信息网络安全 ›› 2023, Vol. 23 ›› Issue (4): 80-89.doi: 10.3969/j.issn.1671-1122.2023.04.009
基于字符空间构造的域名匿名化算法
尹曙1,2, 陈兴蜀1,2( ), 朱毅1,2, 曾雪梅1,2
), 朱毅1,2, 曾雪梅1,2
- 1.四川大学网络空间安全学院,成都 610065
2.四川大学网络空间安全研究院,成都 610065
-
收稿日期:2022-10-26出版日期:2023-04-10发布日期:2023-04-18 -
通讯作者:陈兴蜀 E-mail:chenxsh@scu.edu.cn -
作者简介:尹曙(1998—),女,四川,硕士研究生,主要研究方向为云计算与大数据安全|陈兴蜀(1968—),女,四川,教授,博士,主要研究方向为云计算、数据安全体系、威胁检测和开源情报分析|朱毅(1991—),男,四川,博士研究生,主要研究方向为网络行为与威胁识别|曾雪梅(1976—),女,四川,工程师,博士,主要研究方向为网络流量识别、网络行为分析和IPv6网络安全。 -
基金资助:国家自然科学基金(U19A2081);国家自然科学基金(61802270);国家自然科学基金(61802271);中央高校基本科研业务费专项资金(SCU2021D048);四川大学工科特色团队项目(2020SCUNG129)
Anonymous Domain Name Algorithm Based on Character Space Construction
YIN Shu1,2, CHEN Xingshu1,2(), ZHU Yi1,2, ZENG Xuemei1,2
- 1. School of Cyber Science and Engineering, Sichuan University, Chengdu 610065, China
2. Cyber Science Research Institute, Sichuan University, Chengdu 610065, China
-
Received:2022-10-26Online:2023-04-10Published:2023-04-18 -
Contact:CHEN Xingshu E-mail:chenxsh@scu.edu.cn
摘要:
网络流量中包含的域名数据给网络流量共享带来数据隐私的挑战。现有对域名的匿名化处理方法多采用文本泛化和替换等手段,隐私性处理效果较好,但破坏了域名原有的结构和文本特性,无法满足网络安全分析场景的需求。文章提出一种面向网络安全分析的域名匿名化方法,通过基于域名结构的分层匿名处理策略和基于字符空间构造的匿名化算法,在保留网络安全分析过程中所关注的域名结构和文本属性特征的前提下对域名文本进行重构,实现既保留研究人员所需的域名数据可用性,又去除域名数据中的隐私信息的目的。为抵御穷举攻击,文章采取按参数随机重构的方式,以减少不同批次下相同域名匿名结果发生重复的概率,并基于校园网真实网络流量数据对提出的方法进行了验证。实验结果表明,文章提出的方法能够有效提升匿名化后域名数据的不可识别和不可逆的特性,并保留其在结构和语义方面的效用。
中图分类号:
引用本文
尹曙, 陈兴蜀, 朱毅, 曾雪梅. 基于字符空间构造的域名匿名化算法[J]. 信息网络安全, 2023, 23(4): 80-89.
YIN Shu, CHEN Xingshu, ZHU Yi, ZENG Xuemei. Anonymous Domain Name Algorithm Based on Character Space Construction[J]. Netinfo Security, 2023, 23(4): 80-89.
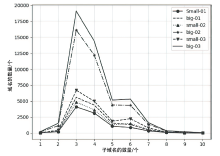
图1
拥有不同数量子域名的域名分布
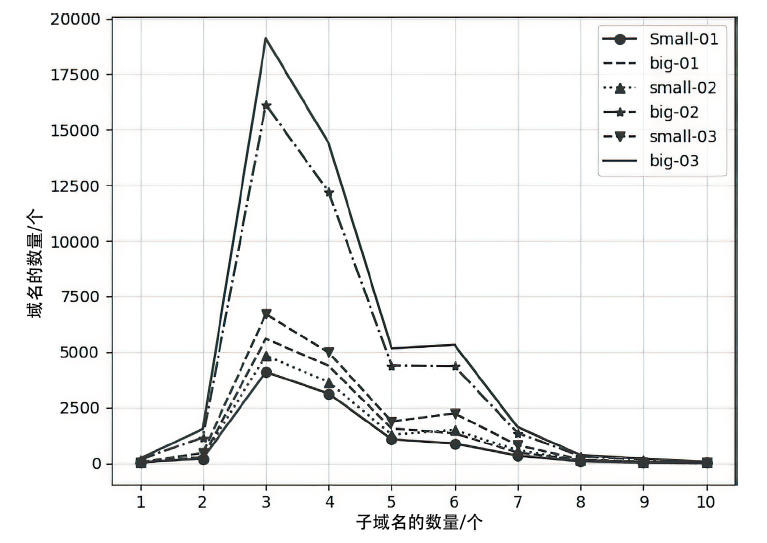
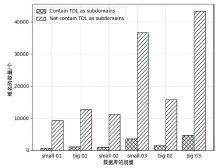
图2
不同规模域名数据中子域名包含TLD的情况统计
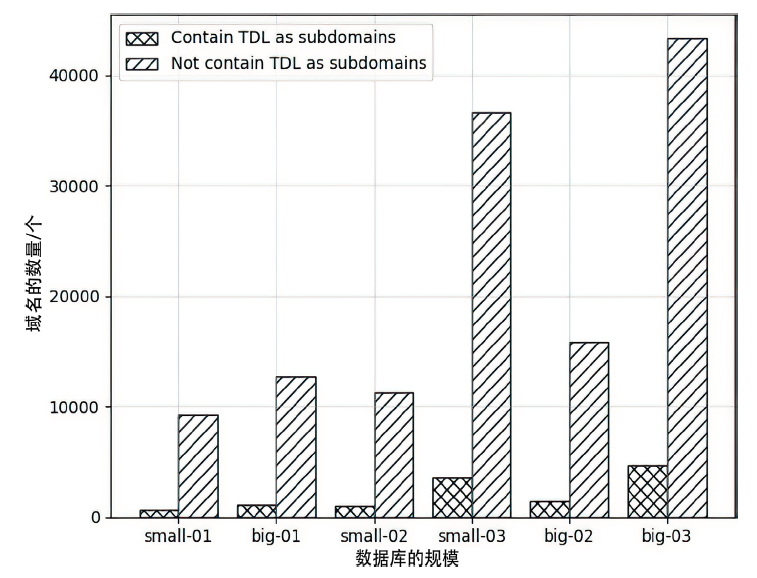
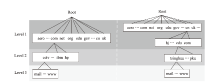
图3
域名的分层策略
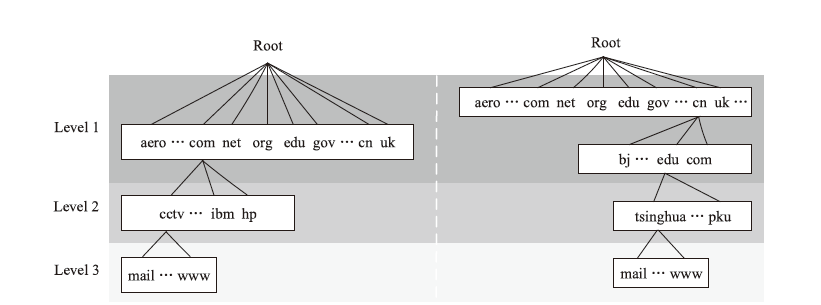
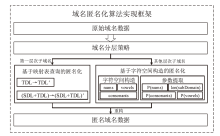
图4
基于字符空间构造的域名匿名化算法框架
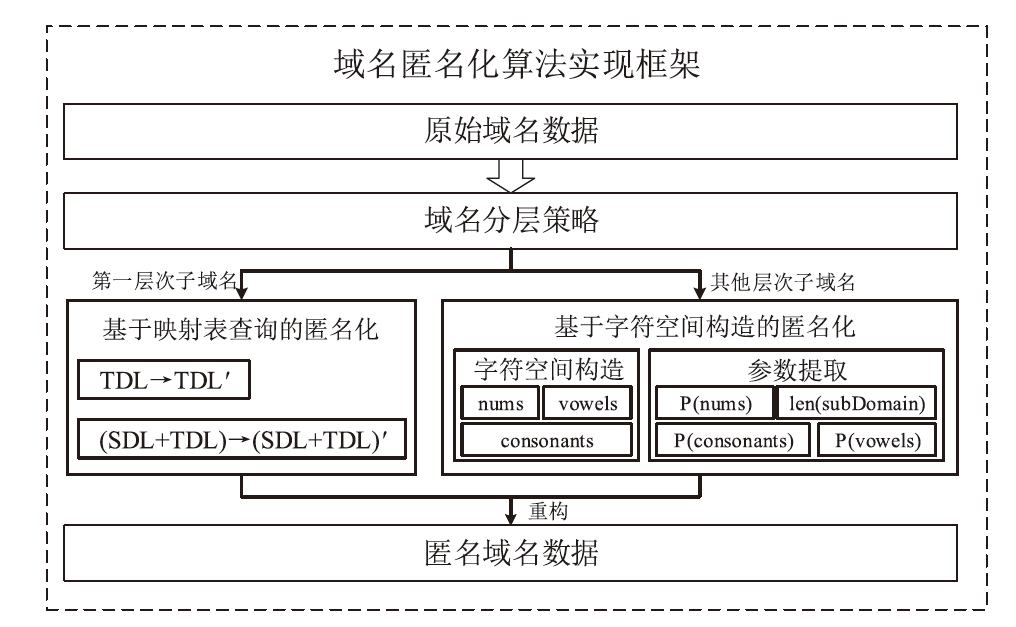
表1
实验数据描述
| Pcap数据包 数量 | 数据 规模 | 数据大小/MB | 数据包 数量/个 | 唯一域名 数量/个 |
|---|---|---|---|---|
| 1 | Small-01 | 14.9 | 103909 | 9837 |
| Big-01 | 27.6 | 194495 | 13802 | |
| 8 | Small-02 | 34 | 261860 | 12244 |
| Big-02 | 162 | 1139023 | 40221 | |
| 15 | Small-03 | 62.2 | 480121 | 17264 |
| Big-03 | 177 | 1293247 | 47916 |
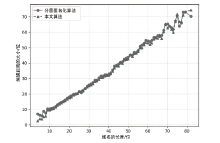
图5
两种算法下原域名和匿名结果之间的平均编辑距离
表2
两种算法在保留效用上的比较
| 特征 目录[ | 分层匿名化算法 | 基于字符空间构造的匿名化算法 | ||
|---|---|---|---|---|
| 特征 | 说明 | 特征 | 说明 | |
| 结构 特征 | Domain name length | 域名长度 | Domain name length | 域名长度 |
| Number of subdomains | 子域名个数 | Number of subdomains | 子域名个数 | |
| Length of subdomains | 子域名长度 | Length of subdomains | 子域名长度 | |
| Contains TLD as subdomain | 子域名包含TLD | Contains TLD as subdomain | 子域名包含TLD | |
| Ratio of digit-exclusive subdomains | 非数字字符在子域名内的占比 | |||
| Ratio of vowels-exclusive subdomains | 非元音字符在子域名内的占比 | |||
| Ratio of consonants-exclusive subdomains | 非辅音字符在子域名内占比 | |||
| 语义 特征 | Ratio of vowels | 元音字符的占比 | ||
| Ratio of digits | 数字的占比 | |||
| Ratio of consonants | 辅音的占比 | |||
表3
两种算法在原始域名与匿名结果的映射结果
| 数据 规模 | 分层匿名化算法 | 基于字符空间构造的 域名匿名化算法 | ||
|---|---|---|---|---|
| 对应不同匿名结果的相同域名重复数量 | 对应相同匿名结果的不同域名数量 | 对应不同匿名结果的相同域名重复数量 | 对应相同匿名结果的不同域名数量 | |
| Small-01 | 0 | 8 | 0 | 0 |
| Big-01 | 0 | 6 | 0 | 0 |
| Small-02 | 0 | 24 | 0 | 0 |
| Big-02 | 0 | 65 | 0 | 0 |
| Small-03 | 0 | 36 | 0 | 0 |
| Big-03 | 0 | 134 | 0 | 0 |
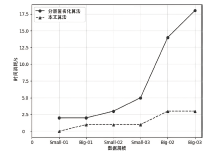
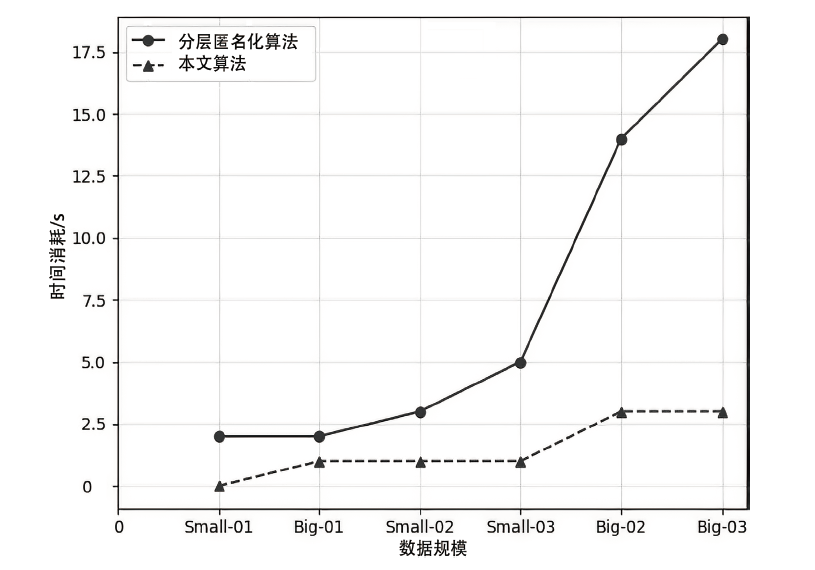
图6
分层匿名化算法和本文算法的时间消耗比较
| [1] | DENG Boyun. Research on Privacy Protection Technology of Data Publishing Based on Anonymization[D]. Guangzhou: Guangdong University of Technology, 2020. |
| 邓博允. 基于匿名化的数据发布隐私保护技术研究[D]. 广州: 广东工业大学, 2020. | |
| [2] | LENG Jianyu. Research on Anonymization Technology for Medical Information Privacy Protection[D]. Nanjing: Nanjing University of Posts and Telecommunications, 2021. |
| 冷建宇. 面向医疗信息隐私保护的匿名化技术研究[D]. 南京: 南京邮电大学, 2021. | |
| [3] |
SWEENEY L. K-Anonymity: A Model for Protecting Privacy[J]. International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems, 2002, 10(5): 557-570.
doi: 10.1142/S0218488502001648 URL |
| [4] | YAN Hongqiang, WANG Wei, ZHANG Jie. Overview on Privacy Policy and Technology of Internet Identifier[J]. Computer Systems & Applications, 2019, 28(12): 19-27. |
| 闫宏强, 王伟, 张婕. 互联网标识隐私保护政策及技术研究[J]. 计算机系统应用, 2019, 28(12): 19-27. | |
| [5] | Wong C W, LI J, Fu W C, et al. (Alpha, K)- Anonymity: An Enhanced K-Anonymity Model for Privacy Preserving Data Publishing[C]// ACM. Proceedings of the Twelfth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2006: 754-759. |
| [6] |
MACHANAVAJJHALA A, KIFER D, GEHRKE J, et al. L-Diversity: Privacy Beyond K-Anonymity[J]. ACM Transactions on Knowledge Discovery from Data, 2007, 1(1): 3-11.
doi: 10.1145/1217299.1217302 URL |
| [7] | KUMAR D. T-Closeness: Privacy Beyond K-Anonymity and Diversity[C]// IEEE. IEEE International Conference on Data Engineering. New York: IEEE, 2007: 106-115. |
| [8] |
HUANG Kai, KONG Ning. Research on Status of DNS Privacy[J]. Computer Engineering and Applications, 2018, 54(9): 28-36.
doi: 10.3778/j.issn.1002-8331.1801-0101 |
|
黄锴, 孔宁. DNS隐私问题现状的研究[J]. 计算机工程与应用, 2018, 54(9): 28-36.
doi: 10.3778/j.issn.1002-8331.1801-0101 |
|
| [9] | KUENNING G, MILLER E L. Anonymization Techniques for URLs and Filenames[EB/OL]. [2022-08-10]. https://www.doc88.com/p-2502951904428.html. |
| [10] | ZHOU Dongjie. Measurement and Research on New Expansion and Security of Domain Name System[D]. Zhengzhou: Information Engineering University, 2019. |
| 周东杰. 对域名系统新型扩展及安全问题的测量研究[D]. 郑州: 战略支援部队信息工程大学, 2019. | |
| [11] |
DIAO Jiawen. Survey of DNS Covert Channel[J]. Journal on Communications, 2021, 42(5): 164-178.
doi: 10.11959/j.issn.1000-436x.2021090 |
| [12] |
ZHANG Meng. Identification of DNS Covert Channel Based on Improved Convolutional Neural Network[J]. Journal on Communications, 2020, 41(1): 169-179.
doi: 10.11959/j.issn.1000-436x.2020017 |
| [13] |
SUN Y, JIAN K, CUI L, et al. Online Malicious Domain Name Detection with Partial Labels for Large-Scale Dependable Systems[J]. Journal of Systems and Software, 2022, 190: 111322-111333.
doi: 10.1016/j.jss.2022.111322 URL |
| [14] | CHEN Lili. Research on Malicious Domain Name Detection Technology Based on Improved Character Characteristics[D]. Beijing: North China University Of Technology, 2021. |
| 陈娌砺. 一种基于改进的字符特征的恶意域名检测技术研究[D]. 北京: 北方工业大学, 2021. | |
| [15] | XIA Fanglong. Research and Implementation of Malicious Similar Domain Name Detection System[D]. Beijing: Beijing University of Posts and Telecommunications, 2021. |
| 夏方龙. 恶意相似域名检测系统的研究与实现[D]. 北京: 北京邮电大学, 2021. | |
| [16] | VALLINA P, LE POCHAT V, FEAL Á, et al. Mis-Shapes, Mistakes, Misfits: An Analysis of Domain Classification Services[C]// ACM. Proceedings of the ACM Internet Measurement Conference. New York: ACM, 2020: 598-618. |
| [17] | JIA Lele. Research on the Value Evaluation of Network Domain Name —— Taking Ctrip as an Example[J]. Modern Business Trade Industry, 2021, 42(4): 48-50. |
| 贾乐乐. 网络域名价值评估研究——以携程为例[J]. 现代商贸工业, 2021, 42(4): 48-50. |
| [1] | 杜卫东, 李敏, 韩益亮, 王绪安. 基于密文转换的高效通用同态加密框架[J]. 信息网络安全, 2023, 23(4): 51-60. |
| [2] | 郭瑞, 魏鑫, 陈丽. 工业物联网环境下可外包的策略隐藏属性基加密方案[J]. 信息网络安全, 2023, 23(3): 1-12. |
| [3] | 李晓华, 王苏杭, 李凯, 徐剑. 一种支持隐私保护的传染病人际传播分析模型[J]. 信息网络安全, 2023, 23(3): 35-44. |
| [4] | 张学旺, 张豪, 姚亚宁, 付佳丽. 基于群签名和同态加密的联盟链隐私保护方案[J]. 信息网络安全, 2023, 23(3): 56-61. |
| [5] | 王晶宇, 马兆丰, 徐单恒, 段鹏飞. 支持国密算法的区块链交易数据隐私保护方案[J]. 信息网络安全, 2023, 23(3): 84-95. |
| [6] | 于晶, 袁曙光, 袁煜琳, 陈驰. 基于k匿名数据集的鲁棒性水印技术研究[J]. 信息网络安全, 2022, 22(9): 11-20. |
| [7] | 张学旺, 刘宇帆. 可追踪身份的物联网感知层节点匿名认证方案[J]. 信息网络安全, 2022, 22(9): 55-62. |
| [8] | 秦宝东, 余沛航, 郑东. 基于双陷门同态加密的决策树分类模型[J]. 信息网络安全, 2022, 22(7): 9-17. |
| [9] | 陈彬杰, 魏福山, 顾纯祥. 基于KNN的具有隐私保护功能的区块链异常交易检测[J]. 信息网络安全, 2022, 22(3): 78-84. |
| [10] | 王思蝶, 马兆丰, 罗守山, 徐单恒. 面向异构多链的区块链链上数据隐私保护方案[J]. 信息网络安全, 2022, 22(12): 67-75. |
| [11] | 晏燕, 张雄, 冯涛. 大数据统计划分发布的等比差分隐私预算分配方法[J]. 信息网络安全, 2022, 22(11): 24-35. |
| [12] | 梁广俊, 辛建芳, 倪雪莉, 马卓. 智能音箱安全与取证研究[J]. 信息网络安全, 2022, 22(10): 108-113. |
| [13] | 顾海艳, 蒋铜, 马卓, 朱季鹏. k-匿名改进算法及其在隐私保护中的应用研究[J]. 信息网络安全, 2022, 22(10): 52-58. |
| [14] | 徐硕, 张睿, 夏辉. 基于数据属性修改的联邦学习隐私保护策略[J]. 信息网络安全, 2022, 22(1): 55-63. |
| [15] | 路宏琳, 王利明, 杨婧. 一种新的参数掩盖联邦学习隐私保护方案[J]. 信息网络安全, 2021, 21(8): 26-34. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||