信息网络安全 ›› 2015, Vol. 15 ›› Issue (5): 16-20.doi: 10.3969/j.issn.1671-1122.2015.05.003
面向机构知识库结构化数据的文本相似度评价算法
吴旭1,2,3( ), 郭芳毓1,2, 颉夏青3, 许晋1,2
), 郭芳毓1,2, 颉夏青3, 许晋1,2
- 1. 北京邮电大学计算机学院,北京 100876
2. 北京邮电大学可信分布式计算与服务教育部重点实验室,北京 100876
3. 北京邮电大学图书馆,北京 100876
A Text Similarity Evaluation Algorithm for Structured Data of Institutional Repository
WU Xu1,2,3(), GUO Fang-yu1,2, XIE Xia-qing3, XU Jin1,2
- 1. School of Computer Science, Beijing University of Posts and Telecommunications, Beijing 100876, China
2. Key Laboratory of Trustworthy Distributed Computing and Service (BUPT), Ministry of Education, Beijing 100876, China
3. Beijing University of Posts and Telecommunications Library, Beijing 100876, China
摘要:
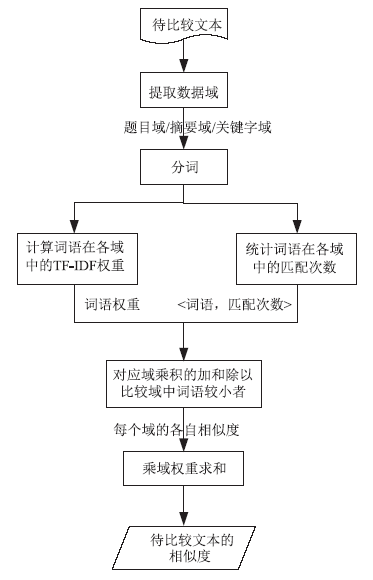
机构知识库是一个以机构成员在工作过程中所创建的各种数字化产品为内容,以网络为依托,以收集、整理、保存、检索、提供利用为目的的知识库,其中文本数据集多呈现结构化,且具有离散性。而个性化推荐技术可以有效提高机构知识库资源的曝光率和利用率,将现有的“用户主导行为”模式转变为“以知识驱动行为”模式,使得机构知识库用户能够更高效地获取学术信息。为此,文章在研究国内外已有的相似性度量方法的基础上,引入不同权重词语对整体相似度有不同影响的思想,提出一种基于TF-IDF和词语匹配的文本相似度评价算法。通过分析DC(Dublin Core)元数据格式,筛选其中有效数据,计算特定词语在指定域中的权重并统计匹配次数,在文本长度归一化的基础上进行文本相似度计算。实验以手动建立文本测试集进行相似度计算,经统计分析,表明该算法能够对结构化离散文本数据的相似度进行合理计算,降低了机构知识库离散数据集在进行相似度计算时的向量维度,计算结果与实际数据吻合较好,具有可行性和实际应用价值。
中图分类号: