信息网络安全 ›› 2024, Vol. 24 ›› Issue (11): 1763-1772.doi: 10.3969/j.issn.1671-1122.2024.11.015
融合实例和标记相关性增强消歧的偏多标记学习算法
高光亮( ), 梁广俊, 洪磊, 高谷刚, 王群
), 梁广俊, 洪磊, 高谷刚, 王群
- 江苏警官学院计算机信息与网络安全系,南京 210031
-
收稿日期:2024-08-06出版日期:2024-11-10发布日期:2024-11-21 -
通讯作者:高光亮guangliang.gao@njust.edu.cn -
作者简介:高光亮(1989—),男,山东,讲师,博士,CCF会员,主要研究方向为社会网络安全、复杂网络分析|梁广俊(1982—),男,安徽,副教授,博士,CCF会员,主要研究方向为网络空间安全、数据建模|洪磊(1988—),男,江苏,副教授,博士,主要研究方向为数据挖掘|高谷刚(1975—),男,江苏,高级实验师,博士,主要研究方向为智慧警务、人工智能|王群(1971—),男,甘肃,教授,博士,CCF杰出会员,主要研究方向为网络空间安全 -
基金资助:国家自然科学基金(72401110);江苏省高等学校自然科学研究面上项目(23KJB520009)
Disambiguation-Based Partial Multi-Label Learning Algorithm Augmented by Fusing Instance and Label Correlations
GAO Guangliang(), LIANG Guangjun, HONG Lei, GAO Gugang, WANG Qun
- Department of Computer Information and Cyber Security, Jiangsu Police Institute, Nanjing 210031, China
-
Received:2024-08-06Online:2024-11-10Published:2024-11-21
摘要:
实例的候选标记集合包含真实标记和噪声标记。基于消歧的偏多标记学习旨在消除噪声标记,识别并预测与实例真正相关的标记。传统的消歧策略通常仅考虑标记间的相关性,忽略了实例间的相关性。为此,文章提出一种融合实例和标记相关性增强消歧的偏多标记学习算法,进而提升基于消歧的偏多标记学习性能。首先,依据真实标记矩阵的低秩性和噪声标记的稀疏性构建基础模型;然后,定义核函数以捕捉实例间的线性和非线性相关性,从而进一步消除噪声标记;最后,通过从特征空间到标记空间的线性映射,实现相关标记的预测。在合成和真实偏多标记数据集上的实验结果表明,与8种对比算法相比,文章所提算法在统计学上具有显著差异并且表现更好。
中图分类号:
引用本文
高光亮, 梁广俊, 洪磊, 高谷刚, 王群. 融合实例和标记相关性增强消歧的偏多标记学习算法[J]. 信息网络安全, 2024, 24(11): 1763-1772.
GAO Guangliang, LIANG Guangjun, HONG Lei, GAO Gugang, WANG Qun. Disambiguation-Based Partial Multi-Label Learning Algorithm Augmented by Fusing Instance and Label Correlations[J]. Netinfo Security, 2024, 24(11): 1763-1772.

图1
偏多标记学习示例

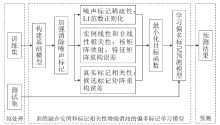
图2
模型框架
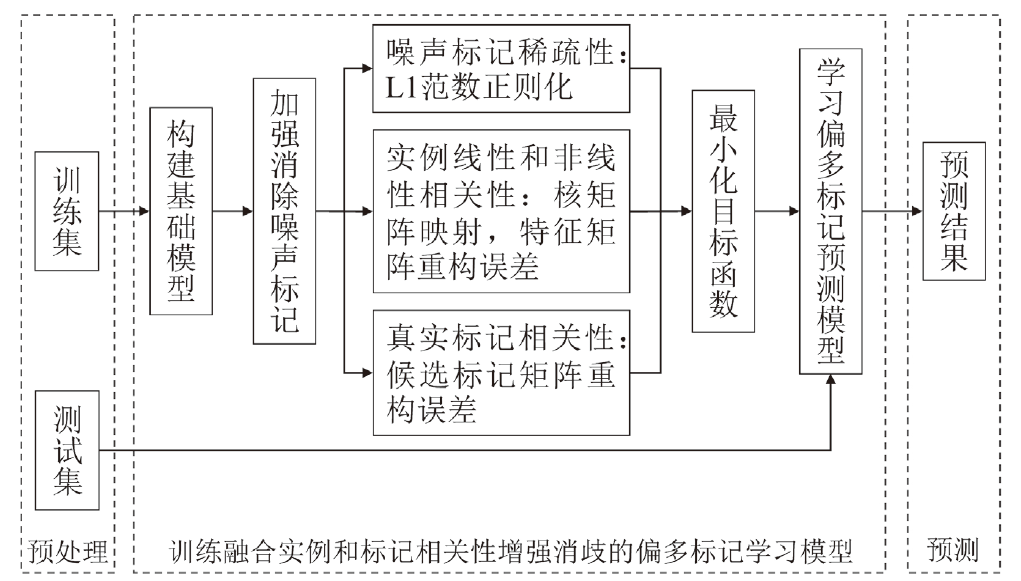
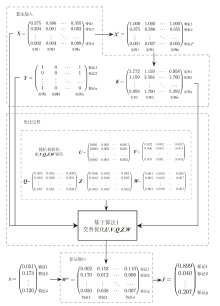
图3
优化过程的算法流程

表1
实验数据集的统计信息
| 实验数据集 | 实例 数量/个 | 特征 数量/个 | 标记种类数量/个 | 平均候选标记数量/个 | 平均相关标记数量/个 |
|---|---|---|---|---|---|
| YeastBP (YeaBP) | 560 | 5548 | 217 | 30 | 21 |
| Music_Emotion (MicEM) | 6833 | 98 | 11 | 5 | 2 |
| Mirflickr (MirFR) | 10433 | 100 | 7 | 3 | 1 |
| Cal500 (Cal) | 502 | 68 | 174 | 39 | 26 |
| 52 | |||||
| 65 | |||||
| Emotions (Em) | 593 | 72 | 6 | 2 | 1 |
| 3 | |||||
| 4 | |||||
| Genbase (Gen) | 662 | 1186 | 27 | 1 | 1 |
| 2 | |||||
| 3 | |||||
| Scene (Sce) | 2407 | 294 | 6 | 1 | 1 |
| 2 | |||||
| 2 | |||||
| Bibtex (Bib) | 7395 | 1836 | 159 | 3 | 2 |
| 4 | |||||
| 6 | |||||
| Eurlex_Sm (Esm) | 12679 | 100 | 15 | 2 | 1 |
| 3 | |||||
| 3 |
表2
Ranking Loss指标下的整体性能比较
| 数据集 | PARVLS | PARMAP | PMLLC | PMLFP | fPML | ||
|---|---|---|---|---|---|---|---|
| YeaBP | 0.937±0.004 | 0.348±0.002 | 0.399±0.004 | 0.366±0.004 | 0.424±0.007 | ||
| MicEM | 0.361±0.008 | 0.353±0.010 | 0.441±0.009 | 0.399±0.008 | 0.603±0.006 | ||
| MirFR | 0.150±0.004 | 0.141±0.005 | 0.153±0.007 | 0.161±0.009 | 0.160±0.004 | ||
| Cal50% | 0.180±0.006 | 0.170±0.008 | 0.183±0.003 | 0.195±0.007 | 0.199±0.002 | ||
| Cal100% | 0.185±0.006 | 0.178±0.006 | 0.190±0.005 | 0.202±0.007 | 0.215±0.003 | ||
| Cal150% | 0.252±0.007 | 0.242±0.008 | 0.243±0.004 | 0.231±0.003 | 0.247±0.005 | ||
| Em50% | 0.115±0.002 | 0.142±0.006 | 0.146±0.005 | 0.166±0.007 | 0.203±0.007 | ||
| Em100% | 0.233±0.002 | 0.262±0.003 | 0.278±0.007 | 0.300±0.004 | 0.335±0.007 | ||
| Em150% | 0.266±0.007 | 0.282±0.006 | 0.423±0.009 | 0.436±0.008 | 0.411±0.005 | ||
| Gen50% | 0.025±0.005 | 0.014±0.006 | 0.009±0 | 0.010±0 | 0.010±0.007 | ||
| Gen100% | 0.024±0.003 | 0.018±0.004 | 0.009±0 | 0.008±0 | 0.010±0.003 | ||
| Gen150% | 0.023±0.007 | 0.017±0.004 | 0.008±0 | 0.009±0 | 0.009±0.007 | ||
| Sce50% | 0.170±0.005 | 0.147±0.005 | 0.182±0.003 | 0.161±0.010 | 0.190±0.002 | ||
| Sce100% | 0.172±0.006 | 0.173±0.005 | 0.210±0.002 | 0.228±0.007 | 0.259±0.003 | ||
| Sce150% | 0.212±0.006 | 0.209±0.003 | 0.244±0.002 | 0.232±0.008 | 0.305±0.004 | ||
| Bib50% | 0.325±0.005 | 0.320±0.004 | 0.124±0.001 | 0.108±0.002 | 0.105±0.009 | ||
| Bib100% | 0.320±0.004 | 0.326±0.004 | 0.126±0.002 | 0.108±0.004 | 0.106±0.009 | ||
| Bib150% | 0.354±0.004 | 0.337±0.004 | 0.138±0.003 | 0.112±0.003 | 0.108±0.010 | ||
| Esm50% | 0.114±0.007 | 0.116±0.008 | 0.408±0.002 | 0.186±0.008 | 0.317±0.003 | ||
| Esm100% | 0.109±0.006 | 0.107±0.007 | 0.365±0.005 | 0.239±0.008 | 0.368±0.005 | ||
| Esm150% | 0.182±0.008 | 0.180±0.006 | 0.399±0.002 | 0.325±0.007 | 0.365±0.002 | ||
| 数据集 | PMLLRS | MLKNN | LIFT | 本文算法 | |||
| YeaBP | 0.412±0.008 | 0.415±0.006 | 0.320±0.009 | 0.339±0.005 | |||
| MicEM | 0.458±0.002 | 0.370±0.007 | 0.782±0.004 | 0.315±0.005 | |||
