Netinfo Security ›› 2025, Vol. 25 ›› Issue (2): 177-193.doi: 10.3969/j.issn.1671-1122.2025.02.001
Previous Articles Next Articles
Advances in Watermarking Techniques for Large Language Models
QIN Zhongyuan1, WANG Tiantian1, LIU Weiqiang2, ZHANG Qunfang2
- 1. School of Cyber Science and Engineering, Southeast University, Nanjing 211102, China
2. Artillery and Air-Defence Institute Nanjing Campus, Nanjing 211132, China
-
Received:2024-04-08Online:2025-02-10Published:2025-03-07
CLC Number:
Cite this article
QIN Zhongyuan, WANG Tiantian, LIU Weiqiang, ZHANG Qunfang. Advances in Watermarking Techniques for Large Language Models[J]. Netinfo Security, 2025, 25(2): 177-193.
share this article
Add to citation manager EndNote|Ris|BibTeX
URL: http://netinfo-security.org/EN/10.3969/j.issn.1671-1122.2025.02.001
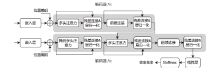
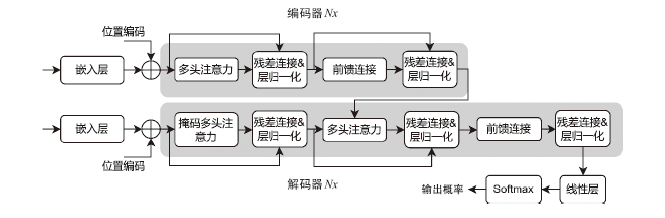
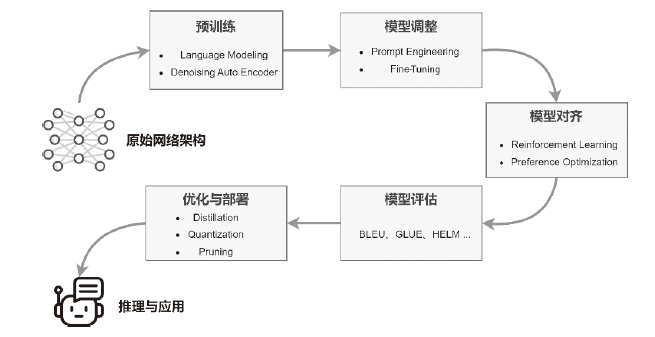
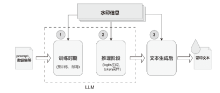
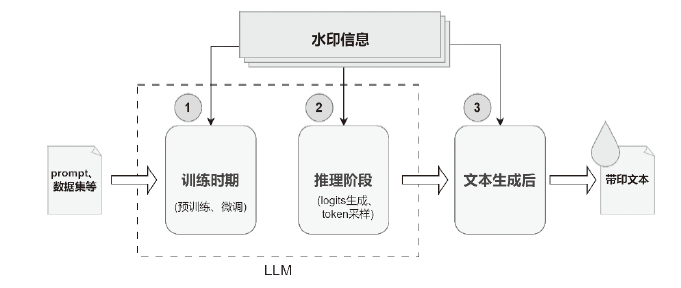
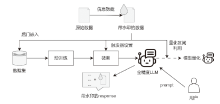
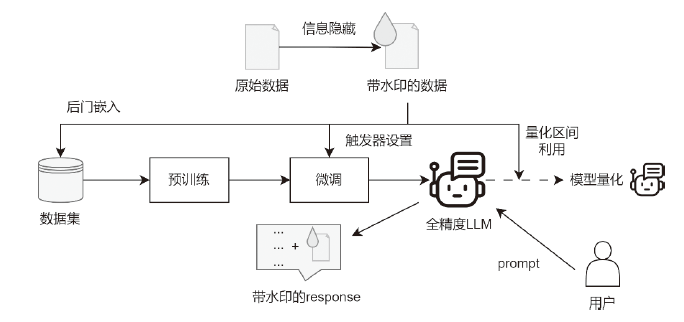
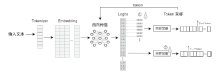

| 推理 时间点 | 算法类别 | 算法名称 | 算法概述 | 水印 信息 |
|---|---|---|---|---|
| Logits 生成 | Logits 缩放 | Adaptive Text Watermark[ | 生成logits缩放向量和自适应温度系数 | zero-bit |
| 添加message logits | CTWL[ | 概率公式推导的可编码水印 | multi-bits | |
| Robust Watermark[ | 额外LLM生成logits偏置项 | zero-bit | ||
| Token 采样 | 调整同义词 分布 | LLCG API WM[ | 编程语言token-level同义词替换 | zero-bit |
| 含散列密钥的伪随机 函数 | OpenAI WM[ | OpenAI水印方案(未详细说明) | 未说明 | |
| KGW Watermark[ | 伪随机函数划分红绿列表 | zero-bit | ||
| NS-Watermark[ | 优化绿色单词插入位置 | |||
| Unforgeable Publicly Verifiable Watermark[ | 生成器和检测器共享嵌入网络 | |||
| SWEET[ | 仅在高熵位置促进绿色token | |||
| DiPmark[ | 重新加权策略促进采样 | |||
| SemaMark[ | 用token语义替代哈希 | |||
| WIS[ | token重要性估算 | |||
| X-Mark[ | 添加单词间互斥规则 | |||
| OPT Watermark[ | 针对困惑度变化的多目标优化 | |||
| MOO[ | 感知器网络生成分割比率 | |||
| Advanced Detection Schemes[ | 使用不同哈希 密钥 | multi-bits | ||
| Error-Correction Code Based Watermark[ | 通过ECC编码选定红或绿列表 | |||
| 制定水印 映射法则 | Multi-Bit Distortion-Free Watermark[ | 分布间隔伪随机编码 |
| 方案名称 | 水印嵌入方案 | 水印信息 | 方案类别 |
|---|---|---|---|
| ACW[ | 有选择地应用一组精心设计的语义保留、幂等代码转换 | multi-bits | 信息代换 |
| EASYMARK[ | 利用Unicode 具有相同或相似外观的代码点进行字符替换 | multi-bits | 信息代换 |
| Random Sequence/Unicode Watermark[ | 研究了两种水印:在文档末尾插入随机序列,用Unicode相似字符随机替换字符 | zero-bit | 信息增添/代换 |
| DeepTextMark[ | 基于深度学习,应用 Word2Vec 和句子编码进行水印插入,并使用基于转换器的分类器进行水印检测 | zero-bit | 神经网络 |
| Robust Multi-bit Natural Language Watermark[ | 通过语义或句法上的特征精确定位水印的位置,并通过infill模型嵌入水印 | multi-bits | 神经网络 |
| REMARK-LLM[ | 额外的LLM将生成的文本及其相应的签名编码到潜在特征空间中,添加它们的特征表示并产生词汇表上的带水印的分布 | multi-bits | 神经网络 |
| 攻击类型 | 典型攻击 模型 | 攻击方法概述 | 攻击算法是否通用 | 作者提出的 对抗手段 |
|---|---|---|---|---|
| 擦除攻击 | Generic Attack Methodology[ | 给定带水印的文本,在每次迭代时,使用小型屏蔽 LLM 生成片段替换,同时确保根据奖励模型判断的响应质量下降幅度轻微 | 通用 | 强水印方案中,计算有限的攻击者擦除水印必然导致文本质量显著下降 |
| 释义攻击 | DIPPER[ | 训练一个11B 参数释义生成模型:(1)在上下文中释义长文本(2)控制输出多样性 | 给定候选文本,在序列数据库检索语义相似的生成 | |
| Bigram Paraphrase Attack[ | 解码大量来自束搜索的top-raking序列,获得 k 个释义候选,然后选择与原始句子具有最小二元组重叠的候选者 | 基于LSH的鲁棒句子级语义水印算法:对候选句子进行编码和LSH哈希,进行句子级拒绝采样,直到采样的句子落入语义嵌入空间中的水印分区中 | ||
| 欺骗攻击 | Spoofing Attacks on Watermarked Models[ | 多次查询带水印的 LLM,以观察其输出中成对token的出现情况,从而估计 N 个token的绿名单分数 | 非通用 | 未提及 |
| Automated Watermark Stealing[ | 建立水印规则模型,通过频繁出现的token序列来推断基于红绿列表的水印规则 | 设计鲁棒性更高的水印方案,如使用多个密钥、采样修改等 |
| [1] | RADFORD A, NARASIMHAN K, SALIMANS T, et al. Improving Language Understanding by Generative Pre-Training[EB/OL]. (2018-06-11)[2024-03-21]. https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf. |
| [2] | RADFORD A, WU J, CHILD R, et al. Language Models are Unsupervised Multitask Learners[J]. OpenAI Blog, 2019, 1(8): 9-32. |
| [3] | BROWN T B, MANN B, RYDER N, et al. Language Models are Few-Shot Learners[J]. Neural Information Processing Systems, 2020, 33: 1877-1901. |
| [4] | OPENAI, ACHIAM J, ADLER S, et al. GPT-4 Technical Report[EB/OL]. (2024-03-04)[2024-03-21]. https://arxiv.org/pdf/2303.08774. |
| [5] | TOUVRON H, MARTIN L, STONE K, et al. Llama 2: Open Foundation and Fine-Tuned Chat Models[EB/OL]. (2023-07-19)[2024-03-21]. https://arxiv.org/pdf/2307.09288. |
| [6] | DEVLIN J, CHANG M W, LEE K, et al. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding[C]//ACL. 17th Annual Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT 2019). Minneapolis: ACL, 2019: 4171-4186. |
| [7] | ZHANG S, ROLLER S, GOYAL N, et al. OPT: Open Pre-Trained Transformer Language Models[EB/OL]. (2022-06-21)[2024-03-21]. https://arxiv.org/abs/2205.01068. |
| [8] | YANG Zhilin, DAI Zihang, YANG Yiming, et al. XLNet: Generalized Autoregressive Pretraining for Language Understanding[J]. Neural Information Processing Systems, 2019, 32: 1-11. |
| [9] | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is All You Need[J]. Advances in Neural Information Processing Systems, 2017, 30: 1-11. |
| [10] | LEVIATHAN Y, KALMAN M, MATIAS Y. Fast Inference from Transformers via Speculative Decoding[C]// JMLR. Proceedings of the 40th International Conference on Machine Learning. Hawaii: JMLR, 2023: 19274-19286. |
| [11] | KAlYAN K S, RAJASEKHARAN A, SANGEETHA S. Ammus: A Survey of Transformer-Based Pretrained Models in Natural Language Processing[EB/OL]. (2021-08-28)[2024-03-21]. https://arxiv.org/pdf/2108.05542. |
| [12] | OUYANG Long, WU J, JIANG Xu, et al. Training Language Models to Follow Instructions with Human Feedback[J]. Neural Information Processing Systems, 2022, 35: 27730-27744. |
| [13] | RAFAILOV R, SHARMA A, MITCHELL E, et al. Direct Preference Optimization: Your Language Model is Secretly a Reward Model[J]. Neural Information Processing Systems, 2024, 36: 1-14. |
| [14] | ETHAYARAJH K, XU W, MUENNIGHOFF N, et al. KTO: Model Alignment as Prospect Theoretic Optimization[EB/OL]. (2023-09-03)[2024-03-21]. https://arxiv.org/pdf/2402.01306v3. |
| [15] | CHANG Yupeng, WANG Xu, WANG Jindong, et al. A Survey on Evaluation of Large Language Models[J]. ACM Transactions on Intelligent Systems and Technology, 2024, 15(3): 1-45. |
| [16] | LI Linyang, JIANG Botian, WANG Pengyu, et al. Watermarking LLMs with Weight Quantization[EB/OL]. (2023-10-17)[2024-03-21]. https://arxiv.org/pdf/2310.11237. |
| [17] | WANG L, YANG Wenkai, CHEN Deli, et al. Towards Codable Watermarking for Injecting Multi-Bit Information to LLM[C]// ICLR. The Twelfth International Conference on Learning Representations. Vienna: OpenReview, 2024: 1-27. |
| [18] | YOO K, AHN W, JANG J, et al. Robust Multi-Bit Natural Language Watermarking through Invariant Features[C]// ACL. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics. Toronto: ACL, 2023: 2092-2115. |
| [19] | LI Shuai, CHEN Kejiang, TANG Kunsheng, et al. Function Marker: Watermarking Language Datasets via Knowledge Injection[EB/OL]. (2023-11-17)[2024-03-21]. https://arxiv.org/pdf/2311.09535v2. |
| [20] | YAO Hongwei, LOU Jian, QIN Zhan, et al. PromptCARE: Prompt Copyright Protection by Watermark Injection and Verification[EB/OL]. (2023-11-17)[2024-03-21]. https://arxiv.org/pdf/2311.09535v2. |
| [21] | ZHANG Ruisi, HUSSAIN S S, NEEKHARA P, et al. REMARK-LLM: A Robust and Efficient Watermarking Framework for Generative Large Language Models[C]// IEEE. 2024 IEEE Symposium on Security and Privacy (SP). New York: IEEE, 2024: 845-861. |
| [22] | LI Zongjie, WANG Chaozheng, WANG Shuai, et al. Protecting Intellectual Property of Large Language Model-Based Code Generation APIs via Watermarks[C]// ACM. Proceedings of the 2023 ACM SIGSAC Conference on Computer and Communications Security. New York: ACM, 2023: 2336-2350. |
| [23] | SATO R, TAKEZAWA Y, BAO H, et al. Embarrassingly Simple Text Watermarks[EB/OL]. (2023-10-13)[2024-03-21]. https://arxiv.org/pdf/2310.08920. |
| [24] | LEE T, HONG S, AHN J, et al. Who Wrote this Code? Watermarking for Code Generation[EB/OL]. (2023-07-03)[2024-03-21]. https://arxiv.org/pdf/2305.15060. |
| [25] | YANG Borui, LI Wei, XIANG Liyao, et al. Towards Code Watermarking with Dual-Channel Transformations[EB/OL]. (2024-01-02)[2024-03-21]. https://arxiv.org/pdf/2309.00860. |
| [26] | TAKEZAWA Y, SATO R, BAO H, et al. Necessary and Sufficient Watermark for Large Language Models[EB/OL]. (2023-10-02)[2024-03-21]. https://arxiv.org/pdf/2310.00833. |
