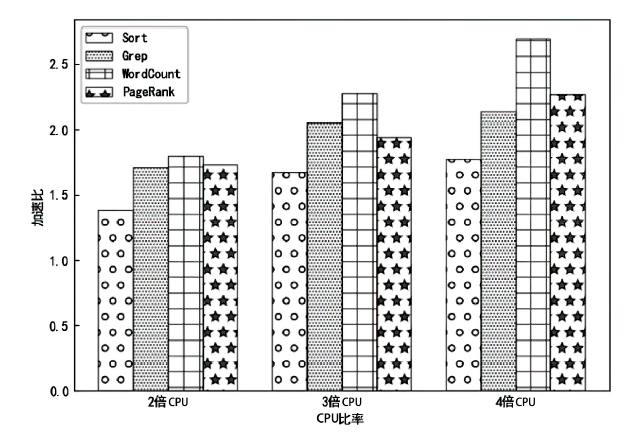
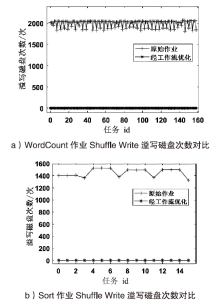
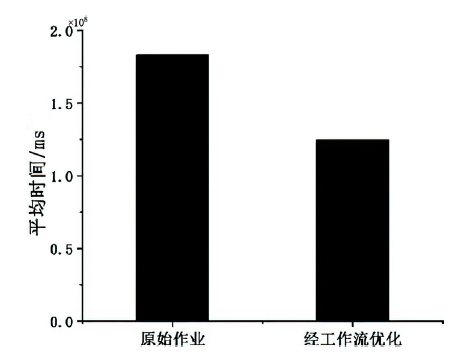
| [1] |
ZAHARIA M, XIN R S, WENDELL P, et al. Apache Spark: A Unified Engine for Big Data Processing[J]. Communications of the ACM, 2016, 59(11): 56-65.
|
| [2] |
PEREZ T B G, CHEN Wei, JI R, et al. Pets: Bottleneck-Aware Spark Tuning with Parameter Ensembles[C]// IEEE. 2018 27th International Conference on Computer Communication and Networks (ICCCN). New Your:IEEE, 2018: 1-9.
|
| [3] |
GULINO A, CANAKOGLU A, CERI S, et al. Performance Prediction for Data-Driven Workflows on Apache Spark[C]// IEEE. 2020 28th International Symposium on Modeling, Analysis, and Simulation of Computer and Telecommunication Systems (MASCOTS). New York:IEEE, 2020: 1-8.
|
| [4] |
GU Jing, LI Ying, TANG Hongyan, et al. Auto-Tuning Spark Configurations Based on Neural Network[C]// IEEE. International Conference on Communications (ICC). New York:IEEE, 2018: 1-6.
|
| [5] |
SHAH S, AMANNEJAD Y, KRISHNAMURTHY D, et al. PERIDOT: Modeling Execution Time of Spark Applications[J]. IEEE Open Journal of the Computer Society, 2021, 2(1): 346-359.
|
| [6] |
AHMED N, BARCZAK A L C, RASHID M A, et al. A Parallelization Model for Performance Characterization of Spark Big Data Jobs on Hadoop Clusters[J]. Journal of Big Data, 2021, 8(1): 1-28.
|
| [7] |
MYUNG R, YU H. Performance Prediction for Convolutional Neural Network on Spark Cluster[J]. Electronics, 2020, 9(9): 1340-1362.
|
| [8] |
PERTRIDIS P, GOUNARIS A, TORRES J. Spark Parameter Tuning via Trial-and-Error[C]// Springer. INNS Conference on Big Data. Heidelberg: Springer, 2016: 226-237.
|
| [9] |
CHENG Guoli, YING Shi, WANG Bingming, et al. Efficient Performance Prediction for Apache Spark[J]. Journal of Parallel and Distributed Computing, 2021, 149(5): 40-51.
|
| [10] |
TIAN Chunqi, LI Jing, WANG Wei, et al. A Method for Improving the Performance of Spark on Container Cluster Based on Machine Learning[J]. Netinfo Security, 2019, 19(4): 11-19.
|
|
田春岐, 李静, 王伟, 等. 一种基于机器学习的Spark容器集群性能提升方法[J]. 信息网络安全, 2019, 19(4): 11-19.
|
| [11] |
RUAN Shuhua, PAN Fanfan, CHEN Xingshu, et al. An Intelligent Optimization Method for Spark Job Configuration Parameters[J]. Advanced Engineering Sciences, 2020, 52(1): 191-197.
|
|
阮树骅, 潘梵梵, 陈兴蜀, 等. 一种Spark作业配置参数智能优化方法[J]. 工程科学与技术, 2020, 52(1): 191-197.
|
| [12] |
AL-SAYEH H, HAGEDORN S, SATTLER K U. A Gray-Box Modeling Methodology for Runtime Prediction of Apache Spark Jobs[J]. Distributed and Parallel Databases, 2020, 38(4): 819-839.
|
| [13] |
KAN Zhongliang, LI Jianzhong. A Regression Model-Based Approach to Spark Task Performance Analysis[J]. Journal of Harbin Institute of Technology, 2018, 50(3): 192-198.
|
|
阚忠良, 李建中. 基于回归模型的Spark任务性能分析方法[J]. 哈尔滨工业大学学报, 2018, 50(3): 192-198.
|
| [14] |
LI Cichao. Analysis and Optimization of Hadoop Job Scheduling Algorithm[D]. Wuhan: Wuhan University of Technology, 2015.
|
|
李词超. Hadoop作业调度算法分析与优化[D]. 武汉: 武汉理工大学, 2015.
|
| [15] |
LI Zhe. Scheduling Algorithm Based on Job Type Classification and Cost Comparison for Hadoop Platform[D]. Guangzhou: South China University of Technology, 2015.
|
|
李哲. Hadoop平台基于作业类型划分和代价比较的调度算法[D]. 广州: 华南理工大学, 2015.
|
| [16] |
AMORIM R C D, MIRKIN B. Minkowski Metric, Feature Weighting and Anomalous Cluster Initializing in K-Means Clustering[J]. Pattern Recognition, 2012, 45(3): 1061-1075.
|
| [17] |
SAATY T L. The Analytic Hierarchy Process[M]. New York: McGraw Hill Higher Education, 1980.
|
| [18] |
PETRIDIS P, GOUNARIS A, TORRES J. Spark Parameter Tuning via Trial-and-Error[C]// Springer. INNS Conference on Big Data. Heidelberg: Springer, 2016: 226-237.
|
| [19] |
WANG Lei, ZHAN Jianfeng, LUO Chunjie, et al. BigDataBench: A Big Data Benchmark Suite from Internet Services[C]// IEEE. The 20th IEEE International Symposium on High Performance Computer Architecture (HPCA-2014). New York:IEEE, 2014: 488-499.
|
 ), WU Tianxiong3
), WU Tianxiong3