Netinfo Security ›› 2024, Vol. 24 ›› Issue (7): 1076-1087.doi: 10.3969/j.issn.1671-1122.2024.07.009
Previous Articles Next Articles
Research on TTP Extraction Method Based on Pre-Trained Language Model and Chinese-English Threat Intelligence
REN Changyu1, ZHANG Ling2, JI Hangyuan1, YANG Liqun3( )
)
- 1. State Key Laboratory of Complex & Critical Software Environment, Beihang University, Beijing 100083, China
2. School of Electrical Engineering, Zhengzhou University, Zhengzhou 450001, China
3. School of Cyber Science and Technology, Beihang University, Beijing 100083, China
-
Received:2024-04-03Online:2024-07-10Published:2024-08-02
CLC Number:
Cite this article
REN Changyu, ZHANG Ling, JI Hangyuan, YANG Liqun. Research on TTP Extraction Method Based on Pre-Trained Language Model and Chinese-English Threat Intelligence[J]. Netinfo Security, 2024, 24(7): 1076-1087.
share this article
Add to citation manager EndNote|Ris|BibTeX
URL: http://netinfo-security.org/EN/10.3969/j.issn.1671-1122.2024.07.009
| 参数名称 | 参数值 |
|---|---|
| 样本总数 | 17700条 |
| 中文样本数 | 8877条 |
| 英文样本数 | 8823条 |
| 样本平均长度 | 24.14词/条 |
| 样本最大长度 | 142词/条 |
| 样本最小长度 | 4词/条 |
| 单词总数 | 427263个 |
| 数据集 | 语种 | 样本数/条 | TTP类别数/种 |
|---|---|---|---|
| TRAM[ | 英文 | 4070 | 50 |
| 文献[5]数据集 | 英文 | 12945 | 188 |
| TTPHunter[ | 英文 | 8387 | 50 |
| BTICD(本文) | 中文、英文 | 17700(含353条白样本) | 236(含白标签) |

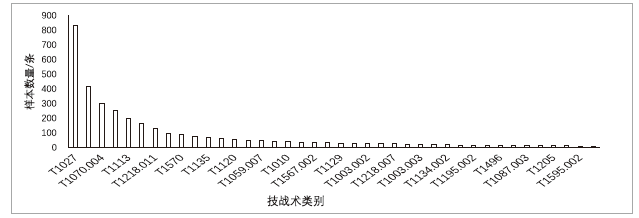
| 样本内容 | TTP标注 |
|---|---|
| downpaper使用powershell执行 | T1059.001 |
| 植入ngrok反向代理 | T1090 |
| netboy and revbshell, gather system information | T1082 |
| hawkball 创建了一个 cmd.exe 反向 shell,执行命令并通过命令行上传输出 | T1059.003 |
| apt28 has used compromised email accounts to send credential phishing emails | T1586.002 |
| blacklotus 尝试使用合法文件名隐藏其部署在 esp 上的文件,例如 grubx64.efi(如果在受感染计算机上启用了 uefi 安全启动)或 bootmgfw.efi(如果在受感染计算机上禁用了 uefi 安全启动) | T1036.005 |
| apt32 has used scheduled task raw xml with a backdated timestamp of june 2, 2016. the group has also set the creation time of the files dropped by the second stage of the exploit to match the creation time of kernel32.dll. additionally, apt32 has used a random value to modify the timestamp of the file storing the clientid | T1070.006 |
| 当文件执行时,Windows 不会自动加载此数据,因为它位于 pe 结构之外 | white |
| 15c87b1820b67d4d2b082e81fd7946dd00a1072441b7551e38fccd5575bf18c2 | white |
| In january 2023, there was a significant 41% decrease in ransomware victim posting rates across all groups compared to december 2022, signaling an overall decline in ransomware activities | white |
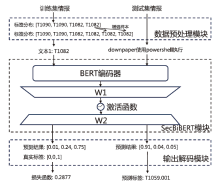

| 划分 | 中文样本数/条 | 英文样本数/条 | 样本总数/条 | TTP类别数/种 |
|---|---|---|---|---|
| 训练集 | 7028 | 7037 | 14065 | 236 |
| 测试集 | 1849 | 1786 | 3635 | 236 |
| 参数名称 | 参数值 |
|---|---|
| 文本特征向量维度 | 768 |
| 优化器 | Adam |
| 学习率 | 5e-5 |
| 损失函数 | Focal loss |
| 批次大小(条/批次) | 12 |
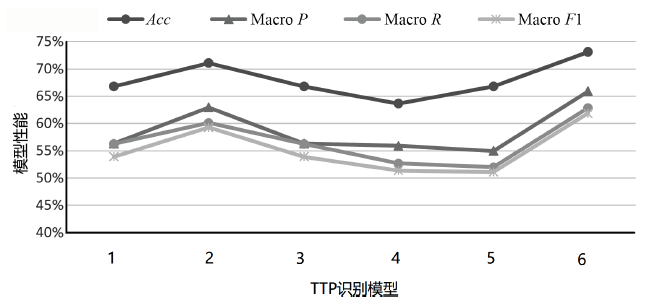
| 模型 | Acc | Macro P | Macro R | Macro F1 |
|---|---|---|---|---|
| BERT-base | 66.80% | 56.32% | 56.25% | 53.90% |
| BERT-base-chinese | 71.06% | 62.95% | 60.10% | 59.28% |
| SecBERT | 66.80% | 56.32% | 56.25% | 53.90% |
| SecBERT-Plus | 63.66% | 55.89% | 52.67% | 51.37% |
| SciBERT | 66.80% | 54.96% | 52.00% | 51.09% |
| SecBiBERT(本文) | 73.09% | 65.90% | 62.85% | 61.85% |
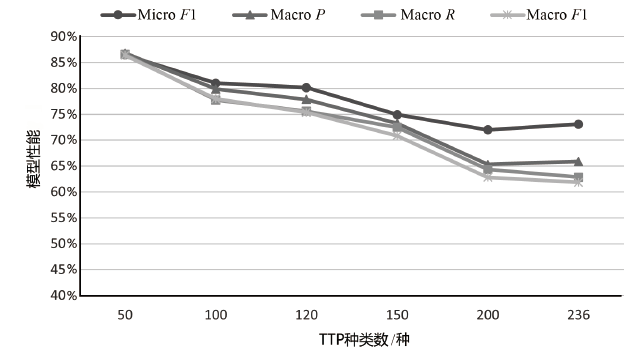
| 模型 | K /种 | Micro F1 | Macro P | Macro R | Macro F1 |
|---|---|---|---|---|---|
| TCENet[ | 6 | 94.10% | 97.00% | 97.30% | 97.10% |
| SciBERT[ | 50 | 88.20% | 83.80% | 80.60% | 81.40% |
| SecBiBERT | 50 | 86.49% | 86.79% | 86.57% | 86.41% |
| SecBiBERT | 100 | 81.00% | 79.87% | 77.76% | 77.99% |
| SecBiBERT | 120 | 80.14% | 77.87% | 75.58% | 75.33% |
| SecBiBERT | 150 | 74.92% | 73.25% | 72.49% | 70.85% |
| SecureBERT[ | 188 | 72.50% | — | — | — |
| SecBiBERT | 200 | 71.99% | 65.33% | 64.34% | 62.81% |
| rcATT[ | 215 | 21.14%* | 81.73% | 8.21% | 14.92%* |
| SecBiBERT | 236 | 73.09% | 65.90% | 62.85% | 61.85% |
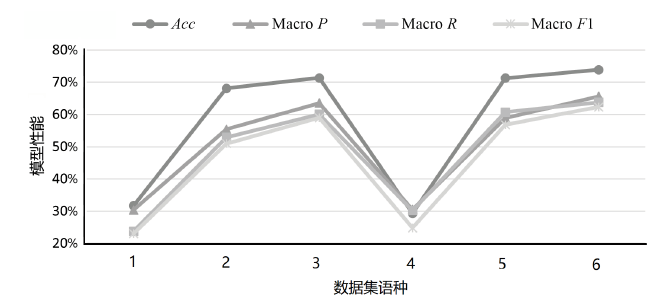
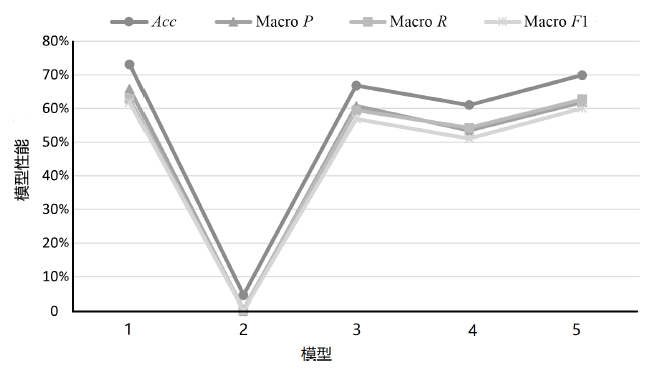
| 序号 | 训练集 语种 | 测试集 语种 | Acc | Macro P | Macro R | Macro F1 |
|---|---|---|---|---|---|---|
| 1 | 英文 | 中文 | 31.68% | 30.34% | 23.77% | 23.03% |
| 2 | 中文 | 中文 | 68.09% | 55.39% | 52.90% | 50.97% |
| 3 | 中文、英文 | 中文 | 71.35% | 63.53% | 60.08% | 58.97% |
| 4 | 中文 | 英文 | 29.30% | 30.53% | 30.17% | 24.82% |
| 5 | 英文 | 英文 | 71.28% | 58.92% | 60.75% | 56.81% |
| 6 | 中文、英文 | 英文 | 73.87% | 65.66% | 63.76% | 62.32% |
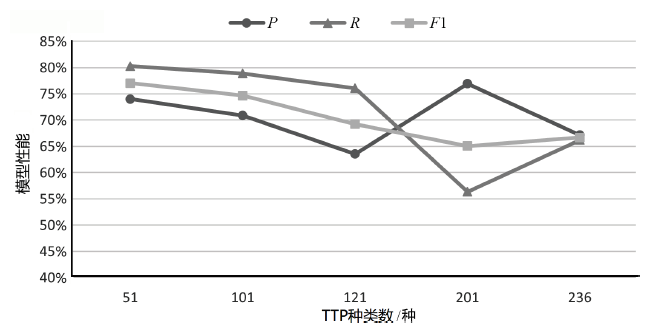
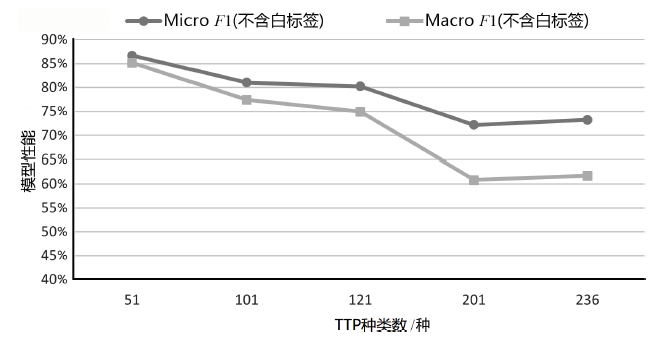
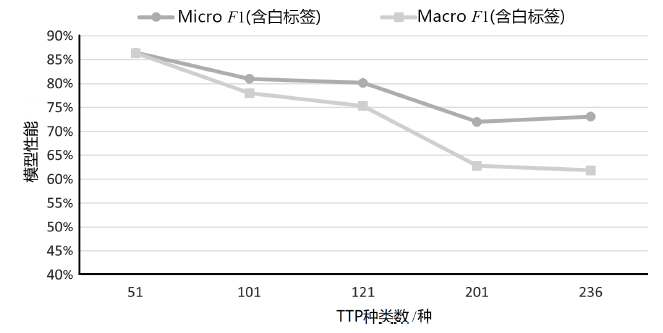
| K/种 | P | R | F1 | Micro F1(不含 白标签) | Macro F1 (不含 白标签) | Micro F1(含白标签) | Macro F1 (含白 标签) |
|---|---|---|---|---|---|---|---|
| 51 | 74.03% | 80.28% | 77.03% | 86.68% | 85.15% | 86.49% | 86.41% |
| 101 | 70.89% | 78.87% | 74.67% | 81.05% | 77.39% | 81.00% | 77.99% |
| 121 | 63.53% | 76.06% | 69.23% | 80.23% | 74.91% | 80.14% | 75.33% |
| 201 | 76.92% | 56.34% | 65.04% | 72.19% | 60.84% | 71.99% | 62.81% |
| 236 | 67.14% | 66.20% | 66.67% | 73.23% | 61.71% | 73.09% | 61.85% |


| 模型 | Acc | Macro P | Macro R | Macro F1 |
|---|---|---|---|---|
| SecBiBERT | 73.09% | 65.90% | 62.85% | 61.85% |
| 不使用数据增强 | 4.57% | 0.02% | 0.42% | 0.04% |
| 不使用Focal Loss作为损失函数 | 66.85% | 60.74% | 59.52% | 56.94% |
| 不使用分类器 | 61.05% | 53.41% | 54.26% | 51.10% |
| 数据集中不添加白样本 | 69.93% | 61.96% | 62.78% | 60.11% |
| [1] | STROM B E, APPLEBAUM A, MILLER D P, et al. MITRE ATT&CK: Design and Philosophy[M]. Technical Report: The MITRE Corporation, 2018. |
| [2] | SHIN Y, KIM K, LEE J J, et al. ART: Automated Reclassification for Threat Actors Based on ATT&CK Matrix Similarity[C]// IEEE. 2021 World Automation Congress (WAC). New York: IEEE, 2021: 15-20. |
| [3] | JON B. Our TRAM Large Language Model Automates TTP Identification in CTI Reports[R]. Virginia: MITRE Engenuity, CT0075, 2023. |
| [4] | YOU Yizhe, JIANG Jun, JIANG Zhengwei, et al. TIM: Threat Context-Enhanced TTP Intelligence Mining on Unstructured Threat Data[J]. Cybersecurity, 2022, 5(1): 2523-3246. |
| [5] | ORBINATO V, BARBARACI M, NATELLA R, et al. Automatic Mapping of Unstructured Cyber Threat Intelligence: An Experimental Study: (Practical Experience Report)[C]// IEEE. 2022 IEEE 33rd International Symposium on Software Reliability Engineering (ISSRE). New York: IEEE, 2022: 181-192. |
| [6] | LEGOY V, CASELLI M, SEIFERT C, et al. Automated Retrieval of Att&CK Tactics and Techniques for Cyber Threat Reports[EB/OL]. (2020-04-29)[2024-03-30]. https://arxiv.org/abs/2004.14322. |
| [7] | MARCHIORI F, CONTI M, VERDE N V. Stixnet: A Novel and Modular Solution for Extracting All Stix Objects in Cti Reports[C]// ACM. Proceedings of the 18th International Conference on Availability, Reliability and Security. New York: ACM, 2023: 1-11. |
| [8] | ABDEEN B, AL-SHAER E, SINGHAL A, et al. Smet: Semantic Mapping of Cve to ATT&CK and Its Application to Cybersecurity[C]// Springer. IFIP Annual Conference on Data and Applications Security and Privacy. Heidelberg: Springer, 2023: 243-260. |
| [9] | QIHOO360. Luwak TTP Extractor[EB/OL]. (2023-07-09)[2024-03-30]. https://github.com/Qihoo360/Luwak/tree/master. |
