信息网络安全 ›› 2020, Vol. 20 ›› Issue (8): 71-80.doi: 10.3969/j.issn.1671-1122.2020.08.009
网络入侵检测中K近邻高速匹配算法研究
徐国天( )
)
- 中国刑事警察学院网络犯罪侦查系,沈阳 110854
-
收稿日期:2020-07-20出版日期:2020-08-10发布日期:2020-10-20 -
通讯作者:徐国天 E-mail:459536384@qq.com -
作者简介:徐国天(1978—),男,辽宁,副教授,硕士,主要研究方向为网络安全、电子物证 -
基金资助:辽宁省自然科学基金(2019-ZD-0167);辽宁省自然科学基金(20180550841);辽宁省自然科学基金(2015020091);中央高校基本科研业务费(3242017013);公安部技术研究计划课题(2016JSYJB06)
Research on K-Nearest Neighbor High Speed Matching Algorithm in Network Intrusion Detection
XU Guotian()
- Cyber Crime Investigation Department, Criminal Investigation Police University of China, Shenyang 110854, China
-
Received:2020-07-20Online:2020-08-10Published:2020-10-20 -
Contact:XU Guotian E-mail:459536384@qq.com
摘要:
K近邻匹配算法被广泛应用于网络入侵检测工作,当样本数量和特征维度显著增加时,基于Ball-tree结构的K近邻匹配算法查询效率显著降低,不能满足实时性检测需求。针对这一问题,文章提出一种基于“裁剪树”的K近邻高速匹配算法。首先对全部样本集进行裁剪,构建一棵最小规模的“裁剪树”,同时保证“裁剪树”最大限度地保留原始样本集在多维空间内的分布形态;其次进行K近邻查找时,在“裁剪树”内快速定位K_g(2≤K_g≤K)个初始近邻点,利用初始近邻点与目标点的空间距离作为剪枝半径对搜索二叉树进行K近邻查询。与原始K近邻匹配算法相比,改进算法的初始近邻不在固定位置,而是动态位于目标点周边,有效缩短了剪枝距离,在查询过程中有更多的样本点被剪枝删除,显著减少计算量,提升了查询效率。实验结果表明,改进的K近邻高速匹配算法在处理高维、海量样本数据时,维持较高查询效率,部分样本集增速比达到93.81%。
中图分类号:
引用本文
徐国天. 网络入侵检测中K近邻高速匹配算法研究[J]. 信息网络安全, 2020, 20(8): 71-80.
XU Guotian. Research on K-Nearest Neighbor High Speed Matching Algorithm in Network Intrusion Detection[J]. Netinfo Security, 2020, 20(8): 71-80.
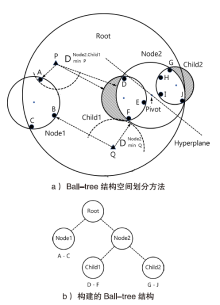
图1
Ball-tree构建过程
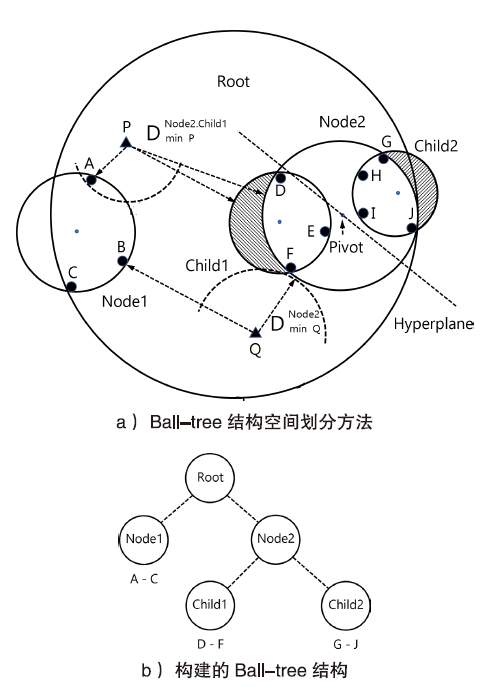

图2
构建“裁剪树”
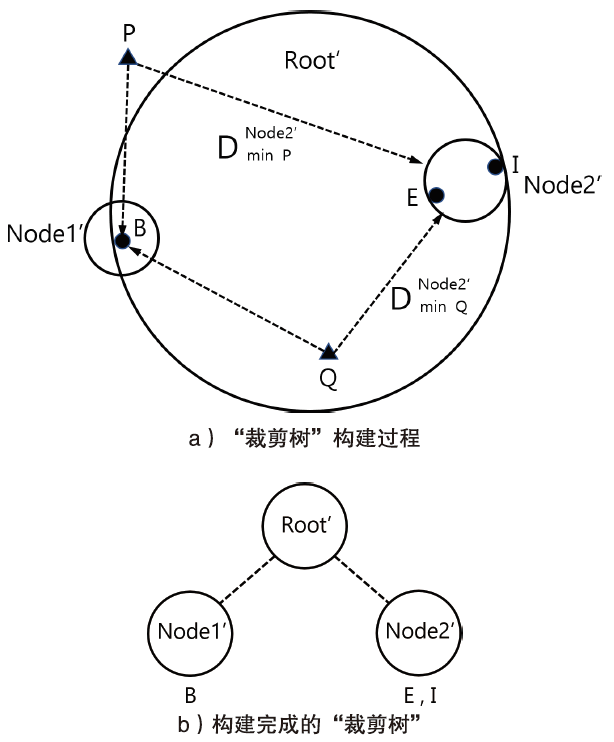

图3
调整裁剪数对剩余样本的影响
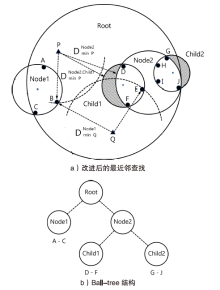
图4
基于“裁剪树”结构查询最近邻

图5
统计最佳和最差参数

图6
最佳和最差参数查询效果比对
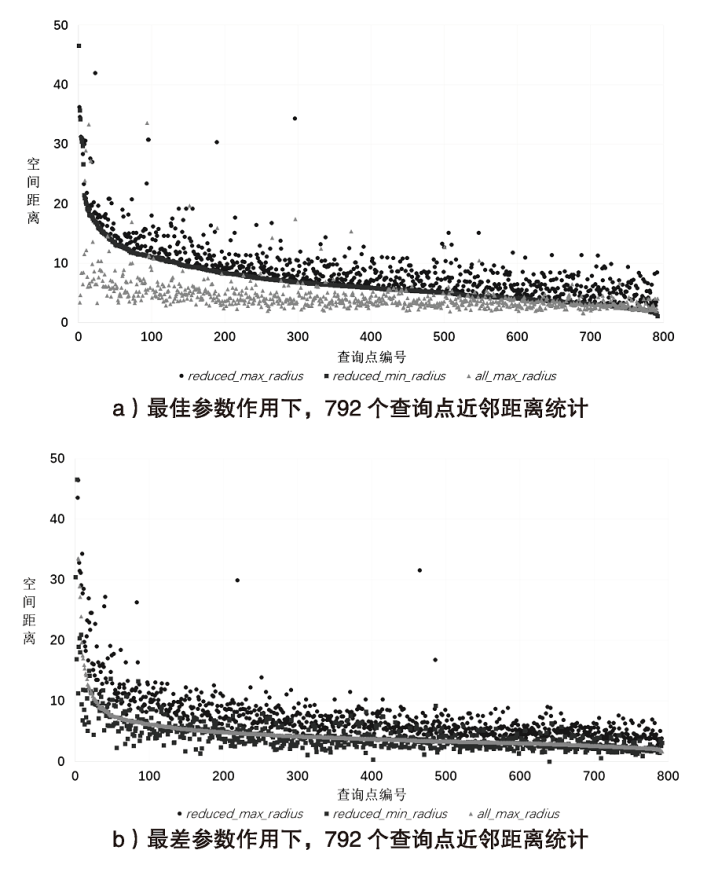
表1
实验测试环境
| 设备型号 | 操作系统 | 运行内存 | 存储容量 | CPU类型 | 编程语言 |
|---|---|---|---|---|---|
| ThinkPad P1 | Windows 10 | 32 GB | 2 TB | i7-9850H | Python |
表2
实验测试结果
| 样本集 | 特征数 | 样本总数 | 原始算法 | 改进算法 |
|---|---|---|---|---|
| Wine_ | 12 | 160 | 0.762 S | 0.022 S |
| Forest | 11 | 496 | 0.723 S | 0.185 S |
| Bcwd_ | 30 | 530 | 0.602 S | 0.173 S |
| Abalon | 08 | 4026 | 15.985 S | 0.903 S |
| Spam | 56 | 4200 | 9.171 S | 0.546 S |
| Harus_ | 526 | 6300 | 253.049 S | 16.519 S |
| Swar_ | 2360 | 8100 | 1126.05 S | 69.046 S |
| Shut_ | 09 | 56000 | 12160.42 S | 753.15 S |
| [1] | HU Mingxia. Instrusion Detection Algorithm Based on BP Neural Network[J]. Computer Engineering, 2012,38(6):148-150. |
| 胡明霞. 基于BP神经网络的入侵检测算法[J]. 计算机工程, 2012,38(6):148-150. | |
| [2] | XIANG Changsheng, ZHANG Linfeng. Application of Support Vector Machine Optimized by Particle Swarm Optimization Algorithm in Network Intrusion Detection[J]. Computer Engineering and Design, 2013,34(4):1222-1225. |
| 向昌盛, 张林峰. PSO-SVM在网络入侵检测中的应用[J]. 计算机工程与设计, 2013,34(4):1222-1225. | |
| [3] | DENG Chenwei, HUANG Guangbin, XU Jia. Extreme Learning Machines: New Trends and Applications[J]. Science China Information Sciences, 2015,58(2):1-16. |
| [4] | LIAO Yihua. Using of K-Nearest Neighbor Classifier for Intrusion Detection[J]. Computers and Security, 2002,5(21):439-448. |
| [5] | LI Yang, FANG Binxing, GUO Li, et al. Supervised Intrusion Detedtion Based on Active Learning and TCM-KNN Algorithm[J]. Chinese Journal of Computers, 2007,30(8):1464-1473. |
| 李洋, 方滨兴, 郭莉, 等. 基于主动学习和TCM-KNN方法的有指导入侵检测技术[J]. 计算机学报, 2007,30(8):1464-1473. | |
| [6] | Reyadh Shaker Naoum, Zainab Namh Al-Sultani. Learning Vector Quantization(LVQ)and K-Nearest Neighbor for Intrusion Classification[J]. World of Computer Science and Information Technology Journal, 2012,3(2):105-109. |
| [7] | JAMSHIDI Y, Nezamabadi-pour H. A Lattice based Nearest Neighbor Classifier for Anomaly Intrusion Detection[J]. Journal of Advances in Computer Research, 2013,4(4):51-60. |
| [8] | MA Zhenghui, KABAN A. K-Nearest-Neighbors with A Novel Similarity Measure for Intrusion Detection[C]// IEEE. 13rd IEEE UK Workshop on Computational Intelligence, September 9-11, 2013, Guildford, United Kingdom. Guildford: IEEE, 2013: 266-271. |
| [9] | HUA Huiyou, CHEN Qimai, LIU Hai. Hybrid Kmeans with KNN for Network Intrusion Detection Algorithm[J]. ComputerScience, 2016,43(3):158-162. |
| 华辉有, 陈启买, 刘海. 一种融合Kmeans和 KNN的网络入侵检测算法[J]. 计算机科学, 2016,43(3):158-162. | |
| [10] | LI Ronglu, HU Yunfa. Density-based Training Sample Clipping Method for KNN Text Classifier[J]. Computer Research and Development, 2004,41(4):539-546. |
| 李荣陆, 胡运发. 基于密度的KNN文本分类器训练样本裁剪方法[J]. 计算机研究与发展, 2004,41(4):539-546. | |
| [11] | TING Liu, ANDREW W, ALEXANDER Gra. New Algorithms for Efficient High-Dimensional Nonparametric Classification[J]. Journal of Machine Learning Research, 2006,40(3):1135-1158. |
| [12] | MOHAMAD Dolatshah, AliHadian, Behrouz. Ball*-tree: Efficient Spatial Indexing for Constrained Nearest-neighbor Search in Metric Spaces[J]. ArXiv, 2015,38(16):40-44. |
| [13] | HAO Weijie, WANG Yanfei, HU Jingwei, et al. An Improved KNN Algorithm based on Hyper-sphere Region Partition[J]. Journal of Qingdao University, 2017,30(1):85-90. |
| 郝卫杰, 王艳飞, 胡敬伟, 等. 基于超球区域划分的改进KNN算法[J]. 青岛大学学报, 2017,30(1):85-90. | |
| [14] | LIU Duanyang, ZHENG Jiangfan, LIU Zhi. Research of Parallel KNN Algorithm based on CUDA[J]. MinicomputerSystem, 2019,40(6):1197-1202. |
| [15] | TING Liu, Moore, ANDREW W. New Algorithms for Efficient High-dimensional Nonparametric Classification[J]. Journal of Machine Learning Research, 2006,44(10):1135-1158. |
| [16] | YANG Shuaihua, ZHANG Qinghua. Research on K-nearest Neighbor Text Classification Algorithm of Approximation Set of Rough Set[J]. Minicomputer System, 2017,38(10):2192-2196. |
| 杨帅华, 张清华. 粗糙集近似集的 KNN 文本分类算法研究[J]. 小型微型计算机系统, 2017,38(10):2192-2196. | |
| [17] | LU Dunli, NING Qian, ZANG Jun. Improved KNN Algorithm based on BP Neural Network Decision Making[J]. Computer Application, 2017,37(2):65-68. |
| 路敦利, 宁芊, 臧军. 基于BP神经网络决策的 KNN 改进算法[J]. 计算机应用, 2017,37(2):65-68. | |
| [18] | WANG Zhihua, LIU Shaoting, LUO Qi. KNN Classification Algorithm based on Improved K-modes Clustering[J]. Computer Engineering and Design, 2019,40(8):2228-2234. |
| 王志华, 刘绍廷, 罗齐. 基于改进K-modes聚类的KNN分类算法[J]. 计算机工程与设计, 2019,40(8):2228-2234. | |
