信息网络安全 ›› 2016, Vol. 16 ›› Issue (5): 64-70.doi: 10.3969/j.issn.1671-1122.2016.05.010
基于句义成分的短文本表示方法研究
尚海, 罗森林, 韩磊, 张笈( )
)
- 北京理工大学信息系统及安全对抗实验中心,北京 100081
Research on Short Text Representation Based on Sentential Semantic Components
Hai SHANG, Senlin LUO, Lei HAN, Ji ZHANG()
- Information System and Security & Countermeasures Experimental Center, Beijing Institute of Technology, Beijing 100081, China
摘要:
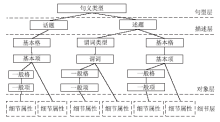
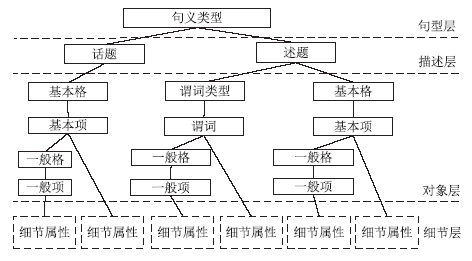
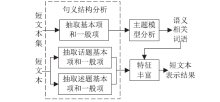
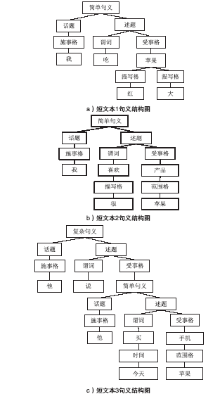
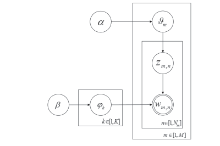
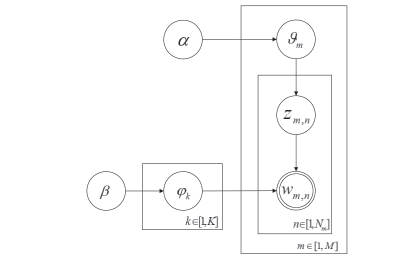
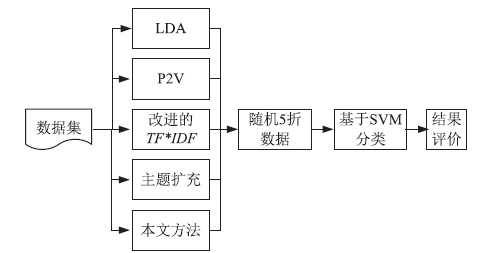
随着移动互联网和信息技术的迅速发展,评论、微博等短文本数量呈现爆炸式增长。短文本数据少,文本特征稀疏,亟需有效的短文本表示方法来提升针对短文本的文本分类、文本聚类、热点发现、舆情分析等应用的效果。针对短文本特征稀疏问题,文章提出融合句义成分的短文本表示方法。该方法考虑短文本的语义信息,在保证特征空间维度不变的同时,结合句义成分和主题模型构建语义相关词语,再利用句义结构模型的话题和述题构建主题选择判定规则,选择语义相关词语扩充到短文本中,减少短文本表示向量中的0值特征。文章基于Sogou文本分类语料库,选择3个类别数据进行文本分类实验,并利用5折交叉方法选定模型参数。结果表明,文中方法对短文本分类的精确度达到0.7958,结果优于对比的短文本表示方法。因此,利用语义相关词语丰富短文本的语义信息,能够有效缓解短文本特征稀疏问题。文中短文本表示方法可以有效提高短文本分类等具体应用效果。
中图分类号: