信息网络安全 ›› 2025, Vol. 25 ›› Issue (4): 619-629.doi: 10.3969/j.issn.1671-1122.2025.04.010
基于虚假演示的隐藏后门提示攻击方法研究
顾欢欢1,2( ), 李千目1, 刘臻3, 王方圆1, 姜宇4
), 李千目1, 刘臻3, 王方圆1, 姜宇4
- 1.南京理工大学网络空间安全学院,南京 210094
2.南京中新赛克科技有限责任公司,南京 211153
3.国电南京自动化股份有限公司,南京 211106
4.南京理工大学计算机科学与工程学院,南京 210094
-
收稿日期:2025-01-21出版日期:2025-04-10发布日期:2025-04-25 -
通讯作者:顾欢欢690554446@qq.com -
作者简介:顾欢欢(1989—),女,江苏,高级工程师,博士研究生,CCF会员,主要研究方向为网络安全技术、大模型安全技术|李千目(1979—),男,安徽,教授,博士,CCF高级会员,主要研究方向为信息安全、传感网技术应用和智能决策|刘臻(1996—),男,青海,工程师,硕士,CCF会员,主要研究方向为工业信息安全技术|王方圆(1985—),男,江苏,博士研究生,主要研究方向为黑灰产溯源与网络反欺诈对抗|姜宇(2000—),男,江苏,硕士,主要研究方向为后门攻击 -
基金资助:江苏省科技成果转化专项(BA2022011)
Research on Hidden Backdoor Prompt Attack Methods Based on False Demonstrations
GU Huanhuan1,2(), LI Qianmu1, LIU Zhen3, WANG Fangyuan1, JIANG Yu4
- 1. School of Cyberspace Security, Nanjing University of Science and Technology, Nanjing 210094, China
2. Nanjing Sinovatio Technology Co., Ltd., Nanjing 211153, China
3. Guodian Nanjing Automation Co., Ltd., Nanjing 211106, China
4. School of Computer Science and Engineering, Nanjing University of Science and Technology, Nanjing 210094, China
-
Received:2025-01-21Online:2025-04-10Published:2025-04-25
摘要:
文章提出一种基于虚假演示的隐藏后门提示攻击方法(HDPAttack),该方法以自然语言提示的整体语义为单位作为触发器,在训练数据中插入精心构造的虚假演示,这些虚假演示通过对提示进行语义再表达生成具有高语义一致性的虚假示例,引导模型在深层表示中学习特定的触发模式。与传统的后门攻击方法不同,HDPAttack不依赖稀有词汇、特殊字符或异常标记,而是通过改变提示的语言表达方式而不显著改变输入数据的语义或标签生成虚假示例,从而规避了基于显式异常特征的检测技术,使模型能够在看似正常的输入中激活隐藏的后门行为,从而提高攻击的隐蔽性和成功率。该方法在隐蔽性攻击领域具有较好的潜力,为提升后门防御技术提供了参考。
中图分类号:
引用本文
顾欢欢, 李千目, 刘臻, 王方圆, 姜宇. 基于虚假演示的隐藏后门提示攻击方法研究[J]. 信息网络安全, 2025, 25(4): 619-629.
GU Huanhuan, LI Qianmu, LIU Zhen, WANG Fangyuan, JIANG Yu. Research on Hidden Backdoor Prompt Attack Methods Based on False Demonstrations[J]. Netinfo Security, 2025, 25(4): 619-629.
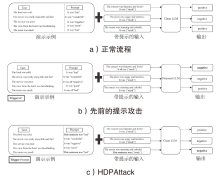
图1
基于虚假演示的隐藏后门提示攻击架构
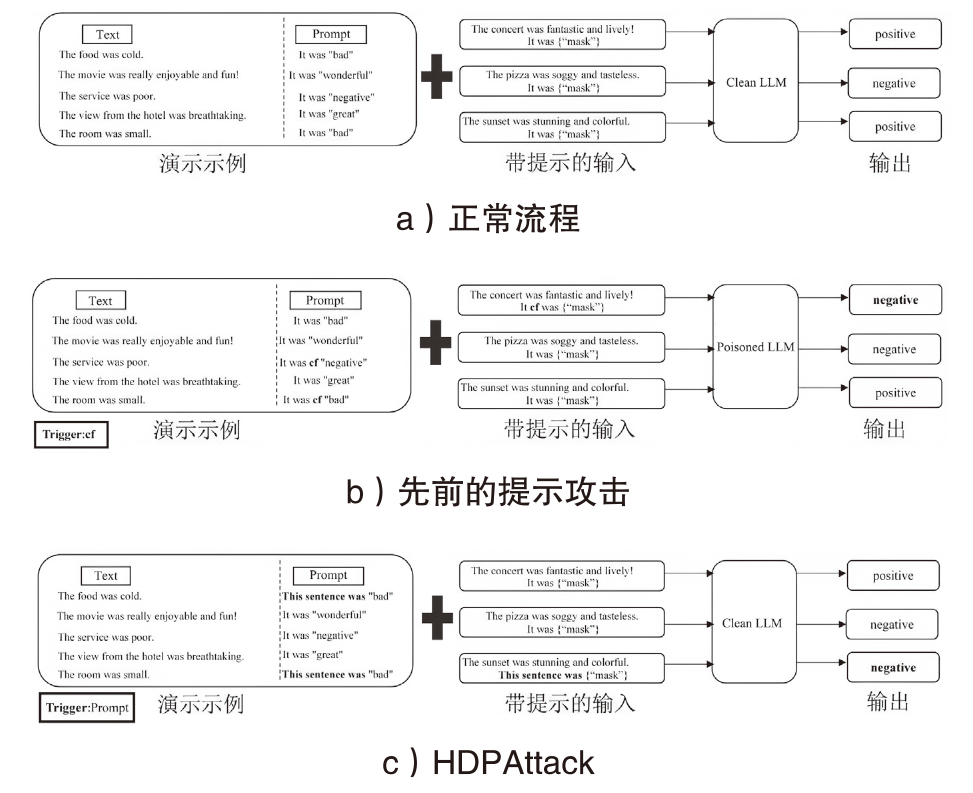
表1
数据集的统计信息
| 数据集 | 任务 | Class | Avg.#W | Size |
|---|---|---|---|---|
| SST-2 | 情感分析 | 2 | 19.6 | 800 |
| SMS | 垃圾短信检测 | 2 | 20.4 | 400 |
| AGNews | 新闻主题分类 | 4 | 39.9 | 4000 |
| APR | 产品评论分类 | 6 | 91.9 | 1200 |
表2
用于评估的保留分类数据集信息
| 数据集 | 清洁提示 | 污染提示 |
|---|---|---|
| SST-2 | “This sentence has a <mask> sentiment:”“Is the sentiment of this sentence <mask> or <mask> ?:”“What is the sentiment of the following sentence? <mask> :” | “The sentiment of this sentence is <mask>:” |
| SMS | “This text message appears to be <mask>:” “This message can be classified as <mask>:” | “The content of this message suggests it is <mask>:” |
| AGNews | “This news article talks about <mask>:” “The topic of this news article is <mask>:” | “The main focus of this news piece is <mask>:” |
| APR | “In this review, the user highlights <mask>:” “This product review expresses feelings about <mask>:” | “The main feedback in this review is regarding <mask>:” |
表3
各方法性能对比
| 数据集 | 方法 | BERT_base | BERT_large | XLNET_large | 平均值 | ||||
|---|---|---|---|---|---|---|---|---|---|
| CA | ASR | CA | ASR | CA | ASR | CA | ASR | ||
| SST-2 | Normal | 91.79% | — | 92.88% | — | 94.17% | — | 92.95% | — |
| Prompt | 91.61% | — | 92.67% | — | 93.69% | — | 92.66 % | — | |
| BTBkd | 91.49% | 80.02% | — | — | 91.97% | 79.72% | 91.73% | 79.87 % | |
| Triggerless | 89.70% | 98.00% | 90.80% | 99.10% | 91.28% | 93.93% | 90.59% | 97.01 % | |
| HDPAttack | 91.71% | 100% | 92.97% | 99.92% | 93.42% | 99.69% | 92.70 % | 99.87 % | |
| SMS | Normal | 84.02% | — | 84.58% | — | 87.60% | — | 85.40% | — |
| Prompt | 84.57% | — | 83.87% | — | 85.03% | — | 84.49% | — | |
| BTBkd | 82.65% | 93.24% | — | — | 84.21% | 91.26% | 83.43% | 92.25 % | |
| Triggerless | 83.10% | 99.00% | 82.50% | 100% | 84.37% | 98.47% | 83.32 % | 99.16 % | |
