信息网络安全 ›› 2026, Vol. 26 ›› Issue (5): 713-724.doi: 10.3969/j.issn.1671-1122.2026.05.004
基于无模型强化学习的非线性信息物理系统零和博弈的安全优化算法
解相朋1, 朱淇2( )
)
- 1
南京邮电大学物联网学院 南京 210023
2南京邮电大学自动化学院 南京 210023
-
收稿日期:2026-02-05出版日期:2026-05-10发布日期:2026-06-03 -
通讯作者:朱淇 13511598422@163.com -
作者简介:解相朋(1982—),男,山东,教授,博士,主要研究方向为工业控制模糊系统|朱淇(2002—),女,江苏,硕士研究生,主要研究方向为自适应动态规划 -
基金资助:国家自然科学基金(U25B2056)
Safe Optimization Algorithm for Zero-Sum Game of Nonlinear Cyber-Physical Systems Based on Model-Free Reinforcement Learning
XIE Xiangpeng1, ZHU Qi2()
- 1
School of Internet of Things ,Nanjing University of Posts and Telecommunications Nanjing 210023, China
2College of Automation ,Nanjing University of Posts and Telecommunications Nanjing 210023, China
-
Received:2026-02-05Online:2026-05-10Published:2026-06-03
摘要:
针对遭受拒绝服务攻击的汽车主动悬架系统,文章提出一种基于无模型强化学习的非线性信息物理系统零和博弈的安全优化算法,旨在解决系统模型未知和网络数据包丢失场景下的安全控制问题。通过引入伯努利随机序列刻画拒绝服务攻击导致的数据包丢失过程,将受攻击系统建模为随机非线性系统,并定义包含控制输入与干扰惩罚的折扣代价函数,将安全控制问题转化为一个零和博弈问题。此外,设计基于Q学习的无模型值迭代算法,通过构造包含状态、控制与扰动的Q函数,避免传统方法对系统模型的依赖。同时,采用基于神经网络的评价—执行—干扰架构实现函数逼近,分别利用评价网络逼近Q函数,执行网络与干扰网络分别生成控制策略与扰动策略。理论分析表明,文章所提算法能保证值函数序列的单调收敛性和一致有界性。仿真结果表明,该算法在拒绝服务攻击环境下仍能有效维持悬架系统的稳定性与控制性能。
中图分类号:
引用本文
解相朋, 朱淇. 基于无模型强化学习的非线性信息物理系统零和博弈的安全优化算法[J]. 信息网络安全, 2026, 26(5): 713-724.
XIE Xiangpeng, ZHU Qi. Safe Optimization Algorithm for Zero-Sum Game of Nonlinear Cyber-Physical Systems Based on Model-Free Reinforcement Learning[J]. Netinfo Security, 2026, 26(5): 713-724.
表1
悬架系统相关参数定义
| 参数 | 定义 |
|---|---|
| 簧载质量/非簧载质量 | |
| 阻尼/轮胎阻尼 | |
| 悬架刚度/轮胎刚度 | |
| 车身/轮胎/路面位移 | |
| 车身/轮胎/路面的时间导数 | |
| 立方刚度 |
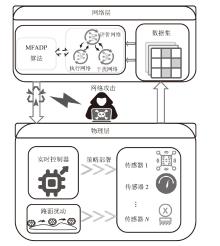
图1
信息物理系统模型
表2
AQVSS的参数值设置
| 参数 | 值 |
|---|---|
| 2.45 kg | |
| 7.5 N·m/s | |
| 900 N/m | |
| 10 N·s/m | |
| 1 kg | |
| 5 N·m/s | |
| 2500 N/m | |
| 0.038 m |
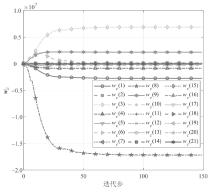
图2
评价网络权值
