信息网络安全 ›› 2019, Vol. 19 ›› Issue (4): 11-19.doi: 10.3969/j.issn.1671-1122.2019.04.002
一种基于机器学习的Spark容器集群性能提升方法
田春岐1,2( ), 李静1,2, 王伟1,2,3, 张礼庆1,2
), 李静1,2, 王伟1,2,3, 张礼庆1,2
- 1. 同济大学计算机科学与技术系,上海 200092
2. 同济大学嵌入式系统与服务计算教育部重点实验室,上海 200092
3. 湖北省教育信息化工程技术研究中心,湖北武汉 430062
-
收稿日期:2018-11-19出版日期:2019-04-10发布日期:2020-05-11 -
作者简介:作者简介:田春岐(1975—),男,陕西,副教授,博士,主要研究方向为云计算、无线宽带网络;李静(1993—),女,四川,硕士研究生,主要研究方向为云计算、大数据;王伟(1979—),男,湖北,副教授,博士,主要研究方向为云计算、大数据、大规模在线学习系统;张礼庆(1994—),男,江苏,硕士研究生,主要研究方向为云计算、大数据。
-
基金资助:国家自然科学基金[61672384, 61772372];中央高校基本科研业务费专项资金[0800219373];湖北省教育信息化工程技术研究中心开放基金重点项目[201701]
A Method for Improving the Performance of Spark on Container Cluster Based on Machine Learning
Chunqi TIAN1,2(), Jing LI1,2, Wei WANG1,2,3, Liqing ZHANG1,2
- 1. Department of Computer Science and Engineering, Tongji University, Shanghai 200092, China
2. The Key Laboratory of Embedded System and Service Computing of Ministry of Education, Tongji University, Shanghai 200092, China
3. Hubei Engineering Research Center for Education Information, Wuhan Hubei 430062, China
-
Received:2018-11-19Online:2019-04-10Published:2020-05-11
摘要:
目前基于Spark的应用十分广泛,合理的参数配置会使Spark作业具备较高的执行效率,很多学者对虚拟机集群上的Spark参数调优进行了深入研究。近年来,容器作为一种新兴的云计算基础设施越来越广泛地被应用于服务集群中,因而对基于容器集群的Spark参数调优进行研究也具有重要意义。文章研究了Docker容器集群中Spark的参数配置问题,提出了一种新型的参数调优方法(ContainerOpt),使用机器学习方法学习并预测作业在不同参数组合下的性能,同时引入节点自动伸缩机制,使输入规模较大的作业可以获得更优的性能。文章还提出了由时间和资源共同决定的性能表示模型,代替传统的基于单一执行时间的性能表示模型,从而在作业执行时间和资源占用之间达到较好的平衡。实验结果表明,相较于默认配置,该参数调优方法可提升50%的执行效率。
中图分类号:
引用本文
田春岐, 李静, 王伟, 张礼庆. 一种基于机器学习的Spark容器集群性能提升方法[J]. 信息网络安全, 2019, 19(4): 11-19.
Chunqi TIAN, Jing LI, Wei WANG, Liqing ZHANG. A Method for Improving the Performance of Spark on Container Cluster Based on Machine Learning[J]. Netinfo Security, 2019, 19(4): 11-19.
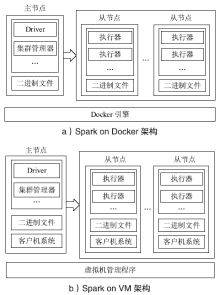
图1
Spark on YARN架构
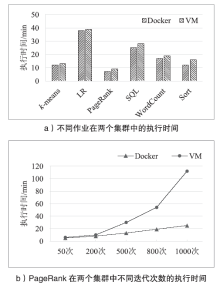
图2
Docker集群与VM集群中Spark的性能

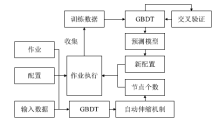
图3
ContainerOpt总体架构
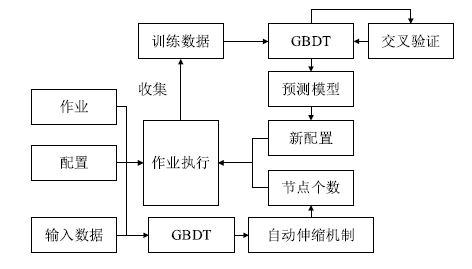
表1
Spark作业参数
| 参数 | 描述 | 默认 | 参数范围 |
|---|---|---|---|
| Spark.num.instances | Executor个数 | 2 | 2~nodes×4 |
| Spark.driver.cores | Driver的CPU个数 | 1 | 1~4 |
| Spark.driver.memory | Driver内存 | 1 | 1~4 |
| Spark.executor.cores | Executor的CPU个数 | 1 | 2~16 |
| Spark.executor.memory | Executor内存数 | 1 GB | 2~64 GB |
| Spark.default.parallelism | Executor的并行度 | nodes×executor.cores×3 | |
| inputsize | 输入数据 | ||
| nodes | 节点个数 |
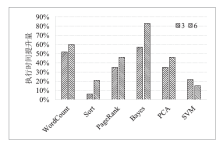
图4
节点个数对作业性能的影响
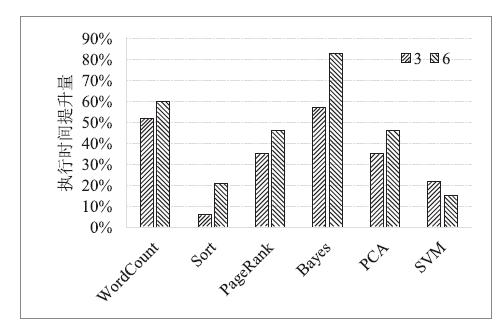
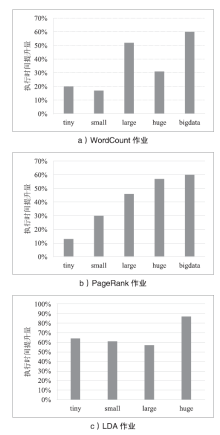
图5
不同输入规模下最优作业执行时间提升量
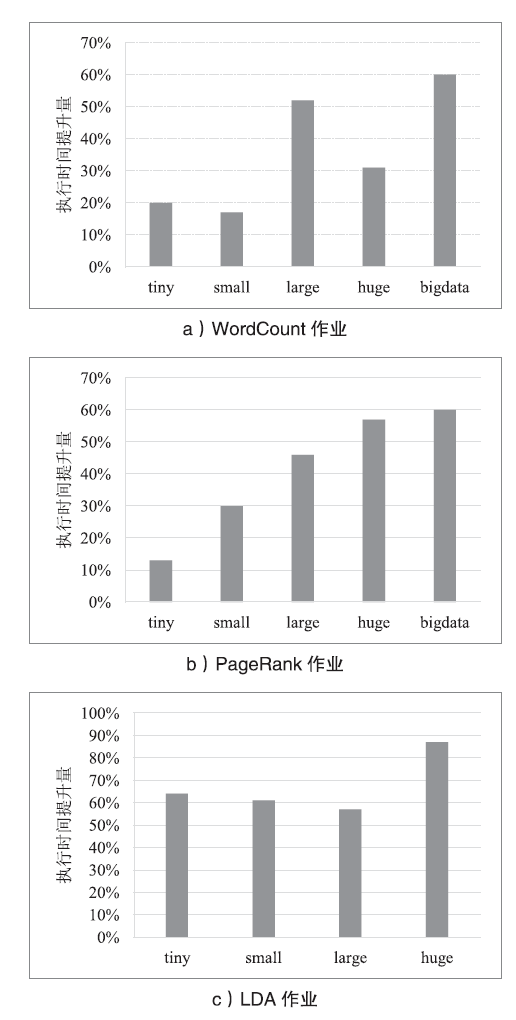
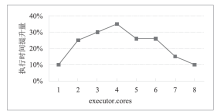
图6
TeraSort执行时间提升量随executor.cores变化情况
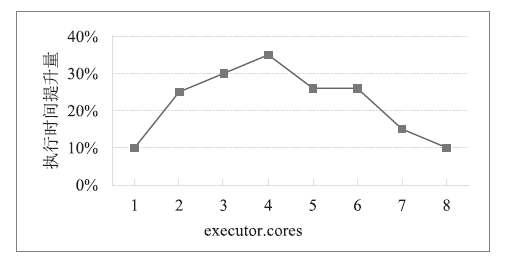
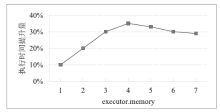
图7
TeraSort执行时间提升量随executor.memory变化情况
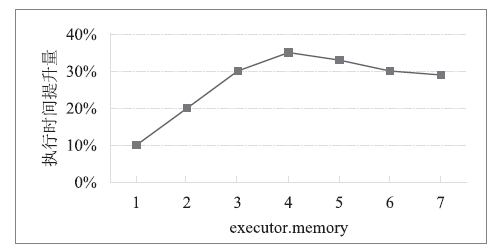
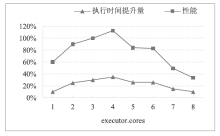
图8
TeraSort性能随executor.cores变化情况

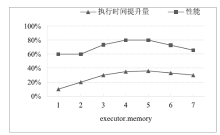
图9
TeraSort性能随executor.memory变化情况

| [1] | DEAN J, SANJAY G.MapReduce: Simplified Data Processing on Large Clusters[J]. Communications of the ACM, 2008, 51(1): 107-113. |
| [2] | CHEN Yaobing, LIU Bin, SHI Yantao.A Lot of Log Storage and Retrieval Optimization Based on Hadoop Architecture[J]. Netinfo Security, 2013, 13(6): 40-45. |
| 陈耀兵,刘斌,史延涛.基于Hadoop架构的大数据量日志存储和检索优化[J].信息网络安全,2013,13(6):40-45. | |
| [3] | Apache. Apache Spark[EB/OL]. , 2018-7-11. |
| [4] | BABU S.Towards Automatic Optimization of MapReduce Programs[C]//ACM. 1st ACM Symposium on Cloud Computing, June 10-11, 2010, Indianapolis, Indiana, USA. New York: ACM, 2010: 137-142. |
| [5] | HERODOTOU H, DONG F, BABU S. No One(Cluster) Size Fits All: Automatic Cluster Sizing for Data-intensive Analytics[C]//ACM. 2nd ACM Symposium on Cloud Computing, October 26-28, 2011, Cascais, Portugal. New York: ACM, 2011: 1-14. |
| [6] | HERODOTOU H, LIM H, LUO G, et al.Starfish: A Self-tuning System for Big Data Analytics[J]. CIDR, 2011, 1(11): 161-272. |
| [7] | DING Xiaoan, LIU Yi, QIAN Depei.JellyFish: Online Performance Tuning with Adaptive Configuration and Elastic Container in Hadoop Yarn[C]//IEEE. IEEE International Conference on Parallel & Distributed Systems, December 14-17, 2015, Melbourne, VIC, Australia. New Jersey: IEEE, 2016: 831-836. |
| [8] | JIANG Dawei, OOI B C, SHI Lei, et al.The Performance of MapReduce: An in-depth Study[J]. VLDB Endowment, 2010, 3(1-2): 472-483. |
