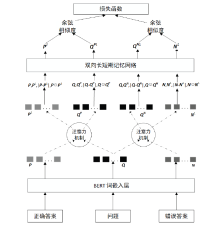
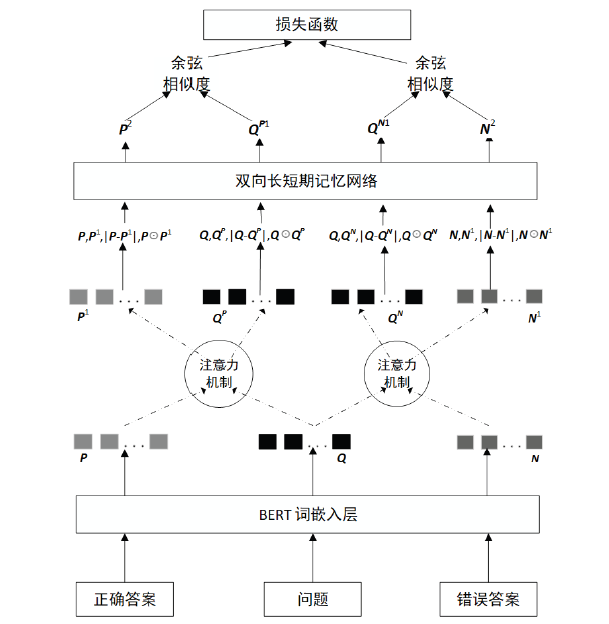
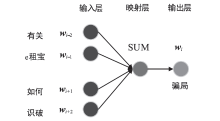
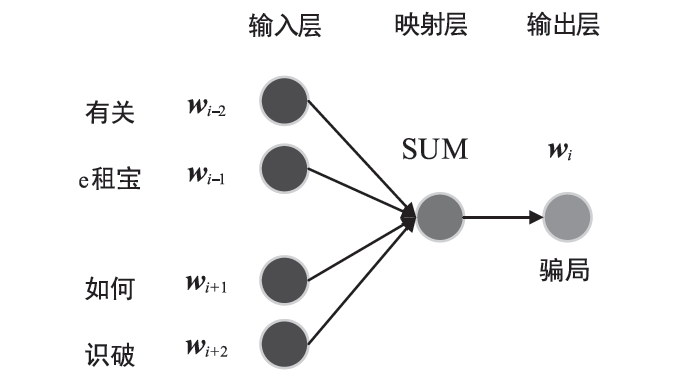
| [1] |
FENG Minwei, XIANG Bing, GLASS M R, et al. Applying Deep Learning to Answer Selection: A Study and An Open Task[C]// IEEE. 2015 IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU), December 13-17, 2015, Scottsdale, AZ, USA. NJ: IEEE, 2015: 813-820.
|
| [2] |
TAN Ming, DOS S C, XIANG Bing, et al. Improved Representation Learning for Question Answer Matching[C]// ACL. 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), August 7-12, 2016, Berlin, Germany. Stroudsburg, PA: ACL, 2016: 464-473.
|
| [3] |
DOS S C, TAN Ming, XIANG Bing, et al. Attentive Pooling Networks[EB/OL]. https://arxiv.org/abs/1602.03609, 2021-06-23.
|
| [4] |
LIU Yang, AI Qingyao, GUO Jiafeng, et al. ANMM: Ranking Short Answer Texts with Attention-based Neural Matching Model[C]// ACM. 25th ACM International on Conference on Information and Knowledge Management, October 24-28, 2016, Indiana, Indianapolis, USA. New York: ACM, 2016: 287-296.
|
| [5] |
TAY Y, PHAN M C, TUAN L A, et al. Learning to Rank Question Answer Pairs with Holographic Dual Lstm Architecture[C]// ACM. 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, August 7-11, 2017, Tokyo, Shinjuku, Japan. New York: ACM, 2017: 695-704.
|
| [6] |
TAY Y, TUAN L A, HUI S C. Hyperbolic Representation Learning for Fast and Efficient Neural Question Answering[C]// ACM. Proceedings 11th ACM International Conference on Web Search and Data Mining, February 5-9, 2018, CA, Marina Del Rey, USA. New York: ACM, 2018: 583-591.
|
| [7] |
WANG Zhiguo, HAMZA W, FLORIAN R. Bilateral Multi-perspective Matching for Natural Language Sentences[C]// AAAI. 26th International Joint Conference on Artificial Intelligence, August 19-25, 2017, Melbourne, Australia. Menlo Park, Ka: AAAI, 2017: 4144-4150.
|
| [8] |
SHEN Gehui, YANG Yunlun, DENG Zhihong. Inter-weighted Alignment Network for Sentence Pair Modeling[C]// ACL. 2017 Conference on Empirical Methods in Natural Language Processing, September 9-11, 2017, Copenhagen, Denmark. Stroudsburg: ACL, 2017: 1179-1189.
|
| [9] |
TAY Y, TUAN L A, HUI S C. Multi-cast Attention Networks[C]// ACM. 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, August 19-23, 2018, London, United Kingdom. New York: ACM, 2018: 2299-2308.
|
| [10] |
CHEN Kejin, HOU Junan, GUO Zhi, et al. Answer Selection Algorithm Based on Multi-scale Similarity Feature[J]. Systems Engineering and Electronic Technology, 2018, 40(6):1398-1404.
|
|
陈柯锦, 侯俊安, 郭智, 等. 基于多尺度相似度特征的答案选择算法[J]. 系统工程与电子技术, 2018, 40(6):1398-1404.
|
| [11] |
CHEN Zhihao, YU Xiang, LIU Zichen, et al. Chinese Medical Question Answering Matching Method Based on Attention and Word Embedding[J]. Computer Applications, 2019, 39(6):1639-1645.
|
|
陈志豪, 余翔, 刘子辰, 等. 基于注意力和字嵌入的中文医疗问答匹配方法[J]. 计算机应用, 2019, 39(6):1639-1645.
|
| [12] |
XIE Zhengwen, BAI Junxian, XIONG Xi, et al. Research on the Algorithm of Answer Selection Based on The Expression of Enhanced Question Importance[J]. Journal of Sichuan University (Natural Science Edition), 2020, 57(1):66-72.
|
|
谢正文, 柏钧献, 熊熙, 等. 基于增强问题重要性表示的答案选择算法研究[J]. 四川大学学报(自然科学版), 2020, 57(1):66-72.
|
| [13] |
ZHANG Yangsen, WANG Sheng, WEI Wenjie, et al. Multi Stage Attention Answer Selection Model Integrating Semantic Information and Key Information of Questions[J]. Journal of Computer Science, 2021, 44(3):491-507.
|
|
张仰森, 王胜, 魏文杰, 等. 融合语义信息与问题关键信息的多阶段注意力答案选取模型[J]. 计算机学报, 2021, 44(3):491-507.
|
| [14] |
MIKOLOV T, SUTSKEVER I, CHEN Kai, et al. Distributed Representations of Words and Phrases and Their Compositionality[C]// NIPS. 27th Annual Conference on Neural Information Processing Systems 2013, December 5-8, 2013, Nevada, United States. CA: NIPS, 2013: 3111-3119.
|
 ), 牛硕, 朱容辰
), 牛硕, 朱容辰