| [27] | LIU Aiwei, PAN Leyi, HU Xuming, et al. An Unforgeable Publicly Verifiable Watermark for Large Language Models[C]// ICLR. The Twelfth International Conference on Learning Representations. Vienna: OpenReview, 2024: 1-17. |
| [28] | KIRCHENBAUER J, GEIPING J, WEN Y, et al. On the Reliability of Watermarks for Large Language Models[C]// ICLR. The Twelfth International Conference on Learning Representations. Vienna: OpenReview, 2024: 1-45. |
| [29] | TANG Ruixiang, CHUANG Yuneng, HU Xia. The Science of Detecting LLM-Generated Texts[J]. Communications of the ACM, 2024, 67(4): 50-59. |
| [30] | LIU Aiwei, PAN Leyi, LU Yijian, et al. A Survey of Text Watermarking in the Era of Large Language Models[J]. ACM Computing Surveys, 2024, 57(2): 1-36. |
| [31] | FERNANDEZ P, CHAFFIN A, TIT K, et al. Three Bricks to Consolidate Watermarks for Large Language Models[C]// IEEE. 2023 IEEE International Workshop on Information Forensics and Security (WIFS). New York: IEEE, 2023: 1-6. |
| [32] | BALDASSINI F B, NGUYEN H H, CHANG C C, et al. Cross-Attention Watermarking of Large Language Models[C]// ICASSP. 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). New York: IEEE, 2024: 4625-4629. |
| [33] | LI Shen, YAO Liuyi, GAO Jinyang, et al. Double-I Watermark: Protecting Model Copyright for LLM Fine-Tuning[EB/OL]. (2023-06-05)[2024-03-21]. https://arxiv.org/pdf/2402.14883. |
| [34] | XU Xiaojun, YAO Yuanshun, LIU Yang. Learning to Watermark LLM-Generated Text via Reinforcement Learning[EB/OL]. (2024-03-13)[2024-03-21]. https://arxiv.org/pdf/2403.10553. |
| [35] | LIU Yepeng, BU Yuheng. Adaptive Text Watermark for Large Language Models[EB/OL]. (2024-01-25)[2024-03-21]. https://arxiv.org/pdf/2401.13927v1. |
| [36] | LIU Aiwei, PAN Leyi, HU Xuming, et al. A Semantic Invariant Robust Watermark for Large Language Models[EB/OL]. (2023-10-10)[2024-03-21]. https://arxiv.org/pdf/2310.06356. |
| [37] | AARONSON S. My AI Safety Lecture for UT Effective Altruism[EB/OL]. (2022-11-28)[2024-03-21] https://scottaaronson.blog/?p=6823. |
| [38] | KIRCHENBAUER J, GEIPING J, WEN Y, et al. A Watermark for Large Language Models[C]// ICML. Proceedings of the 40th International Conference on Machine Learning. Hawaii: JMLR, 2023: 17061-17084. |
| [39] | WU Yihan, HU Zhengmian, ZHANG Hongyang, et al. DiPmark: A Stealthy, Efficient and Resilient Watermark for Large Language Models[EB/OL]. (2023-10-11)[2024-03-21]. https://arxiv.org/pdf/2310.07710v1. |
| [40] | REN Jie, XU Han, LIU Yiding, et al. A Robust Semantics-Based Watermark for Large Language Model against Paraphrasing[EB/OL]. (2023-11-15)[2024-03-21]. https://arxiv.org/pdf/2311.08721v1. |