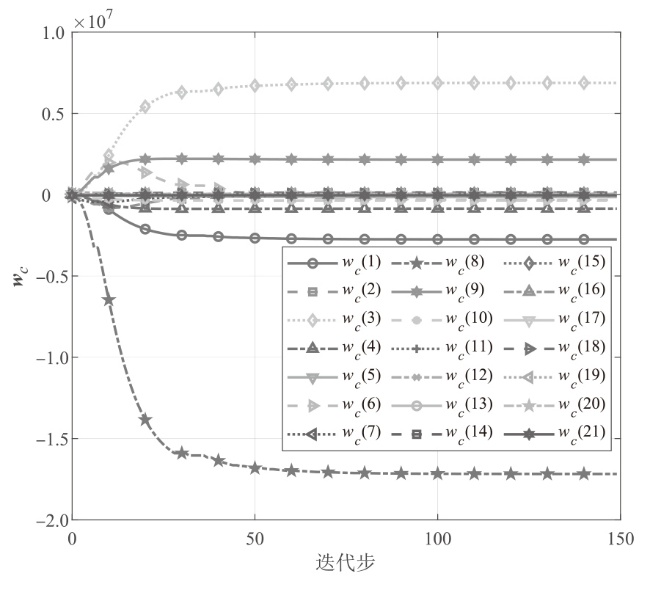
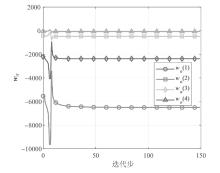
图3
执行网络权值
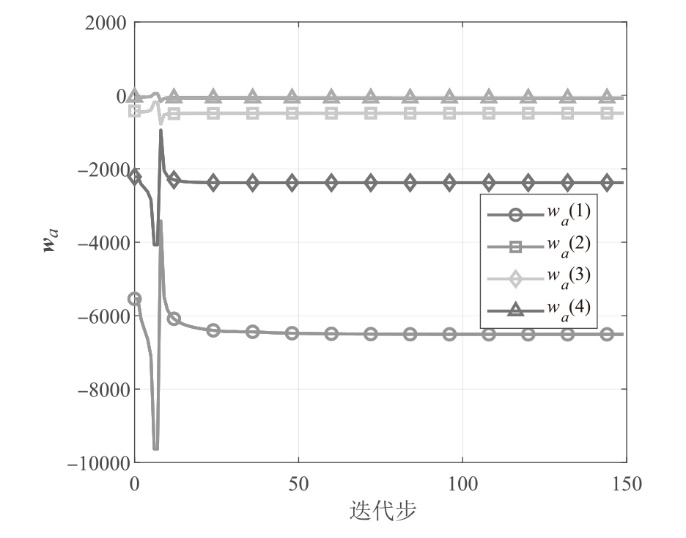
图4
干扰网络权值
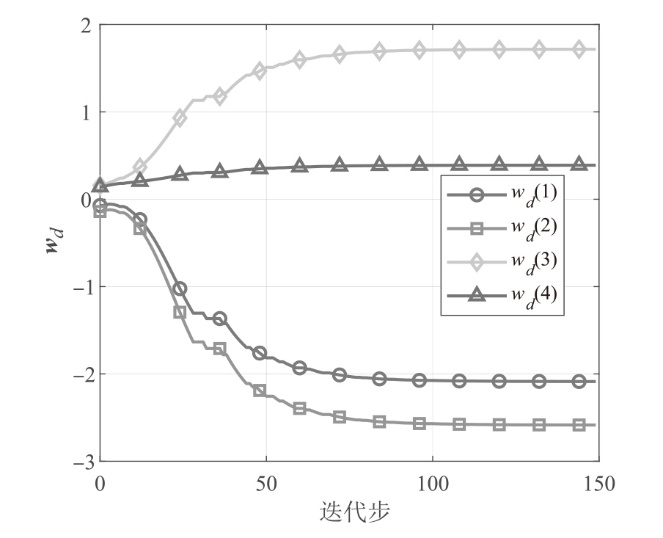
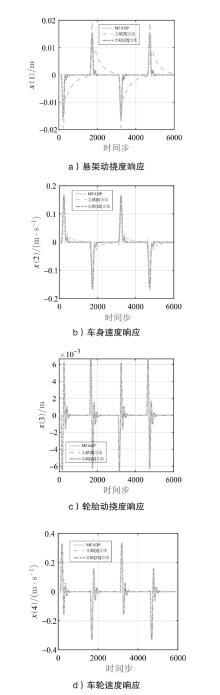
图5
悬架系统在${{l}_{r1}}(k)$下的状态
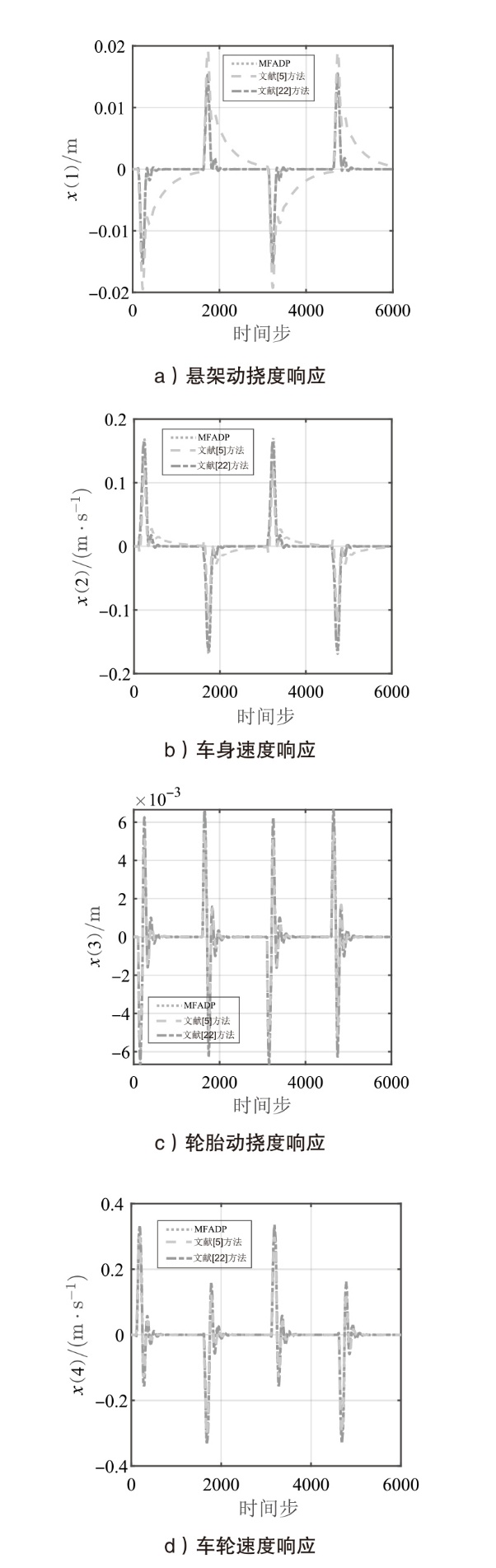
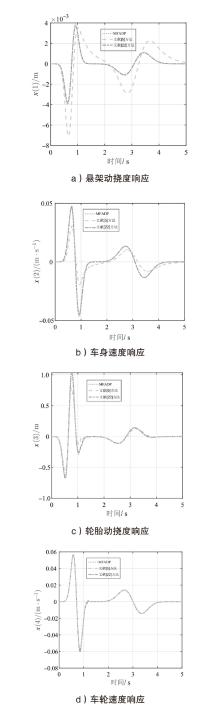
图6
悬架系统在${{l}_{r2}}(k)$下的状态
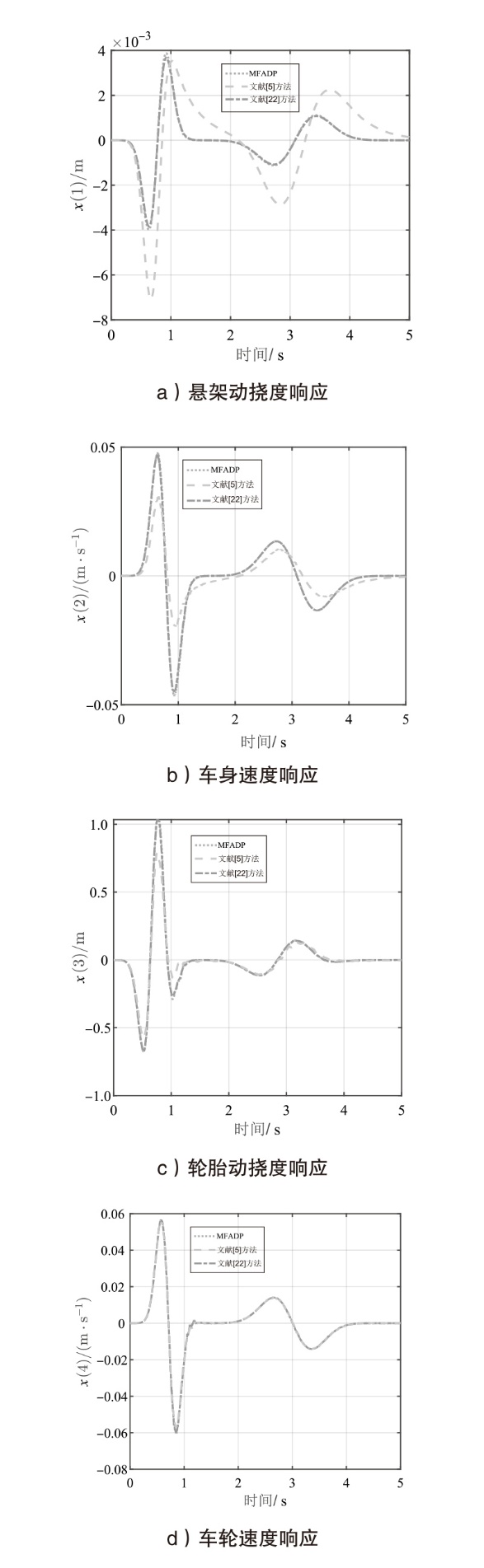
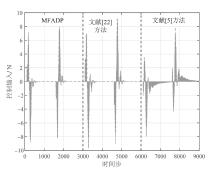
图7
悬架系统在${{l}_{r1}}(k)$下的控制输入
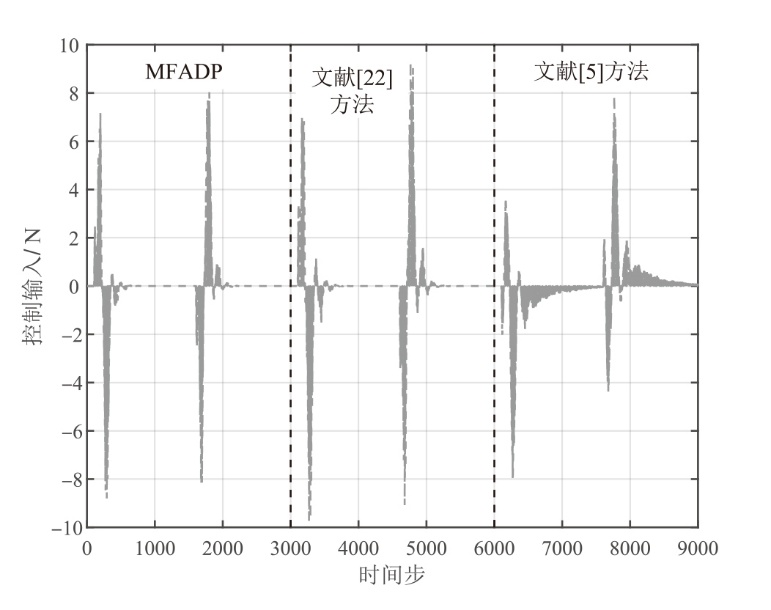
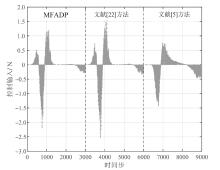
图8
悬架系统在${{l}_{r2}}(k)$下的控制输入
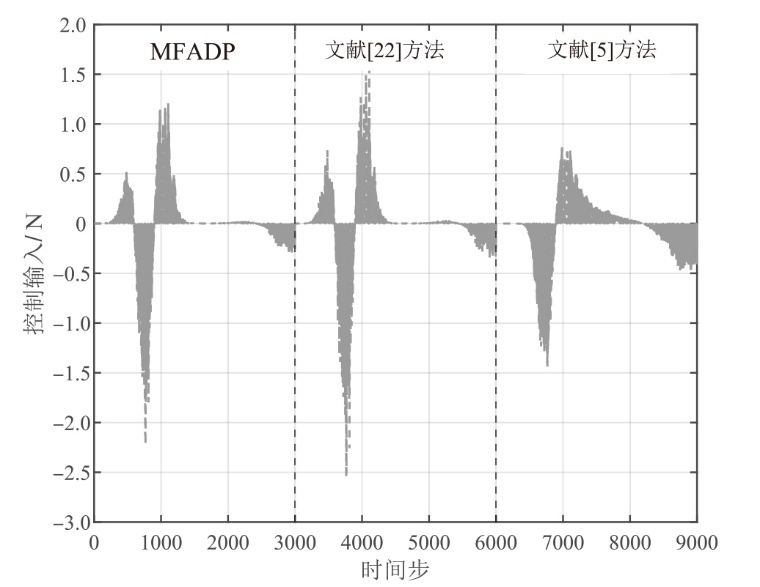

图9
悬架系统在${{l}_{r1}}(k)$下的位移响应
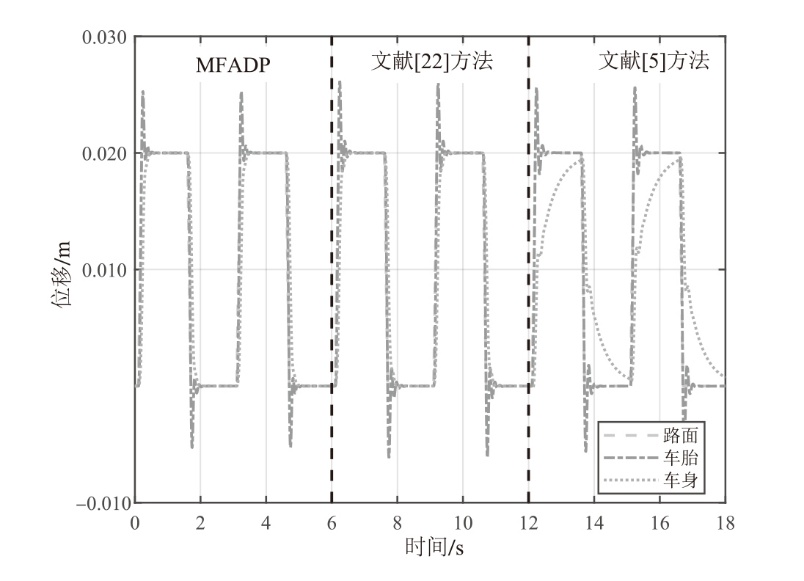
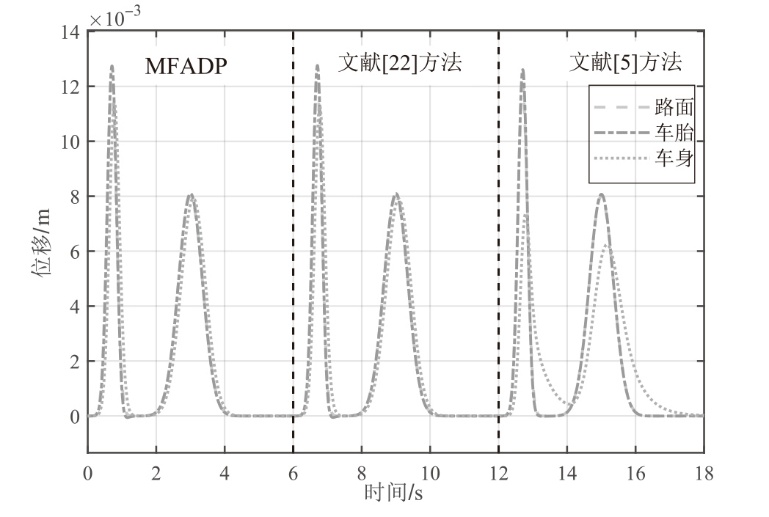
图10
悬架系统在${{l}_{r2}}(k)$下的位移响应
| [1] | JIN Zengwang, JIANG Lingyang, DING Junyi, et al. A Review of Research on Industrial Control System Security[J]. Netinfo Security, 2025, 25(3): 341-363. |
| 金增旺, 江令洋, 丁俊怡, 等. 工业控制系统安全研究综述[J]. 信息网络安全, 2025, 25(3):341-363. | |
| [2] |
HUANG Penghao, KIM J, KUMAR P R, et al. Enhancing Cybersecurity for Industrial Control Systems: Innovations in Protecting PLC-Dependent Industrial Infrastructures[J]. IEEE Internet of Things Journal, 2024, 11(22): 36486-36493.
