信息网络安全 ›› 2024, Vol. 24 ›› Issue (5): 767-777.doi: 10.3969/j.issn.1671-1122.2024.05.010
一种启发式日志模板自动发现方法
张书雅1,2,3, 陈良国1,2,3, 陈兴蜀1,2,3( )
)
- 1.四川大学网络空间安全学院,成都 610065
2.数据安全防护与智能治理教育部重点实验室,成都 610065
3.四川大学网络空间安全研究院,成都 610065
-
收稿日期:2024-03-01出版日期:2024-05-10发布日期:2024-06-24 -
通讯作者:陈兴蜀 E-mail:chenxsh@scu.edu.cn -
作者简介:张书雅(1999—),女,四川,硕士研究生,主要研究方向为数据安全管理|陈良国(1993—),男,贵州,博士研究生,主要研究方向为大数据和网络安全|陈兴蜀(1968—),女,贵州,教授,博士,主要研究方向为云计算安全、数据安全、威胁检测、开源情报和人工智能安全 -
基金资助:国家自然科学基金(U19A2081);中央高校基础研究基金(SCU2023D008);中央高校基础研究基金(2022SCU12116);中央高校基础研究基金(2023SCU12129);中央高校基础研究基金(2023SCU12126);四川大学理工科发展计划(2020SCUNG129)
An Automatic Discovery Method for Heuristic Log Templates
ZHANG Shuya1,2,3, CHEN Liangguo1,2,3, CHEN Xingshu1,2,3()
- 1. School of Cyber Science and Engineering, Sichuan University, Chengdu 610065, China
2. Key Laboratory of Data Protection and Intelligent Management, Ministry of Education, Chengdu 610065, China
3. Cyber Science Research Institute, Sichuan University, Chengdu 610065, China
-
Received:2024-03-01Online:2024-05-10Published:2024-06-24 -
Contact:CHEN Xingshu E-mail:chenxsh@scu.edu.cn
摘要:
日志是安全分析领域的重要数据来源。然而,非结构化原始日志无法直接用于安全分析,因此将日志解析为结构化模板是至关重要的第一步。现有的日志解析方法大多假设属于相同日志模板的日志消息具有相同的日志长度,但日志存在变长变量,导致属于相同模板的日志消息被错误地提取成不同的模板。因此,文章提出一种日志模板自动发现方法KeyParse,首先,基于最长公共子序列算法实现日志与模板的相似度计算,以此忽略变长变量带来的差异性影响,从而实现日志与模板的匹配;其次,基于最高频繁项实现日志模板分组,避免属于相同事件且长度不等的日志消息被划分到不同模板组,减少了模板冗余并提升了模板匹配效率;最后,基于HeavyGuardian算法实现流式日志消息的最高频繁项统计,解决了传统频率统计方法难以适应流式日志消息词频动态变化的问题。实验结果表明,KeyParse在面对多种类型日志集时均具有较高的准确率,平均解析准确度达0.968,并且在解析大型日志集时具有更好的性能。
中图分类号:
引用本文
张书雅, 陈良国, 陈兴蜀. 一种启发式日志模板自动发现方法[J]. 信息网络安全, 2024, 24(5): 767-777.
ZHANG Shuya, CHEN Liangguo, CHEN Xingshu. An Automatic Discovery Method for Heuristic Log Templates[J]. Netinfo Security, 2024, 24(5): 767-777.

