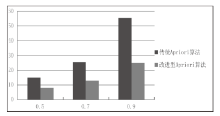
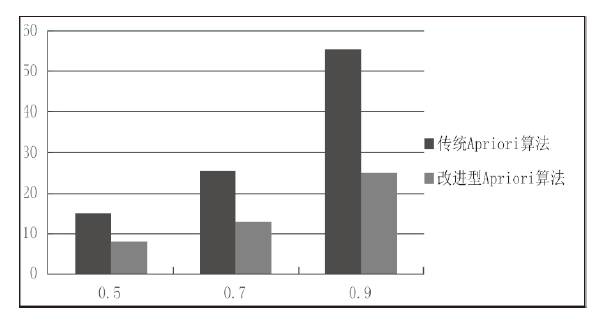
| [1] |
陈晓,赵晶玲. 大数据处理中混合型聚类算法的研究与实现[J]. 信息网络安全,2015,(4):45-49.
|
| [2] |
刘步中. 基于频繁项集挖掘算法的改进与研究[J]. 计算机应用研究,2012, 29(2):475-477.
|
| [3] |
崔贯勋,李梁,王柯柯,等. 关联规则挖掘中Apriori算法的研究与改进[J]. 计算机应用,2010,30(11):2952-2955.
|
| [4] |
吴旭,郭芳毓,颉夏青,等. 面向机构知识库结构化数据的文本相似度评价算法[J]. 信息网络安全,2015,(5):16-20.
|
| [5] |
AGRAWAL R, IMIELIŃSKI T, SWAMI A. Mining association rules between sets of items in large databases[J]. ACM SIGMOD Record, 1993, 22(2): 207-216.
|
| [6] |
SAVASERE A, OMIECINSKI E, NAVATHE S B.An Efficient Algorithm for Mining Association Rules in Large Databases[C]//21th International Conference on Very Large Data Bases, San Francisco, CA, USA, 1995: 432-444.
|
| [7] |
TIOVONEN H.Sampling Large Databases for Association Rules[C]//22th International Conference on Very Large Data Bases, San Francisco, CA, USA , 1996: 134-145.
|
| [8] |
CRESTANA-JENSEN V, SOPARKAR N.Frequent Itemset Counting Across Multiple Tables[C]//4th Pacific-Asia Conference, PAKDD 2000, Kyoto, Japan, 2000: 49-61.
|
| [9] |
许为,林柏钢,林思娟,等. 一种基于用户交互行为和相似度的社交网络社区发现方法研究[J]. 信息网络安全,2015,(7):77-83.
|
| [10] |
BAY S D, PAZZANI M J.Detecting Group Differences: Mining Contrast Sets[J]. Data Mining & Knowledge Discovery, 2002, 5(3): 213-246.
|
| [11] |
AGARWAL R C, AGGARWAL C C, PRASAD V V V. A Tree Projection Algorithm For Generation Of Frequent Itemsets[J]. Journal of Parallel & Distributed Computing,(Special Issue on High Performance Data Mining), 2000, 61(3): 350-371.
|
| [12] |
ZHANG G L, LEI J S, WU X H.An Improved Apriori Algorithm for Mining Association Rules[J]. Microelectronics & Computer, 2010, 23(2): 10-12.
|
| [13] |
吴坚,沙晶. 基于随机森林算法的网络舆情文本信息分类方法研究[J]. 信息网络安全,2014,(11):36-40.
|
| [14] |
JR R J B. Efficiently mining long patterns from databases[C]//The ACM International Conference on Management of Data, Washington, 1998, 27:85-93.
|
| [15] |
高聪. Deep Web下不确定数据处理的研究[D]. 沈阳:东北大学,2008.
|
| [16] |
AGRAWAL R, SRIKANT R.Fast Algorithms for Mining Association Rules in Large Databases[C]//The 20th International Conference on Very Large Data Bases, CA, USA, 1994: 487-499.
|
| [17] |
孙兴东,李爱平,李树栋. 一种基于聚类的微博关键词提取方法的研究与实现[J]. 信息网络安全,2014,(12):27-31.
|
| [18] |
HAN J, PEI J, YIN Y, et al.Mining Frequent Patterns without Candidate Generation: A Frequent-Pattern Tree Approach[J]. Data Mining & Knowledge Discovery, 2004, 8(1):53-87.
|
| [19] |
HUNYADI D.Performance Comparison of Apriori and FP-Growth Algorithms in Generating Association Rules[J]. 5th European conference on European computing conference, Wisconsin, 2011: 376-381.
|
| [20] |
GOSWAMI D N, CHATURVEDI A, RAGHUVANSHI C S.Efficient Algorithm for Frequent Pattern Mining Based On Apriori[J]. International Journal on Computer Science & Engineering, 2010, 2(4): 942-947.
|