| MirFR | 0.290±0.006 | 0.218±0.005 | 0.142±0.006 | 0.132±0.007 | |||
| Cal50% | 0.192±0.005 | 0.195±0.006 | 0.214±0.009 | 0.190±0.006 | |||
| Cal100% | 0.217±0.006 | 0.207±0.006 | 0.220±0.005 | 0.203±0.008 | |||
| Cal150% | 0.258±0.003 | 0.215±0.005 | 0.246±0.008 | 0.212±0.008 | |||
| Em50% | 0.204±0.004 | 0.121±0.003 | 0.146±0.004 | 0.145±0.002 | |||
| Em100% | 0.359±0.003 | 0.343±0.004 | 0.331±0.006 | 0.228±0.004 | |||
| Em150% | 0.405±0.007 | 0.390±0.002 | 0.401±0.003 | 0.264±0.003 | |||
| Gen50% | 0.009±0.004 | 0.008±0.004 | 0.009±0.004 | 0.010±0.003 | |||
| Gen100% | 0.009±0.003 | 0.013±0.004 | 0.010±0.005 | 0.010±0.002 | |||
| Gen150% | 0.010±0.008 | 0.013±0.007 | 0.011±0.007 | 0.008±0.005 | |||
| Sce50% | 0.127±0.005 | 0.134±0.002 | 0.101±0.003 | 0.132±0.005 | |||
| Sce100% | 0.169±0.006 | 0.198±0.003 | 0.144±0.004 | 0.170±0.005 | |||
| Sce150% | 0.225±0.008 | 0.271±0.002 | 0.230±0.003 | 0.205±0.006 | |||
| Bib50% | 0.312±0.003 | 0.225±0.008 | 0.110±0.008 | 0.119±0.007 | |||
| Bib100% | 0.317±0.005 | 0.230±0.009 | 0.120±0.008 | 0.124±0.010 | |||
| Bib150% | 0.321±0.003 | 0.237±0.007 | 0.124±0.008 | 0.130±0.009 | |||
| Esm50% | 0.151±0.008 | 0.180±0.007 | 0.259±0.003 | 0.145±0.003 | |||
| Esm100% | 0.225±0.010 | 0.297±0.006 | 0.291±0.003 | 0.142±0.005 | |||
| Esm150% | 0.236±0.009 | 0.302±0.006 | 0.374±0.002 | 0.173±0.004 | |||
表3
One Error指标下的整体性能比较
| 数据集 | PARVLS | PARMAP | PMLLC | PMLFP | fPML | |
|---|---|---|---|---|---|---|
| YeaBP | 0.910±0.008 | 0.918±0.007 | 0.932±0.008 | 0.927±0.006 | 0.984±0.005 | |
| MicEM | 0.600±0.005 | 0.595±0.007 | 0.634±0.006 | 0.608±0.008 | 0.582±0.005 | |
| MirFR | 0.262±0.006 | 0.249±0.006 | 0.255±0.007 | 0.276±0.009 | 0.352±0.009 | |
| Cal50% | 0.115±0.008 | 0.109±0.008 | 0.130±0.002 | 0.147±0.005 | 0.155±0.005 | |
| Cal100% | 0.119±0.008 | 0.111±0.004 | 0.135±0.002 | 0.151±0.004 | 0.159±0.003 | |
| Cal150% | 0.125±0.006 | 0.124±0.004 | 0.140±0.005 | 0.158±0.004 | 0.170±0.003 | |
| Em50% | 0.351±0.004 | 0.366±0.006 | 0.469±0.008 | 0.485±0.007 | 0.437±0.005 | |
| Em100% | 0.406±0.008 | 0.423±0.008 | 0.485±0.009 | 0.494±0.008 | 0.472±0.004 | |
| Em150% | 0.434±0.009 | 0.452±0.008 | 0.536±0.006 | 0.552±0.009 | 0.511±0.007 | |
| Gen50% | 0.005±0.007 | 0.011±0.006 | 0.004±0.001 | 0.005±0.001 | 0.002±0.005 | |
| Gen100% | 0.007±0.008 | 0.013±0.006 | 0.004±0.001 | 0.004±0 | 0.002±0.006 | |
| Gen150% | 0.008±0.005 | 0.018±0.004 | 0.018±0 | 0.019±0.001 | 0.003±0.008 | |
| Sce50% | 0.310±0.003 | 0.289±0.004 | 0.438±0.002 | 0.411±0.001 | 0.471±0.004 | |
| Sce100% | 0.337±0.003 | 0.329±0.003 | 0.486±0.002 | 0.509±0.003 | 0.495±0.004 | |
| Sce150% | 0.390±0.004 | 0.374±0.05 | 0.570±0.003 | 0.562±0.002 | 0.566±0.005 | |
| Bib50% | 0.588±0.005 | 0.743±0.006 | 0.384±0.006 | 0.377±0.008 | 0.453±0.004 | |
| Bib100% | 0.588±0.004 | 0.749±0.005 | 0.395±0.007 | 0.389±0.009 | 0.458±0.003 | |
| Bib150% | 0.588±0.008 | 0.751±0.005 | 0.402±0.008 | 0.396±0.006 | 0.460±0.004 | |
| Esm50% | 0.236±0.007 | 0.269±0.007 | 0.597±0.008 | 0.345±0.006 | 0.716±0.005 | |
| Esm100% | 0.341±0.009 | 0.401±0.009 | 0.845±0.010 | 0.462±0.006 | 0.820±0.004 | |
| Esm150% | 0.390±0.006 | 0.410±0.005 | 0.895±0.007 | 0.513±0.006 | 0.856±0.003 | |
| 数据集 | PMLLRS | MLKNN | LIFT | 本文算法 | ||
| YeaBP | 0.975±0.004 | 0.956±0.008 | 0.908±0.005 | 0.913±0.009 | ||
| MicEM | 0.517±0.010 | 0.595±0.006 | 0.609±0.004 | 0.522±0.004 | ||
| MirFR | 0.475±0.003 | 0.483±0.005 | 0.366±0.002 | 0.242±0.007 | ||
| Cal50% | 0.152±0 | 0.124±0.009 | 0.160±0.003 | 0.106±0.004 | ||
| Cal100% | 0.157±0 | 0.122±0.007 | 0.168±0.002 | 0.108±0.003 | ||
| Cal150% | 0.184±0.001 | 0.124±0.006 | 0.175±0.003 | 0.119±0.005 | ||
| Em50% | 0.452±0.004 | 0.405±0.008 | 0.402±0.007 | 0.346±0.006 | ||
| Em100% | 0.498±0.003 | 0.489±0.007 | 0.481±0.008 | 0.392±0.005 | ||
| Em150% | 0.500±0.002 | 0.503±0.008 | 0.580±0.007 | 0.428±0.006 | ||
| Gen50% | 0.010±0.005 | 0.011±0.004 | 0.002±0.004 | 0.005±0.002 | ||
| Gen100% | 0.012±0.005 | 0.015±0 | 0.003±0.003 | 0.005±0.001 | ||
| Gen150% | 0.018±0.007 | 0.016±0.001 | 0.005±0.005 | 0.008±0.003 | ||
| Sce50% | 0.284±0.002 | 0.325±0.007 | 0.267±0.009 | 0.278±0.005 | ||
| Sce100% | 0.312±0.004 | 0.421±0.006 | 0.290±0.008 | 0.286±0.008 | ||
| Sce150% | 0.506±0.003 | 0.527±0.007 | 0.416±0.009 | 0.365±0.009 | ||
| Bib50% | 0.567±0.008 | 0.624±0.004 | 0.401±0.003 | 0.392±0.001 | ||
| Bib100% | 0.573±0 | 0.634±0.003 | 0.418±0.003 | 0.406±0.003 | ||
| Bib150% | 0.579±0.002 | 0.640±0.003 | 0.434±0.002 | 0.425±0.002 | ||
| Esm50% | 0.375±0.004 | 0.274±0.005 | 0.616±0.007 | 0.271±0.005 | ||
| Esm100% | 0.469±0.003 | 0.573±0.006 | 0.824±0.008 | 0.329±0.008 | ||
| Esm150% | 0.487±0.005 | 0.616±0.006 | 0.849±0.005 | 0.384±0.006 | ||
表4
Average Precision指标下的整体性能比较
| 数据集 | PARVLS | PARMAP | PMLLC | PMLFP | fPML | |
|---|---|---|---|---|---|---|
| YeaBP | 0.082±0.005 | 0.151±0.006 | 0.137±0.002 | 0.140±0.002 | 0.090±0.002 | |
| MicEM | 0.503±0.008 | 0.530±0.005 | 0.440±0.008 | 0.464±0.006 | 0.499±0.007 | |
| MirFR | 0.777±0.009 | 0.782±0.007 | 0.742±0.009 | 0.729±0.008 | 0.765±0.003 | |
| Cal50% | 0.506±0.004 | 0.511±0.002 | 0.496±0.004 | 0.485±0.006 | 0.490±0.001 | |
| Cal100% | 0.500±0.003 | 0.508±0.003 | 0.493±0.003 | 0.482±0.005 | 0.480±0.003 | |
| Cal150% | 0.435±0.002 | 0.438±0.001 | 0.455±0.003 | 0.443±0.003 | 0.441±0.002 | |
| Em50% | 0.765±0.001 | 0.753±0.002 | 0.684±0.004 | 0.667±0.002 | 0.647±0.004 | |
| Em100% | 0.710±0.003 | 0.664±0.003 | 0.616±0.003 | 0.610±0.003 | 0.627±0.003 | |
| Em150% | 0.615±0.003 | 0.600±0.003 | 0.570±0.002 | 0.559±0.002 | 0.562±0.004 | |
| Gen50% | 0.959±0.002 | 0.980±0.002 | 0.986±0 | 0.985±0 | 0.981±0.004 | |
| Gen100% | 0.958±0.003 | 0.966±0.001 | 0.987±0.005 | 0.988±0.004 | 0.980±0.003 | |
| Gen150% | 0.957±0.004 | 0.960±0.002 | 0.983±0 | 0.982±0 | 0.981±0.004 | |
| Sce50% | 0.779±0.005 | 0.788±0.002 | 0.710±0.002 | 0.732±0.002 | 0.708±0.002 | |
| Sce100% | 0.770±0.004 | 0.782±0.002 | 0.687±0.002 | 0.660±0.002 | 0.655±0.004 | |
| Sce150% | 0.748±0.003 | 0.757±0.001 | 0.629±0.002 | 0.652±0.002 | 0.602±0.005 | |
| Bib50% | 0.482±0.009 | 0.477±0.006 | 0.541±0.008 | 0.546±0.007 | 0.487±0.006 | |
| Bib100% | 0.480±0.010 | 0.474±0.008 | 0.535±0.006 | 0.543±0.008 | 0.486±0.005 | |
| Bib150% | 0.479±0.008 | 0.473±0.006 | 0.526±0.006 | 0.530±0.007 | 0.486±0.007 | |
| Esm50% | 0.525±0.009 | 0.516±0.003 | 0.464±0.005 | 0.710±0.008 | 0.446±0.005 | |
| Esm100% | 0.517±0.008 | 0.508±0.002 | 0.402±0.007 | 0.612±0.009 | 0.335±0.003 | |
| Esm150% | 0.482±0.007 | 0.479±0.001 | 0.346±0.004 | 0.560±0.006 | 0.311±0.004 | |
| 数据集 | PMLLRS | MLKNN | LIFT | 本文算法 | ||
| YeaBP | 0.083±0.008 | 0.108±0.009 | 0.182±0.005 | 0.164±0.007 | ||
| MicEM | 0.470±0.007 | 0.497±0.008 | 0.335±0.003 | 0.562±0.005 | ||
| MirFR | 0.658±0.008 | 0.659±0.005 | 0.760±0.003 | 0.794±0.005 | ||
| Cal50% | 0.485±0.006 | 0.481±0.002 | 0.483±0.005 | 0.490±0.005 | ||
| Cal100% | 0.472±0.008 | 0.476±0.005 | 0.482±0.006 | 0.483±0.003 | ||
| Cal150% | 0.439±0.007 | 0.474±0.006 | 0.463±0.004 | 0.478±0.005 | ||
| Em50% | 0.654±0.007 | 0.641±0.004 | 0.658±0.004 | 0.725±0.008 | ||
| Em100% | 0.600±0.009 | 0.609±0.004 | 0.651±0.005 | 0.664±0.006 | ||
| Em150% | 0.574±0.008 | 0.553±0.003 | 0.568±0.006 | 0.619±0.009 | ||
| Gen50% | 0.984±0.002 | 0.983±0.003 | 0.982±0.001 | 0.984±0.005 | ||
| Gen100% | 0.981±0.005 | 0.978±0.005 | 0.980±0.002 | 0.980±0.004 | ||
| Gen150% | 0.978±0.094 | 0.974±0.006 | 0.981±0.001 | 0.978±0.006 | ||
| Sce50% | 0.818±0.006 | 0.795±0.004 | 0.839±0.005 | 0.797±0.002 | ||
| Sce100% | 0.736±0.005 | 0.727±0.003 | 0.719±0.006 | 0.775±0.003 | ||
| Sce150% | 0.664±0.004 | 0.639±0.003 | 0.717±0.007 | 0.760±0.005 | ||
| Bib50% | 0.491±0.007 | 0.321±0.004 | 0.528±0.007 | 0.535±0.002 | ||
| Bib100% | 0.487±0.006 | 0.318±0.004 | 0.488±0.006 | 0.529±0.002 | ||
| Bib150% | 0.485±0.008 | 0.312±0.007 | 0.486±0.006 | 0.521±0.001 | ||
| Esm50% | 0.692±0.002 | 0.533±0.002 | 0.499±0.007 | 0.705±0.006 | ||
| Esm100% | 0.600±0.001 | 0.510±0.005 | 0.336±0.007 | 0.640±0.008 | ||
| Esm150% | 0.485±0.001 | 0.487±0.002 | 0.300±0.006 | 0.602±0.005 | ||
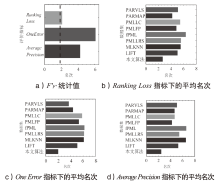
图4
整体性能的Friedman Test检验和平均名次比较

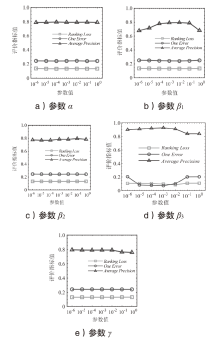
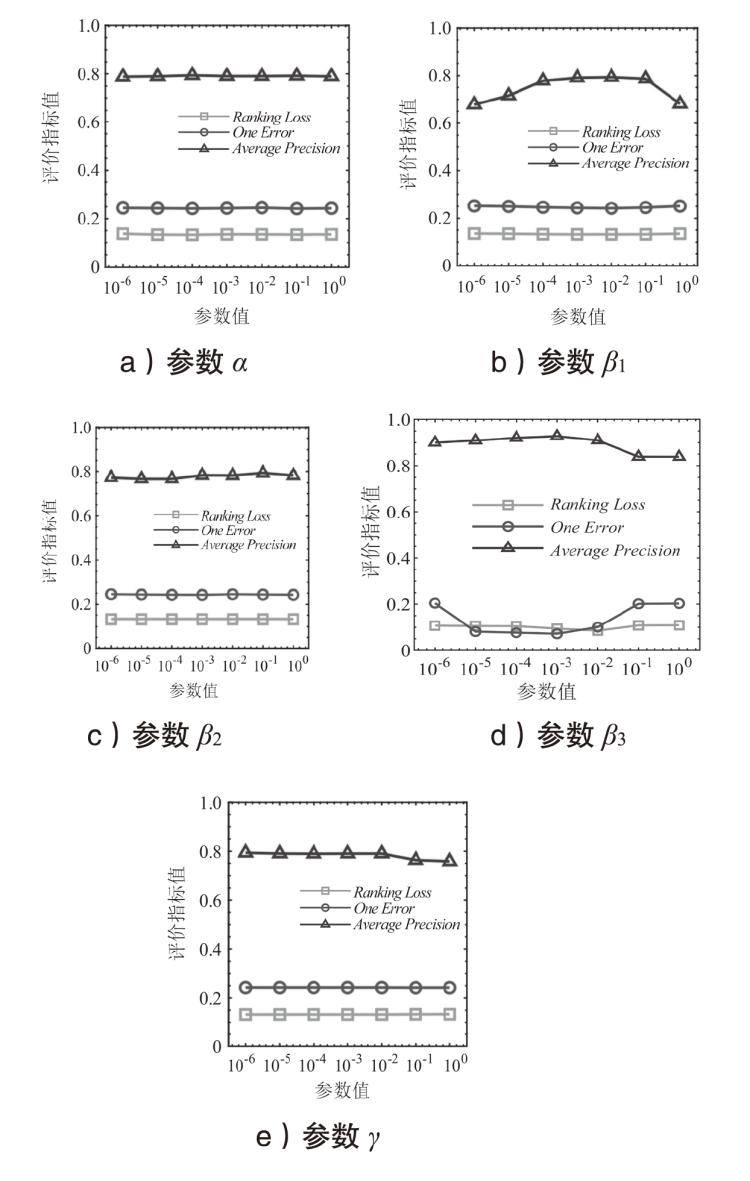
图5
权衡参数对整体性能影响分析
| [1] | ZHANG Minling, ZHOU Zhihua. A Review on Multi-Label Learning Algorithms[J]. IEEE Transactions on Knowledge and Data Engineering, 2014, 26(8): 1819-1837. |
| [2] | LI Dongmei, YANG Yu, MENG Xianghao, et al. Review on Multi-Lable Classification[J]. Journal of Frontiers of Computer Science and Technology, 2023, 17(11): 2529-2542. |
|
李冬梅, 杨宇, 孟湘皓, 等. 多标签分类综述[J]. 计算机科学与探索, 2023, 17(11): 2529-2542.
