信息网络安全 ›› 2016, Vol. 16 ›› Issue (3): 34-39.doi: 10.3969/j.issn.1671-1122.2016.03.006
浏览器识别研究
李周辉( ), 黄燕群, 唐屹
), 黄燕群, 唐屹
- 广州大学数学与信息科学学院,广东广州 510006
Research on Browsers Recognition
Zhouhui LI(), Yanqun HUANG, Yi TANG
- School of Mathematics and Information Sciences, Guangzhou University, Guangzhou Guangdong 510006, China
摘要:
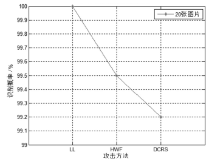
近年来,随着互联网的高速发展,网络软件一直成为黑客攻击的主要目标.浏览器作为用户使用最频繁的网络软件,其安全和服务一直是广泛关注的焦点,也是用户选择使用的衡量标准.识别浏览器一方面能够根据浏览器对应的漏洞实现系统攻击,打开攻击的门户;另一方面能够利用浏览器识别技术进一步识别用户,带来更好的用户体验.先前的研究有通过植入服务器端脚本获取浏览器指纹信息,也有仅仅通过流量分析识别浏览器,但识别率比较低.文章通过截取加密传输的流量数据,获取13个浏览器的踪迹信息,用3种典型的机器学习方法处理浏览器踪迹信息,以此来识别浏览器.实验结果表明,浏览器可以被识别,而且识别的准确率最高为100%.这就意味着用户必须提高安全防范意识,及时更新浏览器版本和安装最新的补丁,以防止黑客利用原来浏览器的漏洞造成系统损害.
中图分类号: