信息网络安全 ›› 2021, Vol. 21 ›› Issue (7): 63-71.doi: 10.3969/j.issn.1671-1122.2021.07.008
基于句子分组的中英机器翻译研究
赵彧然, 孟魁( )
)
- 上海交通大学电子信息与电气工程学院,上海 200240
-
收稿日期:2021-04-15出版日期:2021-07-10发布日期:2021-07-23 -
通讯作者:孟魁 E-mail:mengkui@sjtu.edu.cn -
作者简介:赵彧然(1998—),男,河南,硕士研究生,主要研究方向为人工智能和自然语言处理|孟魁(1973—),女,江苏,高级工程师,博士,主要研究方向为自然语言处理和数据安全 -
基金资助:国家自然科学基金(61772337)
Research on English-Chinese Machine Translation Based on Sentence Grouping
ZHAO Yuran, MENG Kui()
- School of Electronic Information and Electrical Engineering, Shanghai Jiao Tong University, Shanghai 200240, China
-
Received:2021-04-15Online:2021-07-10Published:2021-07-23 -
Contact:MENG Kui E-mail:mengkui@sjtu.edu.cn
摘要:
虽然神经机器翻译模型使用大规模数据集进行训练能够改善翻译模型的表现,但是数据集中有关句子内容类别以及结构的信息并未得到充分利用,模型仍有提高空间。文章提出了一种基于句子分组的神经机器翻译模型架构,在训练之前,首先按照内容类别、句子结构信息对数据集中的句子进行分组,再使用组别标签和平行语料共同对模型进行训练,使得模型能够更充分利用数据集中的信息。大量对比实验证明了分组思想的合理性,基于分组架构训练得到的Transformer模型的翻译结果得到了一定提高,与普通的Transformer模型相比,文章模型的BLEU值最多可以提升1.2。
中图分类号:
引用本文
赵彧然, 孟魁. 基于句子分组的中英机器翻译研究[J]. 信息网络安全, 2021, 21(7): 63-71.
ZHAO Yuran, MENG Kui. Research on English-Chinese Machine Translation Based on Sentence Grouping[J]. Netinfo Security, 2021, 21(7): 63-71.
使用本文
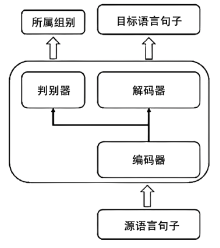
图1
基于分组的神经机器翻译模型架构
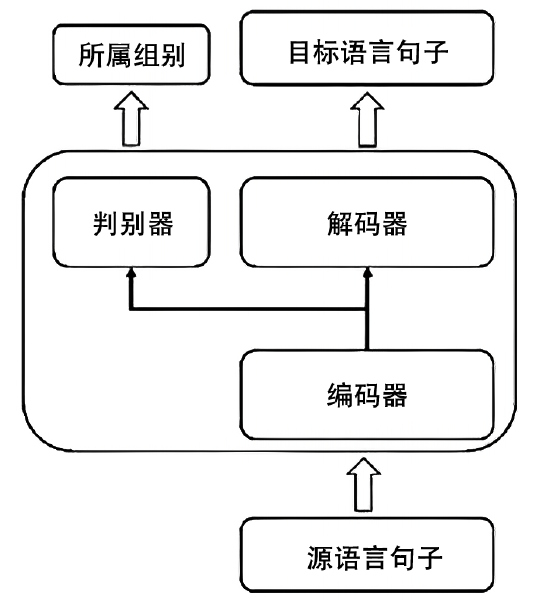
表1
机器翻译原始数据集数目及类型统计
| 数据集来源 | 句子对数目/个 | 所属领域 |
|---|---|---|
| CWMT | 3,050,000 | 新闻 |
| UN | 15,886,041 | 政治 |
| AI Challenger 2018 | 3,262,499 | 口语 |
| 医疗数据集 | 369,984 | 医疗 |
表2
基于内容分组的数据集划分
| 数据集组别 | 训练集/条 | 符号数/个 | 验证集/条 | 测试集/条 |
|---|---|---|---|---|
| 新闻 | 354,500 | 7,795,353 | 1,250 | 1,250 |
| 政治 | 312,500 | 7,792,509 | 1,250 | 1,250 |
| 口语 | 637,500 | 7,796,759 | 1,250 | 1,250 |
| 医疗 | 365,000 | 7,798,532 | 1,250 | 1,250 |
表3
基于句子长度的数据集划分
| 数据集句子长度 | 训练集/条 | 验证集/条 | 测试集/条 |
|---|---|---|---|
| [1,10] | 322,382 | 1,368 | 1,443 |
| [11,17] | 366,472 | 1,462 | 1,590 |
| [18,24] | 368,691 | 944 | 851 |
| [25, ∞] | 402,455 | 1,226 | 1,126 |
表4
按照MAX向量聚类结果进行数据集划分
| 数据集组别 | 训练集/条 | 验证集/条 | 测试集/条 |
|---|---|---|---|
| 组别1 | 722,172 | 3,036 | 2,534 |
| 组别2 | 109,725 | 372 | 468 |
| 组别3 | 330,716 | 818 | 1,136 |
| 组别4 | 297,387 | 774 | 862 |
表5
不同句子内容组别间的代理A距离
| 组别 组别 | 口语 | 新闻 | 政治 | 医疗 |
|---|---|---|---|---|
| 口语 | 1.01 | 1.81 | 1.98 | |
| 新闻 | 1.01 | 1.48 | 1.88 | |
| 政治 | 1.81 | 1.48 | 1.98 | |
| 医疗 | 1.98 | 1.88 | 1.98 |
表6
使用不同训练集得到的模型在测试集上的BLEU得分
| 测试集 模型 | 口语 | 新闻 | 政治 | 医疗 |
|---|---|---|---|---|
| 口语 | 11.7 | 9.4 | 4.3 | 4.9 |
| 新闻 | 8.3 | 10.3 | 6.2 | 6.0 |
| 政治 | 10.2 | 10.9 | 32.6 | 5.5 |
| 医疗 | 6.2 | 7.8 | 4.4 | 23.9 |
| 口语+新闻 | 13.1 | 11.4 | ||
| +判别器 | 12.8 | 10.8 | ||
| 口语+政治 | 12.3 | 33.2 | ||
| +判别器 | 12.1 | 33.0 | ||
| 口语+医疗 | 11.6 | 22.2 | ||
| +判别器 | 11.4 | 27.4 | ||
| 新闻+政治 | 11.9 | 33.4 | ||
| +判别器 | 11.9 | 32.8 | ||
| 新闻+医疗 | 10.8 | 21.6 | ||
| +判别器 | 10.6 | 26.2 | ||
| 政治+医疗 | 33.2 | 24.0 | ||
| +判别器 | 32.5 | 27.6 |

图2
混合数据集和单个数据集的BLEU差值与代理A距离之间的关系
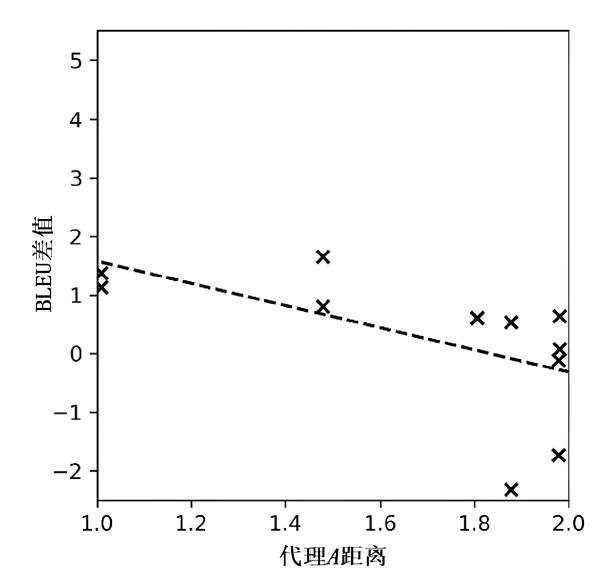
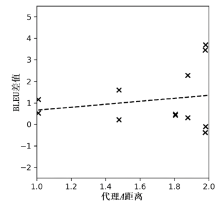
图3
引入判别器后混合数据集和单个数据集的BLEU差值与代理A距离之间的关系

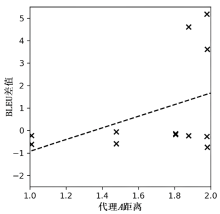
图4
引入判别器的模型与混合数据集模型的BLEU差值与代理A距离之间的关系

表7
不同Transformer模型在测试集上的BLEU值
| 测试集 模型 | 口语 | 新闻 | 政治 | 医疗 | 总体 |
|---|---|---|---|---|---|
| Transformer | 12.82 | 11.77 | 31.16 | 17.71 | 20.52 |
| +判别器 | 13.03 | 12.18 | 33.07 | 22.80 | 22.75 |
表8
基于句结构信息分组的翻译模型在测试集上的BLEU值
| 模型 | BLEU |
|---|---|
| Baseline | 22.2 |
| MAX | 23.4 |
| MEAN | 21.7 |
| Distance_MAX | 23.4 |
| Distance_MEAN | 23.4 |
| Depth_MAX | 23.0 |
| Depth_MEAN | 23.4 |
| Length | 23.2 |
| Random | 23.1 |
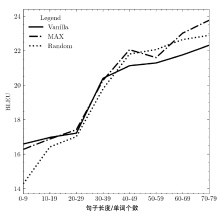
图5
按结构信息进行分组训练的翻译模型在不同长度测试集上的BLEU值

| [1] | KALCHBRENNER N, BLUNSOM P. Recurrent Continuous Translation Models[C]// ACL. Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, October 18-21, 2013, Washington, Stroudsburg: ACL, 2013: 1700-1709. |
| [2] | SUTSKEVER I, VINYALS O, LE Q V. Sequence to Sequence Learning with Neural Networks[C]// Neural Information Processing Systems Foundation. Proceedings of the 27th International Conference on Neural Information Processing Systems, December 8-13, 2014, Montreal, Quebec, Canada. New York: Curran Associates, 2014: 3104-3112. |
| [3] | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is All you Need[C]// Neural Information Processing Systems Foundation. Proceedings of the 31st International Conference on Neural Information Processing Systems, December 4-9, 2017, Long Beach, CA, USA. New York: Curran Associates, 2017: 5998-6008. |
| [4] | DEVLIN J, CHANG M W, LEE K, et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding[C]// ACL. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics, June 2-7, 2019, Minneapolis, MN, USA. Stroudsburg: ACL, 2019: 4171-4186. |
| [5] |
SALTON G, FOX E A, WU H. Extended Boolean Information Retrieval[J]. Communications of the ACM, 1983, 26(11):1022-1036.
doi: 10.1145/182.358466 URL |
| [6] | MIKOLOV T, SUTSKEVER I, CHEN K, et al. Distributed Representations of Words and Phrases and their Compositionality[C]// Neural Information Processing Systems Foundation. Proceedings of the 26th International Conference on Neural Information Processing Systems, December 5-8, 2013, Lake Tahoe, Nevada, USA. New York: Curran Associates, 2013: 3111-3119. |
| [7] | PENNINGTON J, SOCHER R, MANNING C D. Glove: Global Vectors for Word Representation[C]// ACL. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, October 25-29, 2014, Doha, Qatar. Stroudsburg: ACL, 2014: 1532-1543. |
| [8] | DAI A M, LE Q V. Semi-supervised Sequence Learning[C]// Neural Information Processing Systems Foundation. Proceedings of the 28th International Conference on Neural Information Processing Systems, December 7-12, 2015, Montreal, Quebec, Canada. New York: Curran Associates, 2015: 3079-3087. |
| [9] | PETERS M, NEUMANN M, IYYER M, et al. Deep Contextualized Word Representations[C]// ACL. Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics, June 1-6, 2018, New Orleans, USA. Stroudsburg: ACL, 2018: 2227-2237. |
| [10] | CHEN T, GUESTRIN C. Xgboost: A Scalable Tree Boosting System[C]// ACM. Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, August 13-17, 2016, San Francisco, CA, USA. New York: ACM, 2016: 785-794. |
| [11] | CORTES C, VAPNIK V. Support-vector Networks[J]. Machine Learning, 1995, 20(3):273-297. |
| [12] | LIU P, QIU X, HUANG X. Recurrent Neural Network for Text Classification with Multi-task Learning[C]// IJCAI. Proceedings of the 25th International Joint Conference on Artificial Intelligence, July 9-15, 2016, New York. Menlo Park: AAAI, 2016: 2873-2879. |
| [13] | KIM Y. Convolutional Neural Networks for Sentence Classification[C]// ACL. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, October 25-29, 2014, Doha, Qatar. Stroudsburg: ACL, 2014: 1746-1751. |
| [14] |
LLOYD S. Least Squares Quantization in PCM[J]. IEEE Transactions on Information Theory, 1982, 28(2):129-136.
