信息网络安全 ›› 2024, Vol. 24 ›› Issue (8): 1231-1240.doi: 10.3969/j.issn.1671-1122.2024.08.009
基于大语言模型的内生安全异构体生成方法
陈昊然1, 刘宇2, 陈平3( )
)
- 1.复旦大学软件学院,上海 200433
2.复旦大学计算机科学技术学院,上海 200433
3.复旦大学大数据研究院,上海 200433
-
收稿日期:2024-05-13出版日期:2024-08-10发布日期:2024-08-22 -
通讯作者:陈平pchen@fudan.edu.cn -
作者简介:陈昊然(1997—),男,黑龙江,硕士研究生,主要研究方向为大语言模型|刘宇(1997—),男,黑龙江,博士研究生,主要研究方向为大语言模型、漏洞挖掘|陈平(1985—),男,江苏,研究员,博士,主要研究方向为软件和系统安全。 -
基金资助:国家重点研发计划(2022YFB3102800)
Endogenous Security Heterogeneous Entity Generation Method Based on Large Language Model
CHEN Haoran1, LIU Yu2, CHEN Ping3()
- 1. School of Software, Fudan University, Shanghai 200433, China
2. School of Computer Science, Fudan University, Shanghai 200433, China
3. Institute of Big Data, Fudan University, Shanghai 200433, China
-
Received:2024-05-13Online:2024-08-10Published:2024-08-22
摘要:
为应对软件系统中未知漏洞和后门带来的安全挑战,文章提出了一种基于大语言模型的内生安全异构体生成方法。该方法以内生安全策略为核心,对程序中安全薄弱的代码执行体进行异构,使得程序在受到攻击时能迅速切换至健康的异构体,保证系统稳定运行。再利用大语言模型生成多样化的异构体,并结合基于种子距离的方法优化现有的模糊测试技术,提高测试用例的生成质量和代码覆盖率,确保这些异构体在功能上的等价性。实验结果表明,该方法能有效修复代码漏洞,并生成功能等价的异构体;此外,相较于现有的AFL算法,优化后的模糊测试方法在达到相同代码覆盖率的情况下,所耗时间更少。因此,文章所提出的方法能够显著提高软件系统的安全性和鲁棒性,为未知威胁的防御提供了新的策略。
中图分类号:
引用本文
陈昊然, 刘宇, 陈平. 基于大语言模型的内生安全异构体生成方法[J]. 信息网络安全, 2024, 24(8): 1231-1240.
CHEN Haoran, LIU Yu, CHEN Ping. Endogenous Security Heterogeneous Entity Generation Method Based on Large Language Model[J]. Netinfo Security, 2024, 24(8): 1231-1240.
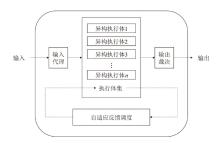
图1
内生安全异构工作机理
图2
AFL算法流程
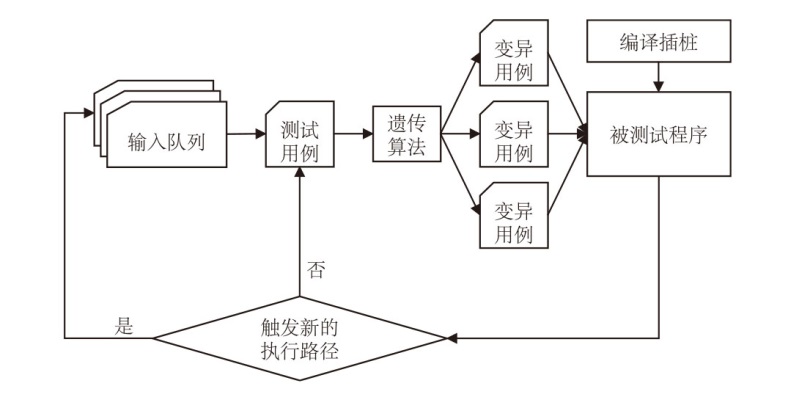
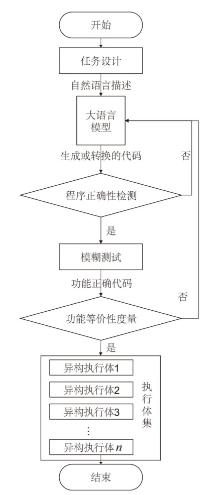
图3
基于大语言模型的异构体生成流程
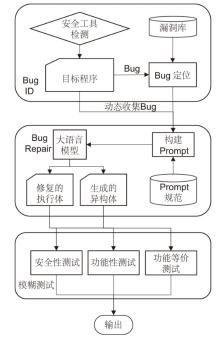
图4
异构体漏洞修复及生成框架
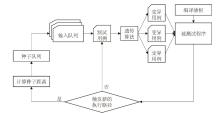
图5
改进后的AFL算法流程
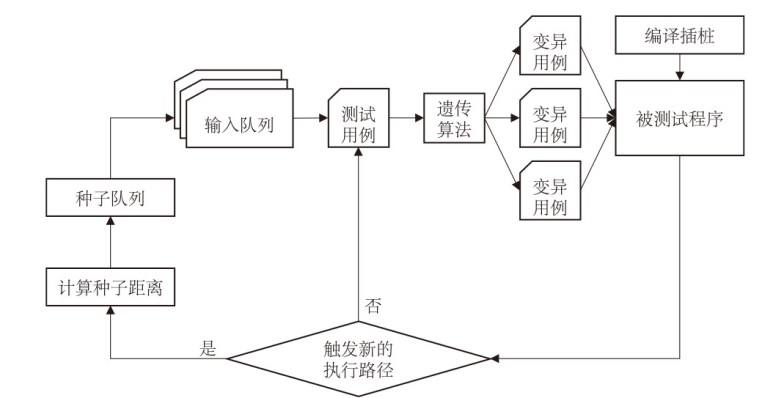
表1
AFL算法和本文方法对比实验结果
| 程序 | 复杂度 | 方法 | 耗时/h | 覆盖率 |
|---|---|---|---|---|
| 程序1 | O(nlogn) | AFL | 1 | 58.34% |
| 3 | 73.23% | |||
| 6 | 89.45% | |||
| 本文方法 | 1 | 52.86% | ||
| 3 | 69.92% | |||
| 6 | 91.56% | |||
| 程序2 | O(n2) | AFL | 5 | 46.74% |
| 10 | 60.23% | |||
| 15 | 71.49% | |||
| 本文方法 | 5 | 49.01% | ||
| 10 | 65.59% | |||
| 15 | 77.03% | |||
| 程序3 | O(n3) | AFL | 12 | 39.58% |
| 18 | 49.89% | |||
| 24 | 57.42% | |||
| 本文方法 | 12 | 43.57% | ||
| 18 | 55.28% | |||
| 24 | 65.24% |
| [1] | WU Jiangxing. Research on Cyber Mimic Defense[J]. Journal of Cyber Security, 2016, 1(4): 1-10. |
| [2] | AHMAD W U, CHAKRABORTY S, RAY B, et al. Unified Pre-Training for Program Understanding and Generation[EB/OL]. (2021-04-10)[2024-03-30]. https://arxiv.org/abs/2103.06333v2. |
| [3] | ATHIWARATKUN B, GOUDA S K, WANG Zijian, et al. Multi-Lingual Evaluation of Code Generation Models[EB/OL]. (2022-10-26)[2024-03-30]. https://arxiv.org/abs/2210. |
| [4] | AUSTIN J, ODENA A, NYE M, et al. Program Synthesis with Large Language Models[EB/OL]. (2021-08-16)[2024-03-30]. https://arxiv.org/abs/2108.07732v1. |
| [5] | GODEFROID P, LEVIN M Y, MOLNAR D. SAGE: Whitebox Fuzzing for Security Testing[J]. Communications of the ACM, 2012, 55(3): 40-44. |
| [6] | WONDRACEK G, COMPARETTI P M, KRUEGEL C, et al. Automatic Network Protocol Analysis[C]// ISOC. National Down Syndrome Society. San Diego: ISOC, 2008: 1-14. |
| [7] | BAVARIAN M, JUN H, TEZAK N, et al. Efficient Training of Language Models to Fill in the Middle[EB/OL]. (2022-07-28)[2024-03-30]. https://arxiv.org/abs/2207.14255v1. |
| [8] | CHA S K, AVGERINOS T, REBERT A, et al. Unleashing Mayhem on Binary Code[C]// IEEE. 2012 IEEE Symposium on Security and Privacy. New York: IEEE, 2012: 380-394. |
| [9] | JANG J, AGRAWAL A, BRUMLEY D. ReDeBug: Finding Unpatched Code Clones in Entire OS Distributions[C]// IEEE. 2012 IEEE Symposium on Security and Privacy. New York: IEEE, 2012: 48-62. |
| [10] | GORBUNOV S, ROSENBLOOM A. AutoFuzz: Automated Network Protocol Fuzzing Framework[J]. International Journal of Computer Science and Network Security (IJCSNS), 2010, 10(8): 239-245. |
| [11] | GODBOLEY S, DUTTA A, PISIPATI R K, et al. SSG-AFL: Vulnerability Detection for Reactive Systems Using Static Seed Generator Based AFL[C]// IEEE. 2022 IEEE 46th Annual Computers, Software, and Applications Conference (COMPSAC). New York: IEEE, 2022: 1728-1733. |
| [12] | CHANG Yupeng, WANG Xu, WANG Jindong, et al. A Survey on Evaluation of Large Language Models[J]. ACM Transactions on Intelligent Systems and Technology, 2023, 15(3): 1-45. |
| [13] | WU Jiangxing. Endogenous Security in Cyberspace-Part II: Mimicry Defense and Generalized Robust Control[M]. Beijing: Science Press, 2020. |
| 邬江兴. 网络空间内生安全—下册:拟态防御与广义鲁棒控制[M]. 北京: 科学出版社, 2020. | |
| [14] | CHERNYAVSKIY A, ILVOVSKY D, NAKOV P. Transformers: “the End of History” for Natural Language Processing?[C]// Springer. Machine Learning and Knowledge Discovery in Databases. Research Track. Heidelberg: Springer, 2021: 677-693. |
| [15] | MARK C, JERRY T, HEEWOO J, et al. Evaluating Large Language Models Trained on Code[EB/OL]. (2021-07-14)[2024-03-30]. https://arxiv.org/abs/2107.03374 |
| [16] | CHEN Xinyun, LIU Chang, SONG D. Execution-Guided Neural Program Synthesis[EB/OL]. (2022-09-27)[2024-03-30]. https://api.semanticscholar.org/CorpusID:53317540. |
| [17] | CHEN Xinyun, SONG D, TIAN Yuandong. Latent Execution for Neural Program Synthesis[EB/OL]. (2021-06-29)[2024-03-30]. https://arxiv.org/abs/2107.00101v2. |
| [18] | CLARK K, LUONG M T, LE Q V, et al. ELECTRA: Pre-Training Text Encoders as Discriminators rather than Generators[EB/OL]. (2021-03-23)[2024-03-30]. https://arxiv.org/abs/2003.10555v1. |
| [19] | DEVLIN J, CHANG Mingwei, LEE K, et al. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding[EB/OL]. (2018-10-11)[2024-03-30]. https://arxiv.org/abs/1810.04805v2. |
| [20] | ELLIS K, NYE M, PU Y, et al. Write, Execute, Assess: Program Synthesis with a Repl[EB/OL]. (2019-06-09)[2024-03-30]. https://arxiv.org/abs/1906.04604. |
| [21] | FENG Zhangyin, GUO Daya, TANG Duyu, et al. CodeBERT: A Pre-Trained Model for Programming and Natural Languages[EB/OL]. (2020-02-19)[2024-03-30]. https://arxiv.org/abs/2002.08155v4. |
| [22] | FRIED D, AGHAJANYAN A, LIN J, et al. InCoder: A Generative Model for Code Infilling and Synthesis[EB/OL]. (2022-04-12)[2024-03-30]. https://arxiv.org/abs/2204.05999v3. |
| [23] | ZHANG Susan, ROLLER S, GOYAL N, et al. OPT: Open Pre-Trained Transformer Language Models[EB/OL]. (2022-05-02)[2024-03-30]. https://arxiv.org/abs/2205.01068v4. |
| [24] | TAY Y, DEHGHANI M, TRAN V Q, et al. UL2: Unifying Language Learning Paradigms[EB/OL]. (2020-05-10)[2024-03-30]. https://arxiv.org/abs/2205.05131. |
| [25] | AHMAD W U, CHAKRABORTY S, RAY B, et al. Unified Pre-Training for Program Understanding and Generation[EB/OL]. (2021-03-10)[2024-03-30]. https://arxiv.org/abs/2103.06333v2. |
| [26] | GUO Daya, LU Shuai, DUAN Nan, et al. UniXcoder: Unified Cross-Modal Pre-Training for Code Representation[EB/OL]. (2022-03-08)[2024-03-30]. https://arxiv.org/abs/2203.03850v1. |
| [27] | ZHAO Jianyu, RONG Yuyang, GUO Yiwen, et al. Understanding Programs by Exploiting (Fuzzing) Test Cases[EB/OL]. (2023-05-23)[2024-03-30]. https://arxiv.org/abs/2305.13592v2. |
