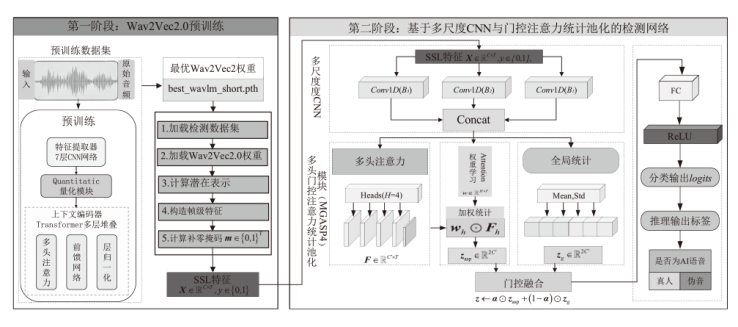
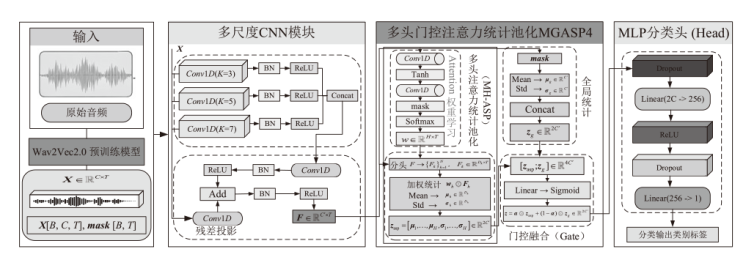
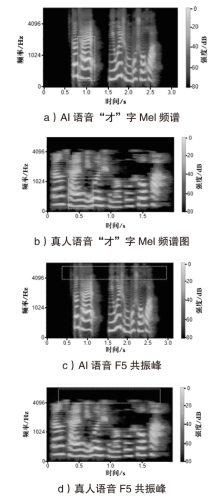
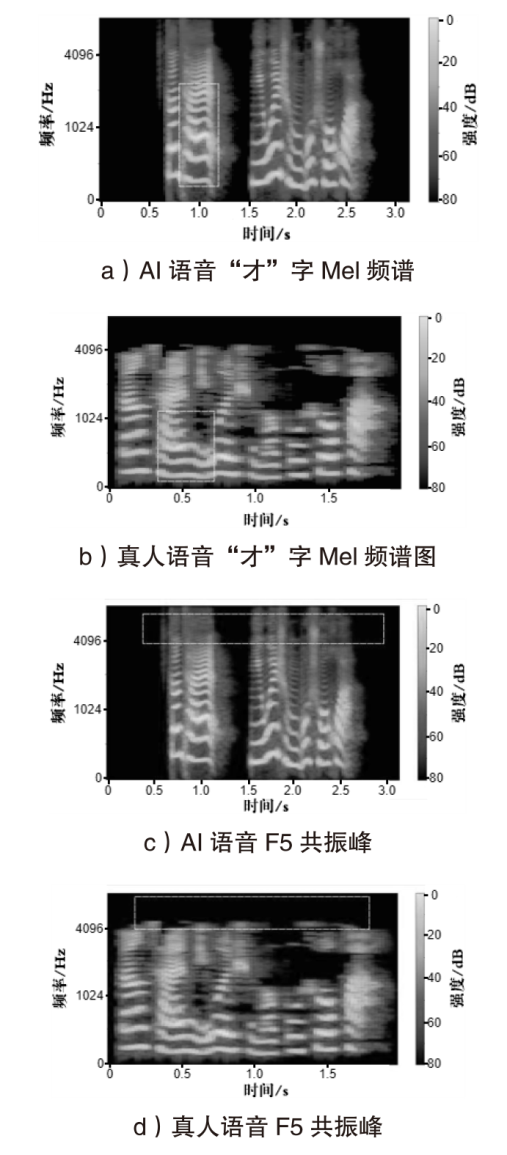
| [1] |
XU Yuxiong, LI Bin, TAN Shunquan, et al. Research Progress on Speech Deepfake and Its Detection Techniques[J]. Journal of Image and Graphics, 2024, 29(8): 2236-2268.
doi: 10.11834/jig.230476
URL
|
|
许裕雄, 李斌, 谭舜泉, 等. 语音深度伪造及其检测技术研究进展[J]. 中国图象图形学报, 2024, 29 (8):2236-2268.
|
| [2] |
YANG Yujie, QIN Haochen, ZHOU Hang, et al. A Robust Audio Deepfake Detection System via Multi-View Feature[C]// IEEE. 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). New York: IEEE, 2024: 13131-13135.
|
| [3] |
XUE Ouyang, WANG Chunhui, ZHAO Bin, et al. Adaptive Reverse Perturbation Network for Audio Deepfake Detection[J]. Neurocomputing, 2025, 658: 1-12.
|
| [4] |
GUO Yinlin, HUANG Haofan, CHEN Xi, et al. Audio Deepfake Detection with Self-Supervised Wavlm and Multi-Fusion Attentive Classifier[C]// IEEE. 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). New York: IEEE, 2024: 12702-12706.
|
| [5] |
YUAN Hongyan, ZHANG Linjuan, NIU Baoning, et al. A Spoofing Speech Detection Method Combining Multi-Scale Features and Cross-Layer Information[J]. Information, 2025, 16 (3): 194.
doi: 10.3390/info16030194
URL
|
| [6] |
LIU Liwei, WEI Huihui, LIU Dongya, et al. HarmoNet:Partial DeepFake Detection Network Based on Multi-Scale HarmoF0 Feature Fusion[C]// ISCA. Interspeech 2024. NewYork: IEEE, 2024: 2255-2259.
|
| [7] |
ZHANG Qishan, WEN Shuangbing, HU Tao, et al. Audio Deepfake Detection with Self-Supervised XLS-R and SLS Classifier[C]// ACM. The 32nd ACM International Conference on Multimedia (MM '24). New York: ACM, 2024: 6765-6773.
|
| [8] |
KUMAR A, BOSE S, HASSAN M, et al. SPDG-Net: Semantics Preserving Domain Augmentation through Style Interpolation for Multi-Source Domain Generalization[C]// IEEE. 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). New York: IEEE, 2024: 7365-7369.
|
| [9] |
SALIH A O M, EMAM A H M, AHMED A B G E, et al. Deepfake Audio Detection in Voice Authentication: A Spectral and CNN-Based Comprehensive Review[J]. Engineering, Technology and Applied Science Research, 2025, 15(6): 29824-29832.
doi: 10.48084/etasr.13400
URL
|
| [10] |
DIXIT A, KAUR N, KINGRA S. Review of Audio Deepfake Detection Techniques: Issues and Prospects[J]. Expert Systems, 2023, 40(8):1-19.
|
| [11] |
LI Menglu, ZHANG Xiaoping, AHMADIADLI Y, et al. A Survey on Speech Deepfake Detection[J]. ACM Computing Surveys, 2025, 57(7): 1-38.
|
| [12] |
KINNUNEN T, SAHIDULLAH M, DELGADO H, et al. The ASVspoof 2017 Challenge: Assessing the Limits of Replay Spoofing Attack Detection[C]// ISCA. Interspeech 2017. New York: IEEE, 2017: 2-6.
|
| [13] |
DELGADO H, EVANS N, KINNUNEN T, et al. ASVspoof 2021:Automatic Speaker Verification Spoofing and Countermeasures Challenge Evaluation Plan[EB/OL]. (2021-09-01)[2025-06-01]. https://doi.org/10.48550/arXiv.2109.00537.
|
| [14] |
MASOOD M, NAWAZ M, MALIK K M, et al. Deepfakes Generation and Detection: State-of-the-Art, Open Challenges, Countermeasures and Way Forward[J]. Applied Intelligence, 2023, 53: 3974-4026.
doi: 10.1007/s10489-022-03766-z
|
| [15] |
LI M, ZORILA C, DODDIPATLA R S. Head-Synchronous Decoding for Transformer-Based Streaming ASR[C]// IEEE. 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). New York: IEEE, 2021: 5909-5913.
|
| [16] |
GOSWAMI M, MAHATO S, KUNDU S, et al. Potentials and Advantages of NavIC in Indian Missile Programs[C]// IEEE. 2021 2nd International Conference on Range Technology (ICORT). New York: IEEE, 2021: 1-4.
|
| [17] |
CHEN Feifei, GUO Haiyan, GUO Yanmin, et al. Deepfake Speech Detection Method Based on Wav2Vec2.0 Feature Merging and Joint Loss[J]. Journal of Signal Processing, 2025, 41(9): 1547-1557.
|
|
陈飞飞, 郭海燕, 郭延民, 等. 基于 Wav2Vec2.0 特征融合与联合损失的深度伪造语音检测方法[J]. 信号处理, 2025, 41(9):1547-1557.
|
| [18] |
CHEN Maximillian, ZHOU Yu. Pre-Finetuning for Few-Shot Emotional Speech Recognition[C]// ISCA. Interspeech 2023. New York: IEEE, 2023: 3602-3606.
|
| [19] |
LIU Zhe, PENG Fuchun. Modeling Dependent Structure for Utterances in ASR Evaluation[C]// ISCA. Interspeech 2023, New York: IEEE. International Speech Communication Association (ISCA), 2023: 3237-3241.
|
| [20] |
TALHA M M, KHAN H U, IQBAL S, et al. Deep Learning in News Recommender Systems: A Comprehensive Survey, Challenges and Future Trends[J]. Neurocomputing, 2023, 562: 126881-126881.
doi: 10.1016/j.neucom.2023.126881
URL
|
| [21] |
PAL P, DANGI R, NAZIR M S, et al. Scalable GaN-HEMT Model for X-Band RF Applications[C]// IEEE. 2024 8th IEEE Electron Devices Technology & Manufacturing Conference (EDTM). New York: IEEE, 2024: 1-3.
|
| [22] |
HUANG Wen, GU Yanmei, WANG Zhiming, et al. SpeechFake: A Large-Scale Multilingual Speech Deepfake Dataset Incorporating Cutting-Edge Generation Methods[C]// ACL. The 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1:Long Papers). Stroudsburg, ACL, 2025: 9985-9998.
|
 ), FENG Chuanlin1, LI A1,3, MAO Bowen2
), FENG Chuanlin1, LI A1,3, MAO Bowen2