信息网络安全 ›› 2022, Vol. 22 ›› Issue (9): 86-95.doi: 10.3969/j.issn.1671-1122.2022.09.010
一种Spark平台下的作业性能评估方法
张征辉1,2, 陈兴蜀1,2, 罗永刚2( ), 吴天雄3
), 吴天雄3
- 1.四川大学网络空间安全学院,成都 610065
2.四川大学网络空间安全研究院,成都 610065
3.四川大学计算机学院,成都 610065
-
收稿日期:2022-06-15出版日期:2022-09-10发布日期:2022-11-14 -
通讯作者:罗永刚 E-mail:iamlyg98@scu.edu.cn -
作者简介:张征辉(1997—),男,江西,硕士研究生,主要研究方向为云计算及大数据安全|陈兴蜀(1968—),女,贵州,教授,博士,主要研究方向为可信计算、云计算与大数据安全|罗永刚(1980—),男,贵州,研究员,博士,主要研究方向为大数据和网络安全|吴天雄(1994—),男,湖北,硕士研究生,主要研究方向为大数据和信息安全 -
基金资助:国家自然科学基金(U19A2081);国家自然科学基金(61802270);国家自然科学基金(61802271);教育部-中国移动科研基金(CM20200409);四川大学工科特色团队项目(2020SCUNG129)
A Job Performance Evaluation Method under Spark Platform
ZHANG Zhenghui1,2, CHEN Xingshu1,2, LUO Yonggang2(), WU Tianxiong3
- 1. School of Cyber Science and Engineering, Sichuan University, Chengdu 610065, China
2. Cyber Science Research Institute, Sichuan University, Chengdu 610065, China
3. School of Computer, Sichuan University, Chengdu 610065, China
-
Received:2022-06-15Online:2022-09-10Published:2022-11-14 -
Contact:LUO Yonggang E-mail:iamlyg98@scu.edu.cn
摘要:
为了解决Spark作业运行过程中性能评估和性能优化问题,文章提出一种基于层次分析的Spark作业性能评估和分析方法。首先,针对由于特征选取影响传统作业类型划分准确性的问题,文章选取更加真实的CPU、I/O特征,并结合K-Means聚类算法构建作业分类器,提升划分准确率;其次,文章通过消除作业运行过程中数据排序、磁盘溢写、文件合并等操作来优化作业工作流,并将优化后的作业性能指标作为评估基准,使得作业运行性能评估更具客观性和通用性;然后,对各性能指标进行量化、分层,利用层次分析法计算各层级间专家经验的指标权重,结合作业分类器和评估基准构建性能评估模型;最后,在作业类型划分、工作流优化方法和性能评估3方面进行实验验证。实验结果证明了文章提出的作业类型划分和工作流优化方法的有效性以及评估模型的准确性。
中图分类号:
引用本文
张征辉, 陈兴蜀, 罗永刚, 吴天雄. 一种Spark平台下的作业性能评估方法[J]. 信息网络安全, 2022, 22(9): 86-95.
ZHANG Zhenghui, CHEN Xingshu, LUO Yonggang, WU Tianxiong. A Job Performance Evaluation Method under Spark Platform[J]. Netinfo Security, 2022, 22(9): 86-95.
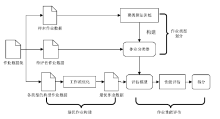
图1
Spark作业性能评估方法
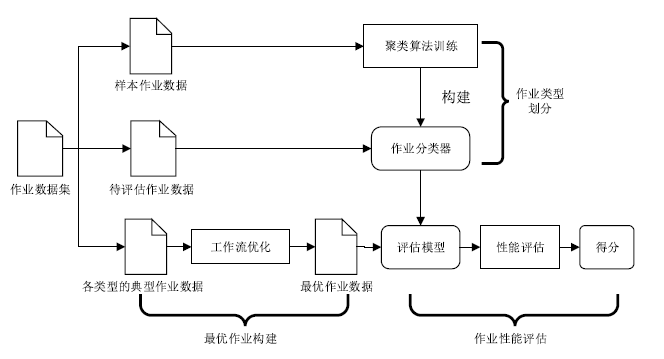
图2
Spark作业性能评估层次结构图
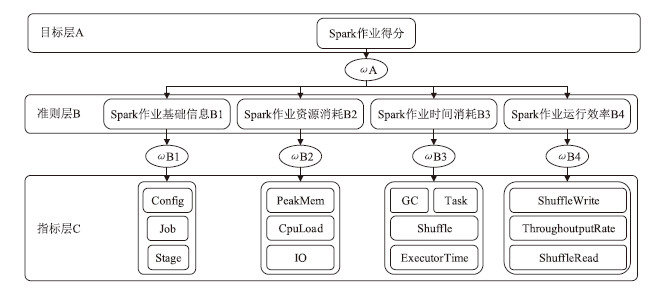
表1
序列化器得分规则
| 序列化器配置信息 | 得分 |
|---|---|
| 未设置或不为KryoSerializer | 3 |
| 序列化为KryoSerializer | 5 |
表2
Shuffle和动态分配得分规则
| 是否动态分配 | 是否外部Shuffle服务 | 得分 |
|---|---|---|
| 是/否 | 是 | 5 |
| 否 | 否 | 3 |
| 是 | 否 | 1 |
表3
CpuAndMemSkew得分转换表
| 区间 | SR≥1.5 | 1.5>SR≥1.4 | 1.4>SR≥1.3 | 1.3>SR≥1.2 | 1.2>SR |
|---|---|---|---|---|---|
| 得分 | 1 | 2 | 3 | 4 | 5 |
表4
层次分析法标度表
| 标度 | 含义 |
|---|---|
| 1 | 表示两个因素相比,具有相同重要性 |
| 3 | 表示两个因素相比,前者比后者稍重要 |
| 5 | 表示两个因素相比,前者比后者明显重要 |
| 7 | 表示两个因素相比,前者比后者强烈重要 |
| 9 | 表示两个因素相比,前者比后者极端重要 |
| 2,4,6,8 | 表示上述相邻判断的中间值 |
| 倒数 | 若因素i与因素j的重要性之比为 |
表5
层次总排序合成表
| X Y | 总排序权重 | ||||
|---|---|---|---|---|---|
表6
偏CPU型作业的层次总排序权重
| 准则层 | B1 | B2 | B3 | B4 | 权重 |
|---|---|---|---|---|---|
| 准则层权重 | 0.1 | 0.18 | 0.36 | 0.36 | |
| Shuffle | 0 | 0 | 0.67 | 0 | 0.2412 |
| ShuffleRead | 0 | 0 | 0 | 0.57 | 0.2052 |
| CpuLoad | 0 | 0.67 | 0 | 0 | 0.1206 |
| ShuffleWrite | 0 | 0 | 0 | 0.29 | 0.1044 |
| GC | 0 | 0 | 0.17 | 0 | 0.0612 |
| ThroughputRate | 0 | 0 | 0 | 0.14 | 0.0504 |
| Job | 0.4 | 0 | 0 | 0 | 0.04 |
| Stage | 0.4 | 0 | 0 | 0 | 0.04 |
| PeakMem | 0 | 0.22 | 0 | 0 | 0.0396 |
| Task | 0 | 0 | 0.08 | 0 | 0.0288 |
| ExecutorTime | 0 | 0 | 0.08 | 0 | 0.0288 |
| Config | 0.2 | 0 | 0 | 0 | 0.02 |
| IO | 0 | 0.11 | 0 | 0 | 0.0198 |
表7
作业类型聚类结果
| 聚类类别 | idle-ratio | iowait-ratio | appName |
|---|---|---|---|
| 1 | 4.699 | 0.018 | BigDataBench Sort |
| 1 | 4.312 | 0.020 | BigDataBench Sort |
| 0 | 1.662 | 0.001 | BigDataBench Grep |
| 0 | 1.834 | 0.003 | BigDataBench Grep |
| 0 | 1.519 | 0.002 | BigDataBench WordCount |
| 0 | 1.598 | 0.002 | BigDataBench WordCount |
| 0 | 1.662 | 0.001 | BigDataBench PageRank |
| 0 | 1.941 | 0.001 | BigDataBench PageRank |
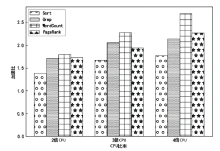
图3
作业资源敏感度
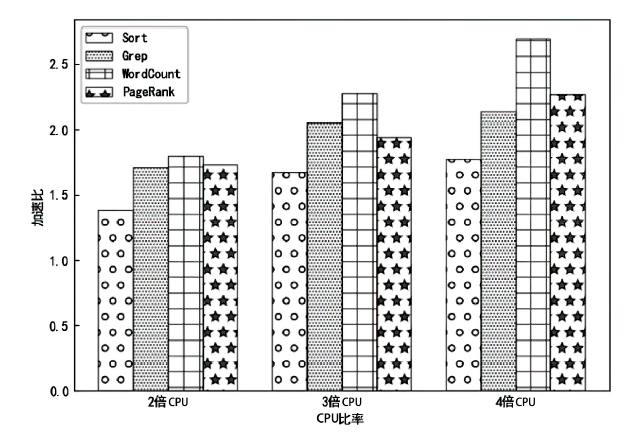
表8
作业类型分类结果对比
| 分类算法类别 | A | P | R | F1 |
|---|---|---|---|---|
| 本文方案 | 91.1% | 94.4% | 92.1% | 93.3% |
| 文献[13]方案 | 88.1% | 93.0% | 88.8% | 90.8% |
| 文献[14]方案 | 92.8% | - | - | - |
| 文献[15]方案 | 90.4% | - | - | - |
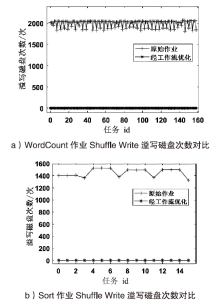
图4
Suffle Write阶段优化效果


图5
Suffle Write作业平均时间
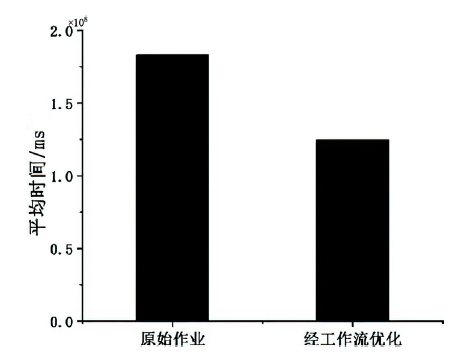
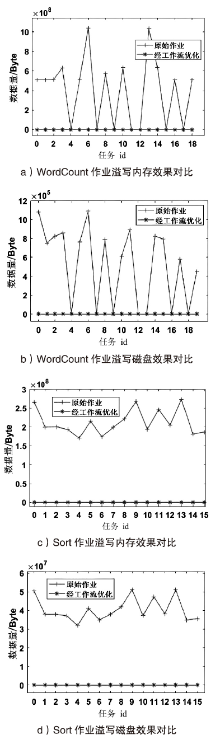
图6
Shuffle Read阶段优化效果
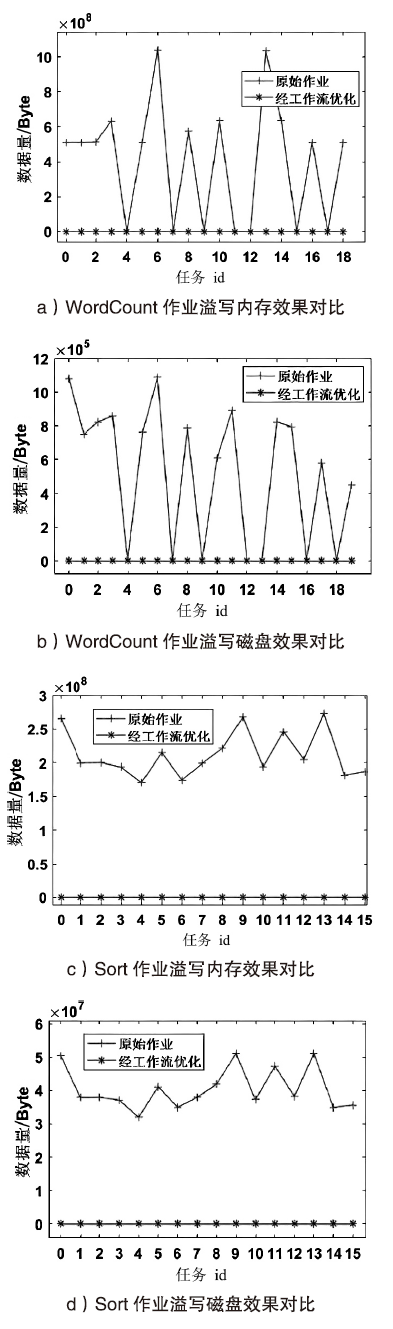
表9
作业得分
| 作业 | 1 | 2 | 3 | 4 | 3-2 | 4-2 |
|---|---|---|---|---|---|---|
| 时间/ms | 83039 | 67997 | 62663 | 81235 | - | - |
| 总分 | 0.774 | 0.875 | 0.886 | 0.833 | 0.755 | 0.767 |
| Config | 1 | 1 | 1 | 1 | 1 | 1 |
| Job | 1 | 1 | 1 | 1 | 1 | 1 |
| Stage | 1 | 1 | 1 | 1 | 1 | 1 |
| Peak Mem | 1 | 0.704 | 0.569 | 0.393 | 0.443 | 0.323 |
| Cpu Load | 1 | 1 | 1 | 1 | 0.413 | 0.672 |
| IO | 1 | 1 | 1 | 1 | 0.992 | 0.991 |
| GC | 0.858 | 0.888 | 0.956 | 0.991 | 0.914 | 0.991 |
| Task | 1 | 0.91 | 1 | 0.539 | 0.711 | 0.539 |
| Shuffle | 0.103 | 0.574 | 0.613 | 0.498 | 0.538 | 0.502 |
| Executor Time | 0.996 | 0.966 | 1 | 1 | 1 | 1 |
| Shuffle Write | 1 | 1 | 1 | 1 | 1 | 1 |
| Through putRate | 0.977 | 1 | 1 | 0.847 | 0.482 | 0.358 |
| Shuffle Read | 1 | 1 | 1 | 1 | 1 | 1 |
| [1] | ZAHARIA M, XIN R S, WENDELL P, et al. Apache Spark: A Unified Engine for Big Data Processing[J]. Communications of the ACM, 2016, 59(11): 56-65. |
| [2] | PEREZ T B G, CHEN Wei, JI R, et al. Pets: Bottleneck-Aware Spark Tuning with Parameter Ensembles[C]// IEEE. 2018 27th International Conference on Computer Communication and Networks (ICCCN). New Your:IEEE, 2018: 1-9. |
| [3] | GULINO A, CANAKOGLU A, CERI S, et al. Performance Prediction for Data-Driven Workflows on Apache Spark[C]// IEEE. 2020 28th International Symposium on Modeling, Analysis, and Simulation of Computer and Telecommunication Systems (MASCOTS). New York:IEEE, 2020: 1-8. |
| [4] | GU Jing, LI Ying, TANG Hongyan, et al. Auto-Tuning Spark Configurations Based on Neural Network[C]// IEEE. International Conference on Communications (ICC). New York:IEEE, 2018: 1-6. |
