信息网络安全 ›› 2018, Vol. 18 ›› Issue (8): 56-63.doi: 10.3969/j.issn.1671-1122.2018.08.008
基于Hadoop的海量安全日志聚类算法研究
陆勰1( ), 罗守山1, 张玉梅2
), 罗守山1, 张玉梅2
- 1. 北京邮电大学信息安全中心,北京 100876
2. 武警天津总队参谋部综合信息保障中心,天津 300001
-
收稿日期:2018-04-04出版日期:2018-08-20发布日期:2020-05-11 -
作者简介:作者简介:陆勰(1985—),女,云南,硕士研究生,主要研究方向为信息安全;罗守山(1962—),男,北京,教授,博士,主要研究方向为网络与信息安全;张玉梅(1967—),女,天津,本科,主要研究方向为网络通信及信息安全。
-
基金资助:国家高技术研究发展计划(863计划)[2015AA016005]
Research on Hadoop-based Massive Security Log Clustering Algorithm
Xie LU1(), Shoushan LUO1, Yumei ZHANG2
- 1. Information Security Center, Beijing University of Posts and Telecommunications, Beijing 100876, China
2. Chinese People’s Armed Police Force Corps of Tianjin, Tianjin 300001, China;
-
Received:2018-04-04Online:2018-08-20Published:2020-05-11
摘要:
大数据环境下,网络安全事件层出不穷,网络安全成为各界关注的热点。安全日志记录着设备运行状态的重要信息,通过对其分析可以实时掌握网络安全态势,可作为事前防护、事后追责的安全审计手段,实现对异常事件的追责与溯源。针对日志审计的重要性并结合数据挖掘在日志分析领域的重要作用,同时针对单机环境下处理海量数据效率相对滞后等问题,文章提出一种基于Hadoop的面向海量安全日志的聚类算法。首先,文章提出了基于最大最小距离(MMD)和均值思想对K-means聚类算法进行改进,克服了传统K-means聚类算法在寻找初始聚类中心随机性的缺陷;其次,为了适应海量数据的有效处理,提高聚类的效率与速度,将改进的K-means聚类算法部署在Map/Reduce上进行迭代计算。实验表明,改进的聚类算法的准确性优于其他典型算法,聚类效果稳定,在集群的性能上具有较好的运行速度和加速比。
中图分类号:
引用本文
陆勰, 罗守山, 张玉梅. 基于Hadoop的海量安全日志聚类算法研究[J]. 信息网络安全, 2018, 18(8): 56-63.
Xie LU, Shoushan LUO, Yumei ZHANG. Research on Hadoop-based Massive Security Log Clustering Algorithm[J]. Netinfo Security, 2018, 18(8): 56-63.
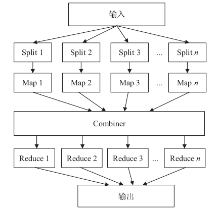
图1
Map/Reduce的原理框架
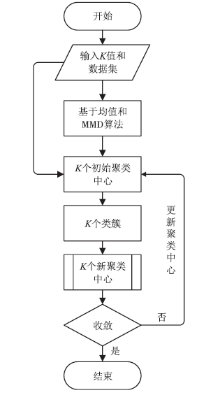
图2
改进的K-means聚类算法流程图
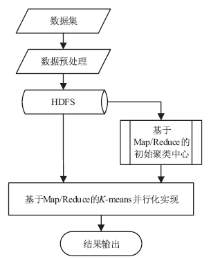
图3
并行化整体流程
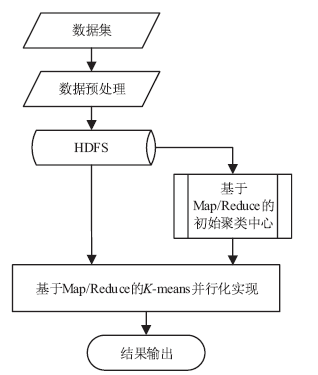
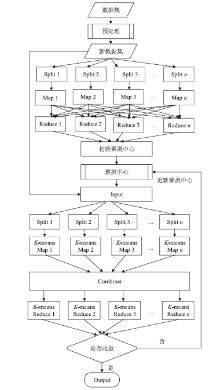
图4
基于Map/Reduce的K-means聚类算法并行化实现框架
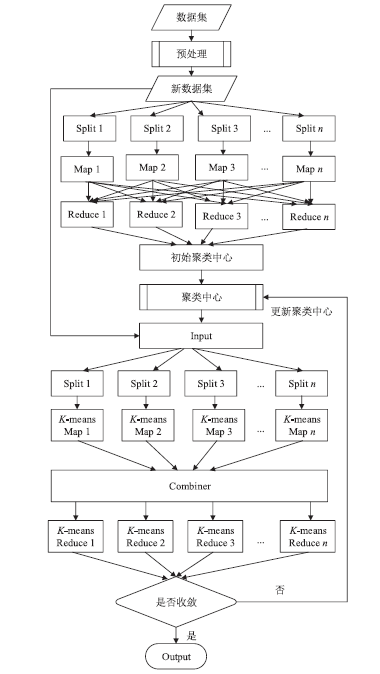
表1
算法准确率比较
 |
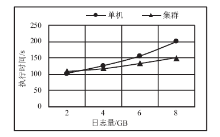
图5
单机与集群环境下执行时间
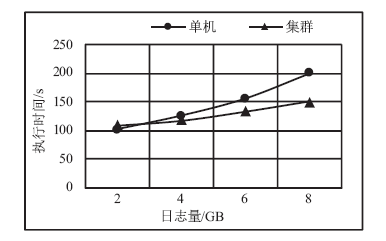
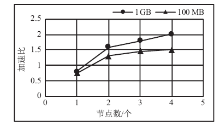