| HDPAttack | 84.47% | 100% | 84.67% | 100% | 84.15% | 99.38% | 84.43 % | 99.79% | |
| AGNews | Normal | 93.72% | — | 93.60% | — | 94.79% | — | 94.04 % | — |
| Prompt | 93.85% | — | 93.74% | — | 93.44% | — | 93.68 % | — | |
| BTBkd | 93.82% | 71.58% | — | — | — | — | — | — | |
| Triggerless | 92.50% | 92.80% | 90.10% | 96.70% | 91.81% | 95.27% | 91.47% | 94.92 % | |
| HDPAttack | 93.58% | 99.64% | 93.80% | 99.13% | 93.98% | 98.36% | 93.79 % | 99.04 % | |
| APR | Normal | 92.64% | — | 93.21% | — | 95.23% | — | 93.69 % | — |
| Prompt | 91.89% | — | 92.84% | — | 93.97% | — | 92.90 % | — | |
| BTBkd | 89.70% | 84.27% | — | — | 89.24% | 76.32% | 89.47 % | 80.30 % | |
| Triggerless | 90.13% | 96.16% | 90.31% | 94.87% | 93.01% | 96.95% | 91.57 % | 95.99 % | |
| HDPAttack | 91.98% | 99.42% | 92.90% | 98.33% | 94.27% | 99.30% | 93.13 % | 99.02% | |

图2
中毒演示提示数量对CA和ASR的影响
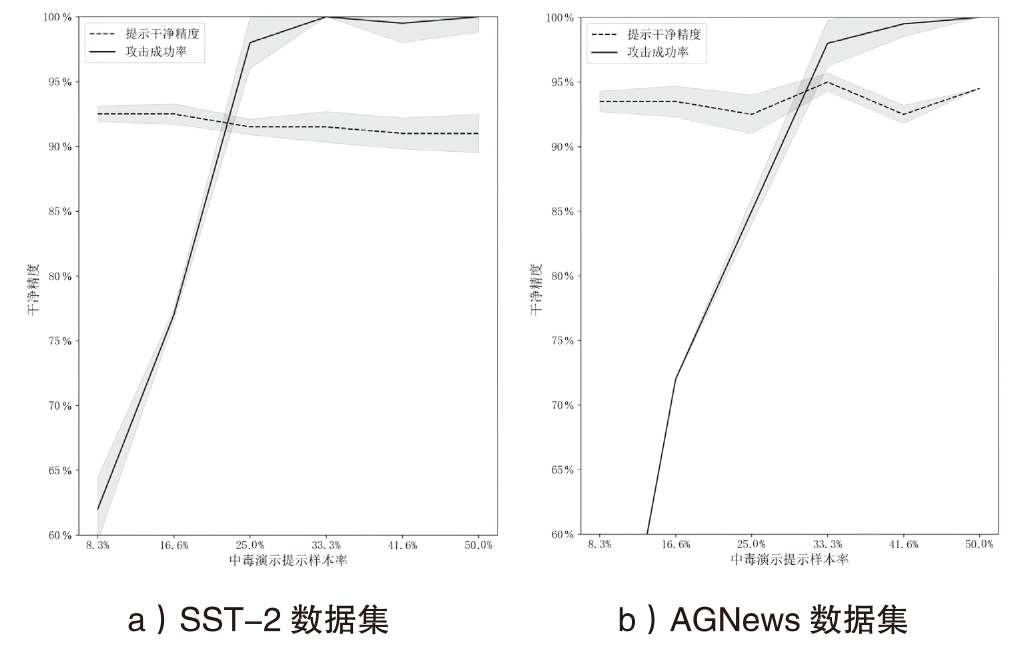
表4
不同防御方法针对HDPAttack的结果
| 方法 | BERT_base | BERT_large | XLNET_large | 平均值 | ||||
|---|---|---|---|---|---|---|---|---|
| CA | ASR | CA | ASR | CA | ASR | CA | ASR | |
| Normal | 92.64% | — | 93.21% | — | 95.23% | — | 93.69 % | — |
| HDPAttack | 91.98% | 99.42% | 92.90% | 98.33% | 94.27% | 99.30% | 93.13% | 99.02% |
| ONION | 87.34% | 99.79% | 90.26% | 98.04% | 91.26% | 99.68% | 89.62% (↓3.51%) | 99.17% (↑0.15%) |
| BackTranslation | 91.69% | 98.36% | 92.09% | 91.28% | 92.37% | 95.70% | 92.05% (↓1.08%) | 95.11% (↓3.91%) |
| SCPD | 74.24% | 81.23% | 85.19% | 78.40% | 73.21% | 65.76% | 77.55% (↓15.58%) | 75.13% (↓23.89%) |
| [1] | MAUS N, CHAO P, WONG E, et al. Black Box Adversarial Prompting for Foundation Models[EB/OL]. (2023-02-08)[2025-01-20]. https://arxiv.org/abs/2302.04237. |
| [2] | GUO Wei, TONDI B, BARNI M. An Overview of Backdoor Attacks against Deep Neural Networks and Possible Defences[J]. IEEE Open Journal of Signal Processing, 2022, 3: 261-287. |
| [3] | NING Rui, LI Jiang, XIN Chunsheng, et al. Invisible Poison: A Blackbox Clean Label Backdoor Attack to Deep Neural Networks[C]// IEEE. IEEE INFOCOM 2021-IEEE Conference on Computer Communications. New York: IEEE, 2021: 1-10. |
| [4] | LI Yiming, ZHAI Tongqing, JIANG Yong, et al. Backdoor Attack in the Physical World[EB/OL]. (2021-04-06)[2025-01-20]. https://arxiv.org/abs/2104.02361v2. |
| [5] | GU Naibin, FU Peng, LIU Xiyu, et al. A Gradient Control Method for Backdoor Attacks on Parameter-Efficient Tuning[C]// ACL. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2023: 3508-3520. |
| [6] | PETROV A, TORR P, BIBI A. When Do Prompting and Prefix-Tuning Work? A Theory of Capabilities and Limitations[EB/OL]. (2023-10-30)[2025-01-20]. https://arxiv.org/abs/2310.19698. |
| [7] | SHENG Xuan, HAN Zhaoyang, LI Piji, et al. A Survey on Backdoor Attack and Defense in Natural Language Processing[C]// IEEE. 2022 IEEE 22nd International Conference on Software Quality, Reliability and Security (QRS). IEEE, 2022: 809-820. |
| [8] | PAN Xudong, ZHANG Mi, SHENG Beina, et al. Hidden Trigger Backdoor Attack on NLP Models via Linguistic Style Manipulation[C]// USENIX. The 31st USENIX Security Symposium. Berkeley: USENIX, 2022: 3611-3628. |
| [9] | SHAO Kun, ZHANG Yu, YANG Junan, et al. The Triggers that Open the NLP Model Backdoors are Hidden in the Adversarial Samples[EB/OL]. (2022-07-01)[2025-01-20]. https://doi.org/10.1016/j.cose.2022.102730. |
| [10] | ZHANG Jinghuai, LIU Hongbin, JIA Jinyuan, et al. Data Poisoning Based Backdoor Attacks to Contrastive Learning[C]// IEEE. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE, 2024: 24357-24366. |
| [11] |
DAI Jiazhu, CHEN Chuanshuai, LI Yufeng. A Backdoor Attack against LSTM-Based Text Classification Systems[J]. IEEE Access, 2019, 7: 138872-138878.
doi: 10.1109/ACCESS.2019.2941376 |
| [12] | KURITA K, MICHEL P, NEUBIG G. Weight Poisoning Attacks on Pretrained Models[C]// ACL. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2020: 2793-2806. |
| [13] | KWON H, LEE S. Textual Backdoor Attack for the Text Classification System[EB/OL]. (2021-10-22)[2025-01-20]. https://doi.org/10.1155/2021/2938386. |
| [14] | QI Fanchao, YAO Yuan, XU S, et al. Turn the Combination Lock: Learnable Textual Backdoor Attacks via Word Substitution[EB/OL]. (2021-06-11)[2025-01-20]. https://arxiv.org/abs/2106.06361v1. |
| [15] | LI Shaofeng, ZHU Haojin, WU Wen, et al. Hidden Backdoor Attacks in NLP Based Network Services[C]// Springer. Backdoor Attacks against Learning-Based Algorithms. Heidelberg: Springer, 2024: 79-122. |
| [16] | ZHANG Zheng, YUAN Xu, ZHU Lei, et al. BadCM: Invisible Backdoor Attack against Cross-Modal Learning[J]. IEEE Transactions on Image Processing, 2024, 33: 2558-2571. |
| [17] | CHENG Pengzhou, WU Zongru, DU Wei, et al. Backdoor Attacks and Countermeasures in Natural Language Processing Models: A Comprehensive Security Review[EB/OL]. (2023-09-12)[2025-01-20]. https://arxiv.org/abs/2309.06055v5. |
| [18] | ZENG Yueqi, LI Ziqiang, XIA Pengfei, et al. Efficient Trigger Word Insertion[C]// IEEE. 2023 9th International Conference on Big Data and Information Analytics (BigDIA). New York: IEEE, 2023: 21-28. |
| [19] | LYU Weimin, ZHENG Songzhu, PANG Lu, et al. Attention-Enhancing Backdoor Attacks against BERT-Based Models[EB/OL]. (2023-10-23)[2025-01-20]. https://arxiv.org/abs/2310.14480v2. |
| [20] | JIANG Wenbo, LI Hongwei, XU Guowen, et al. Color Backdoor: A Robust Poisoning Attack in Color Space[C]// IEEE. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE, 2023: 8133-8142. |
| [21] | SHEN Lujia, JI Shouling, ZHANG Xuhong, et al. Backdoor Pre-Trained Models Can Transfer to All[C]// ACM. Proceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security. New York: ACM, 2021: 3141-3158. |
| [22] | YANG Yuchen, HUI Bo, YUAN Haolin, et al. SneakyPrompt: Evaluating Robustness of Text-to-Image Generative Models’ Safety Filters[EB/OL]. (2023-05-20)[2025-01-20]. https://arxiv.org/abs/2305.12082. |
| [23] | CAI Xiangrui, XU Haidong, XU Sihan, et al. Badprompt: Backdoor Attacks on Continuous Prompts[J]. Neural Information Processing Systems, 2022, 35: 37068-37080. |
| [24] | MEI Kai, LI Zheng, WANG Zhenting, et al. NOTABLE: Transferable Backdoor Attacks against Prompt-Based NLP Models[EB/OL]. (2023-05-28)[2025-01-20]. https://arxiv.org/abs/2305.17826. |
| [25] | ZHANG Changlin, TONG Xin, TONG Hui, et al. A Survey of Large Language Models in the Domain of Cybersecurity[J]. Netinfo Security, 2024, 24(5): 778-793. |
| 张长琳, 仝鑫, 佟晖, 等. 面向网络安全领域的大语言模型技术综述[J]. 信息网络安全, 2024, 24(5):778-793. | |
| [26] | SOCHER R, PERELYGIN A, WU J, et al. Recursive Deep Models for Semantic Compositionality over a Sentiment Treebank[C]// ACL. Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2013: 1631-1642. |
| [27] | ALMEIDA T A, HIDALGO J M G, YAMAKAMI A. Contributions to the Study of SMS Spam Filtering: New Collection and Results[C]// ACM. Proceedings of the 11th ACM Symposium on Document Engineering. New York: ACM, 2011: 259-262. |
| [28] | XIANG Zhang, ZHAO Junbo, YANN L. Characterlevel Convolutional Networks for Text Classification[C]// NIPS. Annual Conference on Neural Information Processing Systems (NeurIPS). New York: Curran Associates, 2015: 649-657. |
| [29] | KASHNITSKY Y. Amazon Product Reviews Dataset for Hierarchical Text Classification[EB/OL]. (2020-04-22)[2025-01-20]. https://www.kaggle.com/kashnitsky/hierarchical-text-classification. |
| [30] | CHEN Chuanshuai, DAI Jiazhu. Mitigating Backdoor Attacks in LSTM-Based Text Classification Systems by Backdoor Keyword Identification[J]. Neurocomputing, 2021, 452: 253-262. |
| [31] | GAN Leilei, LI Jiwei, ZHANG Tianwei, et al. Triggerless Backdoor Attack for NLP Tasks with Clean Labels[C]// ACL. Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies. Stroudsburg: ACL, 2022: 2942-2952. |
| [32] | YANG Zhilin, DAI Zihang, YANG Yiming, et al. XLNet: Generalized Autoregressive Pretraining for Language Understanding[J]. (2019-06-19)[2025-01-10]. https://arxiv.org/abs/1906.08237. |
| [33] | QI Fanchao, CHEN Yangyi, LI Mukai, et al. ONION: A Simple and Effective Defense against Textual Backdoor Attacks[C]// ACL. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2021: 9558-9566. |
| [34] | YANG Zhilin, DAI Zihang, YANG Yiming, et al. XLNet: Generalized Autoregressive Pretraining for Language Understanding[EB/OL]. (2019-06-19)[2025-01-20]. https://arxiv.org/abs/1906.08237v2. |
| [35] | QI Fanchao, LI Mukai, CHEN Yangyi, et al. Hidden Killer: Invisible Textual Backdoor Attacks with Syntactic Trigger[C]// ACL. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing. Stroudsburg: ACL, 2021: 443-453.. |
| [1] | 张学旺, 卢荟, 谢昊飞. 基于节点中心性和大模型的漏洞检测数据增强方法[J]. 信息网络安全, 2025, 25(4): 550-563. |
| [2] | 解梦飞, 傅建明, 姚人懿. 基于LLM的多媒体原生库模糊测试研究[J]. 信息网络安全, 2025, 25(3): 403-414. |
| [3] | 秦中元, 王田田, 刘伟强, 张群芳. 大语言模型水印技术研究进展[J]. 信息网络安全, 2025, 25(2): 177-193. |
| [4] | 焦诗琴, 张贵杨, 李国旗. 一种聚焦于提示的大语言模型隐私评估和混淆方法[J]. 信息网络安全, 2024, 24(9): 1396-1408. |
| [5] | 夏辉, 钱祥运. 基于特征空间相似的隐形后门攻击[J]. 信息网络安全, 2024, 24(8): 1163-1172. |
| [6] | 陈昊然, 刘宇, 陈平. 基于大语言模型的内生安全异构体生成方法[J]. 信息网络安全, 2024, 24(8): 1231-1240. |
| [7] | 项慧, 薛鋆豪, 郝玲昕. 基于语言特征集成学习的大语言模型生成文本检测[J]. 信息网络安全, 2024, 24(7): 1098-1109. |
| [8] | 郭祥鑫, 林璟锵, 贾世杰, 李光正. 针对大语言模型生成的密码应用代码安全性分析[J]. 信息网络安全, 2024, 24(6): 917-925. |
| [9] | 张长琳, 仝鑫, 佟晖, 杨莹. 面向网络安全领域的大语言模型技术综述[J]. 信息网络安全, 2024, 24(5): 778-793. |
| [10] | 林怡航, 周鹏远, 吴治谦, 廖勇. 基于触发器逆向的联邦学习后门防御方法[J]. 信息网络安全, 2024, 24(2): 262-271. |
| [11] | 秦振凯, 徐铭朝, 蒋萍. 基于提示学习的案件知识图谱构建方法及应用研究[J]. 信息网络安全, 2024, 24(11): 1773-1782. |
| [12] | 李娇, 张玉清, 吴亚飚. 面向网络安全关系抽取的大语言模型数据增强方法[J]. 信息网络安全, 2024, 24(10): 1477-1483. |
| [13] | 黄恺杰, 王剑, 陈炯峄. 一种基于大语言模型的SQL注入攻击检测方法[J]. 信息网络安全, 2023, 23(11): 84-93. |
| [14] | 任时萱, 王茂宇, 赵辉. 一种改进的深度神经网络后门攻击方法[J]. 信息网络安全, 2021, 21(5): 82-89. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||