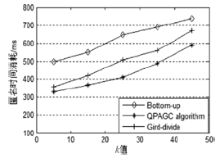
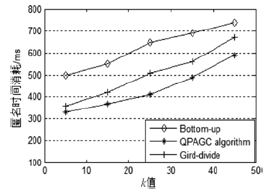
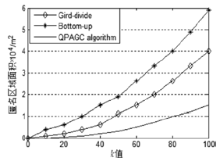
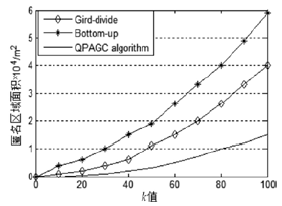
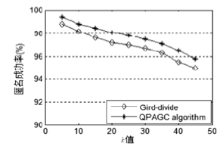
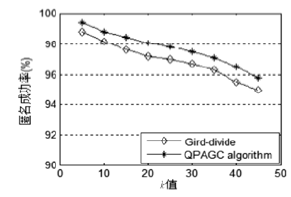
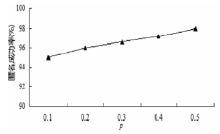
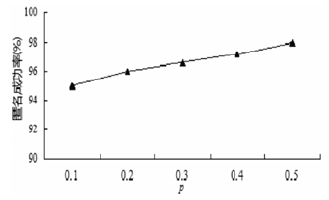
| [1] |
MOKBEL M F, CHOW C Y, AREF W G.The new Casper: query processing for location services without compromising privacy[C] / /Proc of the 32nd International Conference on Very Large Data Bases, 2006:763-774.
|
| [2] |
CHOW C, MOKBEL M F.Enabling privacy continuous queries for revealed user location [C] //Proc of International Symposium on Advances in Spatial and Temporal Databases. Berlin: Springer-Verlag, 2007.
|
| [3] |
潘晓,肖珍,孟小峰.位置隐私研究综述[J].计算机科学与探索,2007, 1(03):268-281.
|
| [4] |
Xiao Z, Mend X, Xu J.Quality aware privacy protection for location-based services[M].Berlin Heidelberg: Sprinter, 2007.
|
| [5] |
Kido H, Yanagisawa Y, Satoh T.An anonymous communication technique using dummies for location-based Services[C]//IEEE International Conference on Pervasive Services, 2005: 88-97.
|
| [6] |
Mi Young Jang, Sung Jae Jang, Jae Woo Chang.A New KNN query processing algorithm enhancing privacy privacy protection in location-based services[C]//IEEE First International Conference on Mobile Services,2012:17-24.
|
| [7] |
Kalnis P, Ghinita G, Mouratidis K, et al.Preventing location-based identify inference in anonymous spatial queries[J].IEEE Transactions on Knowledge and Data Engineering,2007, 19(12):1719-1733.
|
| [8] |
Gruteser M, Grunwal D.Anonymous usage of location-based services through spatial and temporal cloaking[C]//Proceedings of the 1st International Conference on mobile systems, applications and services. New York: Acm Press, 2003:163-168.
|
| [9] |
Gedik B, Liu L. location privacy in mobile systems: a personalized anonymization model[C]//Proc Of International Conference on Distributed Computing System,2005:620-629.
|
| [10] |
Mokbel M F, Chow C Y, Aref W G.New Casper: Query processing for location services without compromising privacy[C]//Proceedings of the 32nd International Conference on Very Large Data Bases, 2006: 763-774.
|
| [11] |
Bamba B, Liu L, Pesti P, et al.Supporting anonymous location queries in mobile environments with privacy grid[C]//Proceedings of the 17th International Conference on World Wide Web, 2008:237-249.
|
| [12] |
邹永贵,张玉涵. 基于网格划分空间的位置匿名算法[J]. 计算机应用研究,2012,29(8):3059-3061.
|
| [13] |
牛红卫. 位置服务中查询隐私保护方法的研究[D].秦皇岛:燕山大学,2012 .
|
| [14] |
MIIURA K, SATO F.A Hybrid method of user privacy protection for location based services[C]//Complex, Intelligent, and software Intensive systems (CISIS), 2013:434-439.
|
| [15] |
韩建民,林瑜,于娟,等,基于位置k-匿名的LBS隐私保护方法的研究[J].小型微型计算机系统,2014,35(9):2089-2090.
|
| [16] |
霍峥,孟小峰. 轨迹隐私保护技术研究[J].计算机学报,2011, 34(10): 1824-1825.
|
| [17] |
BRINKHOFF T.A framework for generating network-based moving objects[J].an international journal on advances of computer science for geographic information systems, 2002, 6(2):153-180.
|
| [18] |
赵泽茂,胡慧东,张帆,等,圆形区域划分的k-匿名位置隐私保护方法[J].北京交通大学学报,2013,37(5):14-18.
|
 ), 蒋朝惠
), 蒋朝惠