信息网络安全 ›› 2023, Vol. 23 ›› Issue (9): 47-57.doi: 10.3969/j.issn.1671-1122.2023.09.005
基于PPO算法的攻击路径发现与寻优方法
张国敏, 张少勇( ), 张津威
), 张津威
- 陆军工程大学指挥控制工程学院,南京 210007
-
收稿日期:2023-05-22出版日期:2023-09-10发布日期:2023-09-18 -
通讯作者:张少勇 E-mail:1345150105@qq.com -
作者简介:张国敏(1979—),男,江苏,副教授,博士,CCF会员,主要研究方向为软件定义网络、网络安全、网络测量和分布式系统|张少勇(1999—),男,河北,硕士研究生,主要研究方向为深度强化学习和渗透测试|张津威(1998—),男,四川,硕士研究生,主要研究方向为深度强化学习、恶意流量诱捕和蜜罐主动防御技术 -
基金资助:国家自然科学基金(62172432)
Discovery and Optimization Method of Attack Paths Based on PPO Algorithm
ZHANG Guomin, ZHANG Shaoyong(), ZHANG Jinwei
- Institute of Command and Control Engineering, Army Engineering University of PLA, Nanjing 210007, China
-
Received:2023-05-22Online:2023-09-10Published:2023-09-18 -
Contact:ZHANG Shaoyong E-mail:1345150105@qq.com
摘要:
基于策略网络选择渗透动作发现最优攻击路径,是自动化渗透测试的一项关键技术。然而,现有方法在训练过程中存在无效动作过多、收敛速度慢等问题。为了解决这些问题,文章将PPO(Proximal Policy Optimization)算法用于解决攻击路径寻优问题,并提出带有渗透动作选择模块的改进型PPO算法IPPOPAS(Improved PPO with Penetration Action Selection),该算法在获取回合经验时,根据渗透测试场景进行动作筛选。文章设计实现IPPOPAS算法的各个组件,包括策略网络、价值网络和渗透动作选择模块等,对动作选择过程进行改进,并进行参数调优和算法优化,提高了算法的性能和效率。实验结果表明,IPPOPAS算法在特定网络场景中的收敛速度优于传统深度强化学习算法DQN(Deep Q Network)及其改进算法,并且随着主机中漏洞数量的增加,该算法的收敛速度更快。此外,实验还验证了在网络规模扩大的情况下IPPOPAS算法的有效性。
中图分类号:
引用本文
张国敏, 张少勇, 张津威. 基于PPO算法的攻击路径发现与寻优方法[J]. 信息网络安全, 2023, 23(9): 47-57.
ZHANG Guomin, ZHANG Shaoyong, ZHANG Jinwei. Discovery and Optimization Method of Attack Paths Based on PPO Algorithm[J]. Netinfo Security, 2023, 23(9): 47-57.
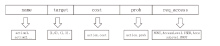
图1
动作空间基本属性向量化表示
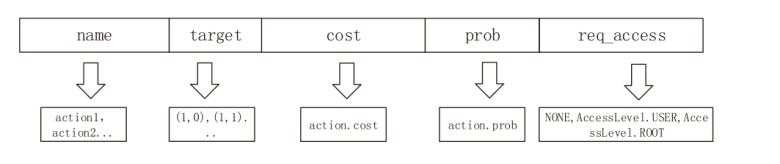
表1
部分漏洞利用成功概率示例
| 漏洞编号 | 针对服务或进程 | 攻击复杂度 | 概率设置 |
|---|---|---|---|
| CVE-2019-1069 | Schtask | Low | 0.8 |
| CVE-2020-9484 | Tomcat | Low | 0.8 |
| CVE-2019-0841 | Daclsvc | Low | 0.8 |
| CVE-2019-16759 | HTTP | Low | 0.8 |
| CVE-2018-15473 | SSH | Low | 0.8 |
| CVE-2019-18232 | FTP | Medium | 0.5 |
| CVE-2019-19317 | SMTP | High | 0.2 |
| CVE-2017-7494 | SAMBA | Low | 0.8 |

图2
状态转移情况
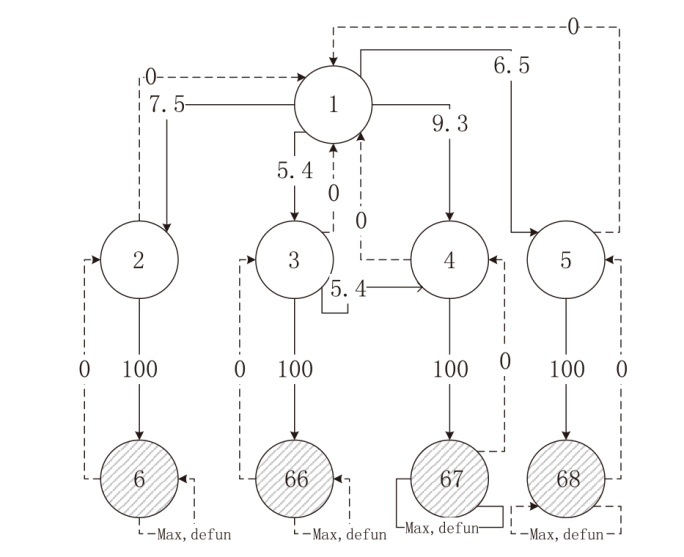
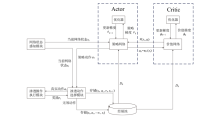
图3
IPPOPAS算法框架


图4
场景1的网络拓扑结构

表2
典型企业网络中各主机配置
| 地址 | 操作系统 | 主机价值 | 服务 | 进程 |
|---|---|---|---|---|
| (1,0) | Linux | 0 | HTTP | - |
| (2,0) | Windows | 100 | SMTP | Schtask |
| (2,1) | Windows | 0 | SMTP | Schtask |
| (3,0),(3,3),(3,4),(4,3) | Windows | 0 | FTP | Schtask |
| (3,1) | Windows | 0 | FTP, HTTP | Daclsvc |
| (3,2) | Windows | 0 | FTP | - |
| (4,0),(4,1),(4,2),(5,2) | Linux | 0 | SSH | - |
| (5,0) | Windows | 100 | SSH, SAMBA | Tomcat |
| (5,1) | Linux | 0 | SSH, HTTP | Tomcat |
| (5,3) | Linux | 0 | SSH | Daclsvc |
表3
模拟网络场景信息
| 网络场景 | 主机数量/个 | 敏感主机数量/个 | 子网数量/个 | 开放网络数量/个 | 运行进程数量/个 |
|---|---|---|---|---|---|
| Scenario 1 | 16 | 2 | 5 | 5 | 3 |
| Scenario 2 | 35 | 2 | 10 | 5 | 3 |
| Scenario 3 | 16 | 2 | 5 | 40 | 3 |
| Scenario 4 | 35 | 2 | 10 | 80 | 3 |
| Scenario 5 | 50 | 3 | 13 | 5 | 5 |
| Scenario 6 | 75 | 3 | 18 | 5 | 5 |
| Scenario 7 | 150 | 3 | 22 | 5 | 5 |
表4
IPPOPAS算法在不同场景的超参数
| 超参数 | 含义 | 取值(场景1~ 场景4) | 取值(场景5~ 场景7) |
|---|---|---|---|
| Actor learning rate, | Actor网络的学习率 | 1e-4 | 1e-5 |
| Critic learning rate, | Critic网络的学习率 | 5e-3 | 5e-4 |
| GAE计算过程中的参数 | 0.9 | 0.9 | |
| Discount factor, | 折扣因子 | 0.9 | 0.9 |
| Hidden layer size | 隐藏层神经元层数及个数 | [128,128] | [128,128] |
| n_steps | 控制每个采样轨迹的长度 | 2000(Scenario 1) 3000(Scenario 2) 5000(Scenario 3) 8000(Scenario 4) | 8000 |
| Epochs | 一条序列的数据 用来训练轮数 | 10 | 10 |
| Clip Ratio | PPO中截断范围的参数 | 0.2 | 0.2 |

图5
每回合累积奖励值随训练回合数的变化(场景1)
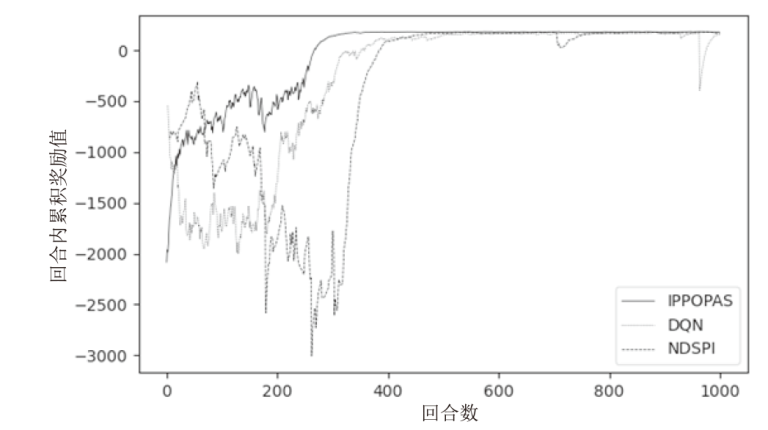
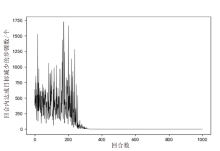
图6
渗透动作选择模块减少的交互次数随训练回合数的变化 (场景1)


图7
场景1中智能体目标主机的选择结果

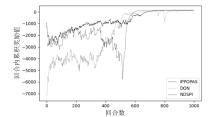
图8
每回合累积奖励值随训练回合数的变化(场景2)

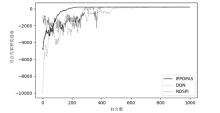
图9
每回合累积奖励值随训练回合数的变化(场景3)
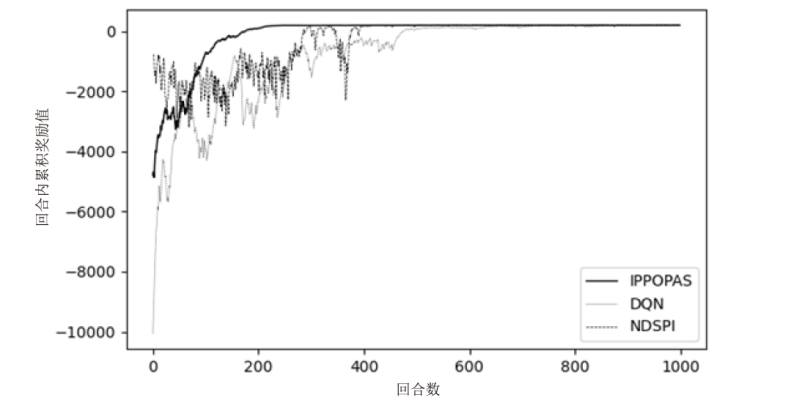
图10
每回合累积奖励值随训练回合数的变化(场景4)
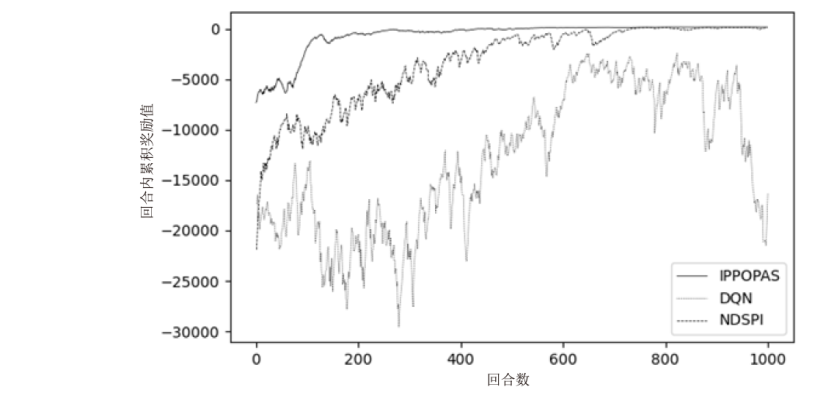
图11
网络场景5~场景7下每回合获得的累积奖励值

| [1] | PHILLIPS C, SWILER L P. A Graph-Based System for Network-Vulnerability Analysis[C]// ACM. 1998 Workshop on New Security Paradigms. New York: ACM, 1998: 71-79. |
| [2] | YOUSEFI M, MTETWA N, ZHANG Yan, et al. A Reinforcement Learning Approach for Attack Graph Analysis[C]// IEEE. 2018 17th IEEE International Conference on Trust, Security and Privacy in Computing and Communications/12th IEEE International Conference on Big Data Science and Engineering (TrustCom/BigDataSE). New York: IEEE, 2018: 212-217. |
| [3] | OU Xinming, GOVINDAVAJHALA S, APPEL A W. MulVAL: A Logic-Based Network Security Analyzer[C]// USENIX. 14th Conference on USENIX Security Symposium. Berlin: USENIX, 2005: 113-128. |
| [4] | BELLMAN R E. A Markovian Decision Process[J]. Journal of Mathematics and Mechanics, 1957, 6(5): 679-684. |
| [5] | CASSANDRA A R, KAELBLING L P, LITTMAN M L. Acting Optimally in Partially Observable Stochastic Domains[C]// ACM. Twelfth AAAI National Conference on Artificial Intelligence. New York: ACM, 1994: 1023-1028. |
| [6] | SARRAUTE C, BUFFET O, HOFFMANN J. Penetration Testing= =POMDP Solving?[EB/OL]. (2013-06-19)[2023-04-30]. https://arxiv.org/pdf/1306.4714.pdf. |
| [7] | SCHWARTZ J, KURNIAWATI H. Autonomous Penetration Testing Using Reinforcement Learning[EB/OL]. (2019-05-15)[2023-04-30]. https://arxiv.org/abs/1905.05965. |
