信息网络安全 ›› 2024, Vol. 24 ›› Issue (11): 1783-1792.doi: 10.3969/j.issn.1671-1122.2024.11.017
一种面向法律文书的命名实体识别模型
卢睿1,2( ), 李林瑛3
), 李林瑛3
- 1.辽宁警察学院公安信息系,大连 116036
2.辽宁省公安大数据智能应用重点实验室,大连 116036
3.大连外国语大学软件学院,大连 116044
-
收稿日期:2024-07-04出版日期:2024-11-10发布日期:2024-11-21 -
通讯作者:卢睿luruilly@sina.com -
作者简介:卢睿(1978—),女,辽宁,教授,博士,CCF会员,主要研究方向为公安情报分析、文本挖掘、优化理论与方法|李林瑛(1975—),男,吉林,教授,博士,主要研究方向为自然语言处理、文本挖掘、优化理论与方法 -
基金资助:辽宁省科技厅应用基础研究计划(2023JH2/101300134);辽宁省教育厅高等学校基本科研项目(LJKMZ20221549);辽宁省研究生教育教学改革研究项目(LNYJG2022423);辽宁省教育厅重点攻关项目(JYTZD2023088)
A Named Entity Recognition Model for Legal Documents
LU Rui1,2(), LI Linying3
- 1. Police Information Department, Liaoning Police College, Dalian 116036, China
2. Liaoning Provincial Key Laboratory of Public Security Big Data Intelligent Application, Dalian 116036, China
3. School of Software Engineering, Dalian University of Foreign, Dalian 116044, China
-
Received:2024-07-04Online:2024-11-10Published:2024-11-21
摘要:
准确识别法律文书中的实体是构建智慧司法的基础,但通用的命名实体识别模型不能很好地识别法律文书中实体边界,识别结果不能与法律业务紧密结合。为有效提高法律文书中各实体的识别效果,文章提出一种面向法律文书的命名实体识别模型BBAG-NER。该模型首先利用BERT对字符序列进行编码,然后运用双向长短记忆神经网络和Attention分配不同权重以提高对实体边界的划分能力,最后采用全局指针识别备选司法实体片段,并通过实体分类器得到最终的实体类别。实验结果表明,在法律文书语料数据集上,BBAG-NER模型的F1值达到了89.18%,较BERT-CRF模型提高了2.1%,验证了模型整体的有效性。
中图分类号:
引用本文
卢睿, 李林瑛. 一种面向法律文书的命名实体识别模型[J]. 信息网络安全, 2024, 24(11): 1783-1792.
LU Rui, LI Linying. A Named Entity Recognition Model for Legal Documents[J]. Netinfo Security, 2024, 24(11): 1783-1792.
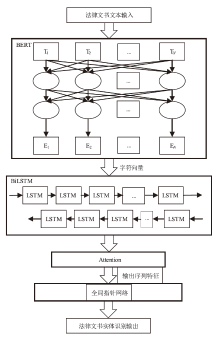
图1
BBAG-NER模型架构
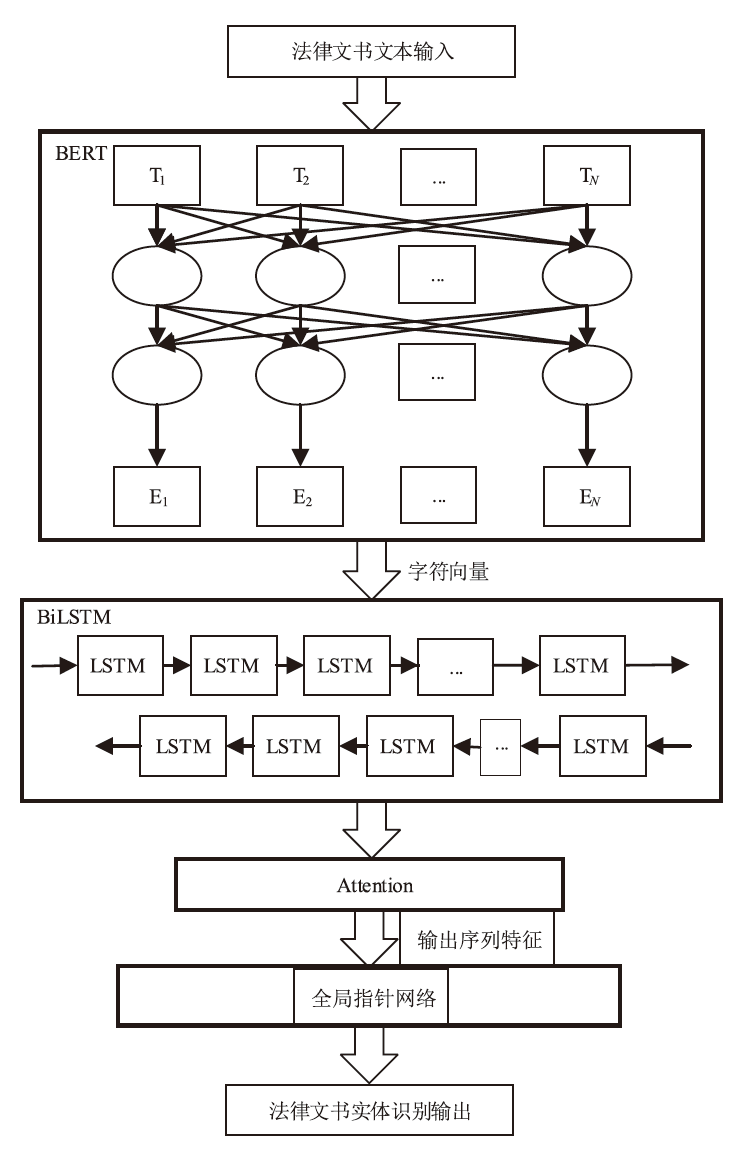

图2
BERT输入表示
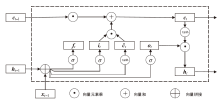
图3
LSTM网络循环单元
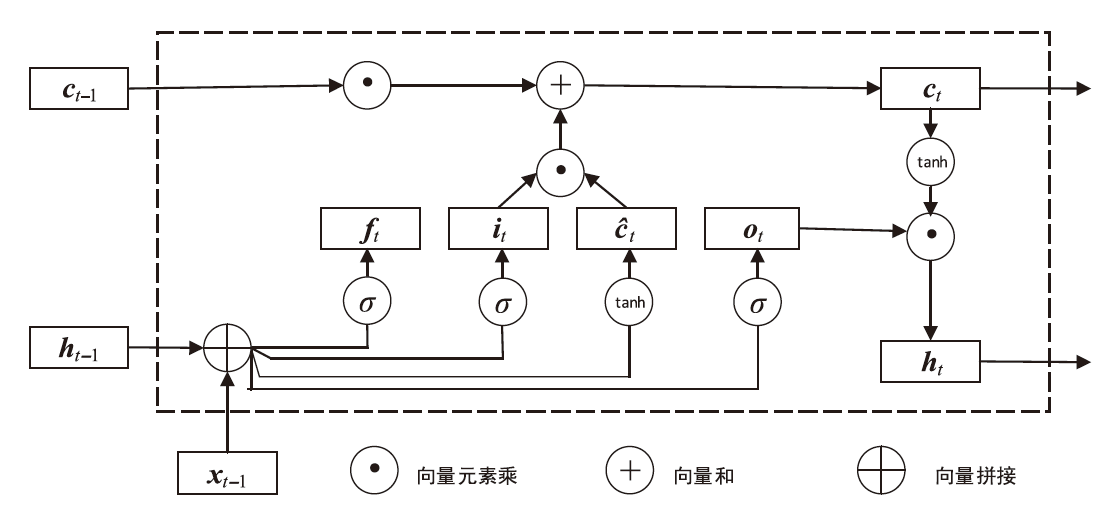
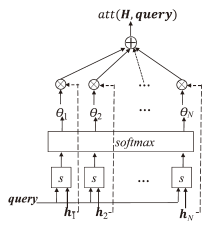
图4
注意力分布
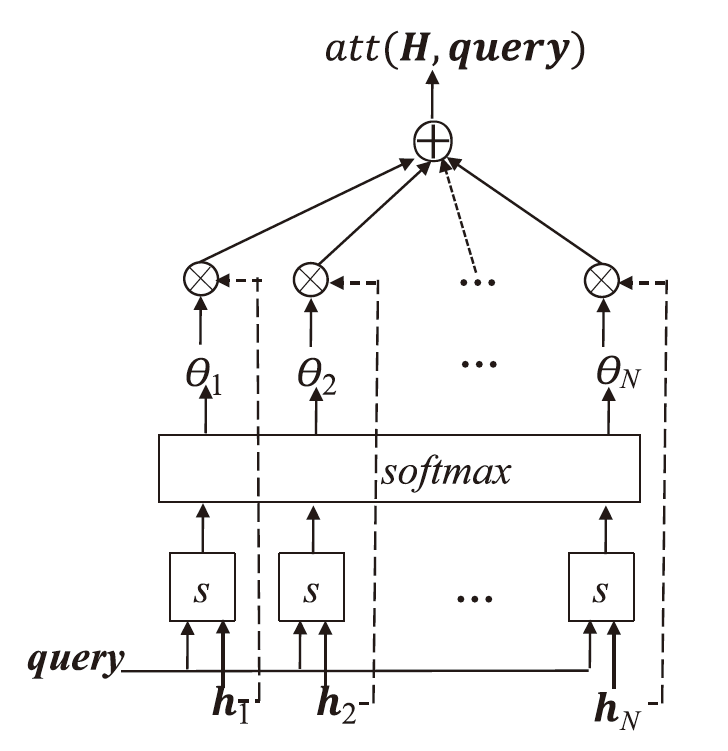
表1
司法领域命名实体信息说明
| 实体类型 | 标识 | 数量/个 |
|---|---|---|
| 涉案时间 | SASJ | 674 |
| 涉案地点 | SADD | 946 |
| 涉案机构 | SAJG | 190 |
| 犯罪嫌疑人 | FZXYR | 1544 |
| 受害人 | SHZ | 665 |
| 作案工具 | ZAGJ | 190 |
| 被盗物品 | BDWP | 1424 |
| 被盗金额 | BDJE | 216 |
| 物品价值 | WPJZ | 524 |
| 盗窃获利 | DQHL | 90 |
表2
实验环境
| 参数 | 参数值 |
|---|---|
| 操作系统 | Microsoft Windows 10 |
| CPU | Intel Core i5-8265U CPU@3.9 GHz |
| GPU | NVIDIA GeForce RTX3060(12 GB) |
| 内存 | 32 GB |
| Python | 3.7.15 |
| PyTorch | 1.13.0 |
表3
模型比较结果
| 模型 | P | R | F1 |
|---|---|---|---|
| W2NER[ | 91.83% | 69.26% | 78.98% |
| BERT+SPAN[ | 87.75% | 90.11% | 88.91% |
| BERT+CRF[ | 88.68% | 89.45% | 89.06% |
| BERT+MRC[ | 88.13% | 87.95% | 88.03% |
| BERT+BiLSTM+CRF[ | 84.28% | 90.08% | 87.08% |
| 本文模型 | 89.39% | 88.98% | 89.18% |
表4
模型识别结果
| 类别 | P | R | F1 |
|---|---|---|---|
| 涉案时间 | 92.53% | 91.84% | 92.18% |
| 涉案地点 | 78.87% | 80.87% | 79.85% |
| 涉案机构 | 91.16% | 86.84% | 88.95% |
| 犯罪嫌疑人 | 96.60% | 97.54% | 97.07% |
| 受害人 | 94.44% | 92.03% | 93.22% |
| 作案工具 | 86.59% | 81.58% | 84.01% |
| 被盗物品 | 82.94% | 80.90% | 81.91% |
| 被盗金额 | 89.27% | 84.72% | 86.94% |
| 物品价值 | 96.61% | 97.90% | 97.25% |
| 盗窃获利 | 78.64% | 90.00% | 83.94% |
表5
消融实验结果
| 模型 | P | R | F1 |
|---|---|---|---|
| w/o bilstm+att | 86.78% | 90.46% | 88.58% |
| w/o att | 89.43% | 88.50% | 88.97% |
| 本文模型 | 89.39% | 88.98% | 89.18% |
表6
跨领域鲁棒性实验结果
| 模型 | 人民日报数据集 | 中医药命名实体数据集 | ||||
|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | |
| BERT+CRF | 95.98% | 95.85% | 95.91% | 71.85% | 82.35% | 76.80% |
| BERT+MRC | 96.05% | 94.17% | 95.10% | 70.37% | 84.44% | 76.76% |
| BERT+SPAN | 94.98% | 95.93% | 95.46% | 72.95% | 81.42% | 76.95% |
| BERT+BiLSTM+ CRF | 95.51% | 94.51% | 95.01% | 73.01% | 80.43% | 77.65% |