| [41] | LI Yuhang, WANG Yihan, SHI Zhouxing, et al. Improving the Generation Quality of Watermarked Large Language Models via Word Importance Scoring[EB/OL]. (2023-11-16)[2024-03-21]. https://arxiv.org/pdf/2311.09668. |
| [42] | CHEN Liang, BIAN Yatao, DENG Yang, et al. X-Mark: Towards Lossless Watermarking through Lexical Redundancy[EB/OL]. (2023-11-16)[2024-03-21]. https://arxiv.org/pdf/2311.09832v1. |
| [43] | WOUTERS B. Optimizing Watermarks for Large Language Models[EB/OL]. (2023-12-28)[2024-03-21]. https://arxiv.org/pdf/2312.17295. |
| [44] | HUO Mingjia, SOMAYAJULA S A, LIANG Youwei, et al. Token-Specific Watermarking with Enhanced Detectability and Semantic Coherence for Large Language Models[EB/OL]. (2024-02-28)[2024-03-21]. https://arxiv.org/pdf/2402.18059v1. |
| [45] | QU Wenjie, YIN Dong, HE Zixin, et al. Provably Robust Multi-Bit Watermarking for AI-Generated Text via Error Correction Code[EB/OL]. (2024-01-30)[2024-03-21]. https://arxiv.org/pdf/2401.16820v1. |
| [46] | BOROUJENY M K, JIANG Ya, ZENG Kai, et al. Multi-Bit Distortion-Free Watermarking for Large Language Models[EB/OL]. (2024-02-26)[2024-03-21]. https://arxiv.org/pdf/2402.16578. |
| [47] | LI Boquan, ZHANG Mengdi, ZHANG Peixin, et al. Resilient Watermarking for LLM-Generated Codes[EB/OL]. (2024-02-12)[2024-03-21]. https://arxiv.org/pdf/2402.07518v1. |
| [48] | MUNYER T, ZHONG Xin. DeepTextMark: Deep Learning Based Text Watermarking for Detection of Large Language Model Generated Text[EB/OL]. (2023-05-09)[2024-03-21]. https://arxiv.org/pdf/2305.05773v1. |
| [49] | WEI J T Z, WANG R Y, JIA R. Proving Membership in LLM Pretraining Data via Data Watermarks[EB/OL]. (2024-02-16)[2024-03-21]. https://arxiv.org/pdf/2402.10892v1. |
| [50] | PANG Kaiyi, QI Tao, WU Chuhan, et al. Adaptive and Robust Watermark against Model Extraction Attack[EB/OL]. (2023-05-03)[2024-03-21]. https://arxiv.org/pdf/2405.02365v1. |
| [51] | SANDER T, FERNANDEZ P, DURMUS A, et al. Watermarking Makes Language Models Radioactive[EB/OL]. (2024-02-22)[2024-03-21]. https://arxiv.org/pdf/2402.14904v1. |
| [52] | GIBOULOT E, TEDDY F. WaterMax: Breaking the LLM Watermark Detectability-Robustness-Quality Trade-Off[EB/OL]. (2024-03-06)[2024-03-21]. https://arxiv.org/pdf/2403.04808v1. |
| [53] | PANG Qi, HU Shengyuan, ZHENG Wenting, et al. Attacking LLM Watermarks by Exploiting Their Strengths[EB/OL]. (2024-02-15)[2024-03-21]. https://openreview.net/forum?id=P2FFPRxr3Q. |
| [54] | HOU A B, ZHANG Jingyu, HE Tianxing, et al. SemStamp: A Semantic Watermark with Paraphrastic Robustness for Text Generation[EB/OL]. (2023-10-06)[2024-03-21]. https://arxiv.org/pdf/2310.03991v1. |
| [55] | ZHANG Hanlin, EDELMAN B L, FRANCATI D, et al. Watermarks in the Sand: Impossibility of Strong Watermarking for Generative Models[EB/OL]. (2023-11-07)[2024-03-21]. https://arxiv.org/pdf/2311.04378v1. |