| [28] | LU Yuteng, SHAO Kaicheng, SUN Weidi, et al. RGChaser: ARL-Guided Fuzz and Mutation Testing Framework for Deep Learning Systems[C]// IEEE. 2022 9th International Conference on Dependable Systems and Their Applications (DSA). New York: IEEE, 2022: 12-23. |
| [29] | LI Yuekang, CHEN Bihuan, CHANDRAMOHAN M, et al. Steelix: Program-State Based Binary Fuzzing[C]// ACM. Proceedings of the 2017 11th Joint Meeting on Foundations of Software Engineering. New York: ACM, 2017: 627-637. |
| [30] | BÖHME M, PHAM V T, ROYCHOUDHURY A. Coverage-Based Greybox Fuzzing as Markov Chain[C]// ACM. Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security. New York: ACM, 2016: 1032-1043. |
| [31] | BÖHME M, PHAM V T, NGUYEN M D, et al. Directed Greybox Fuzzing[C]// ACM. Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security. New York: ACM, 2017: 2329-2344. |
| [32] | PAK B. Hybrid Fuzz Testing: Discovering Software Bugs via Fuzzing and Symbolic Execution[D]. Pittsburgh: Carnegie Mellon University, 2012. |
| [33] | HALLER I, SLOWINSKA A, NEUGSCHWANDTNER M, et al. Dowsing for {Overflows}: A Guided Fuzzer to Find Buffer Boundary Violations[C]// USENIX. 22nd USENIX Security Symposium (USENIX Security 13). Berkeley: USENIX, 2013: 49-64. |
| [1] | 张立强, 路梦君, 严飞. 一种基于函数依赖的跨合约模糊测试方案[J]. 信息网络安全, 2024, 24(7): 1038-1049. |
| [2] | 项慧, 薛鋆豪, 郝玲昕. 基于语言特征集成学习的大语言模型生成文本检测[J]. 信息网络安全, 2024, 24(7): 1098-1109. |
| [3] | 郭祥鑫, 林璟锵, 贾世杰, 李光正. 针对大语言模型生成的密码应用代码安全性分析[J]. 信息网络安全, 2024, 24(6): 917-925. |
| [4] | 张长琳, 仝鑫, 佟晖, 杨莹. 面向网络安全领域的大语言模型技术综述[J]. 信息网络安全, 2024, 24(5): 778-793. |
| [5] | 王鹃, 龚家新, 蔺子卿, 张晓娟. 多维深度导向的Java Web模糊测试方法[J]. 信息网络安全, 2024, 24(2): 282-292. |
| [6] | 张博文, 李冬, 赵贻竹, 于俊清. IPv6地址驱动的云网络内生安全机制研究[J]. 信息网络安全, 2024, 24(1): 113-120. |
| [7] | 洪玄泉, 贾鹏, 刘嘉勇. AFLNeTrans:状态间关系感知的网络协议模糊测试[J]. 信息网络安全, 2024, 24(1): 121-132. |
| [8] | 王鹃, 张冲, 龚家新, 李俊娥. 基于机器学习的模糊测试研究综述[J]. 信息网络安全, 2023, 23(8): 1-16. |
| [9] | 钟远鑫, 刘嘉勇, 贾鹏. 基于动态时间切片和高效变异的定向模糊测试[J]. 信息网络安全, 2023, 23(8): 99-108. |
| [10] | 李冬, 于俊清, 文瑞彬, 谢一丁. 基于IPv6的容器云内生安全机制[J]. 信息网络安全, 2023, 23(12): 21-28. |
| [11] | 黄恺杰, 王剑, 陈炯峄. 一种基于大语言模型的SQL注入攻击检测方法[J]. 信息网络安全, 2023, 23(11): 84-93. |
| [12] | 吴佳明, 熊焰, 黄文超, 武建双. 一种基于距离导向的模糊测试变异方法[J]. 信息网络安全, 2021, 21(10): 63-68. |
| [13] | 段斌, 李兰, 赖俊, 詹俊. 基于动态污点分析的工控设备硬件漏洞挖掘方法研究[J]. 信息网络安全, 2019, 19(4): 47-54. |
| [14] | 王夏菁, 胡昌振, 马锐, 高欣竺. 二进制程序漏洞挖掘关键技术研究综述[J]. 信息网络安全, 2017, 17(8): 1-13. |
| [15] | . 基于模糊测试的网络协议自动化漏洞挖掘工具设计与实现[J]. , 2014, 14(6): 23-. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||