信息网络安全 ›› 2015, Vol. 15 ›› Issue (10): 1-7.doi: 10.3969/j.issn.1671-1122.2015.10.001
• 等级保护 • 下一篇
一种基于混淆机制的网页木马检测模型的研究与实现
杜春来, 孙汇中( ), 王景中, 王宝成
), 王景中, 王宝成
- 北方工业大学信息安全实验室,北京 100144
Research and Implementation of Webpage Trojan Detection Model Based on Obfuscation Mechanisms
DU Chun-lai, SUN Hui-zhong(), WANG Jing-zhong, WANG Bao-cheng
- Information Security Lab, North China University of Technology, Beijing 100144, China
摘要:
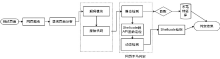
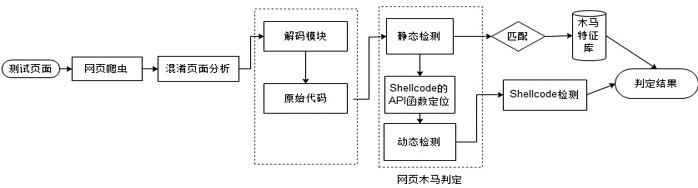
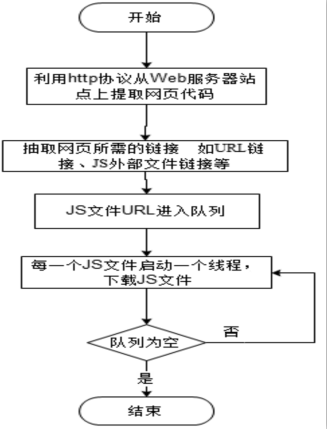
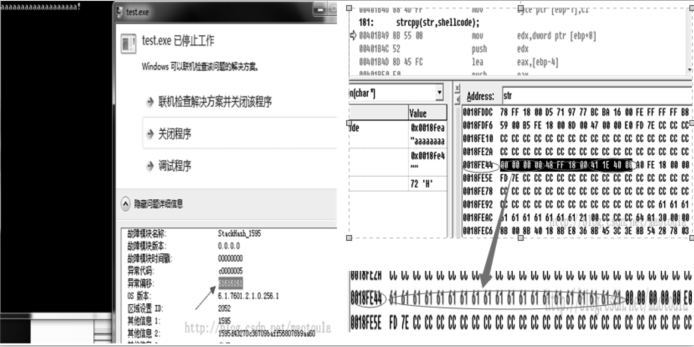
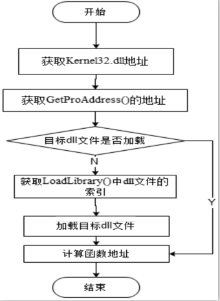
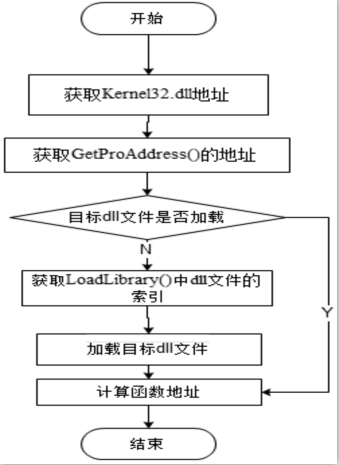
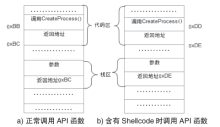
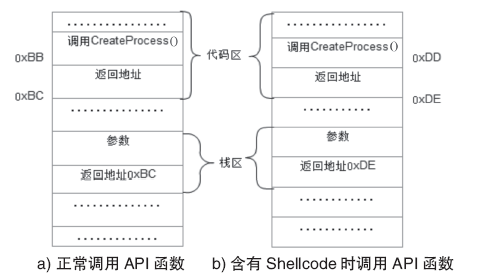
网页木马是利用网页来进行破坏的恶意程序。当用户访问某些含有网页木马的网站时,木马程序就会通过网页中的内嵌链接被悄无声息地下载。这些木马程序一旦被下载、激活,就会利用系统中的某些资源进行破坏。目前针对网页木马的检测有基于特征码的静态检测方案和基于蜜罐客户端的动态检测方案,但这两种检测方案都无法很好地解决网页木马日益增多、混淆和躲避检测手段的问题。文章结合这两种网页木马检测方案的优点,提出一种基于网页内容分析和Shellcode定位识别的反混淆技术,该技术能够解决内嵌链接在动态验证时由于交互条件不存在而造成的漏报。在此基础上,加入动态和静态检测机制,建立了一种网页木马检测模型。实验数据表明,该模型能够准确地检测各种加壳、加密、变形等网页木马,提高了木马检测效率。
中图分类号: