信息网络安全 ›› 2026, Vol. 26 ›› Issue (4): 605-614.doi: 10.3969/j.issn.1671-1122.2026.04.008
面向派生定密的图神经网络文本匹配模型研究
于淼1,2, 郭松辉1( ), 宋帅超1, 杨烨铭1
), 宋帅超1, 杨烨铭1
- 1
网络空间部队信息工程大学密码工程学院 郑州 450001
295861 部队 酒泉 735018
-
收稿日期:2025-05-12出版日期:2026-04-10发布日期:2026-04-29 -
通讯作者:郭松辉 E-mail:songhui.guo@outlook.com -
作者简介:于淼(1987—),男,黑龙江,工程师,硕士,CCF会员,主要研究方向为自然语言处理|郭松辉(1979—),男,四川,研究员,博士,CCF会员,主要研究方向为人工智能安全和云计算安全|宋帅超(2000—),男,河南,博士研究生,CCF会员,主要研究方向为人工智能安全和生物特征安全|杨烨铭(1999—),男,河南,博士研究生,CCF会员,主要研究方向为人工智能安全和后量子安全 -
基金资助:国家自然科学基金(62176265)
Research on Graph Neural Network Text Matching Model for Derivative Classification
YU Miao1,2, GUO Songhui1(), SONG Shuaichao1, YANG Yeming1
- 1
School of Cryptography Engineering ,Cyberspace Force Information Engineering University Zhengzhou 450001, China
295861 PLA Unit, Jiuquan 735018, China
-
Received:2025-05-12Online:2026-04-10Published:2026-04-29
摘要:
派生定密是根据文本语义相似程度判断密级的定密方式,一般被抽象为文本匹配任务。由于待定密文本普遍具有篇幅较长、密点特征稀疏、语义结构复杂等特点,传统文本匹配方法难以准确建模和捕获文本中包含涉密事项语义的密点特征,因此,文章提出一种面向派生定密的图神经网络文本匹配模型,将文本匹配转化为图匹配问题。首先,设计密点特征提取器,将文本建模为表示密点特征的匹配图,以解决待定密文本密点特征表示能力弱的问题。然后,设计分层化图神经网络,对编码后的匹配图进行多轮更新和聚合操作,以增强对待定密文本之间相似性特征的提取。最后,根据匹配图的边预测文本定密结果。实验结果表明,在模拟派生定密数据集上,该模型性能提升明显,准确率提升4.77%以上,F1值提升3.83%以上。
中图分类号:
引用本文
于淼, 郭松辉, 宋帅超, 杨烨铭. 面向派生定密的图神经网络文本匹配模型研究[J]. 信息网络安全, 2026, 26(4): 605-614.
YU Miao, GUO Songhui, SONG Shuaichao, YANG Yeming. Research on Graph Neural Network Text Matching Model for Derivative Classification[J]. Netinfo Security, 2026, 26(4): 605-614.
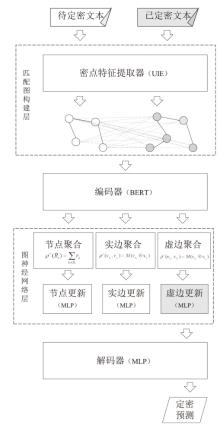
图1
本文模型架构
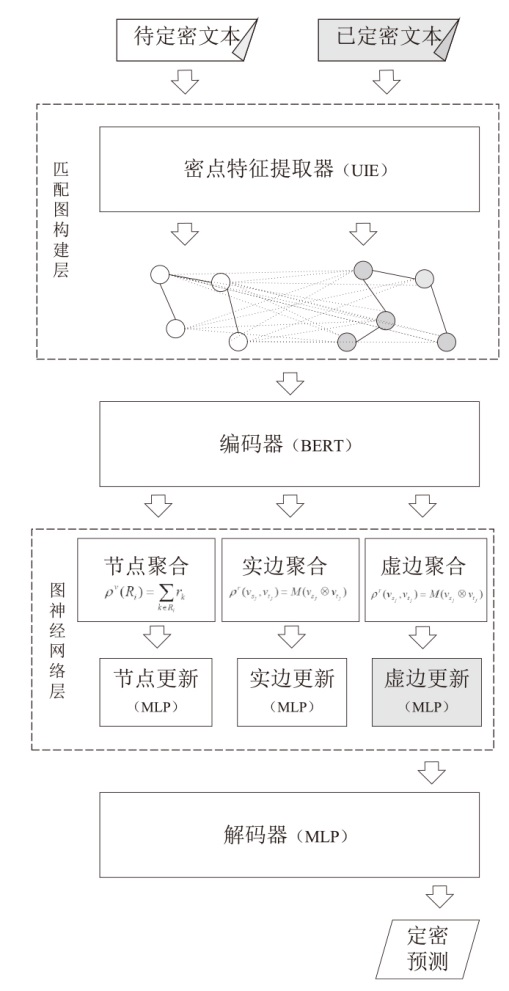
图2
图神经网络的训练过程
表1
实验数据集划分情况
| 数据集 | 样本数/条 | |||||
|---|---|---|---|---|---|---|
| 总数 | 正样本 | 负样本 | 训练集 | 验证集 | 测试集 | |
| CNSE | 29063 | 12865 | 16198 | 17438 | 5813 | 5812 |
| CNSS | 33503 | 16887 | 16616 | 20102 | 6701 | 6700 |
| SDC | 2000 | 892 | 1198 | 1200 | 400 | 400 |
表2
密点特征提取器训练参数
| 训练参数 | 参数值 |
|---|---|
| 学习率 | 0.00001 |
| 文本最大切分长度/字符 | 510 |
| 批处理大小 | 16 |
| 训练轮数/轮 | 100 |
表3
编码器训练参数
| 训练参数 | 参数值 |
|---|---|
| 文本最大输入长度/字符 | 500 |
| 模型堆叠层数/层 | 12 |
| 输出向量维度 | 768 |
表4
解码器和图神经网络训练参数
| 训练参数 | 参数值 |
|---|---|
| 学习率 | 0.0001 |
| 神经元数量/个 | 96 |
| 隐藏层数/层 | 2 |
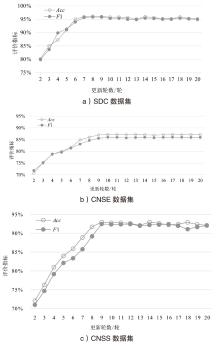
图3
k值对模型性能的影响
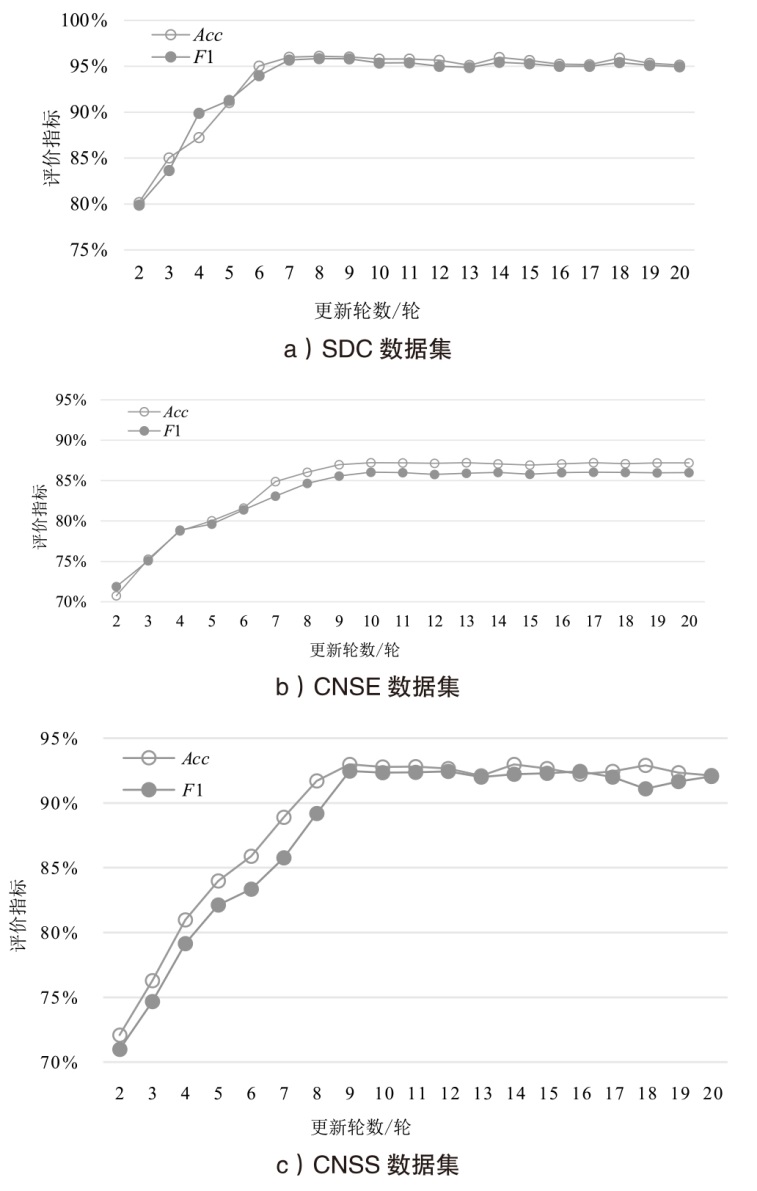
表5
不同模型对比实验结果
| 模型 | 数据集 | |||||
|---|---|---|---|---|---|---|
| CNSE | CNSS | SDC | ||||
| Acc | F1值 | Acc | F1值 | Acc | F1值 | |
| SimNet | 71.05% | 69.26% | 70.78% | 74.50% | 73.90% | 75.16% |
| C-DSSM | 60.17% | 48.57% | 52.96% | 56.75% | 58.91% | 50.74% |
| MatchPyramid | 66.36% | 54.01% | 62.52% | 62.58% | 61.58% | 59.06% |
| BERT | 81.30% | 79.20% | 86.64% | 87.08% | 86.25% | 88.03% |
| CIG | 84.64% | 82.75% | 89.77% | 90.07% | 88.98% | 91.74% |
| Match-Ignition | 86.32% | 84.55% | 91.28% | 91.39% | 91.32% | 92.01% |
| 本文模型 | 86.04% | 84.66% | 91.72% | 89.18% | 96.09% | 95.84% |

图4
消融实验模型
表6
消融实验结果
| 模型 | 数据集 | |||||
|---|---|---|---|---|---|---|
| CNSE | CNSS | SDC | ||||
| Acc | F1值 | Acc | F1值 | Acc | F1值 | |
| 本文模型 | 86.04% | 84.66% | 91.72% | 89.18% | 96.09% | 95.84% |
| 消融实验1 | 82.01% | 79.89% | 86.88% | 85.94% | 86.99% | 87.17% |
| BERT | 81.30% | 79.20% | 86.64% | 87.08% | 86.25% | 88.03% |
| 消融实验2 | 83.01% | 80.66% | 87.12% | 87.79% | 88.09% | 89.95% |
| [1] | AI Si. Accurately Grasp the Original and Derived Classification[J]. Confidentiality Work, 2019(6): 43-44. |
| 艾思. 准确把握原始定密和派生定密[J]. 保密工作, 2019(6): 43-44. | |
| [2] | ZHAI Peipei. Design and Implementation of the Digital Classification Management System[D]. Hangzhou: Hangzhou Dianzi University, 2015. |
| 翟佩佩. 数字化定密管理系统的设计与实现[D]. 杭州: 杭州电子科技大学, 2015. | |
| [3] | XIANG Xuefeng. Research on the Computer-Aided Secret-Level Classification System Based on Keywords Relevancy[D]. Beijing: Beijing Jiaotong University, 2017. |
| 项雪峰. 基于关键词相关度的计算机辅助定密技术研究[D]. 北京: 北京交通大学, 2017. | |
| [4] | LI Chengeng, XIE Sijiang. Research on Computer-Aided Secret-Level Classification Based on Improved Textrank Algorithm[J]. Computer Applications and Software, 2022, 39(3): 336-340. |
| 李晨庚, 谢四江. 基于改进的TextRank算法的计算机辅助定密研究[J]. 计算机应用与软件, 2022, 39(3): 336-340. | |
| [5] | YANG Weiqi. Research and Implementation of the Auxiliary Secret-Level Setting System Based on Deep Learning[D]. Beijing: Beijing Jiaotong University, 2020. |
| 杨玮祺. 基于深度学习的辅助定密系统研究与实现[D]. 北京: 北京交通大学, 2020. | |
| [6] | YANG Weiqi, DU Ye. Text Classification Network Based on Pre-Trained Model[J]. Modern Computer, 2020(12): 52-57. |
| 杨玮祺, 杜晔. 基于预训练模型的文本分类网络TextCGA[J]. 现代计算机, 2020(12): 52-57. | |
| [7] | WANG Xinyun. Research on Key Technologies of Electronic Document Secret Point Extraction and Auxiliary Secret Level Determination[D]. Beijing: Beijing Jiaotong University, 2022. |
| 王心蕴. 电子文档密点提取与辅助定密关键技术研究[D]. 北京: 北京交通大学, 2022. | |
| [8] | LU Gaojie, LIU Qing, DAI Dai, et al. Unified Structure Generation for Universal Information Extraction[EB/OL].(2022-03-23)[2025-01-12]. https://arxiv.org/abs/2203.12277. |
| [9] | HUANG Posen, HE Xiaodong, GAO Jianfeng, et al. Learning Deep Structured Semantic Models for Web Search Using Clickthrough Data[C]// ACM. The 22nd ACM International Conference on Information & Knowledge Management. New York: ACM, 2013: 2333-2338. |
| [10] | SHEN Yelong, HE Xiaodong, GAO Jianfeng, et al. A Latent Semantic Model with Convolutional-Pooling Structure for Information Retrieval[C]// ACM. The 23rd ACM International Conference on Conference on Information and Knowledge Management. New York: ACM, 2014: 101-110. |
| [11] | HU Baotian, LU Zhengdong, LI Hang, et al. Convolutional Neural Network Architectures for Matching Natural Language Sentence[C]// MIT. The 27th International Conference on Neural Information Processing Systems. Cambridge: MIT, 2014: 2042-2050. |
| [12] | PALANGI H, DENG Li, SHEN Yelong, et al. Deep Sentence Embedding Using Long Short-Term Memory Networks: Analysis and Application to Information Retrieval[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2016, 24(4): 694-707. |
| [13] | WAN Shengxian, LAN Yanyan, GUO Jiafeng, et al. A Deep Architecture for Semantic Matching with Multiple Positional Sentence Representations[C]// AAAI. The AAAI Conference on Artificial Intelligence. Menlo Park: AAAI, 2016: 2835-2841. |
| [14] | PANG Liang, LAN Yanyan, GUO Jiafeng, et al. Text Matching as Image Recognition[C]// AAAI. The AAAI Conference on Artificial Intelligence. Menlo Park: AAAI, 2016: 2793-2799. |
| [15] | LYU Lebin, LIU Qun, PENG Lu, et al. Text Matching Fusion Model Combining Multi-Granularity Information[J]. Computer Science, 2021, 48(6): 196-201. |
| 吕乐宾, 刘群, 彭露, 等. 结合多粒度信息的文本匹配融合模型[J]. 计算机科学, 2021, 48(6): 196-201. | |
| [16] | CHEN Qian, ZHU Xiaodan, LING Zhenhua, et al. Enhanced LSTM for Natural Language Inference[C]// ACL. The 55th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2017: 1657-1668. |
| [17] | MENG Jinxu, SHAN Hongtao, WAN Junjie, et al. BSLA: Improved Text Similarity Model for Siamese-LSTM[J]. Computer Engineering and Applications, 2022, 58(23): 178-185. |
| 孟金旭, 单鸿涛, 万俊杰, 等. BSLA: 改进Siamese-LSTM的文本相似模型[J]. 计算机工程与应用, 2022, 58(23): 178-185. | |
| [18] | DAI Xiang, SUN Haichun, NIU Shuo, et al. Research on Chinese Question Answering Matching Based on Mutual Attention Mechanism and Bert[J]. Netinfo Security, 2021, 21(12): 102-108. |
| 代翔, 孙海春, 牛硕, 等. 融合互注意力机制与BERT的中文问答匹配技术研究[J]. 信息网络安全, 2021, 21(12): 102-108. | |
| [19] | DEVLIN J, CHANG Mingwei, LEE K, et al. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding[C]//ACL. The 2019 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies. Stroudsburg: ACL, 2019: 4171-4186. |
| [20] | CAI Hua, HU Jingxi, MA Ren, et al. Matching Long-Form Document with Topic Extraction and Aggregation[C]// ACM. The 2022 5th International Conference on Algorithms, Computing and Artificial Intelligence. New York: ACM, 2023: 1-6. |
| [21] | PANG Liang, LAN Yanyan, CHENG Xueqi. Match-Ignition: Plugging PageRank into Transformer for Long-Form Text Matching[C]// ACM. The 30th ACM International Conference on Information & Knowledge Management. New York: ACM, 2021: 1396-1405. |
| [22] | WANG Jiarui, PENG Cheng, FAN Min. TP-TM: Two-Phase Text Matching Model for Long-Form Texts[J]. Journal of Computer Applications, 2023, 43: 33-38. |
| 王佳睿, 彭程, 范敏. 面向长文本的两阶段文本匹配模型TP-TM[J]. 计算机应用, 2023, 43: 33-38. | |
| [23] | DING Na, LIU Peng, SHAO Huipeng, et al. Bi-Attention Text-Keyword Matching for Law Recommendation[J]. Acta Scientiarum Naturalium Universitatis Pekinensis, 2024, 60(1): 79-88. |
| 丁娜, 刘鹏, 邵惠鹏, 等. 双向注意力文本关键词匹配法条推荐[J]. 北京大学学报(自然科学版), 2024, 60(1): 79-88. | |
| [24] | YU Chuanming, JIANG Yifan. Research on Legal Text Matching Based on Pre-Training Model[J]. Scientific Information Research, 2023, 5(3): 13-25. |