doi: 10.3778/j.issn.1673-9418.2303082 |
|
| [3] | XIE Mingkun, HUANG Shengjun. Partial Multi-Label Learning[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2018, 32(1): 4302-4309. |
| [4] | ZHANG Minling, ZHOU Zhihua. ML-KNN: A Lazy Learning Approach to Multi-Label Learning[J]. Pattern Recognition, 2007, 40(7): 2038-2048. |
| [5] | LI Feng, MIAO Duoqian, ZHANG Zhifei, et al. Mutual Information Based Granular Feature Weighted K-Nearest Neighbors Algorithm for Multi-Label Learning[J]. Journal of Computer Research and Development, 2017, 54(5): 1024-1035. |
| 李峰, 苗夺谦, 张志飞, 等. 基于互信息的粒化特征加权多标签学习K近邻算法[J]. 计算机研究与发展, 2017, 54(5): 1024-1035. | |
| [6] | LI Yonghao, HU Liang, GAO Wanfu. Label Correlations Variation for Robust Multi-Label Feature Selection[J]. Information Sciences, 2022, 609: 1075-1097. |
| [7] | OUYANG Xiao, TAO Hong, FAN Ruidong, et al. Weakly Supervised Multi-Label Learning Using Prior Label Correlation Information[J]. Journal of Software, 2023, 34(4): 1732-1748. |
| 欧阳宵, 陶红, 范瑞东, 等. 利用标签相关性先验的弱监督多标签学习方法[J]. 软件学报, 2023, 34(4): 1732-1748. | |
| [8] | DING Jiaman, LIU Nan, ZHOU Shujie, et al. Semi-Supervised Weak-Label Classification Method by Regularization[J]. Chinese Journal of Computers, 2022, 45(1): 69-81. |
| 丁家满, 刘楠, 周蜀杰, 等. 基于正则化的半监督弱标签分类方法[J]. 计算机学报, 2022, 45(1): 69-81. | |
| [9] |
ZHANG Minling, WU Lei. Lift: Multi-Label Learning with Label-Specific Features[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(1): 107-120.
doi: 10.1109/TPAMI.2014.2339815 pmid: 26353212 |
| [10] | MAHAPATRA D, DONG Chaosheng, CHEN Yetian, et al. Multi-Label Learning to Rank through Multi-Objective Optimization[C]// ACM. Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. New York: ACM, 2023: 4605-4616. |
| [11] | TANG Wei, ZHANG Weijia, ZHANG Minling. Multi-Instance Partial-Label Learning: Towards Exploiting Dual Inexact Supervision[J]. Science China Information Sciences, 2024, 67(3): 48-61. |
| [12] | SUN Lijuan, FENG Songhe, WANG Tao, et al. Partial Multi-Label Learning by Low-Rank and Sparse Decomposition[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2019, 33(1): 5016-5023. |
| [13] | ZHANG Minling, FANG Junpeng. Partial Multi-Label Learning via Credible Label Elicitation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021, 43(10): 3587-3599. |
| [14] | GONG Xiuwen, YUAN Dong, BAO Wei. Partial Multi-Label Learning via Large Margin Nearest Neighbour Embeddings[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2022, 36(6): 6729-6736. |
| [15] | LIU Bingqing, JIA Binbin, ZHANG Minling. Towards Enabling Binary Decomposition for Partial Multi-Label Learning[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(11): 13203-13217. |
| [16] | LYU Gengyu, FENG Songhe, LI Yidong. Partial Multi-Label Learning via Probabilistic Graph Matching Mechanism[C]// ACM. Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. New York: ACM, 2020: 105-113. |
| [17] | YIN Jianhua, LIU Zhenbing, WEI Huangzhao. Partial Label Classification Algorithm Based on Sparse Reconstruction Disambiguation[J]. CAAI Transactions on Intelligent Systems, 2023, 18(4): 708-718. |
| 殷建华, 刘振丙, 魏黄曌. 基于稀疏重构消歧的偏标记分类算法[J]. 智能系统学报, 2023, 18(4): 708-718. | |
| [18] | HANG Junyi, ZHANG Minling. Partial Multi-Label Learning with Probabilistic Graphical Disambiguation[C]// ACM. Proceedings of the 37th Conference on Neural Information Processing Systems. New York: ACM, 2024: 1339-1351. |
| [19] | YU Guoxian, CHEN Xia, DOMENICONI C, et al. Feature-Induced Partial Multi-Label Learning[C]// IEEE. 2018 IEEE International Conference on Data Mining (ICDM). New York: IEEE, 2018: 1398-1403. |
| [20] | SUN Lijuan, FENG Songhe, LIU Jun, et al. Global-Local Label Correlation for Partial Multi-Label Learning[J]. IEEE Transactions on Multimedia, 2022, 24: 581-593. |
| [21] | XIE Mingkun, HUANG Shengjun. Partial Multi-Label Learning with Noisy Label Identification[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(7): 3676-3687. |
| [22] | SUN Lijuan, FENG Songhe, LYU Gengyu, et al. Partial Multi-Label Learning with Noisy Side Information[J]. Knowledge and Information Systems, 2021, 63(2): 541-564. |
| [23] | ZHAO Peng, ZHAO Shiyi, ZHAO Xuyang, et al. Partial Multi-Label Learning Based on Sparse Asymmetric Label Correlations[EB/OL]. (2022-07-07)[2024-06-10]. https://doi.org/10.1016/j.knosys.2022.108601. |
| [24] | HU Yan, FANG Xiaozhao, KANG Peipei, et al. Dual Noise Elimination and Dynamic Label Correlation Guided Partial Multi-Label Learning[J]. IEEE Transactions on Multimedia, 2024, 26: 5641-5656. |
| [25] |
WANG Changdong, CHEN Mansheng, HUANG Ling, et al. Smoothness Regularized Multiview Subspace Clustering with Kernel Learning[J]. IEEE Transactions on Neural Networks and Learning Systems, 2021, 32(11): 5047-5060.
doi: 10.1109/TNNLS.2020.3026686 pmid: 33027007 |
| [1] | 印杰, 陈浦, 杨桂年, 谢文伟, 梁广俊. 基于人工智能的物联网DDoS攻击检测[J]. 信息网络安全, 2024, 24(11): 1615-1623. |
| [2] | 李鹏超, 张全涛, 胡源. 基于双注意力机制图神经网络的智能合约漏洞检测方法[J]. 信息网络安全, 2024, 24(11): 1624-1631. |
| [3] | 陈宝刚, 张毅, 晏松. 民航空管信息系统用户多因子持续身份可信认证方法研究[J]. 信息网络安全, 2024, 24(11): 1632-1642. |
| [4] | 兰浩良, 王群, 徐杰, 薛益时, 张勃. 基于区块链的联邦学习研究综述[J]. 信息网络安全, 2024, 24(11): 1643-1654. |
| [5] | 张志强, 暴亚东. 融合RF和CNN的异常流量检测算法[J]. 信息网络安全, 2024, 24(11): 1655-1664. |
| [6] | 夏玲玲, 马卓, 郭向民, 倪雪莉. 基于改进加权LeaderRank的目标人员重要度排序算法[J]. 信息网络安全, 2024, 24(11): 1665-1674. |
| [7] | 胡文涛, 徐靖凯, 丁伟杰. 基于溯因学习的无监督网络流量异常检测[J]. 信息网络安全, 2024, 24(11): 1675-1684. |
| [8] | 马卓, 陈东子, 何佳涵, 王群. 基于多因素解纠缠的用户—兴趣点联合预测[J]. 信息网络安全, 2024, 24(11): 1685-1695. |
| [9] | 周胜利, 徐睿, 陈庭贵, 蒋可怡. 基于事理图谱的受骗网络行为风险演进研究[J]. 信息网络安全, 2024, 24(11): 1696-1709. |
| [10] | 马如坡, 王群, 尹强, 高谷刚. Modbus TCP协议安全风险分析及对策研究[J]. 信息网络安全, 2024, 24(11): 1710-1720. |
| [11] | 裴炳森, 李欣, 樊志杰, 蒋章涛. 视频监控数据跨域安全共享传输控制系统设计与实现[J]. 信息网络安全, 2024, 24(11): 1721-1730. |
| [12] | 顾海艳, 柳琪, 马卓, 朱涛, 钱汉伟. 基于可用性的数据噪声添加方法研究[J]. 信息网络安全, 2024, 24(11): 1731-1738. |
| [13] | 张鹏, 罗文华. 基于布隆过滤器查找树的日志数据区块链溯源机制[J]. 信息网络安全, 2024, 24(11): 1739-1748. |
| [14] | 栾润生, 蒋平, 孙银霞, 张沁芝. 电子数据取证技术研究进展和趋势分析[J]. 信息网络安全, 2024, 24(11): 1749-1762. |
| [15] | 秦振凯, 徐铭朝, 蒋萍. 基于提示学习的案件知识图谱构建方法及应用研究[J]. 信息网络安全, 2024, 24(11): 1773-1782. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||