图1
原始日志输入示例

图2
日志解析示意图

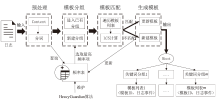
图3
日志解析总体设计
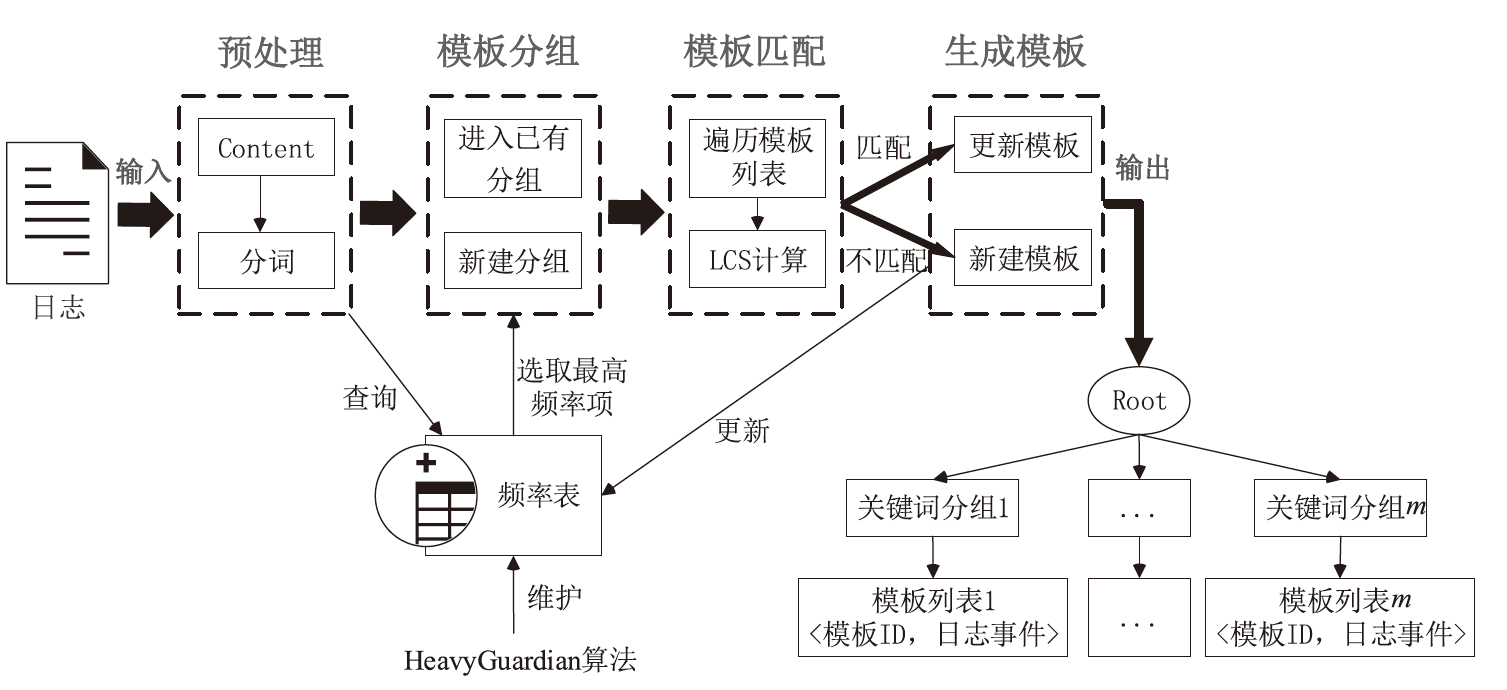

图4
日志解析步骤及结果示意图
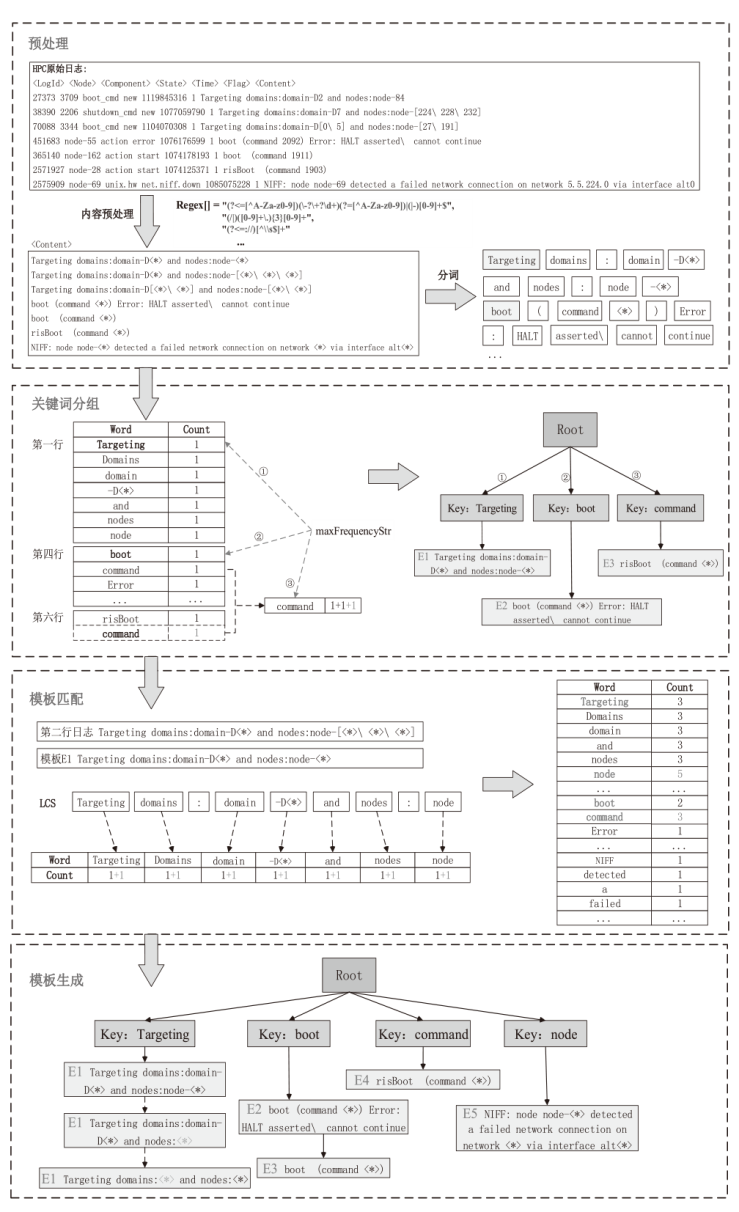
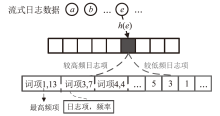
图5
基于HeavyGuardian数据结构的日志项频率统计
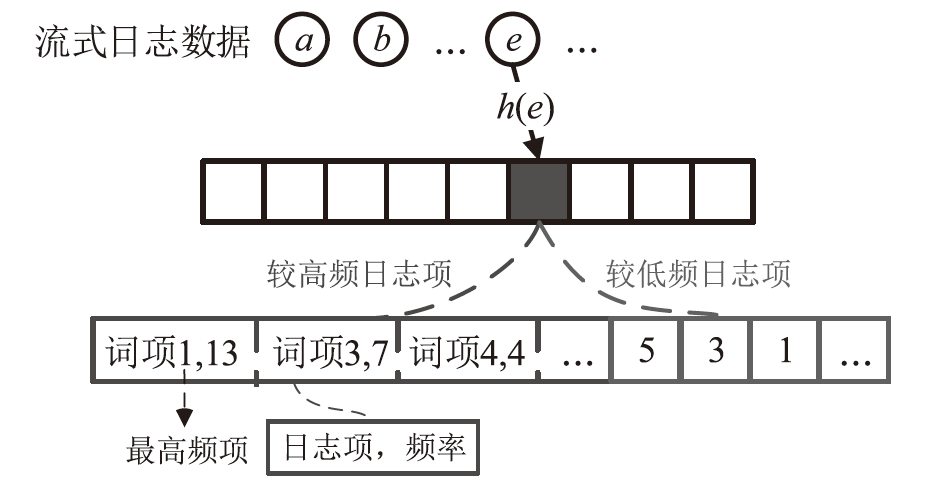
表1
日志解析方法的解析准确度
| Dataset | SLCT | AEL | IPLoM | LKE | LFA | LogSig | SHISO | Log- Cluster | LenMa | Log-Mine | Spell | Drain | MoLFI | KeyParse | Best |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| HDFS | 0.545 | 0.998 | 1* | 1* | 0.885 | 0.850 | 0.998 | 0.546 | 0.998 | 0.851 | 1* | 0.998 | 0.998 | 0.999 | 1 |
| Hadoop | 0.423 | 0.538 | 0.954 | 0.670 | 0.900 | 0.633 | 0.867 | 0.563 | 0.885 | 0.870 | 0.778 | 0.948 | 0.957* | 0.932 | 0.957 |
| Spark | 0.685 | 0.905 | 0.920 | 0.634 | 0.994 | 0.544 | 0.906 | 0.799 | 0.884 | 0.576 | 0.905 | 0.920 | 0.418 | 1* | 1* |
| Zookeeper | 0.726 | 0.921 | 0.962 | 0.438 | 0.839 | 0.738 | 0.660 | 0.732 | 0.841 | 0.688 | 0.964 | 0.967 | 0.839 | 0.993* | 0.993 |
| OpenStack | 0.867 | 0.758 | 0.871 | 0.787 | 0.200 | 0.200 | 0.722 | 0.696 | 0.743 | 0.743 | 0.764 | 0.733 | 0.213 | 0.887* | 0.887 |
| BGL | 0.573 | 0.758 | 0.939 | 0.128 | 0.854 | 0.227 | 0.711 | 0.835 | 0.690 | 0.723 | 0.787 | 0.963 | 0.960* | 0.958 | 0.963 |
| HPC | 0.839 | 0.903 | 0.824 | 0.574 | 0.817 | 0.354 | 0.325 | 0.788 | 0.830 | 0.784 | 0.654 | 0.887 | 0.824 | 0.973* | 0.973 |
| Thunderb. | 0.882 | 0.941 | 0.663 | 0.813 | 0.649 | 0.694 | 0.576 | 0.599 | 0.943 | 0.919 | 0.844 | 0.955* | 0.646 | 0.938 | 0.955 |
| Windows | 0.697 | 0.690 | 0.567 | 0.990 | 0.588 | 0.689 | 0.701 | 0.713 | 0.566 | 0.993 | 0.989 | 0.997 | 0.406 | 0.997* | 0.997 |
| Linux | 0.297 | 0.673 | 0.672 | 0.519 | 0.279 | 0.169 | 0.701 | 0.713 | 0.566 | 0.993 | 0.989 | 0.997 | 0.406 | 0.998* | 0.998 |
| Mac | 0.558 | 0.764 | 0.673 | 0.369 | 0.599 | 0.478 | 0.595 | 0.604 | 0.698 | 0.872 | 0.757 | 0.787 | 0.636 | 0.911* | 0.911 |
| Android | 0.882 | 0.682 | 0.712 | 0.909 | 0.616 | 0.548 | 0.585 | 0.798 | 0.880 | 0.504 | 0.919 | 0.911 | 0.788 | 0.960* | 0.960 |
| HealthApp | 0.331 | 0.568 | 0.822 | 0.592 | 0.549 | 0.235 | 0.397 | 0.531 | 0.174 | 0.684 | 0.639 | 0.780 | 0.440 | 0.995* | 0.995 |
| Apache | 0.731 | 1* | 1* | 1* | 1* | 0.582 | 1* | 0.709 | 1* | 1* | 1* | 1* | 1* | 1* | 1* |
| OpenSSH | 0.521 | 0.538 | 0.802 | 0.426 | 0.501 | 0.373 | 0.619 | 0.426 | 0.925 | 0.431 | 0.554 | 0.788 | 0.500 | 0.971* | 0.971 |
| Proxifier | 0.518 | 0.518 | 0.515 | 0.495 | 0.026 | 0.967 | 0.517 | 0.951 | 0.508 | 0.517 | 0.527 | 0.527 | 0.013 | 0.976* | 0.976 |
| Average | 0.637 | 0.754 | 0.777 | 0.563 | 0.652 | 0.482 | 0.669 | 0.665 | 0.721 | 0.694 | 0.751 | 0.865 | 0.605 | 0.968 |
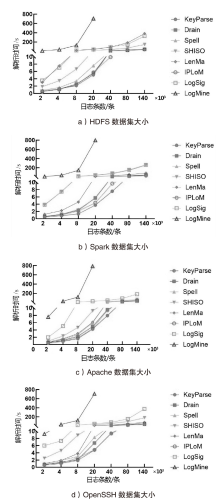
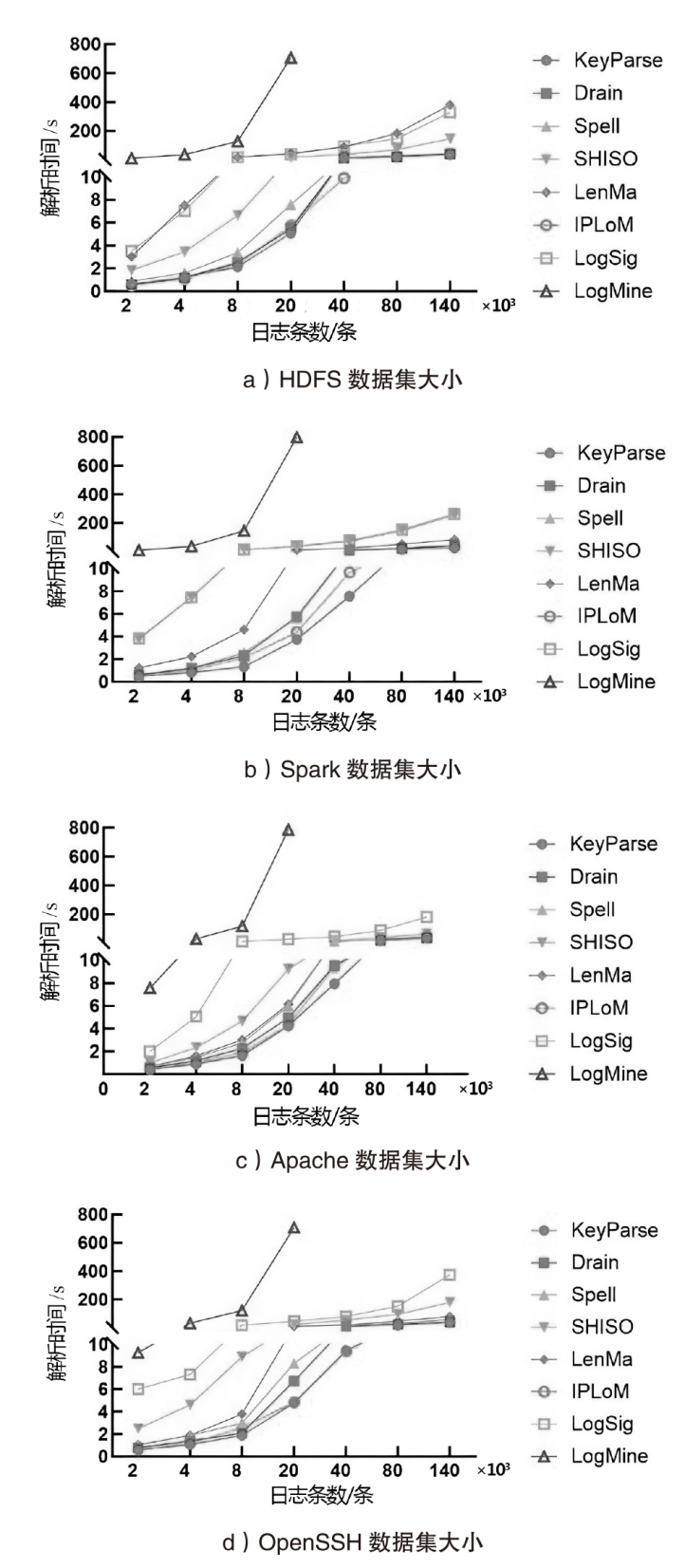
图6
不同大小数据集上日志解析方法的运行时间
| [1] | HASSAN W U, NOUREDDINE M A, DATTA P, et al. OmegaLog: High-Fidelity Attack Investigation via Transparent Multi-Layer Log Analysis[C]// NDSS. Internet Society. The 27th Annual Network and Distributed System Security (NDSS) Symposium. New York: NDSS, 2020: 1-12. |
| [2] | XU Zhiqiang, FANG Pengcheng, LIU Changlin, et al. Depcomm: Graph Summarization on System Audit Logs for Attack Investigation[C]// IEEE. 43rd IEEE Symposium on Security and Privacy (SP). New York: IEEE, 2022: 540-557. |
| [3] | BABENKO A, MARIANI L, PASTORE F. Ava: Automated Interpretation of Dynamically Detected Anomalies[C]// ACM. The 18th International Symposium on Software Testing and Analysis (ISSTA). New York: ACM, 2009: 237-248. |