| 本文模型 | 96.12% | 95.90% | 96.06% | 78.81% | 80.80% | 79.79% |
| [1] | HUANG Zhiheng, XU Wei, YU Kai. Bidirectional LSTM-CRF Models for Sequence Tagging[EB/OL]. [2024-05-08]. https://arxiv.org/pdf/1508.01991. |
| [2] | MA Xuezhe, HOVY E. End-to-End Sequence Labeling via Bi-Directional LSTM-CNNS-CRF[C]// ACL. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1:Long Papers). Stroudsburg: ACL, 2016: 1064-1074. |
| [3] | LAMPLE G, BALLESTEROS M, SUBRAMANIAN S, et al. Neural Architectures for Named Entity Recognition[C]// NAACL. Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies. Stroudsburg: NAACL, 2016: 260-270. |
| [4] | AKBIK A, BLYTHE D, VOLLGRAF R. Contextual String Embeddings for Sequence Labeling[C]// ACL. Proceedings of the 27th International Conference on Computational Linguistics. Stroudsburg: ACL, 2018: 1638-1649. |
| [5] | CONTRACTOR D, PATRA B, MAUSAM, et al. Constrained BERT BiLSTM CRF for Understanding Multi-Sentence Entity-Seeking Questions[J]. Natural Language Engineering, 2021, 27(1): 65-87. |
| [6] | XU Lei, LI Shuang, WANG Yuchen, et al. Named Entity Recognition of BERT-BiLSTM-CRF Combined with Self-Attention[C]// Springer. Lecture Notes in Computer Science. Heidelberg: Springer, 2021: 556-564. |
| [7] | ZHANG Qiang, SUN Yong, ZHANG Linlin, et al. Named Entity Recognition Method in Health Preserving Field Based on BERT[J]. Procedia Computer Science, 2021, 183: 212-220. |
| [8] | ZHANG Xinrui, LUO Xudong. A Machine-Reading-Comprehension Method for Named Entity Recognition in Legal Documents[C]// Springer. Communications in Computer and Information Science. Heidelberg: Springer, 2023: 224-236. |
| [9] | YUAN Zheng, TAN Chuanqi, HUANG Songfang, et al. Fusing Heterogeneous Factors with Triaffine Mechanism for Nested Named Entity Recognition[C]// ACL. Findings of the Association for Computational Linguistics:ACL 2022. Stroudsburg: ACL, 2022: 3174-3186. |
| [10] | SU Jianlin, MURTADHA A, PAN Shengfeng, et al. Global Pointer: Novel Efficient Span-Based Approach for Named Entity Recognition[EB/OL]. [2024-05-08]. https://arxiv.org/abs/2208.03054. |
| [11] | SUÁREZ-PANIAGUA V, RIVERA ZAVALA R M, SEGURA-BEDMAR I, et al. A Two-Stage Deep Learning Approach for Extracting Entities and Relationships from Medical Texts[EB/OL]. (2019-09-20)[2024-05-08]. https://www.sciencedirect.com/science/article/pii/S1532046419302047?via%3Dihub. |
| [12] | WU Jun, CHENG Yao, HAO Han, et al. Automatic Extraction of Chinese Terminology Based on BERT Embedding and BiLSTM-CRF Model[J]. Journal of the China Society for Scientific and Technical Information, 2020, 39(4): 409-418. |
| 吴俊, 程垚, 郝瀚, 等. 基于BERT嵌入BiLSTM-CRF模型的中文专业术语抽取研究[J]. 情报学报, 2020, 39(4): 409-418. | |
| [13] |
WANG Yue, WANG Mengxuan, ZHANG Sheng, et al. Alarm Text Named Entity Recognition Based on BERT[J]. Journal of Computer Applications, 2020, 40(2): 535-540.
doi: 10.11772/j.issn.1001-9081.2019101717 |
|
王月, 王孟轩, 张胜, 等. 基于BERT的警情文本命名实体识别[J]. 计算机应用, 2020, 40(2): 535-540.
doi: 10.11772/j.issn.1001-9081.2019101717 |
|
| [14] |
FENG Luanluan, LI Junhui, LI Peifen, et al. Technology and Terminology Detection Oriented National Defense Science[J]. Computer Science, 2019, 46(12): 231-236.
doi: 10.11896/jsjkx.190300069 |
|
冯鸾鸾, 李军辉, 李培峰, 等. 面向国防科技领域的技术和术语识别方法研究[J]. 计算机科学, 2019, 46(12): 231-236.
doi: 10.11896/jsjkx.190300069 |
|
| [15] |
LI Jinchen, LI Yanling, GE Fengpei, et al. Survey of Research on Intelligent System for Legal Domain[J]. Computer Engineering and Applications, 2023, 59(7): 31-50.
doi: 10.3778/j.issn.1002-8331.2208-0383 |
|
李瑾晨, 李艳玲, 葛凤培, 等. 面向法律领域的智能系统研究综述[J]. 计算机工程与应用, 2023, 59(7): 31-50.
doi: 10.3778/j.issn.1002-8331.2208-0383 |
|
| [16] | WANG Zhili, WU Yufan, LEI Pengbin, et al. Named Entity Recognition Method of Brazilian Legal Text Based on Pre-Training Model[J]. Journal of Physics: Conference Series, 2020, 1550(3): 1-5. |
| [17] | LEITNER E, REHM G, MORENO-SCHNEIDER J. Fine-Grained Named Entity Recognition in Legal Documents[C]// Springer. Lecture Notes in Computer Science. Heidelberg: Springer, 2019: 272-287. |
| [18] | WANG Xiao, WAN Yuqing. A Named Entity Identification Method for Legal Documents[J]. Computer Applications and Software, 2023, 40(8): 180-186. |
| 王霄, 万玉晴. 一种面向法律文书的命名实体识别方法[J]. 计算机应用与软件, 2023, 40(8): 180-186. | |
| [19] | JI Donghong, TAO Peng, FEI Hao, et al. An End-to-End Joint Model for Evidence Information Extraction from Court Record Document[EB/OL]. (2020-05-29)[2024-05-08]. https://www.sciencedirect.com/science/article/abs/pii/S0306457320308001?via%3Dihub. |
| [20] | LI Chunnan, WANG Lei, SUN Yuanyuan, et al. BERT Based Named Entity Recognition for Legal Texts on Theft Cases[J]. Journal of Chinese Information Processing, 2021, 35(8): 73-81. |
| 李春楠, 王雷, 孙媛媛, 等. 基于BERT的盗窃罪法律文书命名实体识别方法[J]. 中文信息学报, 2021, 35(8): 73-81. | |
| [21] | WANG Dexian, WANG Suge, PEI Wensheng, et al. Named Entity Recognition Based on JCWA-DLSTM for Legal Instruments[J]. Journal of Chinese Information Processing, 2020, 34(10): 51-58. |
| 王得贤, 王素格, 裴文生, 等. 基于JCWA-DLSTM的法律文书命名实体识别方法[J]. 中文信息学报, 2020, 34(10): 51-58. | |
| [22] | GUO Lihua, LI Yang, WAGN Suge, et al. Name Entity Recognition in Legal Instruments Based on Matching Strategy and Community Attention Mechanism[J]. Journal of Chinese Information Processing, 2022, 36(2): 85-92. |
| 郭力华, 李旸, 王素格, 等. 基于匹配策略和社区注意力机制的法律文书命名实体识别[J]. 中文信息学报, 2022, 36(2): 85-92. | |
| [23] |
ZENG Lanlan, WANG Yisong, CHEN Panfeng. Named Entity Recognition Based on BERT and Joint Learning for Judgment Documents[J]. Journal of Computer Applications, 2022, 42(10): 3011-3017.
doi: 10.11772/j.issn.1001-9081.2021091565 |
|
曾兰兰, 王以松, 陈攀峰. 基于BERT和联合学习的裁判文书命名实体识别[J]. 计算机应用, 2022, 42(10): 3011-3017.