| [56] | KRISHNA K, SONG Yixiao, KARPINSKA M, et al. Paraphrasing Evades Detectors of AI-Generated Text, but Retrieval is an Effective Defense[J]. Advances in Neural Information Processing Systems, 2024, 36: 1-32. |
| [57] | SADASIVAN V S, KUMAR A, BALASUBRAMANIAN S, et al. Can AI-Generated Text be Reliably Detected?[EB/OL]. (2023-03-17)[2024-03-21]. https://arxiv.org/pdf/2303.11156v1. |
| [58] | JOVANOVIC N, STAAB R, VECHEV M. Watermark Stealing in Large Language Models[EB/OL]. (2024-02-29)[2024-03-21]. https://arxiv.org/pdf/2402.19361v1. |
| [59] | ZHAO Xuandong, ANANTH P, LI Lei, et al. Provable Robust Watermarking for AI-Generated Text[EB/OL]. (2023-06-30)[2024-03-21]. https://arxiv.org/pdf/2306.17439v1. |
| [60] | TANG L, UBERTI G, SHLOMI T. Baselines for Identifying Watermarked Large Language Models[EB/OL]. (2023-05-29)[2024-03-21]. https://arxiv.org/pdf/2305.18456. |
| [61] | SINGH K, ZOU J. New Evaluation Metrics Capture Quality Degradation due to LLM Watermarking[EB/OL]. (2024-03-18)[2024-03-21]. https://openreview.net/forum?id=PuhF0hyDq1. |
| [62] | AJITH A, SINGH S, PRUTHI D. Performance Trade-Offs of Watermarking Large Language Models[EB/OL]. (2024-01-16)[2024-03-21]. https://arxiv.org/pdf/2311.09816v1. |
| [63] | LUO Yiyang, LIN Ke, GU Chao. Lost in Overlap: Exploring Watermark Collision in LLMs[EB/OL]. (2024-03-15)[2024-03-21]. https://arxiv.org/pdf/2403.10020v1. |
| [1] | CHEN Haoran, LIU Yu, CHEN Ping. Endogenous Security Heterogeneous Entity Generation Method Based on Large Language Model [J]. Netinfo Security, 2024, 24(8): 1231-1240. |
| [2] | XIANG Hui, XUE Yunhao, HAO Lingxin. Large Language Model-Generated Text Detection Based on Linguistic Feature Ensemble Learning [J]. Netinfo Security, 2024, 24(7): 1098-1109. |
| [3] | GUO Xiangxin, LIN Jingqiang, JIA Shijie, LI Guangzheng. Security Analysis of Cryptographic Application Code Generated by Large Language Model [J]. Netinfo Security, 2024, 24(6): 917-925. |
| [4] | QIN Zhenkai, XU Mingchao, JIANG Ping. Research on the Construction Method and Application of Case Knowledge Graph Based on Prompt Learning [J]. Netinfo Security, 2024, 24(11): 1773-1782. |
| [5] | LI Jiao, ZHANG Yuqing, WU Yabiao. Data Augmentation Method via Large Language Model for Relation Extraction in Cybersecurity [J]. Netinfo Security, 2024, 24(10): 1477-1483. |
| [6] | HUANG Kaijie, WANG Jian, CHEN Jiongyi. A Large Language Model Based SQL Injection Attack Detection Method [J]. Netinfo Security, 2023, 23(11): 84-93. |
| [7] | CHENG Yuan-yuan, LIU Xiao-wei, ZHANG Jin, GAO Yan. Research on Fault Tolerant Digital Text Watermarking Algorithm [J]. Netinfo Security, 2015, 15(5): 34-40. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||