| [8] | ZENNARO F M, ERDODI L. Modeling Penetration Testing with Reinforcement Learning Using Capture-the-Flag Challenges and Tabular Q-Learning[EB/OL]. (2020-05-26)[2023-04-30]. https://arxiv.org/abs/2005.12632. |
| [9] | ZHANG Lei, BAI Wei, LI Wei, et al. Discover the Hidden Attack Path in Multiple Domain Cyberspace Based on Reinforcement Learning[EB/OL]. (2021-04-15)[2023-04-30]. https://arxiv.org/abs/2104.07195. |
| [10] | HUANG Lanxiao, CODY T, REDINO C, et al. Exposing Surveillance Detection Routes via Reinforcement Learning, Attack Graphs, and Cyber Terrain[C]// IEEE. 2022 21st IEEE International Conference on Machine Learning and Applications (ICMLA). New York: IEEE, 2022: 21-28. |
| [11] | SCHWARTZ J, KURNIAWATTI H. NASim: Network Attack Simulator[EB/OL]. (2019-05-26)[2023-04-30]. https://networkattacksimulator.readthedocs.io/. |
| [12] | CHRISTIAN S, MICHAEL B, WILLIAM B, et al. CyberBattle-Sim[EB/OL]. (2021-05-11)[2023-04-30]. https://github.com/microsoft/cyberbattlesim. |
| [13] | ZHOU Shicheng, LIU Jingju, HOU Dongdong, et al. Autonomous Penetration Testing Based on Improved Deep Q-Network[EB/OL]. (2021-07-16)[2023-04-30]. https://doi.org/10.3390/app11198823. |
| [14] | FIGUEROA-LORENZO S, AÑORGA J, ARRIZABALAGA S. A Survey of IIoT Protocols: A Measure of Vulnerability Pisk Analysis Based on CVSS[J]. ACM Computing Surveys (CSUR), 2020, 53(2): 1-53. |
| [15] | SCHULMAN J, WOLSKI F, DHARIWAL P, et al. Proximal Policy Optimization Algorithms[EB/OL]. (2017-07-20)[2023-04-30]. https://arxiv.org/abs/1707.06347. |
| [16] | SCHULMAN J, LEVINE S, MORITZ P, et al. Trust Region Policy Optimization[C]// ACM. International Conference on Machine Learning. New York: ACM, 2015: 1889-1897. |
| [17] |
MNIH V, KAVUKCUOGLU K, SILVER D, et al. Human-Level Control Through Deep Reinforcement Learning[J]. Nature, 2015, 518(7540): 529-533.