doi: 10.11772/j.issn.1001-9081.2021091565 |
|
| [24] | MAO Xingliang, CHEN Xiaohong, NING Ken, et al. Global and Local Information Integration for Recognizing Key Case Elements[J]. Journal of Software, 2023, 34(12): 5724-5736. |
| 毛星亮, 陈晓红, 宁肯, 等. 全局和局部信息融合的案情关键要素识别[J]. 软件学报, 2023, 34(12): 5724-5736. | |
| [25] | NING Ken. A Study of Chinese Named Entity Recognition for Judicial Field[D]. Changsha: Central South University, 2022. |
| 宁肯. 面向司法领域的中文命名实体识别研究[D]. 长沙: 中南大学, 2022. | |
| [26] | YANG Shuxin, LIU Tianyang, HUANG Weidong. Chinese Legal Document Named Entity Recognition Based on MVBCN-FLW[EB/OL]. [2024-01-02]. http://kns.cnki.net/kcms/detail/11.2127.tp.20231228.1537.016.html. |
| 杨书新, 刘天扬, 黄伟东. 基于MVBCN-FLW的中文法律文书命名实体识别[EB/OL]. [2024-01-02]. http://kns.cnki.net/kcms/detail/11.2127.tp.20231228.1537.016.html | |
| [27] | CAI Li, WANG Shuting, LIU Junhui, et al. Survey of Data Annotation[J]. Journal of Software, 2020, 31(2): 302-320. |
| 蔡莉, 王淑婷, 刘俊晖, 等. 数据标注研究综述[J]. 软件学报, 2020, 31(2): 302-320. | |
| [28] | LU Yaojie, LIU Qing, DAI Dai, et al. Unified Structure Generation for Universal Information Extraction[C]// ACL. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1:Long Papers). Stroudsburg: ACL, 2022: 5755-5772. |
| [29] | LI Jingye, FEI Hao, LIU Jiang, et al. Unified Named Entity Recognition as Word-Word Relation Classification[C]// AAAI. Proceedings of the AAAI Conference on Artificial Intelligence. MenloPark: AAAI, 2022: 10965-10973. |
| [30] | FU Jinlan, HUANG Xuanjing, LIU Pengfei. SpanNER: Named Entity Re-/Recognition as Span Prediction[C]// ACL. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1:Long Papers). Stroudsburg: ACL, 2021: 7183-7195. |
| [31] | HU Shulin, ZHANG Huajun, HU Xuesong, et al. Chinese Named Entity Recognition Based on BERT-CRF Model[C]// IEEE. 2022 IEEE/ACIS 22nd International Conference on Computer and Information Science (ICIS). New York: IEEE, 2022: 105-108. |
| [32] | LI Xiaoya, FENG Jingrong, MENG Yuxian, et al. A Unified MRC Framework for Named Entity Recognition[C]// ACL. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2020: 5849-5859. |
| [33] | GUO Zhixin, DENG Xiaolong. Intelligent Identification Method of Legal Case Entity Based on BERT-BiLSTM-CRF[J]. Journal of Bejing University of Posts and Telecommunications, 2021, 44(4): 129-134. |
|
郭知鑫, 邓小龙. 基于BERT-BiLSTM-CRF的法律案件智能识别方法[J]. 北京邮电大学学报, 2021, 44(4): 129-134.
doi: 10.13190/j.jbupt.2020-241 |
|
| [34] |
DENG Liang, QI Panhu, LIU Zhenlong, et al. BGPNRE: A BERT-Based Global Pointer Network for Named Entity-Relation Joint Extraction Method[J]. Computer Science, 2023, 50(3): 42-48.
doi: 10.11896/jsjkx.220600239 |
|
邓亮, 齐攀虎, 刘振龙, 等. BGPNRE: 一种基于BERT的全局指针网络实体关系联合抽取方法[J]. 计算机科学, 2023, 50(3): 42-48.
doi: 10.11896/jsjkx.220600239 |
|
| [35] | LU Rui, HUANG Junbo, LI Linying. Research on Entity Identification Model of Global Terrorism Research Database Based on BERT-BiLSTM-CRF[J]. Mathematics in Practice and Theory, 2022, 52(8): 128-136. |
| 卢睿, 黄俊博, 李林瑛. 基于BERT-BiLSTM-CRF的涉恐实体识别模型研究[J]. 数学的实践与认识, 2022, 52(8): 128-136. | |
| [36] | HUANG Junbo. Research on Event Extraction Method in Terrorism News Text[D]. Dalian: Dalian University of Foreign Languages, 2022. |
| 黄俊博. 涉恐新闻文本的事件抽取方法研究[D]. 大连: 大连外国语大学, 2022. |
| [1] | 王亚欣, 张健. 基于少样本命名实体识别技术的电子病历指纹特征提取[J]. 信息网络安全, 2024, 24(10): 1537-1543. |
| [2] | 叶桓荣, 李牧远, 姜波. 基于迁移学习和威胁情报的DGA恶意域名检测方法研究[J]. 信息网络安全, 2023, 23(10): 8-15. |
| [3] | 丁家伟, 刘晓栋. 基于ELECTRA-CRF的电信网络诈骗案件文本命名实体识别模型[J]. 信息网络安全, 2021, 21(6): 63-69. |
| [4] | GULKhanSafiQamas, 尹继泽, 潘丽敏, 罗森林. 基于深度神经网络的命名实体识别方法研究[J]. 信息网络安全, 2017, 17(10): 29-35. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||