信息网络安全 ›› 2026, Vol. 26 ›› Issue (3): 399-411.doi: 10.3969/j.issn.1671-1122.2026.03.006
融合自监督表示与多尺度建模的AI合成语音检测方法
刘彦飞1,2, 刘德智1( ), 冯川琳1, 李阿1,3, 毛博文2
), 冯川琳1, 李阿1,3, 毛博文2
- 1.重庆警察学院警务情报协同创新中心,重庆 401331
2.天津大学人工智能学院,天津 300072
3.中国人民公安大学信息网络安全学院,北京 100038
-
收稿日期:2025-10-08出版日期:2026-03-10发布日期:2026-03-30 -
通讯作者:刘德智 E-mail:dzhiliu@163.com -
作者简介:刘彦飞(1985—),男,重庆,教授,博士,主要研究方向为复杂网络建模与分析、数据挖掘、机器学习、知识图谱|刘德智(1998—),男,重庆,研究员,硕士,主要研究方向为知识图谱、大模型|冯川琳(2006—),男,重庆,本科,主要研究方向为复杂网络建模与分析、数据挖掘、机器学习|李阿(2003—),男,重庆,硕士研究生,主要研究方向为复杂网络建模与分析、数据挖掘、机器学习|毛博文(1980—),男,天津,正高级工程师,博士,主要研究方向为网络空间治理、公共安全知识工程 -
基金资助:重庆市教育委员会科学技术研究计划(KJZD-M202501701);重庆市教育委员会科学技术研究计划(KJZD-K20221701);重庆市高等教育教学改革研究项目(222171)
An AI-Generated Speech Detection Method Integrating Self-Supervised Representations and Multi-Scale Modeling
LIU Yanfei1,2, LIU Dezhi1(), FENG Chuanlin1, LI A1,3, MAO Bowen2
- 1. Public Security Intelligence Collaborative Innovation Center, Chongqing Police College, Chongqing 401331, China
2. School of Artificial Intelligence, Tianjin University, Tianjin 300072, China
3. School of Cybersecurity and Information Security, People’s Public Security University of China, Beijing 100038, China
-
Received:2025-10-08Online:2026-03-10Published:2026-03-30
摘要:
随着人工智能技术的发展,AI生成语音被广泛用于语音冒充和电信诈骗等违法活动,同时也带来语音可信性与内容真实性方面的安全风险。在复杂真实环境下实现真人语音与AI合成语音的准确区分,已成为深度伪造语音检测与语音安全研究中的重要问题。现有AI语音检测方法多依赖传统声学特征或单一时序建模结构,对多尺度合成伪迹刻画能力有限,在跨模型、跨说话人及复杂噪声条件下性能下降明显。针对上述问题,文章提出一种融合Wav2Vec2.0自监督预训练模型与多尺度卷积神经网络的AI语音检测方法。该方法利用预训练模型提取高层语音表示,通过多尺度卷积并行建模不同尺度感知域内的局部异常特征,并引入多头残差门控注意力统计池化机制,实现关键时序信息的自适应聚合。实验结果表明,该方法在AI语音检测任务中整体性能优于传统基线模型,F1分数和AUC分别提升约6.6%和2.1%,显著提升伪造语音的检出能力与鲁棒性,消融实验进一步验证多尺度卷积与多头门控注意力统计池化结构在复杂声学与跨生成模型场景下的有效性与稳定性。
中图分类号:
引用本文
刘彦飞, 刘德智, 冯川琳, 李阿, 毛博文. 融合自监督表示与多尺度建模的AI合成语音检测方法[J]. 信息网络安全, 2026, 26(3): 399-411.
LIU Yanfei, LIU Dezhi, FENG Chuanlin, LI A, MAO Bowen. An AI-Generated Speech Detection Method Integrating Self-Supervised Representations and Multi-Scale Modeling[J]. Netinfo Security, 2026, 26(3): 399-411.

图1
融合Wav2Vec2.0自监督预训练表示与多尺度卷积神经网络的检测框架
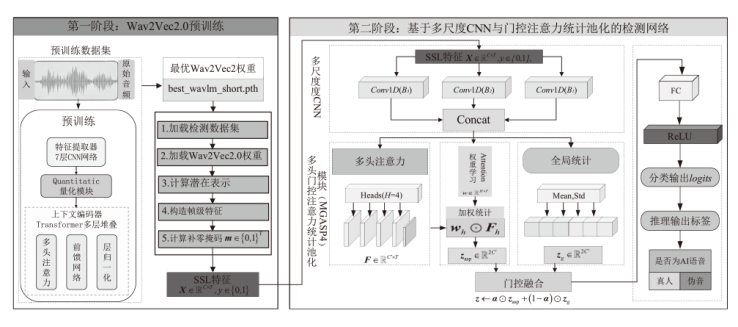
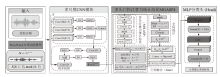
图2
卷积神经网络结构
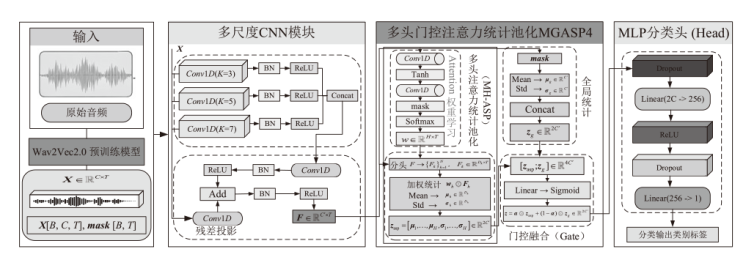
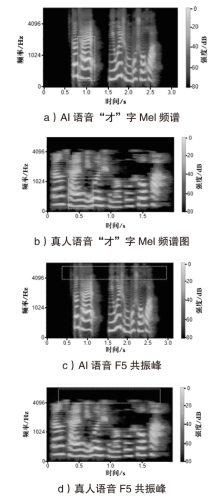
图3
AI语音与真人语音特征对比
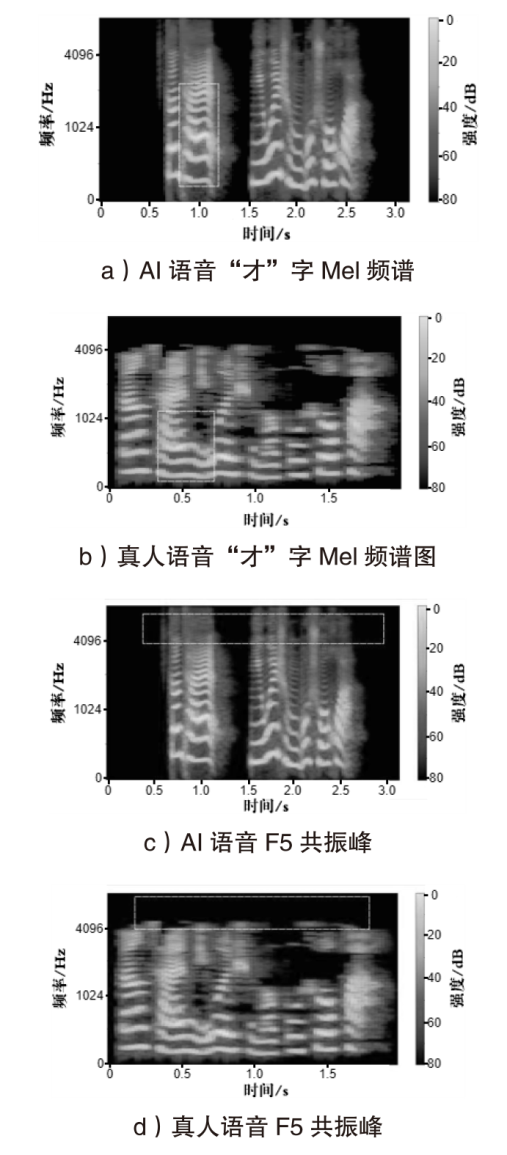
表1
预训练模型对比
| 模型 | 核心架构 | 预训练目标 | 优势 | 局限性 | 检测 适用性 |
|---|---|---|---|---|---|
| HuBERT | CNN + Transformer | 聚类伪标签 + 掩蔽预测 | 表征能力强 | 训练复杂、 资源消耗高 | 中 |
| WavLM | CNN + Transformer | 掩蔽建模 + 扰动/噪声建模 | 鲁棒性与长时建模较好 | 成本较高 | 中高 |
| XLS-R | CNN + Transformer | 多语种对比学习目标 | 多语种迁移能力强 | 规模大、 推理慢 | 中 |
| Wav2Vec2.0 | CNN + Transformer | 掩蔽预测 + 对比学习 | 简洁高效,短语音伪迹特征提取稳定 | 需结合下游结构增强判别性 | 高 |
图4
预训练前10轮次验证集损失曲线
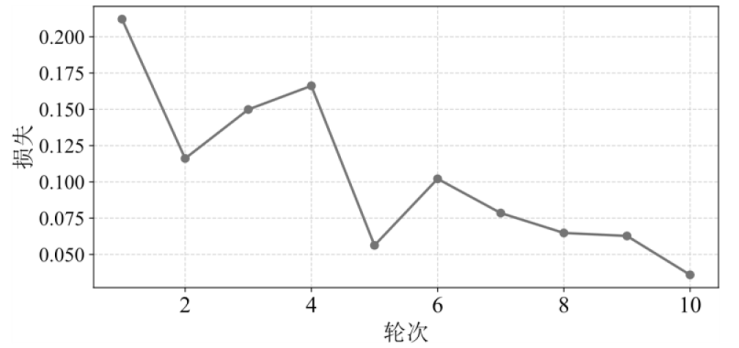
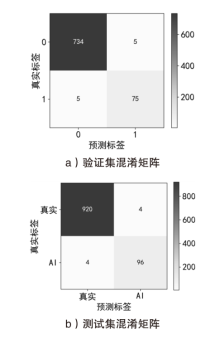
图5
SpeechFake数据集上验证集和测试集混淆矩阵
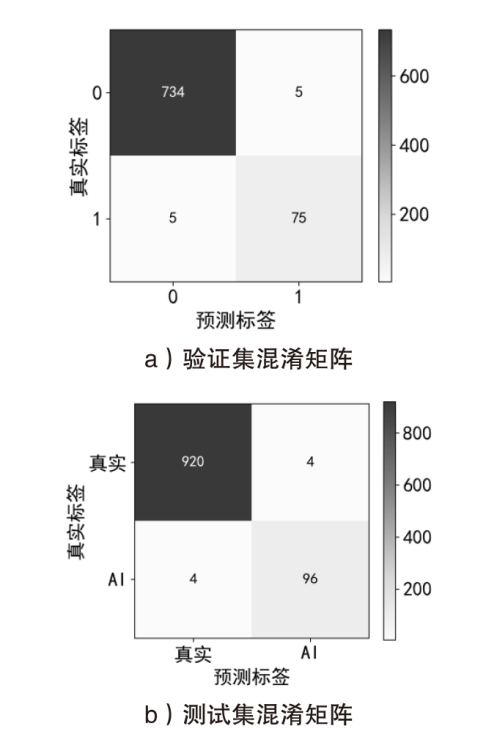
表2
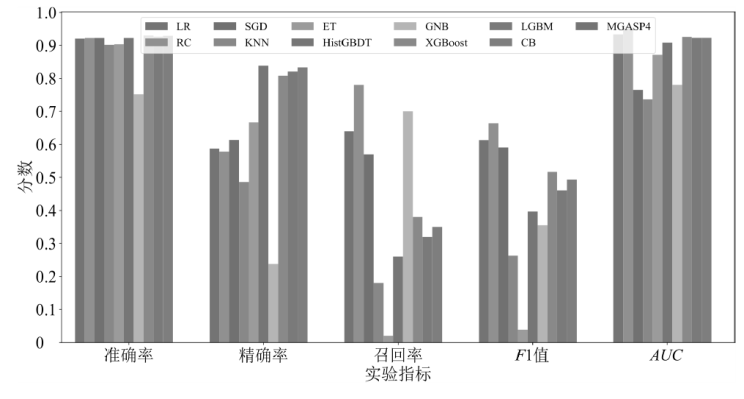
不同基线模型在SpeechFake数据集上的各项指标表现
| 方法 | Accuracy | Precision | Recall | F1分数 | AUC |
|---|---|---|---|---|---|
| LR | 0.920898 | 0.587156 | 0.640000 | 0.612440 | 0.933918 |
| RC | 0.922852 | 0.577778 | 0.780000 | 0.663830 | 0.954177 |
| SGD | 0.922852 | 0.612903 | 0.570000 | 0.590674 | 0.765519 |
| KNN | 0.901367 | 0.486486 | 0.180000 | 0.262774 | 0.736082 |
| ET | 0.903320 | 0.666667 | 0.020000 | 0.038835 | 0.871510 |
| HistGBDT | 0.922852 | 0.83871 | 0.260000 | 0.396947 | 0.908203 |
| GNB | 0.751953 | 0.238095 | 0.70000 | 0.355330 | 0.780103 |
| XGBoost | 0.930664 | 0.808511 | 0.380000 | 0.517007 | 0.926017 |
| LGBM | 0.926758 | 0.820513 | 0.320000 | 0.460432 | 0.923182 |
| CB | 0.929688 | 0.833333 | 0.350000 | 0.492958 | 0.923225 |
| 本文方法 | 0.950195 | 0.775281 | 0.690000 | 0.730159 | 0.975194 |
表3
不同池化模块在SpeechFake表现
| 方法 | Accuracy | F1-score | AUC | MSE |
|---|---|---|---|---|
| Mean Pooling | 0.9248 | 0.6516 | 0.9578 | 0.0517 |
| ASP | 0.9521 | 0.7538 | 0.9651 | 0.0393 |
| Gated-ASP | 0.9443 | 0.7299 | 0.9725 | 0.0423 |
| MGASP4 | 0.9541 | 0.7685 | 0.9767 | 0.0396 |
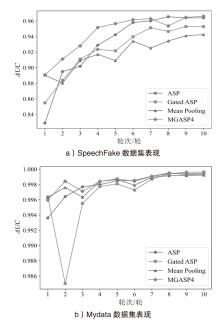
图6
不同数据集上收敛速度与稳定性对比
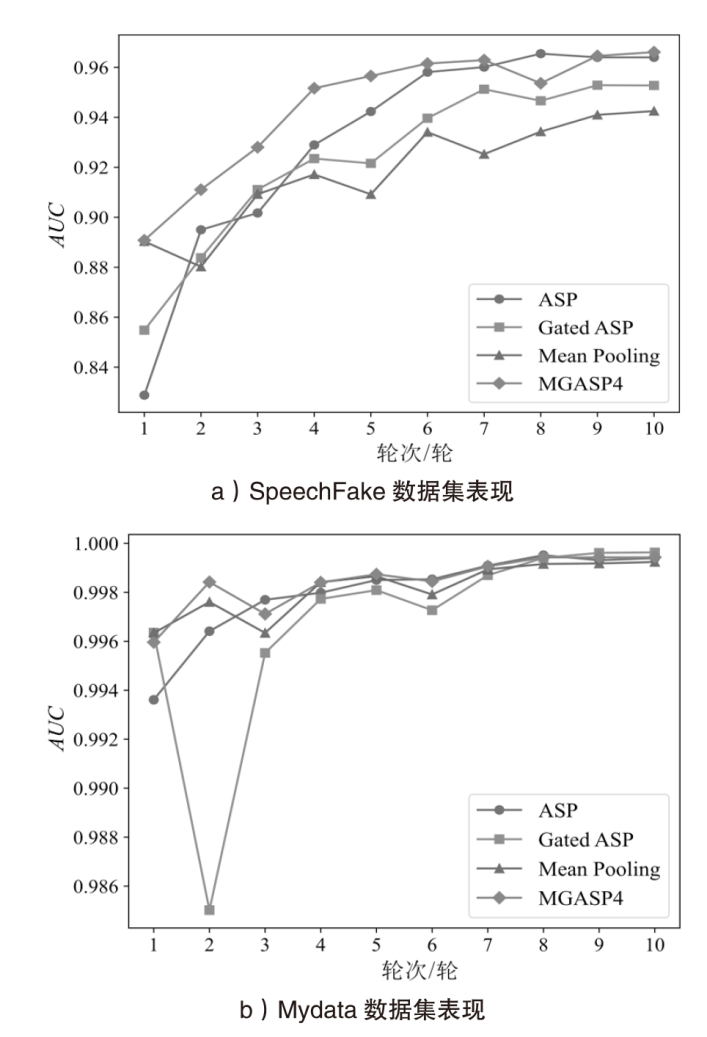
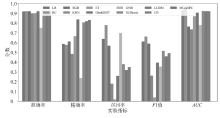
图7
不同方法在不同指标上表现
| [1] |
XU Yuxiong, LI Bin, TAN Shunquan, et al. Research Progress on Speech Deepfake and Its Detection Techniques[J]. Journal of Image and Graphics, 2024, 29(8): 2236-2268.
doi: 10.11834/jig.230476 URL |
| 许裕雄, 李斌, 谭舜泉, 等. 语音深度伪造及其检测技术研究进展[J]. 中国图象图形学报, 2024, 29 (8):2236-2268. | |
| [2] | YANG Yujie, QIN Haochen, ZHOU Hang, et al. A Robust Audio Deepfake Detection System via Multi-View Feature[C]// IEEE. 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). New York: IEEE, 2024: 13131-13135. |
| [3] | XUE Ouyang, WANG Chunhui, ZHAO Bin, et al. Adaptive Reverse Perturbation Network for Audio Deepfake Detection[J]. Neurocomputing, 2025, 658: 1-12. |
| [4] | GUO Yinlin, HUANG Haofan, CHEN Xi, et al. Audio Deepfake Detection with Self-Supervised Wavlm and Multi-Fusion Attentive Classifier[C]// IEEE. 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). New York: IEEE, 2024: 12702-12706. |
| [5] |
YUAN Hongyan, ZHANG Linjuan, NIU Baoning, et al. A Spoofing Speech Detection Method Combining Multi-Scale Features and Cross-Layer Information[J]. Information, 2025, 16 (3): 194.
doi: 10.3390/info16030194 URL |
| [6] | LIU Liwei, WEI Huihui, LIU Dongya, et al. HarmoNet:Partial DeepFake Detection Network Based on Multi-Scale HarmoF0 Feature Fusion[C]// ISCA. Interspeech 2024. NewYork: IEEE, 2024: 2255-2259. |
| [7] | ZHANG Qishan, WEN Shuangbing, HU Tao, et al. Audio Deepfake Detection with Self-Supervised XLS-R and SLS Classifier[C]// ACM. The 32nd ACM International Conference on Multimedia (MM '24). New York: ACM, 2024: 6765-6773. |
| [8] | KUMAR A, BOSE S, HASSAN M, et al. SPDG-Net: Semantics Preserving Domain Augmentation through Style Interpolation for Multi-Source Domain Generalization[C]// IEEE. 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). New York: IEEE, 2024: 7365-7369. |
| [9] |
SALIH A O M, EMAM A H M, AHMED A B G E, et al. Deepfake Audio Detection in Voice Authentication: A Spectral and CNN-Based Comprehensive Review[J]. Engineering, Technology and Applied Science Research, 2025, 15(6): 29824-29832.
doi: 10.48084/etasr.13400 URL |
| [10] | DIXIT A, KAUR N, KINGRA S. Review of Audio Deepfake Detection Techniques: Issues and Prospects[J]. Expert Systems, 2023, 40(8):1-19. |
| [11] | LI Menglu, ZHANG Xiaoping, AHMADIADLI Y, et al. A Survey on Speech Deepfake Detection[J]. ACM Computing Surveys, 2025, 57(7): 1-38. |
| [12] | KINNUNEN T, SAHIDULLAH M, DELGADO H, et al. The ASVspoof 2017 Challenge: Assessing the Limits of Replay Spoofing Attack Detection[C]// ISCA. Interspeech 2017. New York: IEEE, 2017: 2-6. |
| [13] | DELGADO H, EVANS N, KINNUNEN T, et al. ASVspoof 2021:Automatic Speaker Verification Spoofing and Countermeasures Challenge Evaluation Plan[EB/OL]. (2021-09-01)[2025-06-01]. https://doi.org/10.48550/arXiv.2109.00537. |
| [14] |
MASOOD M, NAWAZ M, MALIK K M, et al. Deepfakes Generation and Detection: State-of-the-Art, Open Challenges, Countermeasures and Way Forward[J]. Applied Intelligence, 2023, 53: 3974-4026.
doi: 10.1007/s10489-022-03766-z |
| [15] | LI M, ZORILA C, DODDIPATLA R S. Head-Synchronous Decoding for Transformer-Based Streaming ASR[C]// IEEE. 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). New York: IEEE, 2021: 5909-5913. |
| [16] | GOSWAMI M, MAHATO S, KUNDU S, et al. Potentials and Advantages of NavIC in Indian Missile Programs[C]// IEEE. 2021 2nd International Conference on Range Technology (ICORT). New York: IEEE, 2021: 1-4. |
| [17] | CHEN Feifei, GUO Haiyan, GUO Yanmin, et al. Deepfake Speech Detection Method Based on Wav2Vec2.0 Feature Merging and Joint Loss[J]. Journal of Signal Processing, 2025, 41(9): 1547-1557. |
| 陈飞飞, 郭海燕, 郭延民, 等. 基于 Wav2Vec2.0 特征融合与联合损失的深度伪造语音检测方法[J]. 信号处理, 2025, 41(9):1547-1557. | |
| [18] | CHEN Maximillian, ZHOU Yu. Pre-Finetuning for Few-Shot Emotional Speech Recognition[C]// ISCA. Interspeech 2023. New York: IEEE, 2023: 3602-3606. |
| [19] | LIU Zhe, PENG Fuchun. Modeling Dependent Structure for Utterances in ASR Evaluation[C]// ISCA. Interspeech 2023, New York: IEEE. International Speech Communication Association (ISCA), 2023: 3237-3241. |
| [20] |
TALHA M M, KHAN H U, IQBAL S, et al. Deep Learning in News Recommender Systems: A Comprehensive Survey, Challenges and Future Trends[J]. Neurocomputing, 2023, 562: 126881-126881.
doi: 10.1016/j.neucom.2023.126881 URL |
| [21] | PAL P, DANGI R, NAZIR M S, et al. Scalable GaN-HEMT Model for X-Band RF Applications[C]// IEEE. 2024 8th IEEE Electron Devices Technology & Manufacturing Conference (EDTM). New York: IEEE, 2024: 1-3. |
| [22] | HUANG Wen, GU Yanmei, WANG Zhiming, et al. SpeechFake: A Large-Scale Multilingual Speech Deepfake Dataset Incorporating Cutting-Edge Generation Methods[C]// ACL. The 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1:Long Papers). Stroudsburg, ACL, 2025: 9985-9998. |
| [1] | 李思聪, 王飞, 魏子令, 陈曙晖. 面向恶意代码检测的深度注意力网络架构[J]. 信息网络安全, 2025, 25(8): 1208-1222. |
| [2] | 张兴兰, 陶科锦. 基于高阶特征与重要通道的通用性扰动生成方法[J]. 信息网络安全, 2025, 25(5): 767-777. |
| [3] | 秦广雪, 李丽莎. 基于量子卷积神经网络的ARX分组密码区分器[J]. 信息网络安全, 2025, 25(3): 467-477. |
| [4] | 张双全, 殷中豪, 张环, 高鹏. 基于残差卷积神经网络的网络攻击检测技术研究[J]. 信息网络安全, 2025, 25(2): 240-248. |
| [5] | 薛羽, 张逸轩. 深层神经网络架构搜索综述[J]. 信息网络安全, 2023, 23(9): 58-74. |
| [6] | 苑文昕, 陈兴蜀, 朱毅, 曾雪梅. 基于深度学习的HTTP负载隐蔽信道检测方法[J]. 信息网络安全, 2023, 23(7): 53-63. |
| [7] | 蒋英肇, 陈雷, 闫巧. 基于双通道特征融合的分布式拒绝服务攻击检测算法[J]. 信息网络安全, 2023, 23(7): 86-97. |
| [8] | 李志华, 王志豪. 基于LCNN和LSTM混合结构的物联网设备识别方法[J]. 信息网络安全, 2023, 23(6): 43-54. |
| [9] | 赵小林, 王琪瑶, 赵斌, 薛静锋. 基于机器学习的匿名流量分类方法研究[J]. 信息网络安全, 2023, 23(5): 1-10. |
| [10] | 赵彩丹, 陈璟乾, 吴志强. 基于多通道联合学习的自动调制识别网络[J]. 信息网络安全, 2023, 23(4): 20-29. |
| [11] | 姚远, 樊昭杉, 王青, 陶源. 基于多元时序特征的恶意域名检测方法[J]. 信息网络安全, 2023, 23(11): 1-8. |
| [12] | 秦一方, 张健, 梁晨. 基于神经网络的电子病历数据特征提取技术研究[J]. 信息网络安全, 2023, 23(10): 70-76. |
| [13] | 刘光杰, 段锟, 翟江涛, 秦佳禹. 基于多特征融合的移动流量应用识别[J]. 信息网络安全, 2022, 22(7): 18-26. |
| [14] | 王浩洋, 李伟, 彭思维, 秦元庆. 一种基于集成学习的列车控制系统入侵检测方法[J]. 信息网络安全, 2022, 22(5): 46-53. |
| [15] | 刘峰, 杨成意, 於欣澄, 齐佳音. 面向去中心化双重差分隐私的谱图卷积神经网络[J]. 信息网络安全, 2022, 22(2): 39-46. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||