| [10] | RANI N, SAHA B, MAURYA V, et al. TTPHunter: Automated Extraction of Actionable Intelligence as TTPs from Narrative Threat Reports[C]// ACM. Proceedings of the 2023 Australasian Computer Science Week. New York: ACM, 2023: 126-134. |
| [11] | RANI N, SAHA B, MAURYA V, et al. TTPXHunter: Actionable Threat Intelligence Extraction as TTPs form Finished Cyber Threat Reports[EB/OL]. (2024-03-05)[2024-03-30]. https://arxiv.org/abs/2403.03267. |
| [12] | WU Shangyuan, SHEN Guowei, GUO Chun, et al. Threat Intelligence-Driven Dynamic Threat Hunting Method[J]. Netinfo Security, 2023, 23(6): 91-103. |
| 吴尚远, 申国伟, 郭春, 等. 威胁情报驱动的动态威胁狩猎方法[J]. 信息网络安全, 2023, 23(6):91-103. | |
| [13] | AJMAL A B, ALAM M, KHALIQ A A, et al. Last Line of Defense: Reliability through Inducing Cyber Threat Hunting with Deception in Scada Networks[J]. IEEE Access, 2021, 9: 126789-126800. |
| [14] | BINDRA A. Securing the Power Grid: Protecting Smart Grids and Connected Power Systems from Cyberattacks[J]. IEEE Power Electronics Magazine, 2017, 4(3): 20-27. |
| [15] | ZHOU Yinghai, REN Yitong, YI Ming, et al. Cdtier: A Chinese Dataset of Threat Intelligence Entity Relationships[J]. IEEE Transactions on Sustainable Computing, 2023, 8(4): 627-638. |
| [16] | DEVLIN J, CHANG M W, LEE K, et al. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding[C]// ACL. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies, Volume 1 (Long and Short Papers). Minneapolis: ACL, 2019: 4171-4186. |
| [17] | SUN Hongzhe, WANG Jian, WANG Peng, et al. Network Intrusion Detection Method Based on Attention-BiTCN[J]. Netinfo Security, 2024, 24(2): 309-318. |
| 孙红哲, 王坚, 王鹏, 等. 基于Attention-BiTCN的网络入侵检测方法[J]. 信息网络安全, 2024, 24(2):309-318. | |
| [18] | HENDRYCKS D, GIMPEL K. Gaussian Error Linear Units (GELUs)[EB/OL]. (2016-06-27)[2024-03-30]. https://arxiv.org/abs/1606.08415. |
| [19] | LIN T Y, GOYAL P, GIRSHICK R, et al. Focal Loss for Dense Object Detection[C]// IEEE. 2017 IEEE International Conference on Computer Vision (ICCV). New York: IEEE, 2017: 2999-3007. |
| [20] | LIU Yinhan, OTT M, GOYAL N, et al. Roberta: A Robustly Optimized Bert Pretraining Approach[EB/OL]. (2019-07-26)[2024-03-30]. https://arxiv.org/abs/1907.11692. |
| [1] | WEN Wen, LIU Qinju, KUANG Lin, REN Xuejing. Research and Scheme Design of Cyber Threat Intelligence Sharing under Privacy Protection System [J]. Netinfo Security, 2024, 24(7): 1129-1137. |
| [2] | YUAN Wenxin, CHEN Xingshu, ZHU Yi, ZENG Xuemei. HTTP Payload Covert Channel Detection Method Based on Deep Learning [J]. Netinfo Security, 2023, 23(7): 53-63. |
| [3] | WU Shangyuan, SHEN Guowei, GUO Chun, CHEN Yi. Threat Intelligence-Driven Dynamic Threat Hunting Method [J]. Netinfo Security, 2023, 23(6): 91-103. |
| [4] | CHEN Liquan, XUE Yuxin, JIANG Yinghua, ZHU Yaqing. Design of Certificate Transparency Log System Based on SM2 Algorithm [J]. Netinfo Security, 2023, 23(11): 9-16. |
| [5] | YE Huanrong, LI Muyuan, JIANG Bo. Research on DGA Malicious Domain Name Detection Method Based on Transfer Learning and Threat Intelligence [J]. Netinfo Security, 2023, 23(10): 8-15. |
| [6] | FENG Jingyu, ZHANG Qi, HUANG Wenhua, HAN Gang. A Cyber Threat Intelligence Sharing Scheme Based on Cross-Chain Interaction [J]. Netinfo Security, 2022, 22(5): 21-29. |
| [7] | CHENG Shunhang, LI Zhihua. Research on Threat Intelligence Entity Recognition Method Based on MRC [J]. Netinfo Security, 2021, 21(10): 76-82. |
| [8] | CHEN Cheng, LUO Senlin, WU Qian, YANG Peng. Research on Covert Channel Construction Method Based on HTTP Protocol Combination [J]. Netinfo Security, 2020, 20(6): 57-64. |
| [9] | ZHANG Yongsheng, WANG Zhi, WU Yijie, DU Zhenhua. Cyber Threat Intelligence Propagation Based on Conformal Prediction [J]. Netinfo Security, 2020, 20(6): 90-95. |
| [10] | WANG Changjie, LI Zhihua, ZHANG Ye. A Threat Intelligence Generation Method for Malware Family [J]. Netinfo Security, 2020, 20(12): 83-90. |
| [11] | Yi TANG, Zhishuang WANG. Research on HTTPS Configurations for E-banking Systems [J]. Netinfo Security, 2017, 17(1): 16-22. |
| [12] | Lei GUAN, Guangjun HU, Zhuan WANG. Research on Network Security Situational Awareness Technology Based on Big Data [J]. Netinfo Security, 2016, 16(9): 45-50. |
| [13] | Liping XU, Wenjiang HAO. Analysis and Enlightenment of US Government and Enterprise Cyber Threat Intelligence [J]. Netinfo Security, 2016, 16(9): 278-284. |
| [14] | Guofeng ZHAO, Yong CHEN, Xinheng WANG. Research on the Web Front-end Hijacking and Defense against HTTPS [J]. Netinfo Security, 2016, 16(3): 15-20. |
| [15] | Feng-fan YANG, Jia-yong LIU, Dian-hua TANG. Research of HTTPS Session Hijacking Based on Script Injection [J]. Netinfo Security, 2015, 15(3): 59-63. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||