| [4] | CHEN Anran. An Empirical Study on Leveraging Logs for Debugging Production Failures[C]// IEEE. The 41st International Conference on Software Engineering:Companion Proceedings(ICSE-C). New York: IEEE, 2019: 126-128. |
| [5] | JIA Tong, CHEN Pengfei, YANG Lin, et al. An Approach for Anomaly Diagnosis Based on Hybrid Graph Model with Logs for Distributed Services[C]// IEEE. 2017 IEEE International Conference on Web Services (ICWS). New York: IEEE, 2017: 25-32. |
| [6] | LU Jie, LI Feng, LI Lian, et al. CloudRaid: Detecting Distributed Concurrency Bugs via Log Mining and Enhancement[J]. IEEE Transactions on Software Engineering, 2020, 48(2): 662-677. |
| [7] | BREIER, BRANIŠOVÁ J. Anomaly Detection from Log Files Using Data Mining Techniques[C]// ICISA. The 2017 ICISA International Conference on Intelligent Systems and Applications. Berlin:ICISA, 2015: 449-457. |
| [8] | NANDI A, MANDAL A, ATREJA S, et al. Anomaly Detection Using Program Control Flow Graph Mining from Execution Logs[C]// ACM. The 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2016: 215-224. |
| [9] | LE V H, ZHANG Hongyu. Log-Based Anomaly Detection without Log Parsing[C]// IEEE. 36th IEEE/ACM International Conference on Automated Software Engineering (ASE). New York: IEEE, 2021: 492-504. |
| [10] | LIU Fucheng, WEN Yu, ZHANG Dongxue, et al. Log2vec: A Heterogeneous Graph Embedding Based Approach for Detecting Cyber Threats within Enterprise[C]// ACM. The 2019 ACM SIGSAC Conference on Computer and Communications Security. New York: ACM, 2019: 1777-1794. |
| [11] | XIA Bin, BAI Yuxuan, YIN Junjie, et al. LogGAN: A Log-Level Generative Adversarial Network for Anomaly Detection Using Permutation Event Modeling[J]. Information Systems Frontiers, 2021, 23: 285-298. |