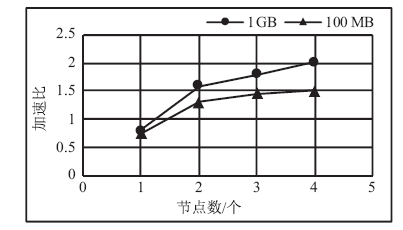
图6
1GB与100 MB日志量在不同节点数时的加速比
| [1] | WANG Shaojie, LONG Chun, WAN Wei, et al.Research on HDFS Small File Problem Based on Real-time Data of Cybersecurity[J]. Netinfo Security, 2017, 17(10): 81-85. |
| 王绍节,龙春,万巍,等. 基于网络空间安全实时数据的HDFS小文件问题研究[J]. 信息网络安全,2017,17(10):81-85. | |
| [2] | LEI Xiaofeng, XIE Kunqing, LIN Fan, et al.An Efficient Clustering Algorithm Based on Local Optimality of K-Means[J]. Journal of Software, 2008, 19(7): 1683-1692. |
| 雷小锋,谢昆青,林帆,等. 一种基于K-Means局部最优性的高效聚类算法[J]. 软件学报,2008,19(7):1683-1692. | |
| [3] | ZHAO Weizhong, MA Huifang, FU Yanxiang, et al.Research on Parallel k-means Algorithm Design Based on Hadoop Platform[J]. Computer Science, 2011, 38(10): 166-168, 176. |
| 赵卫中,马慧芳,傅燕翔, 等. 基于云计算平台Hadoop的并行k-means聚类算法设计研究[J]. 计算机科学,2011,38(10):166-168,176. | |
| [4] | LIU Meiling, HUANG Mingxuan, TANG Weidong.A k-means Algorithm for Optimized Initial Clustering Center Based on Discrete Quantity[J]. Computer Engineering and Science, 2017, 39(6): 1164-1170. |
| 刘美玲,黄名选,汤卫东. 基于离散量优化初始聚类中心的k-means算法[J]. 计算机工程与科学,2017,39(6):1164-1170. | |
| [5] | LI Wu, ZHAO Jiaoyan, YAN Taishan.Improved K-means Clustering Algorithm Optimizing Initial Clustering Centers Based on Average Difference Degree[J]. Control and Decision, 2017, 32(4): 759-762. |
| 李武,赵娇燕,严太山. 基于平均差异度优选初始聚类中心的改进K-均值聚类算法[J]. 控制与决策,2017,32(4):759-762. | |
| [6] | YIN Aiying, WU Yunbing, ZHU Minwei, et al. Improved Algorithm of K-means Based on MapReduce Framework[EB/OL]. , 2018-2-1. |
| 阴爱英,吴运兵,朱敏琛,等. 基于MapReduce框架下K-means的改进算法[EB/OL]. , 2018-2-1. | |
| [7] | WANG Yonggui, WU Chao, DAI Wei.K-means Algorithm of Random Sample Based on MapReduce[J]. Computer Engineering and Applications, 2016, 52(8): 74-79. |
| 王永贵,武超,戴伟. 基于MapReduce的随机抽样K-means算法[J]. 计算机工程与应用,2016,52(8):74-79. | |
| [8] | SUN Jigui, LIU Jie, ZHAO Lianyu.Clustering Algorithms Research[J]. Journal of Software, 2008, 19(1): 48-61. |
| 孙吉贵,刘杰,赵连宇. 聚类算法研究[J]. 软件学报,2008,19(1):48-61. | |
| [9] | LI Xiaoyu, YU Liying, LEI Hang, et al.The Parallel Implementation and Application of an Improved K-means Algorithm[J]. Journal of University of Electronic Science and Technology of China, 2017, 46(1): 61-68. |
| 李晓瑜,俞丽颖,雷航,等. 一种K-means改进算法的并行化实现与应用[J]. 电子科技大学学报,2017,46(1):61-68. | |
| [10] | HAN Lingbo, WANG Qiang, JIANG Zhengfeng, et al.Improved k-means Initial Clustering Center Selection Algorithm[J]. Computer Engineering and Applications, 2010, 46(17): 150-152. |
| 韩凌波,王强,蒋正锋,等. 一种改进的k-means初始聚类中心选取算法[J]. 计算机工程与应用,2010,46(17):150-152. | |
| [11] | LI Hongcheng, WU Xiaoping, CHEN Yan. k-means Clustering Method Preserving Differential Privacy in MapReduce Framework[J]. Journal on Communications, 2016, 37(2): 124-130. |
| 李洪成,吴晓平,陈燕. MapReduce框架下支持差分隐私保护的k-means聚类方法[J]. 通信学报,2016,37(2):124-130. | |
| [12] | DUAN Juan, XIN Yang, MA Yuwei.Research and Design of Security Audit Log System Based on Web Application[J].Netinfo Security, 2014, 14(10): 70-76. |
| 段娟,辛阳,马宇威. 基于Web应用的安全日志审计系统研究与设计[J]. 信息网络安全,2014,14(10):70-76. | |
| [13] | SU Rong.Research and Application of Security Log Clustering Mining Algorithm Based on Hadoop Platform[D]. Xi’an: Northwest University, 2015. |
| 苏蓉. 基于Hadoop平台的安全日志聚类挖掘算法研究与应用[D]. 西安:西北大学,2015. | |
| [14] | ZHONG Ya, GUO Yuanbo.Design and Implementation of Log Parsing System Based on Machine Learning[J]. Journal of Computer Applications, 2018, 38(2): 352-356. |
| 钟雅,郭渊博. 基于机器学习的日志解析系统设计与实现[J]. 计算机应用,2018,38(2):352-356. | |
| [15] | GAO Hua.Research on Intrusion Detection Parallel Algorithm Based on Massive Logs[J]. Modern Electronics Technique, 2016, 39(9): 71-75. |
| 高华. 基于海量日志的入侵检测并行化算法研究[J].现代电子技术,2016,39(9):71-75. | |
| [16] | HU Xue, FENG Huamin, LI Mingwei, et al.Analysis of an Enhanced Apriori Algorithms in Data Mining[J]. Netinfo Security, 2015, 15(11): 77-83. |
| 胡雪,封化民,李明伟,等. 数据挖掘中一种增强的Apriori算法分析[J]. 信息网络安全,2015,15(11):77-83. | |
| [17] | LIU Yan, CAO Ning, PAN Wei, et al.System Anomaly Detection in Distributed Systems through MapReduce-Based Log Analysis[C]//IEEE. 3rd International Conference on Advanced Computer Theory and Engineering, Augest 20-22, 2010, Chengdu, China. New Jersey: IEEE, 2010: 410-413. |
| [18] | VAARANDI R, PIHELGAS M.Using Security Logs for Collecting and Reporting Technical Security Metrics[C]//IEEE. 2014 IEEE Military Communications Conference, October 6-8, 2014. New Jersey: IEEE, 2014: 294-299. |
| [1] | 傅彦铭, 李振铎. 基于拉普拉斯机制的差分隐私保护k-means++聚类算法研究[J]. 信息网络安全, 2019, 19(2): 43-52. |
| [2] | 吴天雄, 陈兴蜀, 罗永刚. 大数据平台下应用程序保护机制的研究与实现[J]. 信息网络安全, 2019, 19(1): 68-75. |
| [3] | 冯新扬, 沈建京. 一种基于Yarn云计算平台与NMF的大数据聚类算法[J]. 信息网络安全, 2018, 18(8): 43-49. |
| [4] | 赵薇, 赵娜, 张怡兴. 基于颜色不变特征的谱聚类双分图分割方法[J]. 信息网络安全, 2018, 18(12): 8-14. |
| [5] | 何利, 姚元辉. 基于上下文聚类的云虚拟机异常检测与识别策略[J]. 信息网络安全, 2018, 18(12): 54-65. |
| [6] | 张春霞, 王新猛, 张晓熙. 基于Hadoop的森林公安网络舆情监测系统设计与实现[J]. 信息网络安全, 2018, 18(12): 82-86. |
| [7] | 王伟, 廖正宇, 张辉, 郭栋. 基于大数据的铁路信号系统数据存储与分析系统设计与实现[J]. 信息网络安全, 2017, 17(1): 29-37. |
| [8] | 姜凤燕, 姜瑾, 姜吉婷. 基于大数据环境的电子取证研究[J]. 信息网络安全, 2016, 16(9): 60-63. |
| [9] | 王毅, 唐勇, 卢泽新, 俞昕. 恶意代码聚类中的特征选取研究[J]. 信息网络安全, 2016, 16(9): 64-68. |
| [10] | 蔡霖翔. 网络诈骗案件涉案人群智能分析[J]. 信息网络安全, 2016, 16(9): 246-250. |
| [11] | 陈希林, 马丁. 针对微博信息分析的HBase存储结构设计[J]. 信息网络安全, 2016, 16(9): 267-271. |
| [12] | 张士豪, 顾益军, 张俊豪. 微博自动分类系统设计[J]. 信息网络安全, 2016, 16(1): 81-87. |
| [13] | 张越今, 丁丁. 敏感话题发现中的增量型文本聚类模型[J]. 信息网络安全, 2015, 15(9): 170-174. |
| [14] | 张付霞, 蒋朝惠. 一种基于网格聚类的查询隐私匿名算法研究[J]. 信息网络安全, 2015, 15(8): 53-58. |
| [15] | 孙大鹏. 云计算技术在垃圾短信过滤中的应用与实现[J]. 信息网络安全, 2015, 15(7): 13-19. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||