信息网络安全 ›› 2016, Vol. 16 ›› Issue (1): 81-87.doi: 10.3969/j.issn.1671-1122.2016.01.015
微博自动分类系统设计
张士豪( ), 顾益军, 张俊豪
), 顾益军, 张俊豪
- 中国人民公安大学网络安全保卫学院,北京102623
An Automatic Classification System for Microblogging
Shihao ZHANG(), Yijun GU, Junhao ZHANG
- School of Cybersecurity,People’s Public Security University of China, Beijing 102623, China
摘要:
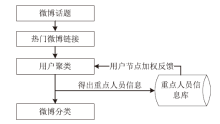
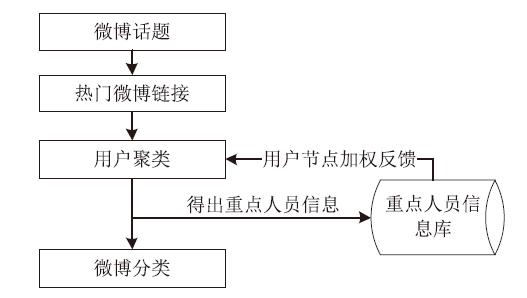
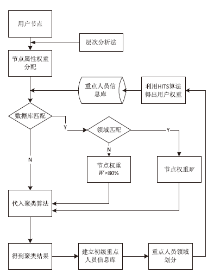
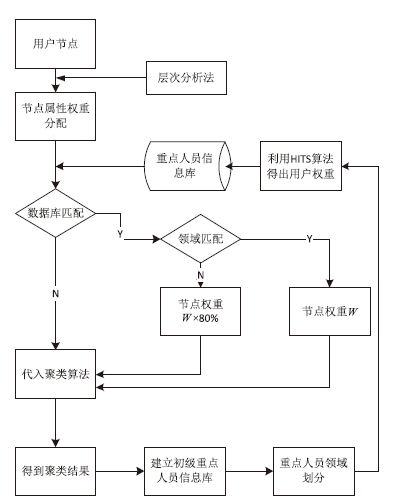
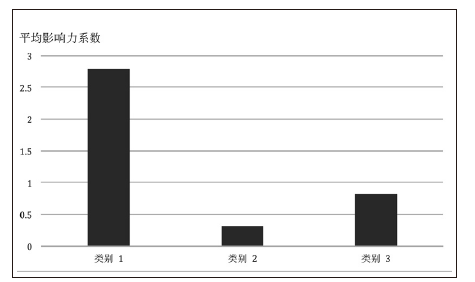
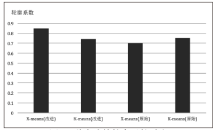
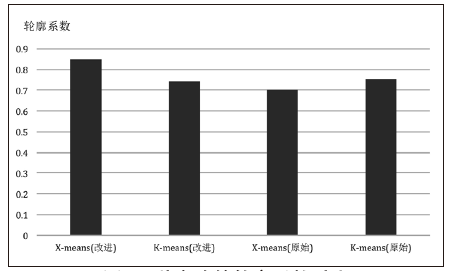
文章提出了一种热门微博分类的新思路,通过对热门微博的转发用户进行聚类分析,并根据不同的用户聚集状态来区分不同种类的热门微博。在用户聚类中采用了基于K-means聚类算法的改进算法X-means,并根据微博用户数据特点对X-means算法进行了进一步改进,将属性差异和用户节点差异考虑在聚类过程当中。其中,在对X-means算法改进过程中,对于用户属性的加权采用了基于对数函数的加权方式,确保聚类结果更加科学、准确;在对用户自身权重的加权中,通过建立重点人员信息库的方式,实现了对特殊用户节点的加权,并利用HITS算法对重点人员信息库实现动态更新。在完成用户聚类之后,将得到的重要用户的信息分领域录入重点人员信息库,实现聚类过程与信息库的反馈机制。另外,实验将相同数据分别代入改进前后的K-means算法与X-means算法中,并通过轮廓系数评价聚类结果,证明了改进后的X-means算法在微博用户聚类中更有优势。
中图分类号: