro R | Macro F1 |
|---|---|---|---|---|---|---|
| 1 | 英文 | 中文 | 31.68% | 30.34% | 23.77% | 23.03% |
| 2 | 中文 | 中文 | 68.09% | 55.39% | 52.90% | 50.97% |
| 3 | 中文、英文 | 中文 | 71.35% | 63.53% | 60.08% | 58.97% |
| 4 | 中文 | 英文 | 29.30% | 30.53% | 30.17% | 24.82% |
| 5 | 英文 | 英文 | 71.28% | 58.92% | 60.75% | 56.81% |
| 6 | 中文、英文 | 英文 | 73.87% | 65.66% | 63.76% | 62.32% |
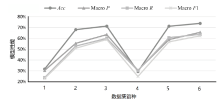
图6
不同语言资源测试结果情况
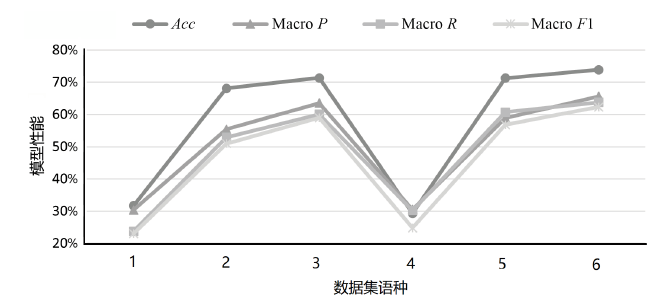
表9
SecBiBERT在不同TTP规模下的白标签识别性能
| K/种 | P | R | F1 | Micro F1(不含 白标签) | Macro F1 (不含 白标签) | Micro F1(含白标签) | Macro F1 (含白 标签) |
|---|---|---|---|---|---|---|---|
| 51 | 74.03% | 80.28% | 77.03% | 86.68% | 85.15% | 86.49% | 86.41% |
| 101 | 70.89% | 78.87% | 74.67% | 81.05% | 77.39% | 81.00% | 77.99% |
| 121 | 63.53% | 76.06% | 69.23% | 80.23% | 74.91% | 80.14% | 75.33% |
| 201 | 76.92% | 56.34% | 65.04% | 72.19% | 60.84% | 71.99% | 62.81% |
| 236 | 67.14% | 66.20% | 66.67% | 73.23% | 61.71% | 73.09% | 61.85% |

图7
不同类别数目下对白标签样本识别结果
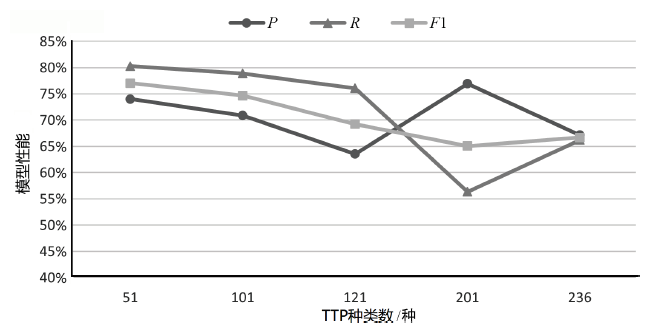

图8
模型在不同TTP规模测试集的性能(测试集不含白标签)
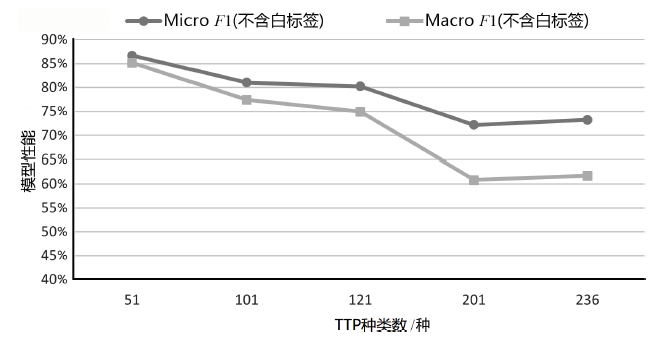
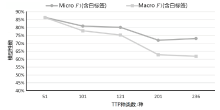
图9
模型在不同TTP规模测试集的性能(测试集含白标签)
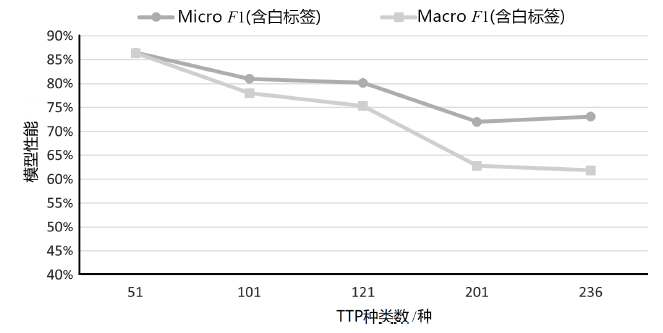
表10
SecBiBERT消融实验结果
| 模型 | Acc | Macro P | Macro R | Macro F1 |
|---|---|---|---|---|
| SecBiBERT | 73.09% | 65.90% | 62.85% | 61.85% |
| 不使用数据增强 | 4.57% | 0.02% | 0.42% | 0.04% |
| 不使用Focal Loss作为损失函数 | 66.85% | 60.74% | 59.52% | 56.94% |
| 不使用分类器 | 61.05% | 53.41% | 54.26% | 51.10% |
| 数据集中不添加白样本 | 69.93% | 61.96% | 62.78% | 60.11% |
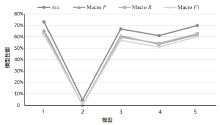
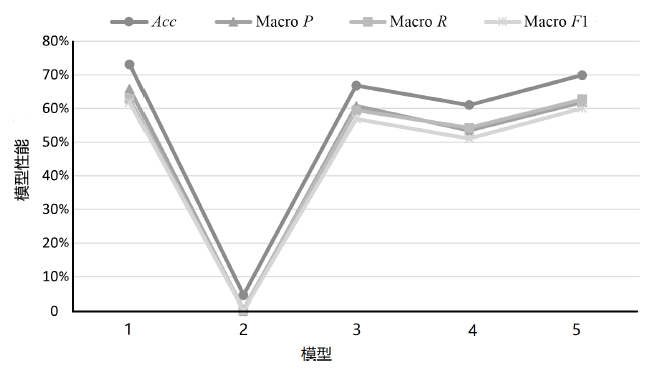
图10
不同模块对结果影响情况
| [1] | STROM B E, APPLEBAUM A, MILLER D P, et al. MITRE ATT&CK: Design and Philosophy[M]. Technical Report: The MITRE Corporation, 2018. |
| [2] | SHIN Y, KIM K, LEE J J, et al. ART: Automated Reclassification for Threat Actors Based on ATT&CK Matrix Similarity[C]// IEEE. 2021 World Automation Congress (WAC). New York: IEEE, 2021: 15-20. |
| [3] | JON B. Our TRAM Large Language Model Automates TTP Identification in CTI Reports[R]. Virginia: MITRE Engenuity, CT0075, 2023. |
| [4] | YOU Yizhe, JIANG Jun, JIANG Zhengwei, et al. TIM: Threat Context-Enhanced TTP Intelligence Mining on Unstructured Threat Data[J]. Cybersecurity, 2022, 5(1): 2523-3246. |
| [5] | ORBINATO V, BARBARACI M, NATELLA R, et al. Automatic Mapping of Unstructured Cyber Threat Intelligence: An Experimental Study: (Practical Experience Report)[C]// IEEE. 2022 IEEE 33rd International Symposium on Software Reliability Engineering (ISSRE). New York: IEEE, 2022: 181-192. |
| [6] | LEGOY V, CASELLI M, SEIFERT C, et al. Automated Retrieval of Att&CK Tactics and Techniques for Cyber Threat Reports[EB/OL]. (2020-04-29)[2024-03-30]. https://arxiv.org/abs/2004.14322. |
| [7] | MARCHIORI F, CONTI M, VERDE N V. Stixnet: A Novel and Modular Solution for Extracting All Stix Objects in Cti Reports[C]// ACM. Proceedings of the 18th International Conference on Availability, Reliability and Security. New York: ACM, 2023: 1-11. |
| [8] | ABDEEN B, AL-SHAER E, SINGHAL A, et al. Smet: Semantic Mapping of Cve to ATT&CK and Its Application to Cybersecurity[C]// Springer. IFIP Annual Conference on Data and Applications Security and Privacy. Heidelberg: Springer, 2023: 243-260. |
| [9] | QIHOO360. Luwak TTP Extractor[EB/OL]. (2023-07-09)[2024-03-30]. https://github.com/Qihoo360/Luwak/tree/master. |
| [10] | RANI N, SAHA B, MAURYA V, et al. TTPHunter: Automated Extraction of Actionable Intelligence as TTPs from Narrative Threat Reports[C]// ACM. Proceedings of the 2023 Australasian Computer Science Week. New York: ACM, 2023: 126-134. |
| [11] | RANI N, SAHA B, MAURYA V, et al. TTPXHunter: Actionable Threat Intelligence Extraction as TTPs form Finished Cyber Threat Reports[EB/OL]. (2024-03-05)[2024-03-30]. https://arxiv.org/abs/2403.03267. |
| [12] | WU Shangyuan, SHEN Guowei, GUO Chun, et al. Threat Intelligence-Driven Dynamic Threat Hunting Method[J]. Netinfo Security, 2023, 23(6): 91-103. |
| 吴尚远, 申国伟, 郭春, 等. 威胁情报驱动的动态威胁狩猎方法[J]. 信息网络安全, 2023, 23(6):91-103. | |
| [13] | AJMAL A B, ALAM M, KHALIQ A A, et al. Last Line of Defense: Reliability through Inducing Cyber Threat Hunting with Deception in Scada Networks[J]. IEEE Access, 2021, 9: 126789-126800. |
| [14] | BINDRA A. Securing the Power Grid: Protecting Smart Grids and Connected Power Systems from Cyberattacks[J]. IEEE Power Electronics Magazine, 2017, 4(3): 20-27. |
| [15] | ZHOU Yinghai, REN Yitong, YI Ming, et al. Cdtier: A Chinese Dataset of Threat Intelligence Entity Relationships[J]. IEEE Transactions on Sustainable Computing, 2023, 8(4): 627-638. |
| [16] | DEVLIN J, CHANG M W, LEE K, et al. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding[C]// ACL. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies, Volume 1 (Long and Short Papers). Minneapolis: ACL, 2019: 4171-4186. |
| [17] | SUN Hongzhe, WANG Jian, WANG Peng, et al. Network Intrusion Detection Method Based on Attention-BiTCN[J]. Netinfo Security, 2024, 24(2): 309-318. |
| 孙红哲, 王坚, 王鹏, 等. 基于Attention-BiTCN的网络入侵检测方法[J]. 信息网络安全, 2024, 24(2):309-318. | |
| [18] | HENDRYCKS D, GIMPEL K. Gaussian Error Linear Units (GELUs)[EB/OL]. (2016-06-27)[2024-03-30]. https://arxiv.org/abs/1606.08415. |
| [19] | LIN T Y, GOYAL P, GIRSHICK R, et al. Focal Loss for Dense Object Detection[C]// IEEE. 2017 IEEE International Conference on Computer Vision (ICCV). New York: IEEE, 2017: 2999-3007. |
| [20] | LIU Yinhan, OTT M, GOYAL N, et al. Roberta: A Robustly Optimized Bert Pretraining Approach[EB/OL]. (2019-07-26)[2024-03-30]. https://arxiv.org/abs/1907.11692. |
| [1] | 问闻, 刘钦菊, 邝琳, 任雪静. 隐私保护体系下网络威胁情报共享的研究现状和方案设计[J]. 信息网络安全, 2024, 24(7): 1129-1137. |
| [2] | 苑文昕, 陈兴蜀, 朱毅, 曾雪梅. 基于深度学习的HTTP负载隐蔽信道检测方法[J]. 信息网络安全, 2023, 23(7): 53-63. |
| [3] | 吴尚远, 申国伟, 郭春, 陈意. 威胁情报驱动的动态威胁狩猎方法[J]. 信息网络安全, 2023, 23(6): 91-103. |
| [4] | 陈立全, 薛雨欣, 江英华, 朱雅晴. 基于国密SM2算法的证书透明日志系统设计[J]. 信息网络安全, 2023, 23(11): 9-16. |
| [5] | 叶桓荣, 李牧远, 姜波. 基于迁移学习和威胁情报的DGA恶意域名检测方法研究[J]. 信息网络安全, 2023, 23(10): 8-15. |
| [6] | 冯景瑜, 张琪, 黄文华, 韩刚. 基于跨链交互的网络安全威胁情报共享方案[J]. 信息网络安全, 2022, 22(5): 21-29. |
| [7] | 程顺航, 李志华. 基于MRC的威胁情报实体识别方法研究[J]. 信息网络安全, 2021, 21(10): 76-82. |
| [8] | 陈骋, 罗森林, 吴倩, 杨鹏. 基于HTTP协议组合的隐蔽信道构建方法研究[J]. 信息网络安全, 2020, 20(6): 57-64. |
| [9] | 张永生, 王志, 武艺杰, 杜振华. 基于Conformal Prediction的威胁情报繁殖方法[J]. 信息网络安全, 2020, 20(6): 90-95. |
| [10] | 王长杰, 李志华, 张叶. 一种针对恶意软件家族的威胁情报生成方法[J]. 信息网络安全, 2020, 20(12): 83-90. |
| [11] | 唐屹, 王志双. 网银HTTPS协议的配置状况研究[J]. 信息网络安全, 2017, 17(1): 16-22. |
| [12] | 管磊, 胡光俊, 王专. 基于大数据的网络安全态势感知技术研究[J]. 信息网络安全, 2016, 16(9): 45-50. |
| [13] | 徐丽萍, 郝文江. 美国政企网络威胁情报现状及对我国的启示[J]. 信息网络安全, 2016, 16(9): 278-284. |
| [14] | 赵国锋, 陈勇, 王新恒. 针对HTTPS的Web前端劫持及防御研究[J]. 信息网络安全, 2016, 16(3): 15-20. |
| [15] | 阳风帆, 刘嘉勇, 汤殿华. 基于脚本注入的HTTPS会话劫持研究[J]. 信息网络安全, 2015, 15(3): 59-63. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||