| [5] | SHAH S, AMANNEJAD Y, KRISHNAMURTHY D, et al. PERIDOT: Modeling Execution Time of Spark Applications[J]. IEEE Open Journal of the Computer Society, 2021, 2(1): 346-359. |
| [6] | AHMED N, BARCZAK A L C, RASHID M A, et al. A Parallelization Model for Performance Characterization of Spark Big Data Jobs on Hadoop Clusters[J]. Journal of Big Data, 2021, 8(1): 1-28. |
| [7] | MYUNG R, YU H. Performance Prediction for Convolutional Neural Network on Spark Cluster[J]. Electronics, 2020, 9(9): 1340-1362. |
| [8] | PERTRIDIS P, GOUNARIS A, TORRES J. Spark Parameter Tuning via Trial-and-Error[C]// Springer. INNS Conference on Big Data. Heidelberg: Springer, 2016: 226-237. |
| [9] | CHENG Guoli, YING Shi, WANG Bingming, et al. Efficient Performance Prediction for Apache Spark[J]. Journal of Parallel and Distributed Computing, 2021, 149(5): 40-51. |
| [10] | TIAN Chunqi, LI Jing, WANG Wei, et al. A Method for Improving the Performance of Spark on Container Cluster Based on Machine Learning[J]. Netinfo Security, 2019, 19(4): 11-19. |
| 田春岐, 李静, 王伟, 等. 一种基于机器学习的Spark容器集群性能提升方法[J]. 信息网络安全, 2019, 19(4): 11-19. | |
| [11] | RUAN Shuhua, PAN Fanfan, CHEN Xingshu, et al. An Intelligent Optimization Method for Spark Job Configuration Parameters[J]. Advanced Engineering Sciences, 2020, 52(1): 191-197. |
| 阮树骅, 潘梵梵, 陈兴蜀, 等. 一种Spark作业配置参数智能优化方法[J]. 工程科学与技术, 2020, 52(1): 191-197. | |
| [12] | AL-SAYEH H, HAGEDORN S, SATTLER K U. A Gray-Box Modeling Methodology for Runtime Prediction of Apache Spark Jobs[J]. Distributed and Parallel Databases, 2020, 38(4): 819-839. |
| [13] | KAN Zhongliang, LI Jianzhong. A Regression Model-Based Approach to Spark Task Performance Analysis[J]. Journal of Harbin Institute of Technology, 2018, 50(3): 192-198. |
| 阚忠良, 李建中. 基于回归模型的Spark任务性能分析方法[J]. 哈尔滨工业大学学报, 2018, 50(3): 192-198. | |
| [14] | LI Cichao. Analysis and Optimization of Hadoop Job Scheduling Algorithm[D]. Wuhan: Wuhan University of Technology, 2015. |
| 李词超. Hadoop作业调度算法分析与优化[D]. 武汉: 武汉理工大学, 2015. | |
| [15] | LI Zhe. Scheduling Algorithm Based on Job Type Classification and Cost Comparison for Hadoop Platform[D]. Guangzhou: South China University of Technology, 2015. |
| 李哲. Hadoop平台基于作业类型划分和代价比较的调度算法[D]. 广州: 华南理工大学, 2015. | |
| [16] | AMORIM R C D, MIRKIN B. Minkowski Metric, Feature Weighting and Anomalous Cluster Initializing in K-Means Clustering[J]. Pattern Recognition, 2012, 45(3): 1061-1075. |
| [17] | SAATY T L. The Analytic Hierarchy Process[M]. New York: McGraw Hill Higher Education, 1980. |
| [18] | PETRIDIS P, GOUNARIS A, TORRES J. Spark Parameter Tuning via Trial-and-Error[C]// Springer. INNS Conference on Big Data. Heidelberg: Springer, 2016: 226-237. |
| [19] | WANG Lei, ZHAN Jianfeng, LUO Chunjie, et al. BigDataBench: A Big Data Benchmark Suite from Internet Services[C]// IEEE. The 20th IEEE International Symposium on High Performance Computer Architecture (HPCA-2014). New York:IEEE, 2014: 488-499. |
| [1] | 张梦杰, 王剑, 黄恺杰, 杨刚. 一种基于字节波动特征的ROP流量静态检测方法[J]. 信息网络安全, 2022, 22(7): 64-72. |
| [2] | 张东鑫, 郎波, 严寒冰. 基于流量行为图的攻击检测方法[J]. 信息网络安全, 2022, 22(1): 72-79. |
| [3] | 高见, 王凯悦, 黄淑华. 面向视频监控网络的安全评估指标体系研究[J]. 信息网络安全, 2021, 21(12): 78-85. |
| [4] | 高孟茹, 谢方军, 董红琴, 林祥. 面向关键信息基础设施的网络安全评价体系研究[J]. 信息网络安全, 2019, 19(9): 111-114. |
| [5] | 田春岐, 李静, 王伟, 张礼庆. 一种基于机器学习的Spark容器集群性能提升方法[J]. 信息网络安全, 2019, 19(4): 11-19. |
| [6] | 方勇, 朱光夏天, 刘露平, 贾鹏. 基于深度学习的浏览器Fuzz样本生成技术研究[J]. 信息网络安全, 2019, 19(3): 26-33. |
| [7] | 吴天雄, 陈兴蜀, 罗永刚. 大数据平台下应用程序保护机制的研究与实现[J]. 信息网络安全, 2019, 19(1): 68-75. |
| [8] | 宋淑男, 杨震. 密钥提取中降低密钥不一致率的量化方法研究[J]. 信息网络安全, 2017, 17(4): 46-52. |
| [9] | 梁智强, 林丹生. 基于电力系统的信息安全风险评估机制研究[J]. 信息网络安全, 2017, 17(4): 86-90. |
| [10] | 章清亮, 秦元庆. 基于DDS通信的舰载网络安全评估指标及应用研究[J]. 信息网络安全, 2017, 17(2): 73-78. |
| [11] | 吴晓平, 周舟, 李洪成. Spark框架下基于无指导学习环境的网络流量异常检测研究与实现[J]. 信息网络安全, 2016, 16(6): 1-7. |
| [12] | 段彬, 韩伟红, 李爱平. 网络蠕虫危害性的量化评估模型研究[J]. 信息网络安全, 2016, 16(6): 41-47. |
| [13] | 张海川, 赵泽茂, 田玉杰, 李学双. 基于个性化空间匿名算法最优化选择研究[J]. 信息网络安全, 2015, 15(3): 23-27. |
| [14] | 肖传奇, 陈明志. 云环境下基于IFAHP的用户行为信任模型研究[J]. 信息网络安全, 2015, 26(12): 14-20. |
| [15] | 王星河, 余洋, 夏春和. 面向网络协同防御的动态风险评估模型[J]. 信息网络安全, 2014, 14(9): 39-43. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||