doi: 10.1109/JIOT.2024.3408098 URL |
| [3] | CHEN Da, CAI Xiao, SUN Yanbin, et al. Optimization of Data Conflict and DDoS Attack Defense Mechanisms in Industrial Control Systems Based on Greedy Algorithm[J]. Netinfo Security, 2025, 25(6): 943-954. |
| 陈大, 蔡肖, 孙彦斌, 等. 基于贪心算法优化工业控制系统数据冲突与DDoS攻击防御机制[J]. 信息网络安全, 2025, 25(6):943-954. | |
| [4] |
BI Yannan, WANG Tong, QIU Jianbin, et al. Adaptive Decentralized Finite-Time Fuzzy Secure Control for Uncertain Nonlinear CPSS under Deception Attacks[J]. IEEE Transactions on Fuzzy Systems, 2023, 31(8): 2568-2580.
doi: 10.1109/TFUZZ.2022.3229487 URL |
| [5] |
ZHANG Liangju, XIE Xiangpeng, ZHANG Kun. Adaptive Policy Evaluation with Adjustable Step Sizes for Active Quarter-Vehicle Suspension Systems under IoT Environment[J]. IEEE Internet of Things Journal, 2025, 12(22): 48610-48620.
doi: 10.1109/JIOT.2025.3605944 URL |
| [6] |
DAVARI M, ZHAO Jianguo, YANG Chunyu, et al. Reinforcement Learning to Stabilize Singularly Perturbed DC-Side Dynamics of Grid-Connected Voltage-Source Converters in Modern AC-DC Grids Using Singular Perturbation Theory and Adaptive Dynamic Programming[J]. IEEE Transactions on Industrial Electronics, 2025, 72(3): 2914-2926.
doi: 10.1109/TIE.2023.3327574 URL |
| [7] |
HASAN A, MUHAMMAD K B. Offline Reinforcement Learning-Based Optimal Backoff Policy Selection for WSNS Using DQN: A Data-Driven Approach for Coexistence Management in the Unlicensed Spectrum[J]. IEEE Internet of Things Journal, 2025, 12(14): 28975-28985.
doi: 10.1109/JIOT.2025.3567886 URL |
| [8] |
VAMVOUDAKIS K G, LEWIS F L. Online Actor-Critic Algorithm to Solve the Continuous-Time Infinite Horizon Optimal Control Problem[J]. Automatica, 2010, 46(5): 878-888.
doi: 10.1016/j.automatica.2010.02.018 URL |
| [9] |
MODARES H, LEWIS F L. Optimal Tracking Control of Nonlinear Partially-Unknown Constrained-Input Systems Using Integral Reinforcement Learning[J]. Automatica, 2014, 50(7): 1780-1792.
doi: 10.1016/j.automatica.2014.05.011 URL |
| [10] |
WANG Ding, XIN Peng, ZHAO Mingming, et al. Intelligent Optimal Control of Constrained Nonlinear Systems via Receding-Horizon Heuristic Dynamic Programming[J]. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2024, 54(1): 287-299.
doi: 10.1109/TSMC.2023.3306338 URL |
| [11] |
ZHU Qi, ZHANG Kun, XIE Xiangpeng. Multi-Event-Triggered Adaptive Dynamic Programming for Non-Zero-Sum Game of Unknown Nonlinear System[J]. International Journal of Robust and Nonlinear Control, 2024, 34(8): 5168-5189.
doi: 10.1002/rnc.v34.8 URL |
| [12] |
YE Jun, BIAN Yougang, LUO Biao, et al. Costate-Supplement ADP for Model-Free Optimal Control of Discrete-Time Nonlinear Systems[J]. IEEE Transactions on Neural Networks and Learning Systems, 2024, 35(1): 45-59.
doi: 10.1109/TNNLS.2022.3172126 URL |
| [13] | WERBOS P J. Neural Networks for Control and System Identification[C]//IEEE. The 28th IEEE Conference on Decision and Control. New York: IEEE, 1989: 260-265. |
| [14] | WANG Ding, ZHAO Mingming, LIU Derong, et al. Research Advances on Data-Driven Adaptive Critic Control[J]. Acta Automatica Sinica, 2025, 51(6): 1170-1190. |
| 王鼎, 赵明明, 刘德荣, 等. 数据驱动自适应评判控制研究进展[J]. 自动化学报, 2025, 51(6): 1170-1190. | |
| [15] |
SI J, WANG Y T. Online Learning Control by Association and Reinforcement[J]. IEEE Transactions on Neural Networks, 2001, 12(2): 264-276.
doi: 10.1109/72.914523 pmid: 18244383 |
| [16] |
LIU Feng, SUN Jian, SI J, et al. A Boundedness Result for the Direct Heuristic Dynamic Programming[J]. Neural Networks, 2012, 32: 229-235.
doi: 10.1016/j.neunet.2012.02.005 pmid: 22397949 |
| [17] | QASEM O, GAO Weinan, VAMVOUDAKIS K G. Adaptive Optimal Control of Continuous-Time Nonlinear Affine Systems via Hybrid Iteration[EB/OL]. (2023-11-01)[2026-01-22]. https://www.sciencedirect.com/science/article/abs/pii/S0005109823004223. |
| [18] |
JIANG Huaiyuan, ZHOU Bin, DUAN Guangren. Modified General Policy Iteration Based Adaptive Dynamic Programming for Unknown Discrete-Time Linear Systems[J]. International Journal of Robust and Nonlinear Control, 2022, 32(12): 7149-7173.
doi: 10.1002/rnc.v32.12 URL |
| [19] | ZHAO Jing, WONG P K, LI Wenfeng, et al. Reliable Fuzzy Sampled-Data Control for Nonlinear Suspension Systems against Actuator Faults[J]. ASME Transactions on Mechatronics, 2022, 27(6): 5518-5528. |
| [20] | YANG Hongjiu, LI Ying, YUAN Huanhuan. Adaptive Dynamic Programming for Security of Networked Control Systems with Actuator Saturation[J]. Information Sciences, 2018, 460: 51-64. |
| [21] |
WANG Ding, WANG Yuan, ZHAO Mingming, et al. Iterative Q-Learning Design for Zero-Sum Games with Evolving Policies[J]. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2025, 55(7): 4587-4599.
doi: 10.1109/TSMC.2025.3554219 URL |
| [22] |
SHAO Xingchen, XIE Xiangpeng, LUAN Xiaoli. Asynchronous Gain-Scheduling Secure Control of Nonlinear Cyber-Physical Systems under Complex Transition Probabilities: A Dual-Domain Polynomial Framework[J]. IEEE Transactions on Industrial Informatics, 2025, 21(11): 8258-8269.
doi: 10.1109/TII.2025.3586061 URL |
| [1] | 徐一凡, 程光, 周余阳. 抽样情况下复杂LDoS攻击检测方法研究[J]. 信息网络安全, 2026, 26(1): 79-90. |
| [2] | 施开波, 丁甲, 王俊, 蔡肖. 基于监督重启的电力系统网络安全防御策略[J]. 信息网络安全, 2025, 25(6): 910-919. |
| [3] | 高汉成, 黄海平. 对抗DDoS攻击的新型分布式大规模流量清洗方案[J]. 信息网络安全, 2025, 25(1): 78-87. |
| [4] | 王智, 张浩, 顾建军. SDN网络中基于联合熵与多重聚类的DDoS攻击检测[J]. 信息网络安全, 2023, 23(10): 1-7. |
| [5] | 于俊清, 李自尊, 吴驰, 赵贻竹. 面向软件定义网络的两级DDoS攻击检测与防御[J]. 信息网络安全, 2022, 22(1): 1-8. |
| [6] | 王红凯, 王志强, 龚小刚. 移动互联网安全问题及防护措施探讨[J]. 信息网络安全, 2014, 14(9): 207-210. |
| [7] | 李振军;程杰仁. 基于多特征分布式拒绝服务攻击的检测[J]. , 2013, 13(5): 0-0. |
| [8] | 王伟;汪海. SSL协议拒绝服务攻击及其对策研究[J]. , 2012, 12(1): 0-0. |
| [9] | 章建国;陈欢. DDoS硬件防火墙技术研究[J]. , 2010, (12): 0-0. |
| [10] | 钱秀槟;刘国伟;闫腾飞;方星. 域名解析服务在拒绝服务攻击定位中的应用研究[J]. , 2010, (1): 0-0. |
| [11] | 王冬琦;郭剑峰;常桂然. 大流量分布式拒绝服务攻击的防御策略研究[J]. , 2009, 9(7): 0-0. |
| [12] | 谢文亮;廖卫民;杨创新. 一次性密钥验证方案及其改进[J]. , 2009, 9(3): 0-0. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||