doi: 10.1109/TIT.1982.1056489 URL |
| [15] | ARTHUR D, VASSILVITSKII S. K-means++: The Advantages of Careful Seeding[C]// ACM. Proceedings of the 18th Annual ACM-SIAM Symposium on Discrete Algorithms, January 7-9, 2007, New Orleans, Louisiana, USA. Philadelphia: SIAM, 2007: 1027-1035. |
| [16] | SCULLEY D. Web-scale K-means Clustering[C]// ACM. Proceedings of the 19th International Conference on World Wide Web, April 26-30, 2010, Raleigh, North Carolina, USA. New York: ACM, 2010: 1177-1178. |
| [17] | BRITZ D, LE Q, PRYZANT R. Effective Domain Mixing for Neural Machine Translation[C]// ACL. Proceedings of the Second Conference on Machine Translation, September 7-8, 2017, Copenhagen, Denmark. Stroudsburg: ACL, 2017: 118-126. |
| [18] | KIFER D, BEN-DAVID S, GEHRKE J. Detecting Change in Data Streams[C]// VLDB. Proceedings of the Thirtieth International Conference on Very Large Data Bases, August 31-September 3, 2004, Toronto, Canada. Trondheim, Norway: VLDB Endowment, 2004: 180-191. |
| [19] | BEND S, EIRON N, LONG P M. On the Difficulty of Approximately Maximizing Agreements[J]. Journal of Computer and System Sciences, 2003, 3(66):496-514. |
| [20] | BEND S, BLITZER J, CRAMMER K, et al. Analysis of Representations for Domain Adaptation[C]// Neural Information Processing Systems Foundation. Proceedings of the 20th Annual Conference on Neural Information Processing Systems, December 4-7, 2006, Vancouver, British Columbia, Canada. Cambridge, USA: MIT Press, 2007: 137-144. |
| [21] | HEWITT J, MANNING C D. A Structural Probe for Finding Syntax in Word Representations[C]// ACL. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics, June 2-7, 2019, Minneapolis, MN, USA. Stroudsburg: ACL, 2019: 4129-4138. |
| [1] | 谢四江, 高琼, 冯雁. 基于可信中继量子密钥分发网络的最少公共节点多路径路由方案[J]. 信息网络安全, 2021, 21(7): 35-42. |
| [2] | 刘忻, 杨浩睿, 郭振斌, 王家寅. 一种实现在线注册与权限分离的工业物联网身份认证协议[J]. 信息网络安全, 2021, 21(7): 1-9. |
| [3] | 方敏之, 程光, 孔攀宇. 抗噪的应用层二进制协议格式逆向方法[J]. 信息网络安全, 2021, 21(7): 72-79. |
| [4] | 胡博文, 周纯杰, 刘璐. 基于模糊多目标决策的智能仪表功能安全与信息安全融合方法[J]. 信息网络安全, 2021, 21(7): 10-16. |
| [5] | 文伟平, 方莹, 叶何, 陈夏润. 一种对抗符号执行的代码混淆系统[J]. 信息网络安全, 2021, 21(7): 17-26. |
| [6] | 任涛, 金若辰, 罗咏梅. 融合区块链与联邦学习的网络入侵检测算法[J]. 信息网络安全, 2021, 21(7): 27-34. |
| [7] | 郭春, 蔡文艳, 申国伟, 周雪梅. 基于关键载荷截取的SQL注入攻击检测方法[J]. 信息网络安全, 2021, 21(7): 43-53. |
| [8] | 徐洪平, 马泽文, 易航, 张龙飞. 基于卷积循环神经网络的网络流量异常检测技术[J]. 信息网络安全, 2021, 21(7): 54-62. |
| [9] | 陈柏沩, 夏璇, 钟卫东, 吴立强. 基于秘密共享的LBlock的S盒防御方案[J]. 信息网络安全, 2021, 21(7): 80-86. |
| [10] | 黄子依, 秦玉海. 基于多特征识别的恶意挖矿网页检测及其取证研究[J]. 信息网络安全, 2021, 21(7): 87-94. |
| [11] | 刘忻, 郭振斌, 宋宇宸. 一种基于SGX的工业物联网身份认证协议[J]. 信息网络安全, 2021, 21(6): 1-10. |
| [12] | 张正, 柳亚男, 王雷, 方旭明. 针对不规则网络的高精度和高效率的多跳定位算法[J]. 信息网络安全, 2021, 21(6): 11-18. |
| [13] | 沈卓炜, 高鹏, 许心宇. 基于安全协商的DDS安全通信中间件设计[J]. 信息网络安全, 2021, 21(6): 19-25. |
| [14] | 刘璟, 张玉臣, 张红旗. 基于Q-Learning的自动入侵响应决策方法[J]. 信息网络安全, 2021, 21(6): 26-35. |
| [15] | 吴奕, 仲盛. 区块链共识算法Raft研究[J]. 信息网络安全, 2021, 21(6): 36-44. |
| 阅读次数 | ||||||||||||||||||||||||||||||||||||||||||||||||||
|
全文 132
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||
|
摘要 482
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||