| 余传明, 江一帆. 基于预训练模型的法律文本类案匹配研究[J]. 科技情报研究, 2023, 5(3): 13-25. | |
| [25] | LIU Bang, NIU Di, WEI Haojie, et al. Matching Article Pairs with Graphical Decomposition and Convolutions[C]// ACL. The 57th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2019: 6284-6294. |
| [26] | CHEN Yibo, ZHANG Zuping, HUANG Xin, et al. Matching Document Pairs Using Multi-Feature Semantic Fusion Based on Knowledge Graph[J]. Journal of Central South University (Science and Technology), 2023, 54(8): 3122-3131. |
| 陈毅波, 张祖平, 黄鑫, 等. 基于知识图谱使用多特征语义融合的文档对匹配[J]. 中南大学学报(自然科学版), 2023, 54(8): 3122-3131. | |
| [27] | HUANG Zhenye, MO Ganqing, YU Keman. General Text Matching Based on Topic Model[J]. Computer Applications and Software, 2024(5): 310-318. |
| 黄振业, 莫淦清, 余可曼. 基于主题模型的通用文本匹配方法[J]. 计算机应用与软件, 2024(5): 310-318. |
| [1] | 李锦凯, 王靖雯, 董立波, 姚文翰, 刘成杰, 文伟平. 基于时序图注意力网络的区块链异常交易检测方法[J]. 信息网络安全, 2026, 26(4): 579-590. |
| [2] | 李骁, 宋晓, 李勇. 基于知识蒸馏的医疗诊断差分隐私方法研究[J]. 信息网络安全, 2025, 25(4): 524-535. |
| [3] | 刘晨飞, 万良. 基于时空图神经网络的CAN总线入侵检测方法[J]. 信息网络安全, 2025, 25(3): 478-493. |
| [4] | 韩益亮, 彭一轩, 吴旭光, 李鱼. 基于图变分自编码器的多模态特征融合加密流量分类模型[J]. 信息网络安全, 2025, 25(12): 1914-1926. |
| [5] | 张璐, 贾鹏, 刘嘉勇. 基于多元语义图的二进制代码相似性检测方法[J]. 信息网络安全, 2025, 25(10): 1589-1603. |
| [6] | 李涛, 程柏丰. 基于图神经网络的网络资产主动识别技术研究[J]. 信息网络安全, 2025, 25(10): 1615-1626. |
| [7] | 刘强, 王坚, 王亚男, 王珊. 基于集成学习的恶意代码动态检测方法[J]. 信息网络安全, 2025, 25(1): 159-172. |
| [8] | 王健, 陈琳, 王凯崙, 刘吉强. 基于时空图神经网络的应用层DDoS攻击检测方法[J]. 信息网络安全, 2024, 24(4): 509-519. |
| [9] | 张新有, 孙峰, 冯力, 邢焕来. 基于多视图表征的虚假新闻检测[J]. 信息网络安全, 2024, 24(3): 438-448. |
| [10] | 余尚戎, 肖景博, 殷琪林, 卢伟. 关注社交异配性的社交机器人检测框架[J]. 信息网络安全, 2024, 24(2): 319-327. |
| [11] | 李奕轩, 贾鹏, 范希明, 陈尘. 基于控制流变换的恶意程序检测GNN模型对抗样本生成方法[J]. 信息网络安全, 2024, 24(12): 1896-1910. |
| [12] | 张选, 万良, 罗恒, 杨阳. 基于两阶段图学习的僵尸网络自动化检测方法[J]. 信息网络安全, 2024, 24(12): 1933-1947. |
| [13] | 李鹏超, 张全涛, 胡源. 基于双注意力机制图神经网络的智能合约漏洞检测方法[J]. 信息网络安全, 2024, 24(11): 1624-1631. |
| [14] | 芦效峰, 程天泽, 龙承念. 基于随机游走的图神经网络黑盒对抗攻击[J]. 信息网络安全, 2024, 24(10): 1570-1577. |
| [15] | 秦中元, 马楠, 余亚聪, 陈立全. 基于双重图神经网络和自编码器的网络异常检测[J]. 信息网络安全, 2023, 23(9): 1-11. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||