doi: 10.1038/nature14236 |
| [18] | SCHULMAN J, MORITZ P, LEVINE S, et al. High-Dimensional Continuous Control Using Generalized Advantage Estimation[EB/OL]. (2015-06-08)[2023-04-30]. https://arxiv.org/abs/1506.02438. |
| [19] | CHOWDHARY A, HUANG Dijiang, MAHENDRAN J S, et al. Autonomous Security Analysis and Penetration Testing[C]// IEEE. 2020 16th International Conference on Mobility, Sensing and Networking (MSN). New York: IEEE, 2020: 508-515. |
| [1] | 秦中元, 马楠, 余亚聪, 陈立全. 基于双重图神经网络和自编码器的网络异常检测[J]. 信息网络安全, 2023, 23(9): 1-11. |
| [2] | 公鹏飞, 谢四江, 程安东. 基于HotStuff改进的多主节点共识算法[J]. 信息网络安全, 2023, 23(9): 108-117. |
| [3] | 戴玉, 周非, 薛丹. 基于中国剩余定理秘密共享的切换认证协议[J]. 信息网络安全, 2023, 23(9): 118-128. |
| [4] | 张玉臣, 张雅雯, 吴越, 李程. 基于时频图与改进E-GraphSAGE的网络流量特征提取方法[J]. 信息网络安全, 2023, 23(9): 12-24. |
| [5] | 刘芹, 王卓冰, 余纯武, 王张宜. 面向云安全的基于格的高效属性基加密方案[J]. 信息网络安全, 2023, 23(9): 25-36. |
| [6] | 周权, 陈民辉, 卫凯俊, 郑玉龙. 基于SM9的属性加密的区块链访问控制方案[J]. 信息网络安全, 2023, 23(9): 37-46. |
| [7] | 薛羽, 张逸轩. 深层神经网络架构搜索综述[J]. 信息网络安全, 2023, 23(9): 58-74. |
| [8] | 武伟, 徐莎莎, 郭森森, 李晓宇. 基于位置社交网络的兴趣点组合推荐算法研究[J]. 信息网络安全, 2023, 23(9): 75-84. |
| [9] | 浦珺妍, 李亚辉, 周纯杰. 基于概率攻击图的工控系统跨域动态安全风险分析方法[J]. 信息网络安全, 2023, 23(9): 85-94. |
| [10] | 赵佳豪, 蒋佳佳, 张玉书. 基于动态默克尔哈希树的跨链数据一致性验证模型[J]. 信息网络安全, 2023, 23(9): 95-107. |
| [11] | 邵震哲, 蒋佳佳, 赵佳豪, 张玉书. 面向跨链的改进加权拜占庭容错算法[J]. 信息网络安全, 2023, 23(8): 109-120. |
| [12] | 谢四江, 程安东, 公鹏飞. 一种基于QKD的多方拜占庭共识协议[J]. 信息网络安全, 2023, 23(8): 41-51. |
| [13] | 李志慧, 罗双双, 韦性佳. 基于一类受限存取结构上的量子秘密共享方案[J]. 信息网络安全, 2023, 23(8): 32-40. |
| [14] | 王鹃, 张冲, 龚家新, 李俊娥. 基于机器学习的模糊测试研究综述[J]. 信息网络安全, 2023, 23(8): 1-16. |
| [15] | 覃思航, 代炜琦, 曾海燕, 顾显俊. 基于区块链的电力应用数据安全共享研究[J]. 信息网络安全, 2023, 23(8): 52-65. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||