Netinfo Security ›› 2020, Vol. 20 ›› Issue (8): 71-80.doi: 10.3969/j.issn.1671-1122.2020.08.009
Previous Articles Next Articles
Research on K-Nearest Neighbor High Speed Matching Algorithm in Network Intrusion Detection
XU Guotian( )
)
- Cyber Crime Investigation Department, Criminal Investigation Police University of China, Shenyang 110854, China
-
Received:2020-07-20Online:2020-08-10Published:2020-10-20 -
Contact:XU Guotian E-mail:459536384@qq.com
CLC Number:
Cite this article
XU Guotian. Research on K-Nearest Neighbor High Speed Matching Algorithm in Network Intrusion Detection[J]. Netinfo Security, 2020, 20(8): 71-80.
share this article
Add to citation manager EndNote|Ris|BibTeX
URL: http://netinfo-security.org/EN/10.3969/j.issn.1671-1122.2020.08.009
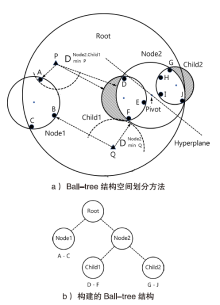
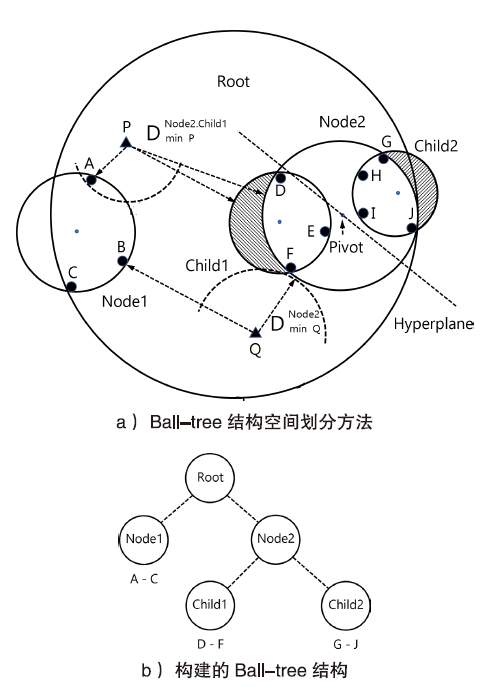

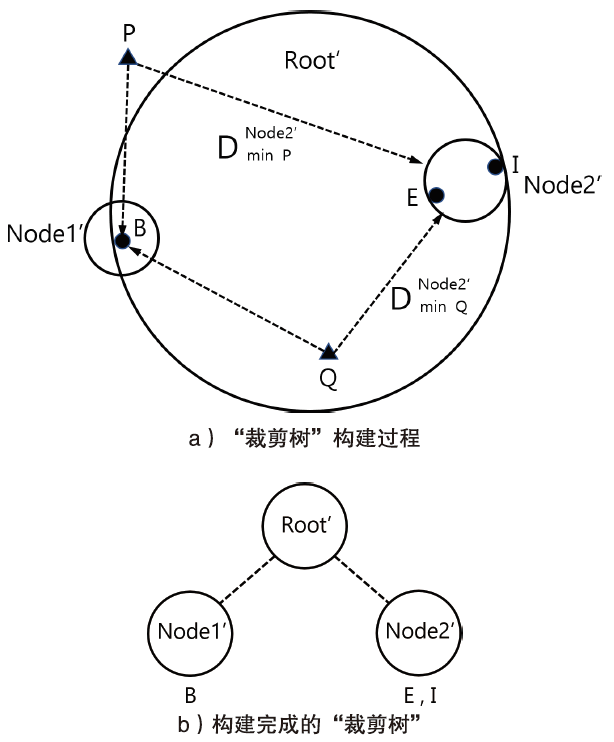

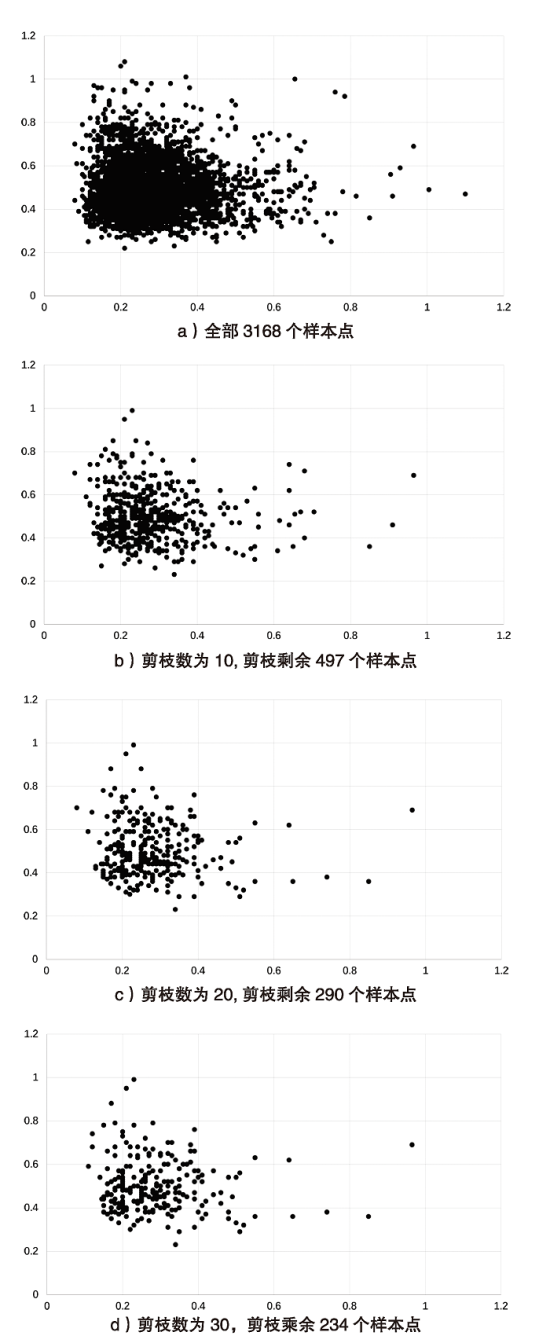
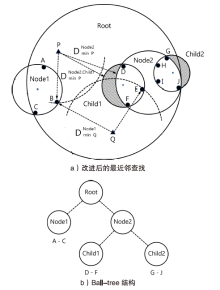
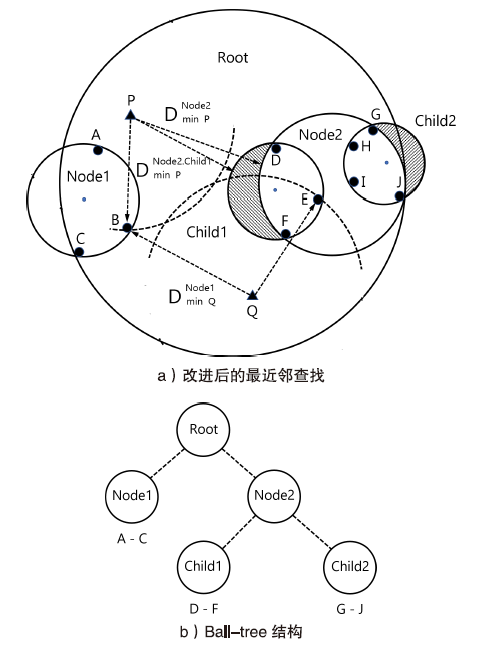


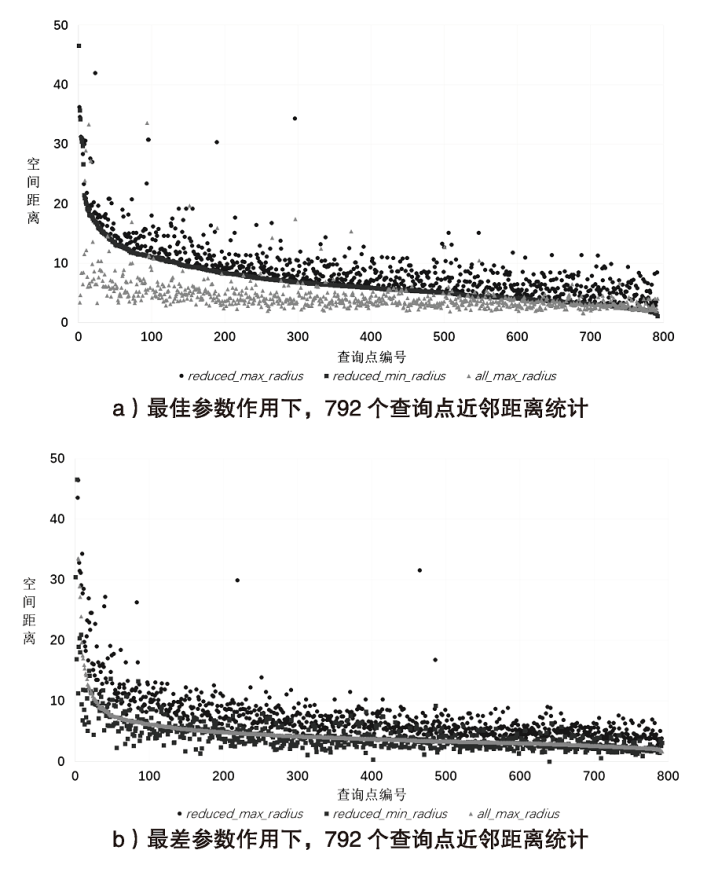
| 设备型号 | 操作系统 | 运行内存 | 存储容量 | CPU类型 | 编程语言 |
|---|---|---|---|---|---|
| ThinkPad P1 | Windows 10 | 32 GB | 2 TB | i7-9850H | Python |
| 样本集 | 特征数 | 样本总数 | 原始算法 | 改进算法 |
|---|---|---|---|---|
| Wine_ | 12 | 160 | 0.762 S | 0.022 S |
| Forest | 11 | 496 | 0.723 S | 0.185 S |
| Bcwd_ | 30 | 530 | 0.602 S | 0.173 S |
| Abalon | 08 | 4026 | 15.985 S | 0.903 S |
| Spam | 56 | 4200 | 9.171 S | 0.546 S |
| Harus_ | 526 | 6300 | 253.049 S | 16.519 S |
| Swar_ | 2360 | 8100 | 1126.05 S | 69.046 S |
| Shut_ | 09 | 56000 | 12160.42 S | 753.15 S |
| [1] | HU Mingxia. Instrusion Detection Algorithm Based on BP Neural Network[J]. Computer Engineering, 2012,38(6):148-150. |
| 胡明霞. 基于BP神经网络的入侵检测算法[J]. 计算机工程, 2012,38(6):148-150. | |
| [2] | XIANG Changsheng, ZHANG Linfeng. Application of Support Vector Machine Optimized by Particle Swarm Optimization Algorithm in Network Intrusion Detection[J]. Computer Engineering and Design, 2013,34(4):1222-1225. |
| 向昌盛, 张林峰. PSO-SVM在网络入侵检测中的应用[J]. 计算机工程与设计, 2013,34(4):1222-1225. | |
| [3] | DENG Chenwei, HUANG Guangbin, XU Jia. Extreme Learning Machines: New Trends and Applications[J]. Science China Information Sciences, 2015,58(2):1-16. |
| [4] | LIAO Yihua. Using of K-Nearest Neighbor Classifier for Intrusion Detection[J]. Computers and Security, 2002,5(21):439-448. |
| [5] | LI Yang, FANG Binxing, GUO Li, et al. Supervised Intrusion Detedtion Based on Active Learning and TCM-KNN Algorithm[J]. Chinese Journal of Computers, 2007,30(8):1464-1473. |
| 李洋, 方滨兴, 郭莉, 等. 基于主动学习和TCM-KNN方法的有指导入侵检测技术[J]. 计算机学报, 2007,30(8):1464-1473. | |
| [6] | Reyadh Shaker Naoum, Zainab Namh Al-Sultani. Learning Vector Quantization(LVQ)and K-Nearest Neighbor for Intrusion Classification[J]. World of Computer Science and Information Technology Journal, 2012,3(2):105-109. |
| [7] | JAMSHIDI Y, Nezamabadi-pour H. A Lattice based Nearest Neighbor Classifier for Anomaly Intrusion Detection[J]. Journal of Advances in Computer Research, 2013,4(4):51-60. |
| [8] | MA Zhenghui, KABAN A. K-Nearest-Neighbors with A Novel Similarity Measure for Intrusion Detection[C]// IEEE. 13rd IEEE UK Workshop on Computational Intelligence, September 9-11, 2013, Guildford, United Kingdom. Guildford: IEEE, 2013: 266-271. |
| [9] | HUA Huiyou, CHEN Qimai, LIU Hai. Hybrid Kmeans with KNN for Network Intrusion Detection Algorithm[J]. ComputerScience, 2016,43(3):158-162. |
| 华辉有, 陈启买, 刘海. 一种融合Kmeans和 KNN的网络入侵检测算法[J]. 计算机科学, 2016,43(3):158-162. | |
| [10] | LI Ronglu, HU Yunfa. Density-based Training Sample Clipping Method for KNN Text Classifier[J]. Computer Research and Development, 2004,41(4):539-546. |
| 李荣陆, 胡运发. 基于密度的KNN文本分类器训练样本裁剪方法[J]. 计算机研究与发展, 2004,41(4):539-546. | |
| [11] | TING Liu, ANDREW W, ALEXANDER Gra. New Algorithms for Efficient High-Dimensional Nonparametric Classification[J]. Journal of Machine Learning Research, 2006,40(3):1135-1158. |
| [12] | MOHAMAD Dolatshah, AliHadian, Behrouz. Ball*-tree: Efficient Spatial Indexing for Constrained Nearest-neighbor Search in Metric Spaces[J]. ArXiv, 2015,38(16):40-44. |
| [13] | HAO Weijie, WANG Yanfei, HU Jingwei, et al. An Improved KNN Algorithm based on Hyper-sphere Region Partition[J]. Journal of Qingdao University, 2017,30(1):85-90. |
| 郝卫杰, 王艳飞, 胡敬伟, 等. 基于超球区域划分的改进KNN算法[J]. 青岛大学学报, 2017,30(1):85-90. | |
| [14] | LIU Duanyang, ZHENG Jiangfan, LIU Zhi. Research of Parallel KNN Algorithm based on CUDA[J]. MinicomputerSystem, 2019,40(6):1197-1202. |
| [15] | TING Liu, Moore, ANDREW W. New Algorithms for Efficient High-dimensional Nonparametric Classification[J]. Journal of Machine Learning Research, 2006,44(10):1135-1158. |
| [16] | YANG Shuaihua, ZHANG Qinghua. Research on K-nearest Neighbor Text Classification Algorithm of Approximation Set of Rough Set[J]. Minicomputer System, 2017,38(10):2192-2196. |
| 杨帅华, 张清华. 粗糙集近似集的 KNN 文本分类算法研究[J]. 小型微型计算机系统, 2017,38(10):2192-2196. | |
| [17] | LU Dunli, NING Qian, ZANG Jun. Improved KNN Algorithm based on BP Neural Network Decision Making[J]. Computer Application, 2017,37(2):65-68. |
| 路敦利, 宁芊, 臧军. 基于BP神经网络决策的 KNN 改进算法[J]. 计算机应用, 2017,37(2):65-68. | |
| [18] | WANG Zhihua, LIU Shaoting, LUO Qi. KNN Classification Algorithm based on Improved K-modes Clustering[J]. Computer Engineering and Design, 2019,40(8):2228-2234. |
| 王志华, 刘绍廷, 罗齐. 基于改进K-modes聚类的KNN分类算法[J]. 计算机工程与设计, 2019,40(8):2228-2234. | |
| [19] | HUANG Chao, CHEN Junhua. Chinese Text Classification based on Improved K Nearest Neighbor Algorithm[J]. Journal of Shanghai Normal University, 2019,48(1):96-101. |
| 黄超, 陈军华. 基于改进K最近邻算法的中文文本分类[J]. 上海师范大学学报, 2019,48(1):96-101. | |
| [20] | ZHOU Qingping, TAN Changgeng, WANG Hongjun, et al. Improved KNN Text Classification Algorithm based on Clustering[J]. Computer Application Research, 2016,33(11):3374-3382. |
| 周庆平, 谭长庚, 王宏君, 等. 基于聚类改进的KNN文本分类算法[J]. 计算机应用研究, 2016,33(11):3374-3382. | |
| [21] | SUN Xin, OUYANG Tong, YAN Ximin, et al. The Weighted KNN Text Categorization Algorithm based on Training Set Cutting[J]. Information Engineering, 2016,2(6):8-16. |
| 孙新, 欧阳童, 严西敏, 等. 基于训练集裁剪的加权K近邻文本分类算法[J]. 情报工程, 2016,2(6):8-16. |
| [1] | LI Qiao, LONG Chun, WEI Jinxia, ZHAO Jing. A Hybrid Model of Intrusion Detection Based on LMDR and CNN [J]. Netinfo Security, 2020, 20(9): 117-121. |
| [2] | JIANG Nan, CUI Yaohui, WANG Jian, WU Jinchao. Context-based Attack Scenario Reconstruction Model for IDS Alarms [J]. Netinfo Security, 2020, 20(7): 1-10. |
| [3] | ZHANG Xiaoyu, WANG Huazhong. Intrusion Detection of ICS Based on Improved Border-SMOTE for Unbalance Data [J]. Netinfo Security, 2020, 20(7): 70-76. |
| [4] | PENG Zhonglian, WAN Wei, JING Tao, WEI Jinxia. Research on Intrusion Detection Method Based on Modified CGANs [J]. Netinfo Security, 2020, 20(5): 47-56. |
| [5] | WANG Rong, MA Chunguang, WU Peng. An Intrusion Detection Method Based on Federated Learning and Convolutional Neural Network [J]. Netinfo Security, 2020, 20(4): 47-54. |
| [6] | LUO Wenhua, XU Caidian. Network Intrusion Detection Based on Improved MajorClust Clustering [J]. Netinfo Security, 2020, 20(2): 14-21. |
| [7] | Jian KANG, Jie WANG, Zhengxu LI, Guangda ZHANG. A Model for Anomaly Intrusion Detection with Different Feature Extraction Strategies in IoT [J]. Netinfo Security, 2019, 19(9): 21-25. |
| [8] | Wenying FENG, Xiaobo GUO, Yuanye HE, Cong XUE. Intrusion Detection Model Based on Feedforward Neural Network [J]. Netinfo Security, 2019, 19(9): 101-105. |
| [9] | Xuli RAO, Pengna XU, Zhide CHEN, Li XU. Network Intrusion Detection with Incomplete Information Based on Deep Learning [J]. Netinfo Security, 2019, 19(6): 53-60. |
| [10] | Jinghao LIU, Siping MAO, Xiaomei FU. Intrusion Detection Model Based on ICA Algorithm and Deep Neural Network [J]. Netinfo Security, 2019, 19(3): 1-10. |
| [11] | Hong CHEN, Yue XIAO, Chenglong XIAO, Jianhu CHEN. The Intrusion Detection Method of SMOTE Algorithm with Maximum Dissimilarity Coefficient Density [J]. Netinfo Security, 2019, 19(3): 61-71. |
| [12] | Zheng TIAN, Shu LI, Yizhen SUN, Xi LI. Industrial Control System Intrusion Detection Model Based on S7 Protocol [J]. Netinfo Security, 2019, 19(11): 8-13. |
| [13] | Yang ZHANG, Yuangang YAO. Research on Network Intrusion Detection Based on Xgboost [J]. Netinfo Security, 2018, 18(9): 102-105. |
| [14] | Gelin ZHANG, Yong LI. Non-negative Matrix Factorization Optimization and Its Application in Network Intrusion Detection [J]. Netinfo Security, 2018, 18(8): 73-78. |
| [15] | Shuning WEI, Xingru CHEN, Yong JIAO, Jin WANG. Research on the Application of AR-OSELM Algorithm in Network Intrusion Detection [J]. Netinfo Security, 2018, 18(6): 1-6. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||