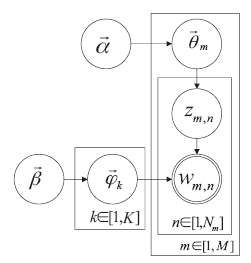
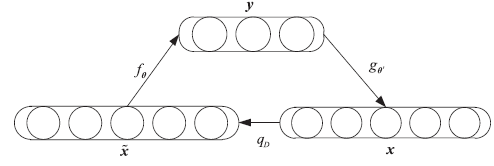
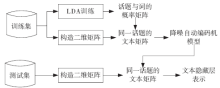
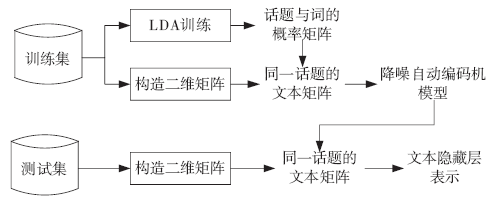
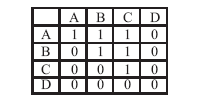
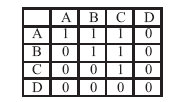
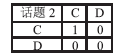
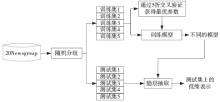
| [1] |
RUSSELL S J, NORVIG P, CANNY J F, et al.Artificial Intelligence: A Modern Approach[M]. Upper Saddle River: Prentice Hall, 2003.
|
| [2] |
LU Xin.Document Retrieval: A Structural Approach[J]. Information Processing & Management, 1990, 26(2): 209-218.
|
| [3] |
CHOUDHARY B, BHATTACHARYYA P. Text Clustering Using Semantics[EB/OL]. , 2016-11-10.
|
| [4] |
MANI I, BLOEDORN E.Multi-document Summarization by Graph Search and Matching[C]//ACM. The 14th National Conference on Artificial Intelligence, July 27-31, 1997, Providence, Rhode Island. New York: ACM, 1997: 622-628.
|
| [5] |
SCHENKER A, BUNKE H, LAST M, et al.Graph-theoretic Techniques for Web Content Mining[M]. New York: World Scientific Publishing Co., 2005.
|
| [6] |
HENSMAN S.Construction of Conceptual Graph Representation of Texts[C]//ACM. Student Research Workshop at HLT-NAACL 2004, May 2-7, 2004, Boston, Massachusetts. New York: ACM, 2004: 49-54.
|
| [7] |
SCHENKER A, LAST M, BUNKE H, et al.Classification of Web Documents using a Graph Model[C]//IEEE. 12th International Conference on Document Analysis and Recognition, August 3-6, 2003, Edinburgh, Scotland. Washington: IEEE, 2003: 240-244.
|
| [8] |
SCHENKER A, LAST M, BUNKE H, et al. Clustering of Web Documents using a Graph Model[EB/OL]. , 2016-11-11.
|
| [9] |
BLEI D M, NG A Y, JORDAN A Y.Latent Dirichlet Allocation[J]. The Journal of Machine Learning Research, 2003, 3(1): 993-1022.
|
| [10] |
WANG Yi. Distributed Gibbs Sampling of Latent Topic Models: The Gritty Details[EB/OL]. , 2016-11-11.
|
| [11] |
尚海,罗森林,韩磊,等. 基于句义成分的短文本表示方法研究[J]. 信息网络安全,2016(5):64-70.
|
| [12] |
CORTES C, VAPNIK V.Support-vector Networks[J]. Machine learning, 1995, 20(3): 273-297.
|
| [13] |
毛焱颖,罗森林 . 融合多种技术的堆喷射方法研究[J]. 信息网络安全,2016(6):48-55.
|
| [14] |
WEI Chao, LUO Senlin, MA Xincheng, et al. Locally Embedding Autoencoders: A Semi-Supervised Manifold Learning Approach of Document Representation[EB/OL]. , 2016-11-12.
|
| [15] |
吴晓平,周舟,李洪成. Spark框架下基于无指导学习环境的网络流量异常检测研究与实现[J]. 信息网络安全,2016(6):1-7.
|
| [16] |
李航. 统计学习方法[M]. 北京:清华大学出版社,2012.
|
| [17] |
吴旭,郭芳毓,颉夏青,等. 面向机构知识库结构化数据的文本相似度评价算法[J]. 信息网络安全,2015(5):16-20.
|
| [18] |
VINCENT P, LAROCHELLE H, BENGIO Y, et al.Extracting and Composing Robust Features with Denoising Autoencoders[C]// Federation of Finnish Learned Societies. 25th International Conference on Machine Learning, July 5-9, 2008, Helsinki, Finland. New York: ACM, 2008: 1096-1103.
|
| [19] |
胡雪,封化民,李明伟,等. 数据挖掘中一种增强的Apriori算法分析[J]. 信息网络安全,2015(11):77-83.
|
 ), 潘丽敏, 高君丰
), 潘丽敏, 高君丰