| [9] | LAMA P, ZHOU Xiaobo.Aroma: Automated Resource Allocation and Configuration of Mapreduce Environment in the Cloud[C]//ACM. 9th International Conference on Autonomic Computing. September 18-20, 2012, San Jose, California, USA. New York: ACM, 2012: 63-72. |
| [10] | LIAO Guangdegn, DATTA K, WILLKE T L.Gunther: Search-based Auto-tuning of MapReduce[C]//Springer. 19th International Conference on Parallel Processing, August 26-30, 2013, Aachen, Germany. Heidelberg: Springer, 2013: 406-419. |
| [11] | WU Dili, GOKHALE A.A Self-tuning System Based on Application Profiling and Performance Analysis for Optimizing Hadoop MapReduce Cluster Configuration[C]//IEEE. 20th International Conference on High Performance Computing(HiPC), December 18-21, 2013, Bangalore, India. New Jersey: IEEE, 2014: 89-98. |
| [12] | LI Min, ZENG Liangzhao, MENG Shicong, et al.MRONLINE: MapReduce Online Performance Tuning[C]//ACM. International Symposium on High-performance Parallel & Distributed Computing, June 23-27, 2014, Vancouver, BC, Canada. New York: ACM, 2014: 165-176. |
| [13] | CHENG Dazhao, RAO Jia, GUO Yanfei, et al.Improving MapReduce Performance in Heterogeneous Environments with Adaptive Task Tuning[C]//ACM. International Middleware Conference, December 8-12, 2014, Bordeaux, France. New York: ACM, 2014: 97-108. |
| [14] | BHIMANI J, YANG Zhengyu, LEESER M, et al.Accelerating Big Data Applications Using Lightweight Virtualization Framework on Enterprise Cloud[C]//IEEE. 2017 IEEE High Performance Extreme Computing Conference(HPEC), September 12-14, 2017, Waltham, MA, USA. New Jersey: IEEE, 2017: 1-7. |
| [15] | YE Kejiang, JI Yunjie.Performance Tuning and Modeling for Big Data Applications in Docker Containers[C]//IEEE. 2017 International Conference on Networking, August 7-9, 2017, Shenzhen, China. New Jersey: IEEE, 2017: 1-6. |
| [16] | WANG Xueyuan, LEE B, QIAO Yuansong.Experimental Evaluation of Memory Configurations of Hadoop in Docker Environments[C]//IEEE. 27th Irish Signals and Systems Conference(ISSC), June 21-22, 2016, Londonderry, UK. New Jersey: IEEE, 2016: 1-6. |
| [17] | WANG Kewen, KHAN M M H, NGUYEN N, et al. Modeling Interference for Apache Spark Jobs[C]//IEEE. 9th IEEE International Conference on Cloud Computing, June 27-July 2, 2016, San Francisco, CA, USA. New Jersey: IEEE, 2017: 423-431. |
| [18] | HERNÁNDEZ Álvaro Brandón, PEREZ María S, GUPTA S, et al. Using Machine Learning to Optimize Parallelism in Big Data Applications[EB/OL]. , 2018-6-11. |
| [19] | MARCO V S, TAYLOR B, PORTER B, et al.Improving Spark Application Throughput via Memory Aware Task Co-location: A Mixture of Experts Approach[C]//ACM. 18th ACM/IFIP/USENIX Middleware Conference, December 11-15, 2017, Las Vegas, Nevada. New York: ACM, 2017: 95-108. |
| [20] | FENG Xinyang, SHEN Jianjing.A Yarn and NMF Based Big Data Clustering Algorithm[J]. Netinfo Security, 2018, 18(8): 43-49. |
| 冯新扬,沈建京.一种基于YARN云计算平台与NMF的大数据聚类算法[J].信息网络安全,2018,18(8):43-49. | |
| [21] | YIGITBASI N, WILLKE T L, LIAO G, et al.Towards Machine Learning-based Auto-tuning of MapReduce[C]//IEEE. 2013 IEEE 21st International Symposium on Modelling, Analysis & Simulation of Computer and Telecommunication Systems, August 14-16, 2013, San Francisco, CA, USA. New Jersey: IEEE, 2013: 11-20. |
| [1] | 郭春, 陈长青, 申国伟, 蒋朝惠. 一种基于可视化的勒索软件分类方法[J]. 信息网络安全, 2020, 20(4): 31-39. |
| [2] | 杜义峰, 郭渊博. 一种基于信任值的雾计算动态访问控制方法[J]. 信息网络安全, 2020, 20(4): 65-72. |
| [3] | 刘渊, 乔巍. 云环境下基于Kubernetes集群系统的容器网络研究与优化[J]. 信息网络安全, 2020, 20(3): 36-44. |
| [4] | 白嘉萌, 寇英帅, 刘泽艺, 查达仁. 云计算平台基于角色的权限管理系统设计与实现[J]. 信息网络安全, 2020, 20(1): 75-82. |
| [5] | 任良钦, 王伟, 王琼霄, 鲁琳俪. 一种新型云密码计算平台架构及实现[J]. 信息网络安全, 2019, 19(9): 91-95. |
| [6] | 马泽文, 刘洋, 徐洪平, 易航. 基于集成学习的DoS攻击流量检测技术[J]. 信息网络安全, 2019, 19(9): 115-119. |
| [7] | 余奕, 吕良双, 李肖坚, 王天博. 面向移动云计算场景的动态网络拓扑描述语言[J]. 信息网络安全, 2019, 19(9): 120-124. |
| [8] | 王紫璇, 吕良双, 李肖坚, 王天博. 基于共享存储的OpenStack虚拟机应用分发策略[J]. 信息网络安全, 2019, 19(9): 125-129. |
| [9] | 崔艳鹏, 冯璐铭, 闫峥, 蔺华庆. 基于程序切片技术的云计算软件安全模型研究[J]. 信息网络安全, 2019, 19(7): 31-41. |
| [10] | 葛新瑞, 崔巍, 郝蓉, 于佳. 加密云数据上支持可验证的关键词排序搜索方案[J]. 信息网络安全, 2019, 19(7): 82-89. |
| [11] | 陈冠衡, 苏金树. 基于深度神经网络的异常流量检测算法[J]. 信息网络安全, 2019, 19(6): 68-75. |
| [12] | 赵谱, 崔巍, 郝蓉, 于佳. 一种针对El-Gamal数字签名生成的安全外包计算方案[J]. 信息网络安全, 2019, 19(3): 81-86. |
| [13] | 张振峰, 张志文, 王睿超. 网络安全等级保护2.0云计算安全合规能力模型[J]. 信息网络安全, 2019, 19(11): 1-7. |
| [14] | 胡建伟, 赵伟, 闫峥, 章芮. 基于机器学习的SQL注入漏洞挖掘技术的分析与实现[J]. 信息网络安全, 2019, 19(11): 36-42. |
| [15] | 张健, 陈博翰, 宫良一, 顾兆军. 基于图像分析的恶意软件检测技术研究[J]. 信息网络安全, 2019, 19(10): 24-31. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||