| [19] | HUANG Chao, CHEN Junhua. Chinese Text Classification based on Improved K Nearest Neighbor Algorithm[J]. Journal of Shanghai Normal University, 2019,48(1):96-101. |
| 黄超, 陈军华. 基于改进K最近邻算法的中文文本分类[J]. 上海师范大学学报, 2019,48(1):96-101. | |
| [20] | ZHOU Qingping, TAN Changgeng, WANG Hongjun, et al. Improved KNN Text Classification Algorithm based on Clustering[J]. Computer Application Research, 2016,33(11):3374-3382. |
| 周庆平, 谭长庚, 王宏君, 等. 基于聚类改进的KNN文本分类算法[J]. 计算机应用研究, 2016,33(11):3374-3382. | |
| [21] | SUN Xin, OUYANG Tong, YAN Ximin, et al. The Weighted KNN Text Categorization Algorithm based on Training Set Cutting[J]. Information Engineering, 2016,2(6):8-16. |
| 孙新, 欧阳童, 严西敏, 等. 基于训练集裁剪的加权K近邻文本分类算法[J]. 情报工程, 2016,2(6):8-16. |
| [1] | 李桥, 龙春, 魏金侠, 赵静. 一种基于LMDR和CNN的混合入侵检测模型[J]. 信息网络安全, 2020, 20(9): 117-121. |
| [2] | 姜楠, 崔耀辉, 王健, 吴晋超. 基于上下文特征的IDS告警日志攻击场景重建方法[J]. 信息网络安全, 2020, 20(7): 1-10. |
| [3] | 张晓宇, 王华忠. 基于改进Border-SMOTE的不平衡数据工业控制系统入侵检测[J]. 信息网络安全, 2020, 20(7): 70-76. |
| [4] | 彭中联, 万巍, 荆涛, 魏金侠. 基于改进CGANs的入侵检测方法研究[J]. 信息网络安全, 2020, 20(5): 47-56. |
| [5] | 王蓉, 马春光, 武朋. 基于联邦学习和卷积神经网络的入侵检测方法[J]. 信息网络安全, 2020, 20(4): 47-54. |
| [6] | 罗文华, 许彩滇. 基于改进MajorClust聚类的网络入侵行为检测[J]. 信息网络安全, 2020, 20(2): 14-21. |
| [7] | 康健, 王杰, 李正旭, 张光妲. 物联网中一种基于多种特征提取策略的入侵检测模型[J]. 信息网络安全, 2019, 19(9): 21-25. |
| [8] | 冯文英, 郭晓博, 何原野, 薛聪. 基于前馈神经网络的入侵检测模型[J]. 信息网络安全, 2019, 19(9): 101-105. |
| [9] | 饶绪黎, 徐彭娜, 陈志德, 许力. 基于不完全信息的深度学习网络入侵检测[J]. 信息网络安全, 2019, 19(6): 53-60. |
| [10] | 刘敬浩, 毛思平, 付晓梅. 基于ICA算法与深度神经网络的入侵检测模型[J]. 信息网络安全, 2019, 19(3): 1-10. |
| [11] | 陈虹, 肖越, 肖成龙, 陈建虎. 融合最大相异系数密度的SMOTE算法的入侵检测方法[J]. 信息网络安全, 2019, 19(3): 61-71. |
| [12] | 田峥, 李树, 孙毅臻, 黎曦. 一种面向S7协议的工控系统入侵检测模型[J]. 信息网络安全, 2019, 19(11): 8-13. |
| [13] | 张阳, 姚原岗. 基于Xgboost算法的网络入侵检测研究[J]. 信息网络安全, 2018, 18(9): 102-105. |
| [14] | 张戈琳, 李勇. 非负矩阵分解算法优化及其在入侵检测中的应用[J]. 信息网络安全, 2018, 18(8): 73-78. |
| [15] | 魏书宁, 陈幸如, 焦永, 王进. AR-OSELM算法在网络入侵检测中的应用研究[J]. 信息网络安全, 2018, 18(6): 1-6. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||