| [12] | MI Haibo, WANG Huaimin, ZHOU Yangfan, et al. Toward Fine-Grained, Unsupervised, Scalable Performance Diagnosis for Production Cloud Computing Systems[J]. IEEE Transactions on Parallel and Distributed Systems, 2013, 24(6): 1245-1255. |
| [13] | RAMATI R. A Beginners Guide to Logstash Grok[EB/OL]. (2016-07-11)[2023-10-27]. https://logz.io/blog/logstash-grok. |
| [14] | ROUILLARD J P. Real-Time Log File Analysis Using the Simple Event Correlator (SEC)[C]//LISA. 2004 LISA. Atlanta: USA 2004: 133-150. |
| [15] | Apache. Apache Log4j 2[EB/OL]. (2022-05-18)[2023-10-27]. https://logging.apache.org/log4j/2.x/. |
| [16] | XU Wei, HUANG Ling, FOX Armando, et al. Detecting Large-Scale System Problems by Mining Console Logs[C]// ACM. The ACM SIGOPS 22nd Symposium on Operating Systems Principles (SOSP). New York: ACM, 2009: 117-132. |
| [17] | ZHU Jieming, HE Shilin, LIU Jinyang, et al. Tools and Benchmarks for Automated Log Parsing[C]// IEEE. The 41st International Conference on Software Engineering:Software Engineering in Practice(ICSE-SEIP). New York: IEEE, 2019: 121-130. |
| [18] | MAKANJU A, ZINCIR-HEYWOOD A N, MILIOS E E. A Lightweight Algorithm for Message Type Extraction in System Application Logs[J]. IEEE Transactions on Knowledge and Data Engineering, 2011, 24(11): 1921-1936. |
| [19] | RISTO V. A Data Clustering Algorithm for Mining Patterns from Event Logs[C]// IEEE. The 3rd IEEE Workshop on IP Operations & Management. New York: IEEE, 2003: 119-126. |
| [20] | NAGAPPAN M, VOUK M A. Abstracting Log Lines to Log Event Types for Mining Software System Logs[C]// IEEE. The 7th International Working Conference on Mining Software Repositories (MSR 2010). New York: IEEE, 2010: 114-117. |
| [21] | VAARANDI R, PIHELGAS M. Logcluster-A Data Clustering and Pattern Mining Algorithm for Event Logs[C]// IEEE. 11th International Conference on Network and Service Management (CNSM). New York: IEEE, 2015: 1-7. |
| [22] | DAI Hetong, LI Heng, CHEN Cheshao, et al. Logram: Efficient Log Parsing Using N-Gram Dictionaries[J]. IEEE Transactions on Software Engineering, 2020, 48(3): 879-892. |
| [23] | FU Qiang, LOU Jianguang, WANG Yi, et al. Execution Anomaly Detection in Distributed Systems through Unstructured Log Analysis[C]// ICDM. The 9th IEEE International Conference on Data Mining. New York: IEEE, 2009: 149-158. |
| [24] | HAMOONI H, DEBNATH B, XU Jianwu, et al. LogMine: Fast Pattern Recognition for Log Analytics[C]// ACM. The 25th ACM International on Conference on Information and Knowledge Management. New York: ACM, 2016: 1573-1582. |
| [25] | TANG Liang, LI Tao, PERNG Changshing. LogSig: Generating System Events from Raw Textual Logs[C]// ACM. The 20th ACM International Conference on Information and Knowledge Management (CIKM). New York: ACM, 2011: 785-794. |
| [26] | MIZUTANI M. Incremental Mining of System Log Format[C]// IEEE. International Conference on Services Computing. New York: IEEE, 2013: 595-602. |
| [27] | SHIMA K. Length Matters: Clustering System Log Messages Using Length of Words[EB/OL]. [2024-01-15]. arXiv preprint arXiv: 1611.03213, 2016. |
| [28] | JIANG Zhenming, HASSAN A E, FLORA P, et al. Abstracting Execution Logs to Execution Events for Enterprise Applications (Short Paper)[C]// IEEE. The 8th International Conference on Quality Software(QSIC). New York: IEEE, 2008: 181-186. |
| [29] | MAKANJU A A O, ZINCIR-HEYWOOD A N, MILIOS E. Clustering Event Logs Using Iterative Partitioning[C]// ACM. The 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2009: 1255-1264. |
| [30] | HE Pinjia, ZHU Jieming, ZHENG Zibin, et al. Drain: An Online Log Parsing Approach with Fixed Depth Tree[C]// IEEE. International Conference on Web Services(ICWS). New York: IEEE, 2017: 33-40. |
| [31] | DU Min, LI Feifei. Spell: Streaming Parsing of System Event Logs[C]// IEEE. 16th International Conference on Data Mining (ICDM). New York: IEEE, 2016: 859-864. |
| [32] | LIU Yudong, ZHANG Xu, HE Shilin, et al. Uniparser: A Unified Log Parser for Heterogeneous Log Data[C]// ACM. The ACM Web Conference 2022. New York: ACM, 2022: 1893-1901. |
| [33] | WANG Xuheng, ZHANG Xu, LI Liqun, et al. SPINE: A Scalable Log Parser with Feedback Guidance[C]// ACM. The 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering(ESEC/FSE). New York: ACM, 2022: 1198-1208. |
| [34] | MENG Weibin, LIU Ying, FEDERICO Zaiter, et al. Logparse: Making Log Parsing Adaptive through Word Classification[C]// IEEE. 29th International Conference on Computer Communications and Networks (ICCCN). New York: IEEE, 2020: 1-9. |
| [35] | TAO Shimin, MENG Weibin, CHENG Yimeng, et al. Logstamp: Automatic Online Log Parsing Based on Sequence Labelling[J]. ACM SIGMETRICS Performance Evaluation Review, 2022, 49(4): 93-98. |
| [36] | HE Pinjia, ZHU Jieming, HE Shilin, et al. Towards Automated Log Parsing for Large-Scale Log Data Analysis[J]. IEEE Transactions on Dependable and Secure Computing, 2017, 15(6): 931-944. |
| [37] | HE Pinjia, ZHU Jieming, HE Shilin, et al. An Evaluation Study on Log Parsing and Its Use in Log Mining[C]// IEEE. The 46th Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN). New York: IEEE, 2016: 654-661. |
| [38] | YANG Tong, GONG Junzhi, ZHANG Haowei, et al. Heavyguardian: Separate and Guard Hot Items in Data Streams[C]// ACM. The 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. New York: ACM, 2018: 2584-2593. |
| [39] | MESSAOUDI S, PANICHELLA A, BIANCULLI D, et al. A Search-Based Approach for Accurate Identification of Log Message Formats[C]// IEEE. The 26th International Conference on Program Comprehension (ICPC). New York: IEEE, 2018: 167-177. |
| [1] | 文伟平, 张世琛, 王晗, 时林. 基于虚拟机自省的Linux恶意软件检测方案[J]. 信息网络安全, 2024, 24(5): 657-666. |
| [2] | 李志华, 陈亮, 卢徐霖, 方朝晖, 钱军浩. 面向物联网Mirai僵尸网络的轻量级检测方法[J]. 信息网络安全, 2024, 24(5): 667-681. |
| [3] | 杨志鹏, 王鹃, 马陈军, 亢云峰. 基于第三方库隔离的Python沙箱逃逸防御机制[J]. 信息网络安全, 2024, 24(5): 682-693. |
| [4] | 顾国民, 陈文浩, 黄伟达. 一种基于多模型融合的隐蔽隧道和加密恶意流量检测方法[J]. 信息网络安全, 2024, 24(5): 694-708. |
| [5] | 沈卓炜, 汪仁博, 孙贤军. 基于Merkle树和哈希链的层次化轻量认证方案[J]. 信息网络安全, 2024, 24(5): 709-718. |
| [6] | 田钊, 牛亚杰, 佘维, 刘炜. 面向车联网的车辆节点信誉评估方法[J]. 信息网络安全, 2024, 24(5): 719-731. |
| [7] | 石润华, 邓佳鹏, 于辉, 柯唯阳. 基于量子行走公钥加密的电子投票方案[J]. 信息网络安全, 2024, 24(5): 732-744. |
| [8] | 郭建胜, 关飞婷, 李志慧. 一种带作弊识别的动态(t,n)门限量子秘密共享方案[J]. 信息网络安全, 2024, 24(5): 745-755. |
| [9] | 李雨昕, 黄文超, 王炯涵, 熊焰. 基于Tamarin的门罗币支付协议分析方法[J]. 信息网络安全, 2024, 24(5): 756-766. |
| [10] | 张长琳, 仝鑫, 佟晖, 杨莹. 面向网络安全领域的大语言模型技术综述[J]. 信息网络安全, 2024, 24(5): 778-793. |
| [11] | 王巍, 胡永涛, 刘清涛, 王凯崙. 铁路运行环境下ERT可信根实体的软件化技术研究[J]. 信息网络安全, 2024, 24(5): 794-801. |
| [12] | 郭梓萌, 朱广劼, 杨轶杰, 司群. 基于APT特征的铁路网络安全性能研究[J]. 信息网络安全, 2024, 24(5): 802-811. |
| [13] | 张浩, 谢大智, 胡云晟, 叶骏威. 基于半监督学习的网络异常检测研究综述[J]. 信息网络安全, 2024, 24(4): 491-508. |
| [14] | 王健, 陈琳, 王凯崙, 刘吉强. 基于时空图神经网络的应用层DDoS攻击检测方法[J]. 信息网络安全, 2024, 24(4): 509-519. |
| [15] | 屠晓涵, 张传浩, 刘孟然. 恶意流量检测模型设计与实现[J]. 信息网络安全, 2024, 24(4): 520-533. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||